







文章目录
基于Resent的医学数据集分类实战
一.医学疾病数据集介绍
原始数据集:
-
NCT-CRC-HE-100K:结肠癌组织
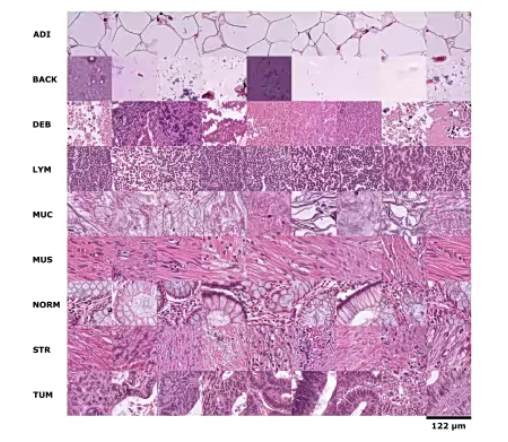
-
NIH-ChestXray14 dataset:肺部X光数据
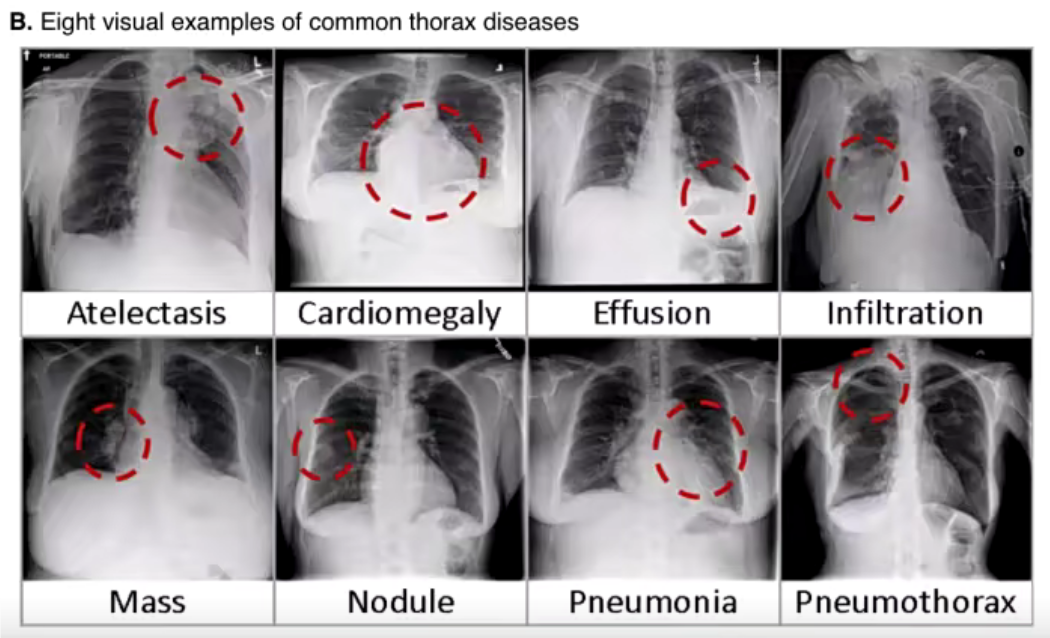
-
HAM10000:皮肤病变数据集
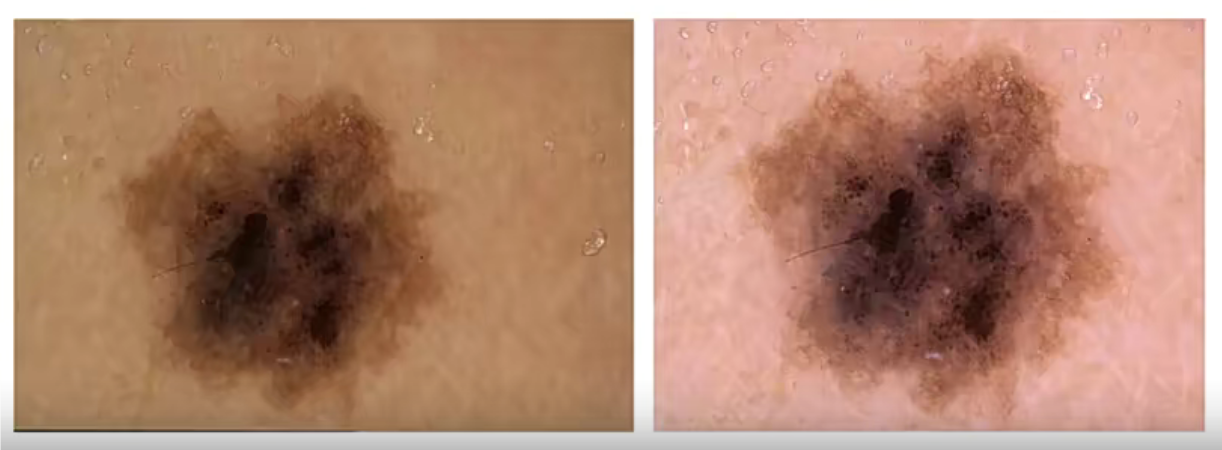
