







目录
前言
层次分析法( Analytic Hierarchy Process,简称 AHP)是对一些较为复杂、较为模
糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。它是美
国运筹学家 T. L. Saaty 教授于上世纪 70 年代初期提出的一种简便、灵活而又实用的
多准则决策方法。
1、层次分析法的基本原理与步骤
人们在进行社会的、经济的以及科学管理领域问题的系统分析中,面临的常常是一个由相互关联、相互制约的众多因素构成的复杂而往往缺少定量数据的系统。层次分析法为这类问题的决策和排序提供了一种新的、简洁而实用的建模方法。
运用层次分析法建模,大体上可按下面四个步骤进行:
(i)建立递阶层次结构模型;
(ii)构造出各层次中的所有判断矩
(iii)层次单排序及一致性检验;
(iv)层次总排序及一致性检验。
下面分别说明这四个步骤的实现过程。
1.1、递阶层次结构的建立与特点
应用 AHP 分析决策问题时,首先要把问题条理化、层次化,构造出一个有层次的结构模型。在这个模型下,复杂问题被分解为元素的组成部分。这些元素又按其属性及关系形成若干层次。上一层次的元素作为准则对下一层次有关元素起支配作用。这些层次可以分为三类:
(i)最高层:这一层次中只有一个元素,一般它是分析问题的预定目标或理想结果,因此也称为目标层。
(ii)中间层:这一层次中包含了为实现目标所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的准则、子准则,因此也称为准则层。
(iii)最底层:这一层次包括了为实现目标可供选择的各种措施、决策方案等,因此也称为措施层或方案层。
递阶层次结构中的层次数与问题的复杂程度及需要分析的详尽程度有关,一般地层次数不受限制。每一层次中各元素所支配的元素一般不要超过 9 个。这是因为支配的元素过多会给两两比较判断带来困难。
下面结合一个实例来说明递阶层次结构的建立。
假期旅游有 P1、 P2 、 P3 3 个旅游胜地供你选择,试确定一个最佳地点。在此问题中,你会根据诸如景色、费用、居住、饮食和旅途条件等一些准则去反复比较 3 个侯选地点。可以建立下图 所示的层次结构模型。
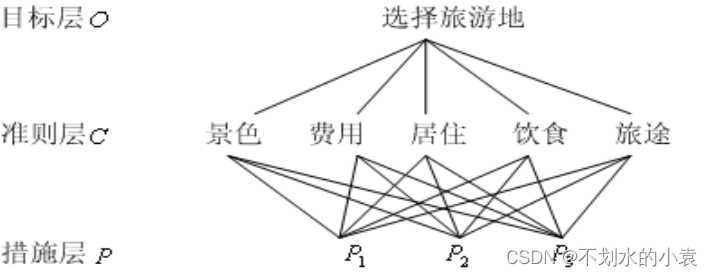 |
1.2、构造判断矩阵
层次结构反映了因素之间的关系,但准则层中的各准则在目标衡量中所占的比重并不一定相同,在决策者的心目中,它们各占有一定的比例。
在确定影响某因素的诸因子在该因素中所占的比重时,遇到的主要困难是这些比重常常不易定量化。此外,当影响某因素的因子较多时,直接考虑各因子对该因素有多大程度的影响时,常常会因考虑不周全、顾此失彼而使决策者提出与他实际认为的重要性程度不相一致的数据,甚至有可能提出一组隐含矛盾的数据。为看清这一点,可作如下假设:将一块重为 1 千克的石块砸成 小块,你可以精确称出它们的重量,设为
,现在,请人估计这
小块的重量占总重量的比例(不能让他知道各小石块的重量),此人不仅很难给出精确的比值,而且完全可能因顾此失彼而提供彼此矛盾的数据。
设现在要比较 个因子
对某因素 Z 的影响大小, 怎样比较才能提供可信的数据呢? Saaty 等人建议可以采取对因子进行两两比较建立成对比较矩阵的办法。即每次取两个因子
和
,以
表示
和
对
的影响大小之比,全部比较结果用矩阵
表示,称
为
之间的成对比较判断矩阵(简称判断矩阵)。容易看出,若
与
对
的影响之比为
,则
与
对 Z 的影响之比应为
定义 1 若矩阵 满足
(i) > 0 (ii)
则称之为正互反矩阵
关于如何确定 的值, Saaty 等建议引用数字 1~9 及其倒数作为标度。表中列出了 1~9 标度的含义:
 |
1.3 层次单排序及一致性检验
判断矩阵 A 对应于最大特征值 的特征向量
,经归一化后即为同一层次相应因素对于上一层次某因素相对重要性的排序权值,这一过程称为层次单排序。
上述构造成对比较判断矩阵的办法虽能减少其它因素的干扰,较客观地反映出一对因子影响力的差别。但综合全部比较结果时,其中难免包含一定程度的非一致性。如果比较结果是前后完全一致的,则矩阵 A 的元素还应当满足:
,
定义2 满足上述条件的正反矩阵称为一致矩阵