但是这些数据集的规模都太大了,所以我们对这些数据进行处理,得到简易实验的数据集,所有的数据格式都类似mnist(28*28),方便我们进行初步试验。

二.Resnet网络架构原理分析
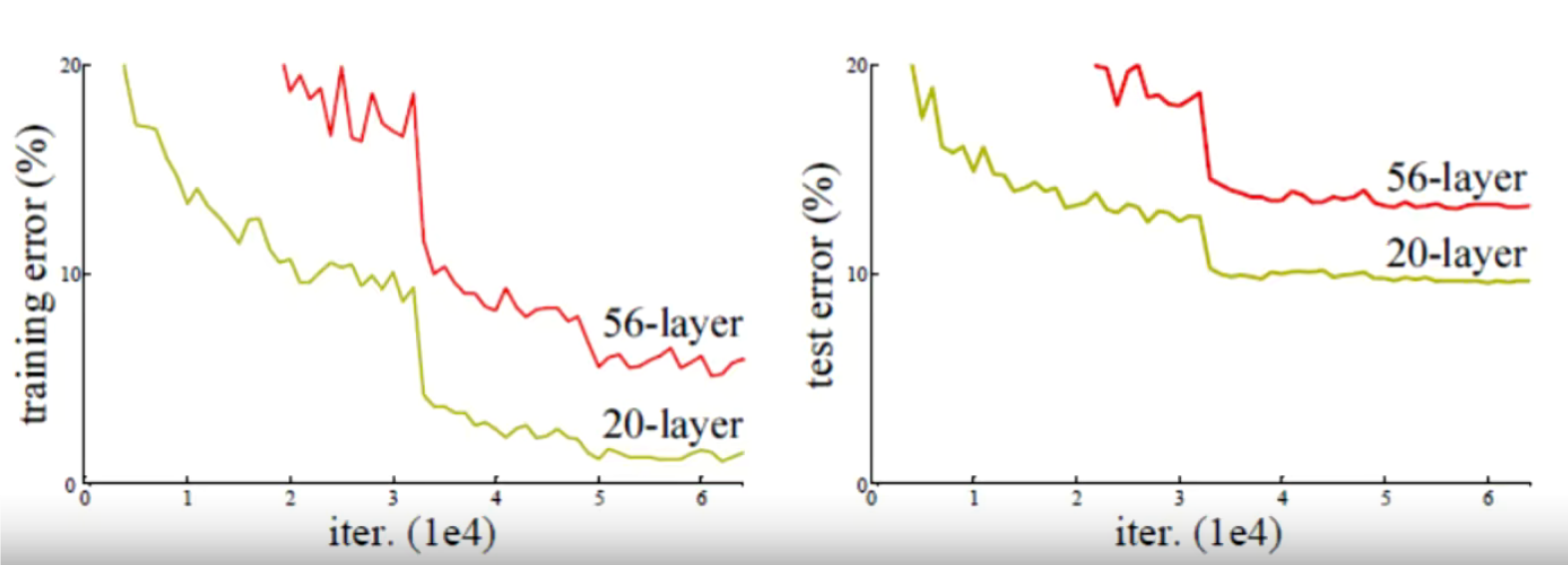
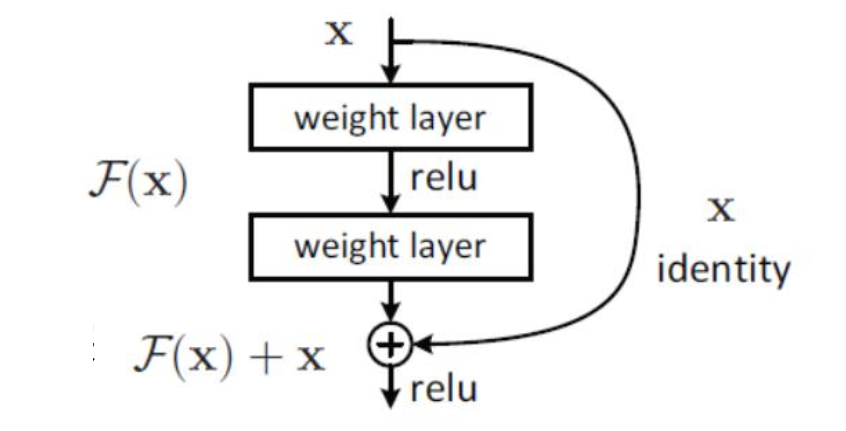
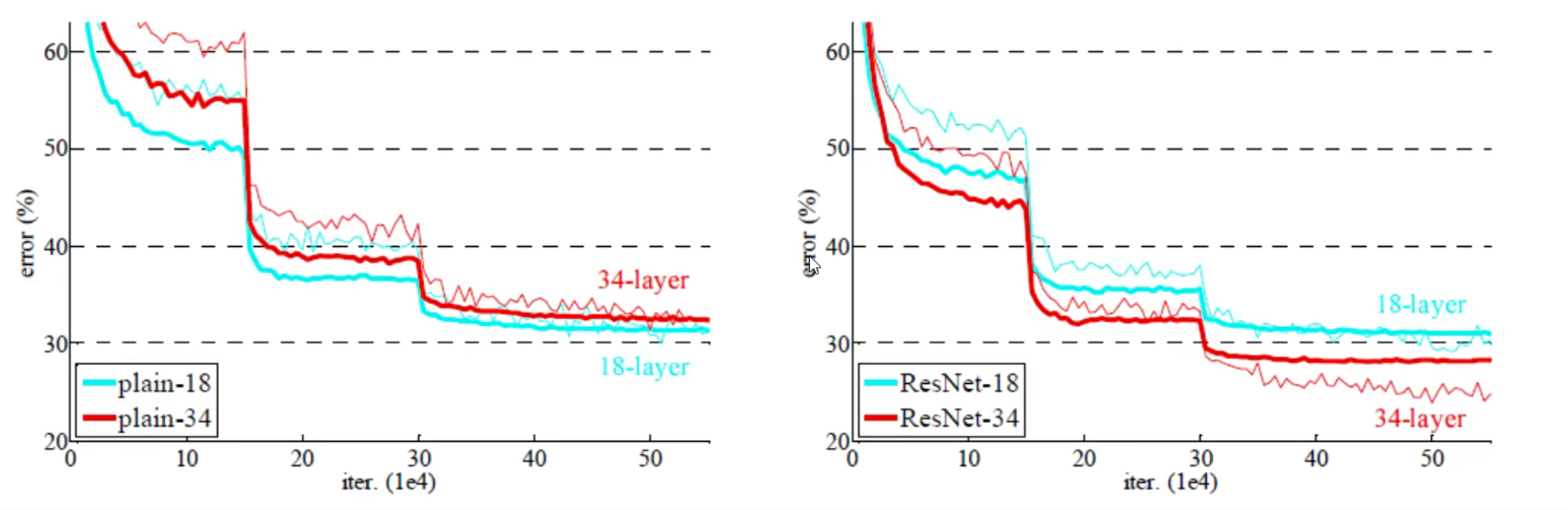
Resnet要解决的问题:传统网络模型如果堆叠的越深,效果反而开始下降(由下图可以看出,56层的网络效果反而差于20层的网络),这可怎么办?
Resnet核心模块:
- 一句话描述:至少不比原来差
- 相当于加了一个双保险,让模型自己选
- 继续堆叠很多的这样的结构,网络就能更深
- 应用领域广泛,各大计算机视觉任务都是以它为基础模块
Resnet的应用效果:
- 可以继续堆叠网络层数,效果还会继续提升
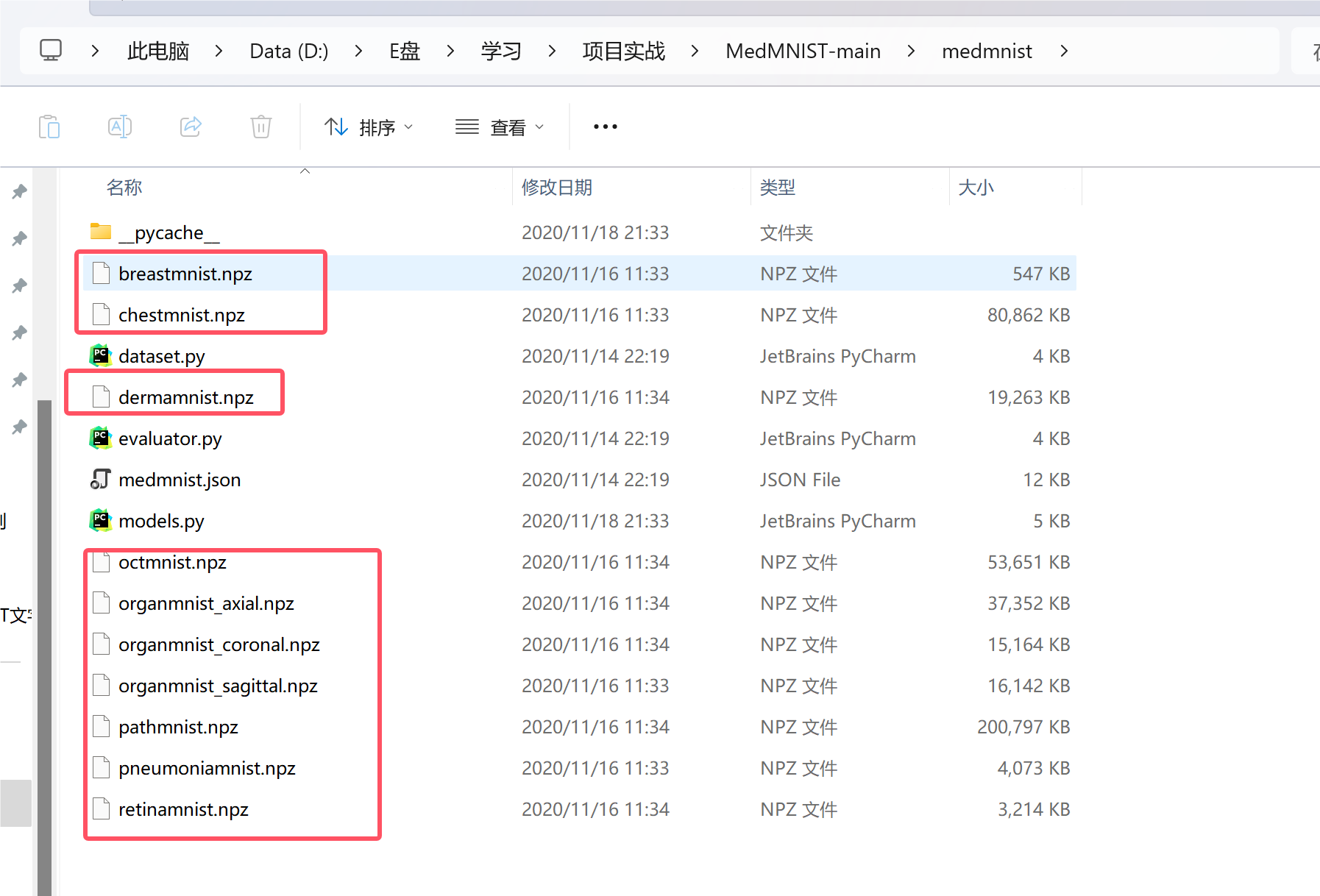
三.dataloader加载数据集
我们先看下我们的数据,这里已经将他们全部都打包成.npz文件了,我们在代码中直接加载即可:
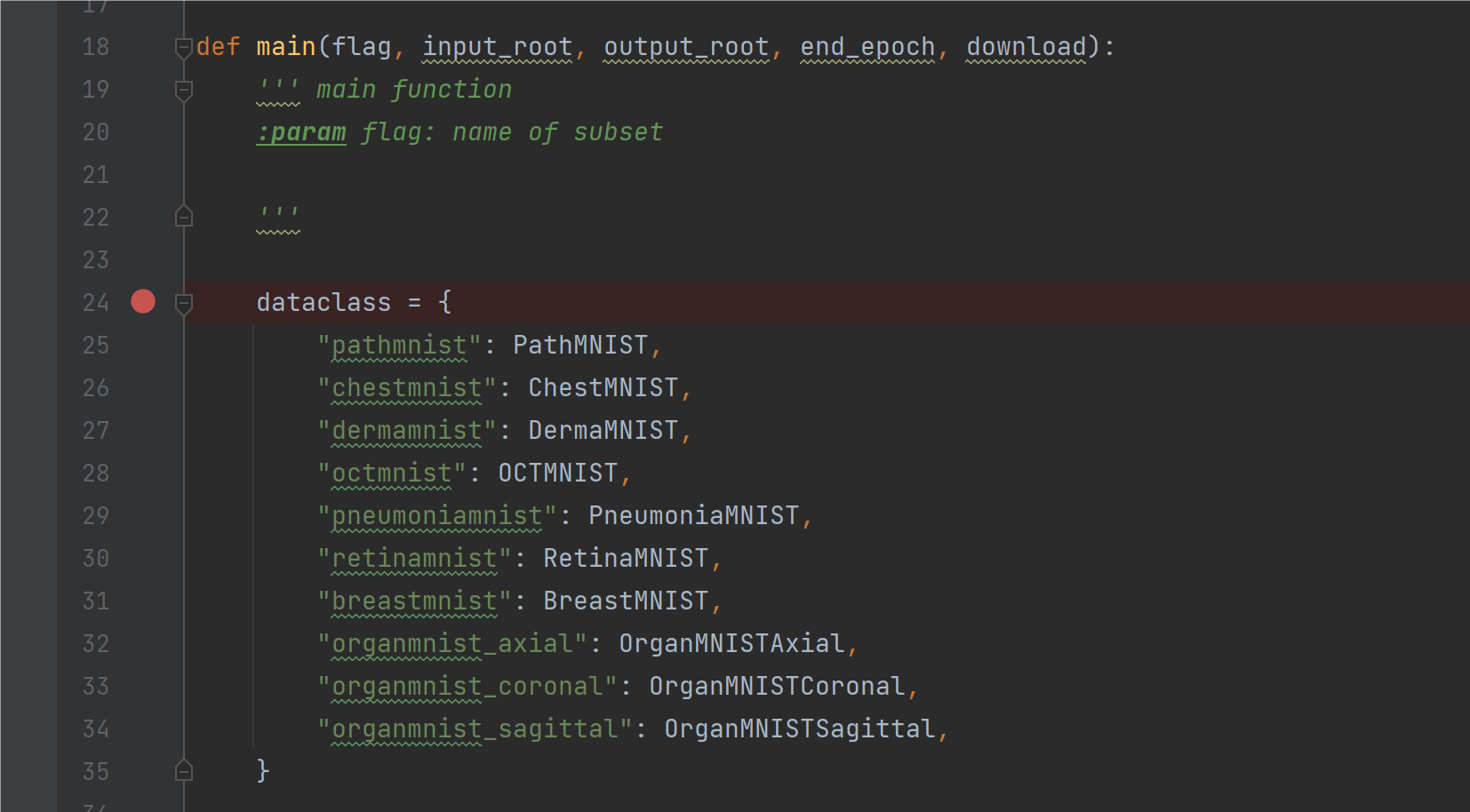
接下来我们来看训练的代码了,先看main函数:
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='RUN Baseline model of MedMNIST')
parser.add_argument('--data_name', default='pathmnist', help='subset of MedMNIST', type=str)