需要检验构造出来的(正互反)判断矩阵 A 是否严重地非一致,以便确定是否接受 A 。
定理 1 正互反矩阵 A 的最大特征根 必为正实数,其对应特征向量的所有分量均为正实数。 A 的其余特征值的模均严格小于
。
(i) 必为正互反矩阵。
(ii) 的转置矩阵
也是一致矩阵。
(iii) 的任意两行成比例,比例因子大于零,从而 rank(A) = 1 (同样, A 的任意两列也成比例)。
(iv) A 的最大特征值 = , 其中 n 为矩阵 A 的阶。 A 的其余特征根均为零。
(v) 若 A 的最大特征值 对应的特征向量为
, 则
,
定理 3 n 阶正互反矩阵 A 为一致矩阵当且仅当其最大特征根 = ,且当正互反矩阵 A 非一致时,必有 >
。
根据定理 3,我们可以由是否等于 n 来检验判断矩阵 A 是否为一致矩阵。由于特征根连续地依赖于aij ,故
比 n 大得越多, A 的非一致性程度也就越严重,
对应的标准化征向量也就越不能真实地反映出
在对因素 Z的影响中所占的比重。因此,对决策者提供的判断矩阵有必要作一次一致性检验,以决定是否能接受它。
对判断矩阵的一致性检验的步骤如下:
(i)计算一致性指标CI
(ii)查找相应的平均随机一致性指标 RI 。对 n = 1,...,9 , Saaty 给出了 RI 的值,
如下表所示。
 |
RI 的值是这样得到的,用随机方法构造 500 个样本矩阵:随机地从 1~9 及其倒数中抽取数字构造正互反矩阵,求得最大特征根的平均值 ,并定义
(ⅲ)计算一致性比例CR
当CR < 0.10 时,认为判断矩阵的一致性是可以接受的,否则应对判断矩阵作适当修正。
2、实际应用
例:挑选合适的工作。经双方恳谈,已有三个单位表示愿意录用某毕业生。该生根据已有信息建立了一个层次结构模型,如下图所示。
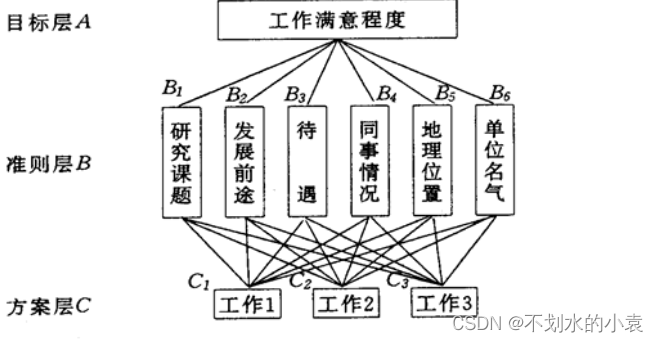 |
准则层判断矩阵如下:
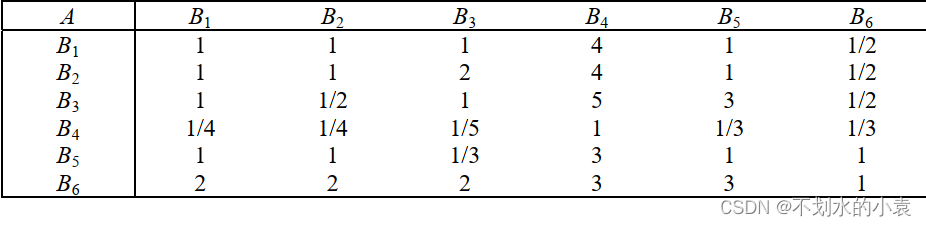 |
方案层判断矩阵如下:
 |
最终结果:
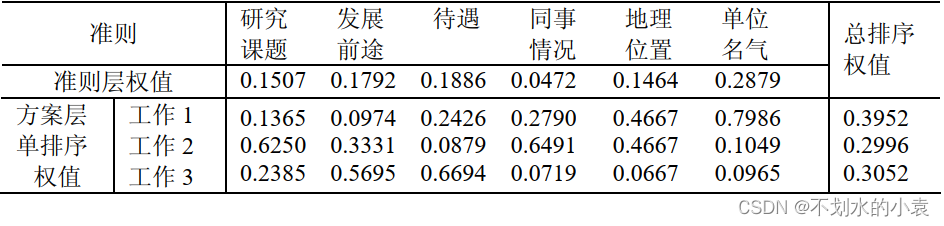 |
3、代码实现
clc
clear
%准则层
B = [1 1 1 4 1 1/2
1 1 2 4 1 1/2
1 1/2 1 5 3 1/2
1/4 1/4 1/5 1 1/3 1/3
1 1 1/3 3 1 1
2 2 2 3 3 1];
%方案层
C1 = [1 1/4 1/2; 4 1 3; 2 1/3 1];
C2 = [1 1/4 1/5; 4 1 1/2; 5 2 1];
C3 = [1 3 1/3; 1/3 1 1/7; 3 7 1];
C4 = [1 1/3 5; 3 1 7; 1/5 1/7 1];
C5 = [1 1 7; 1 1 7; 1/7 1/7 1];
C6 = [1 1 7; 1 1 7; 1/7 1/7 1];
%一致性指标
RI=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45];
%准则层检验
[x,y]=eig(B);
lamda=max(diag(y));%求解最大特征值
num=find(diag(y)==lamda);%找到最大特征值所在列
w0=x(:,num)/sum(x(:,num));%权值向量
CR0=(lamda-length(B))/(length(B)-1)/RI(length(B))%一致性指标检验
%方案层检验
C = [C1, C2, C3, C4, C5, C6];
for i = 1:6
[x,y]=eig(C(:,(i-1)*3+1:(i*3)));
lamda=max(diag(y));
num=find(diag(y)==lamda);
w1(:,i)=x(:,num)/sum(x(:,num));
CR1(i)=(lamda-length(C1))/(length(C1)-1)/RI(length(C1));
end
CR1
%最后得分
score=w1*w0如果以上内容对你有所帮助,不妨点赞关注,感谢观看!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