parser.add_argument('--input_root', default='./input', help='input root, the source of dataset files', type=str)
parser.add_argument('--output_root', default='./output', help='output root, where to save models and results',type=str)
parser.add_argument('--num_epoch', default=100, help='num of epochs of training', type=int)
parser.add_argument('--download', default=False, help='whether download the dataset or not',type=bool)
args = parser.parse_args()
data_name = args.data_name.lower()
input_root = args.input_root
output_root = args.output_root
end_epoch = args.num_epoch
download = args.download
main(data_name, input_root, output_root, end_epoch=end_epoch, download=download)
这里主要是命令行参数和相应的解析,- -data_name是我们需要使用的数据集的名字,- -input_root是我们需要使用的数据集的路径,- -output_root是输出结果的路径,- -num_epoch是训练所需的轮次,- -download是是否需要下载数据集,这里指定false即可,因为数据集我们已经提前下载到本地了。
这里我配置的命令行参数为:
- -data_name pathmnist
- -input_root ./medmnist
- -num_epoch 100
这里我们给代码打上一些断点,开始运行程序,一步一步的去看代码中怎么实现的,我们现在项目中的def main函数的第一行打上断点,然后开始调试:
with open(INFO, 'r') as f:
info = json.load(f)
task = info[flag]['task']
n_channels = info[flag]['n_channels']
n_classes = len(info[flag]['label'])
这里会打开一个json文件,json文件中的内容为数据集的具体详细的一些配置信息。
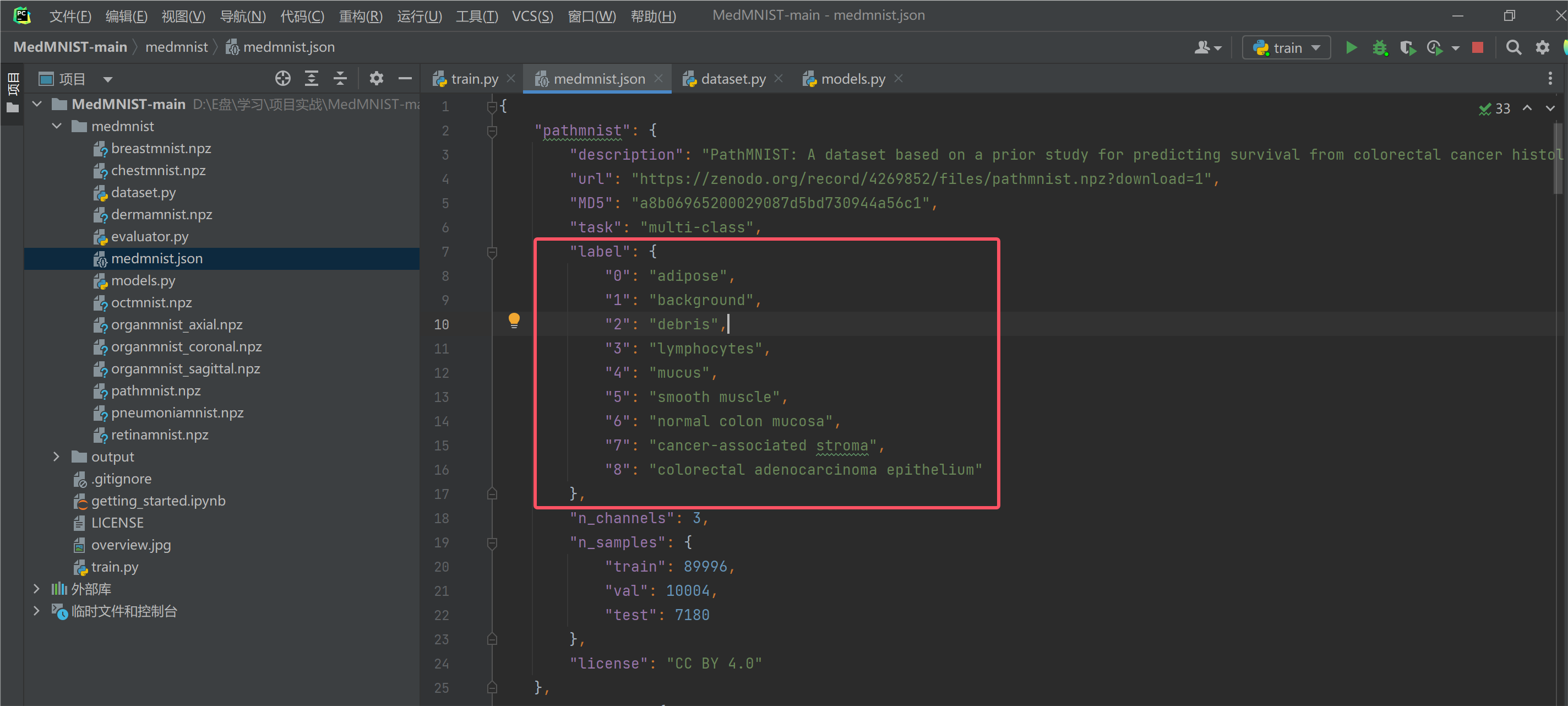
然后我们主要项目中的这三个代码包:
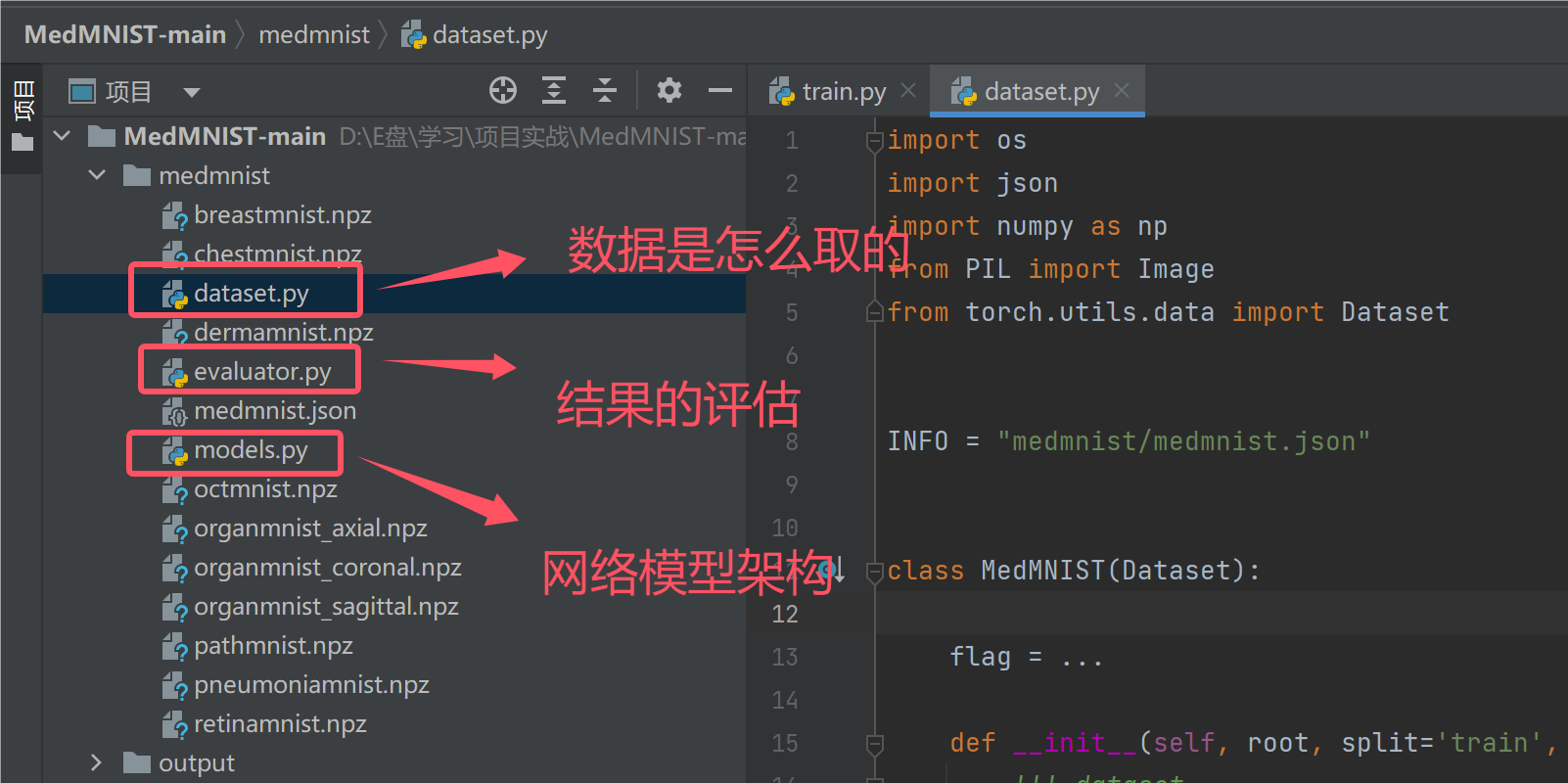
我们在dataset.py中打上断点,在__getitem__函数的第一行打上断点,然后调试程序:
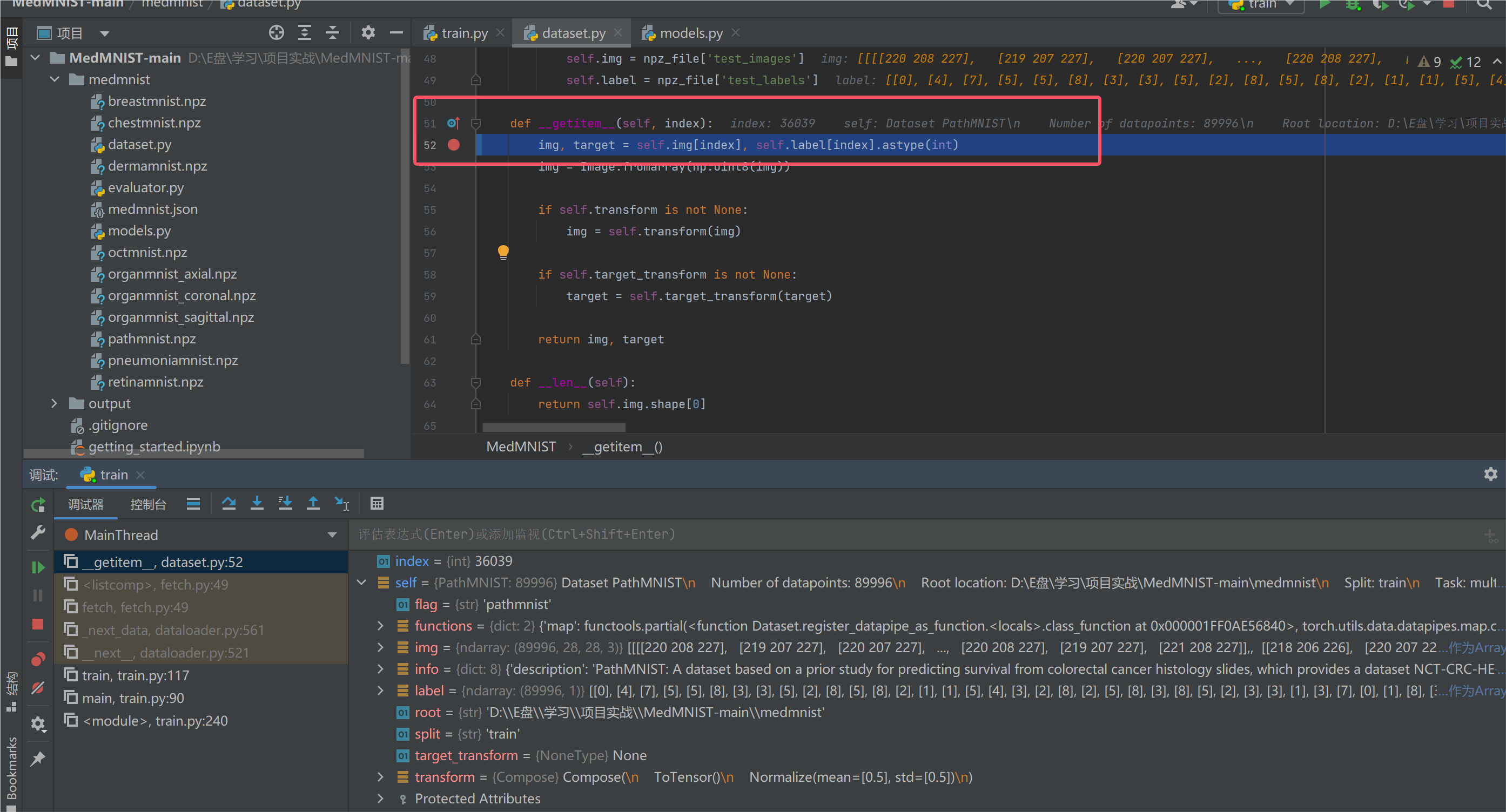
我们的getitem函数会依据batch来构建数据,接下来我们来看看它是如何实现的:
def __getitem__(self, index):
img, target = self.img[index], self.label[index].astype(int)
img = Image.fromarray(np.uint8(img))
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
这里的img是数据x,target是它的标签y,我们需要对x进行数据增强的处理(通过transform),对于标签y一般不需要。这里的getitem会对每条数据都进行处理,所以会被调用很多很多次。直到加载完所有的数据。
四.Resnet网络前向传播
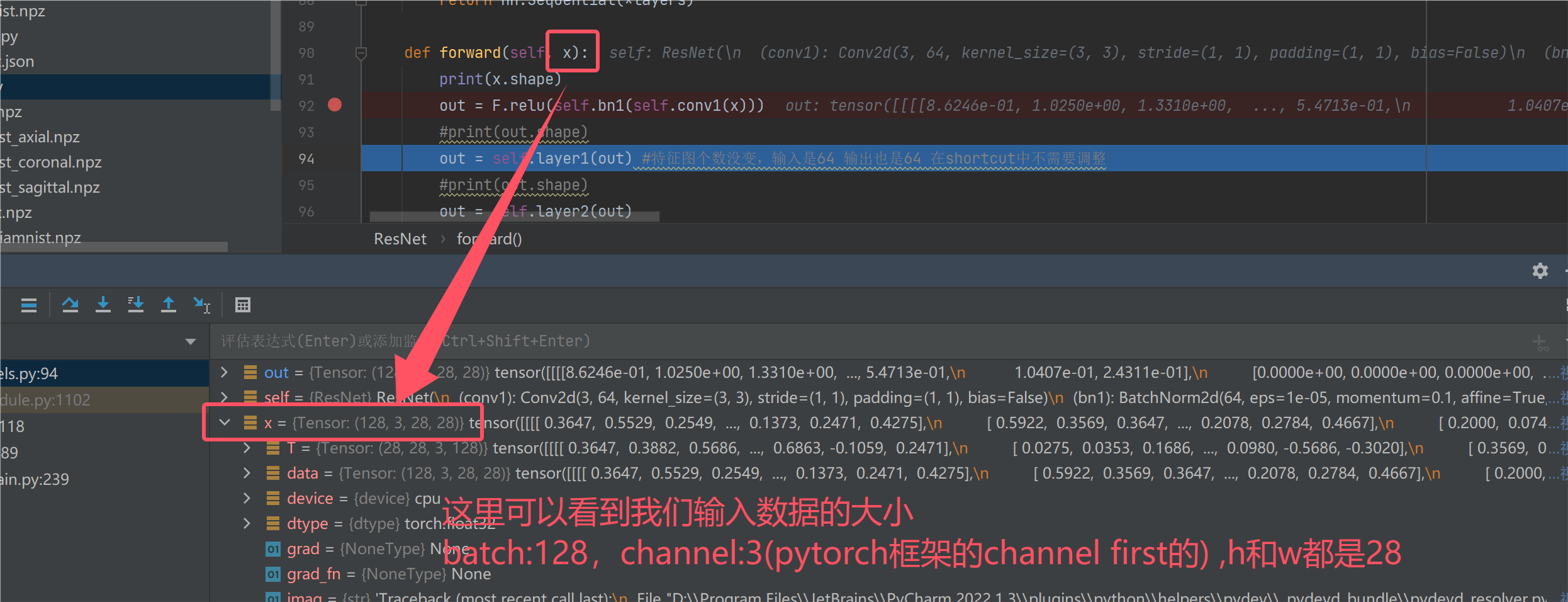
此处我们就不用再看dataset.py里面的代码了,我们去models.py中找到resnet的前向传播(forword函数)的代码,并且打上断点。

我们进行调试,首先看一下输入数据的规模:
五.残差网络的shortcut操作
我们走了两层之后,发现特征图大小变成了:128*64*28*28,其实走一层的时候就变成这样了。batch和h和w都是没有变的。我们设置stride为2的时候,h和w一般才会变。为什么经过一层的卷积后,会得到64张特征图呢?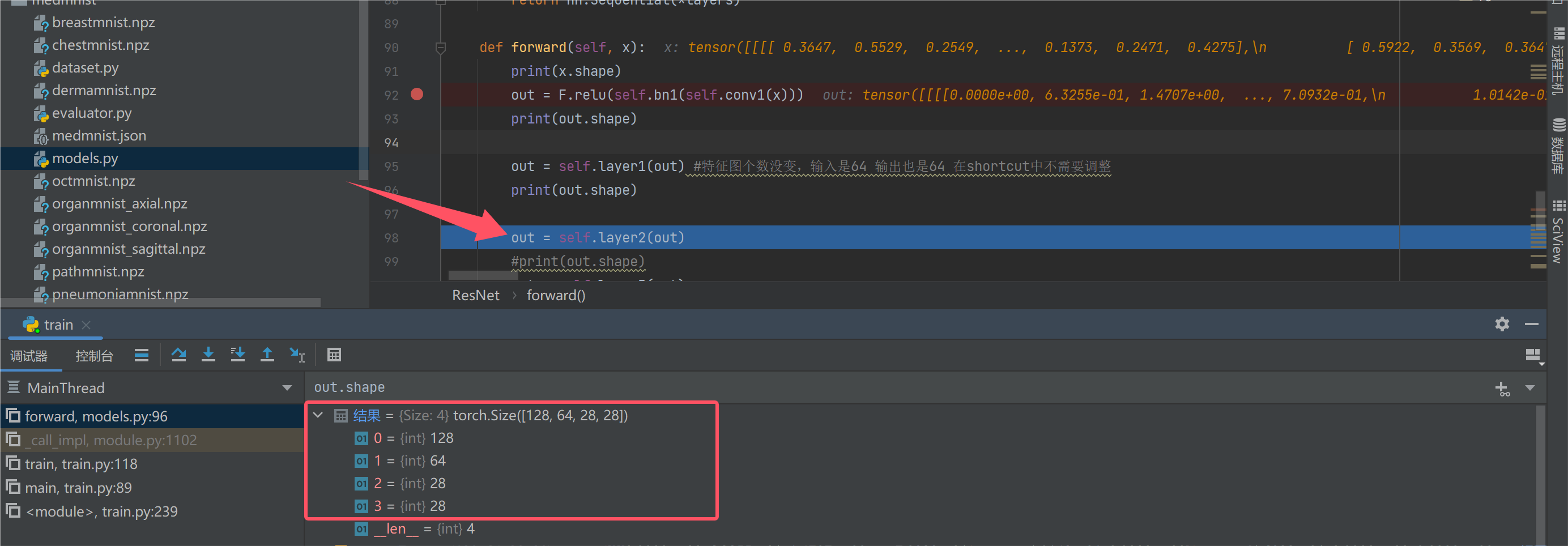
答案在这里,因为有64个卷积核,所以经过一层卷积后会得到64张特征图:
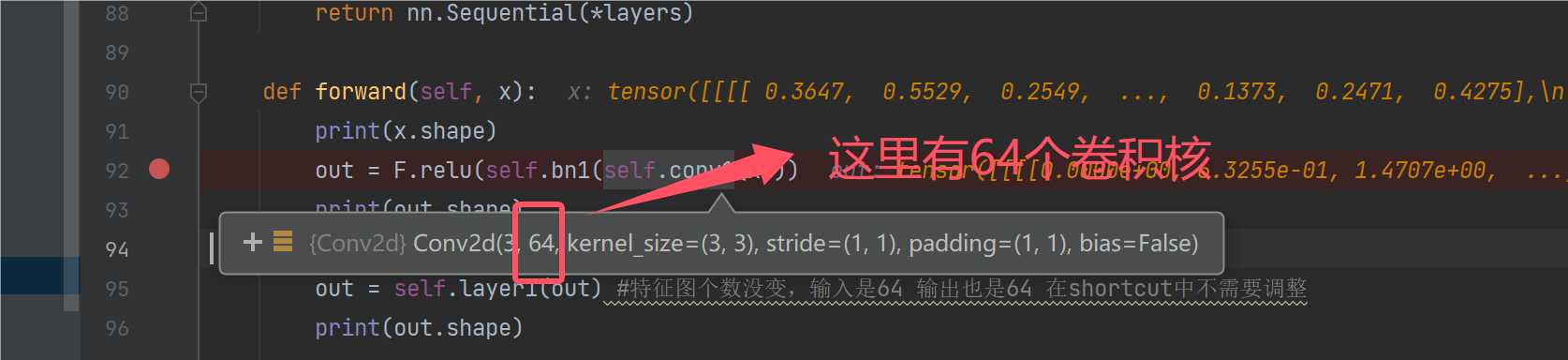
接下来我们来刨析一下Layer1层的行为,根据调试结果不难发现,Layer1并没有让[b,c,h,w]发生变换,我们来分析下原因:
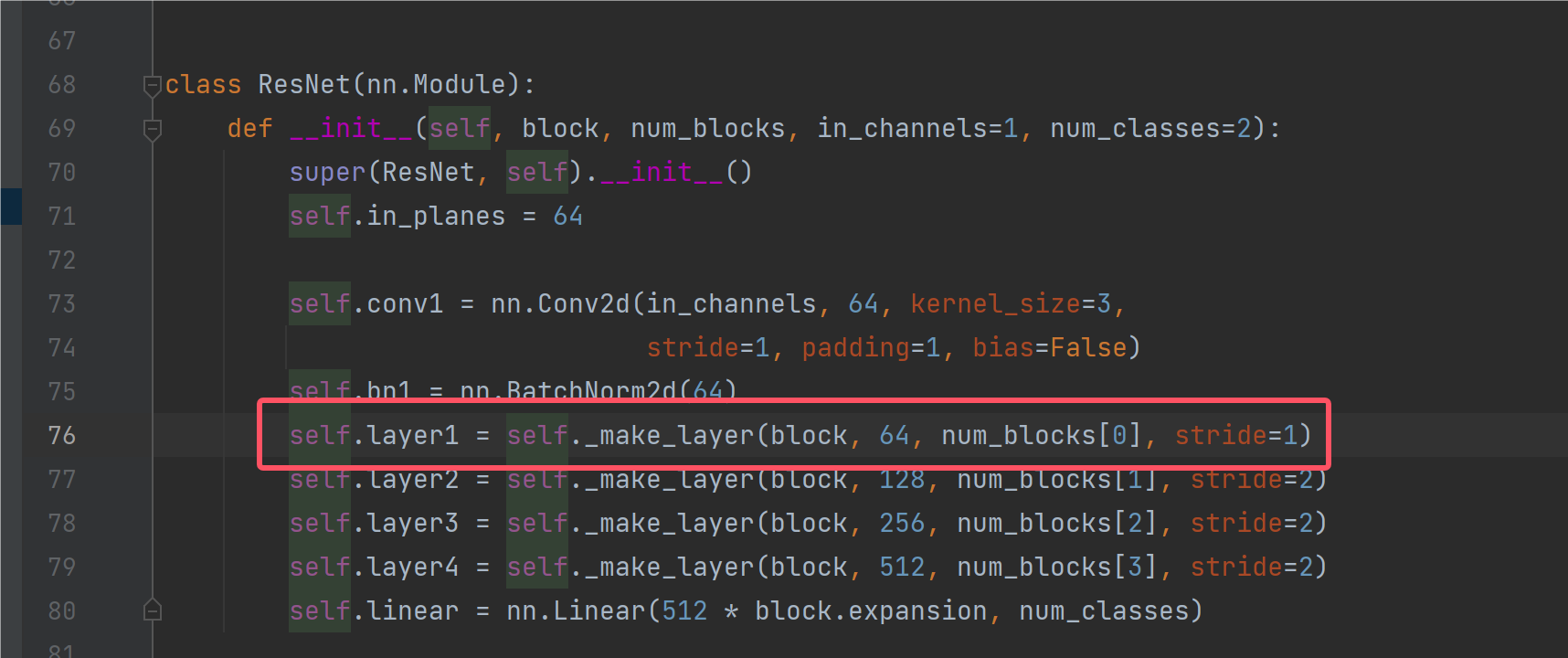
我们首先发现,layer1到layer4都是我们自己定义的一个make_layer函数,那么这个make_layer又是干什么的呢?我们先看代码:
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
这里传入的第一个参数block表示什么意思,这个参数是表示一个基础的计算单元是什么,我们的resnet网络是分为一个个BasicBlock去计算的:
class BasicBlock(nn.Module):
def forward(self, x):
#print(x.shape)
out = F.relu(self.bn1(self.conv1(x)))
#print(out.shape)
out = self.bn2(self.conv2(out))
#print(out.shape)
out += self.shortcut(x)
#print(out.shape)
out = F.relu(out)
return out
这里有个BasciBlock的计算过程是两次卷积操作(bn1和bn2),和一次shortcut操作。计算流程如下:
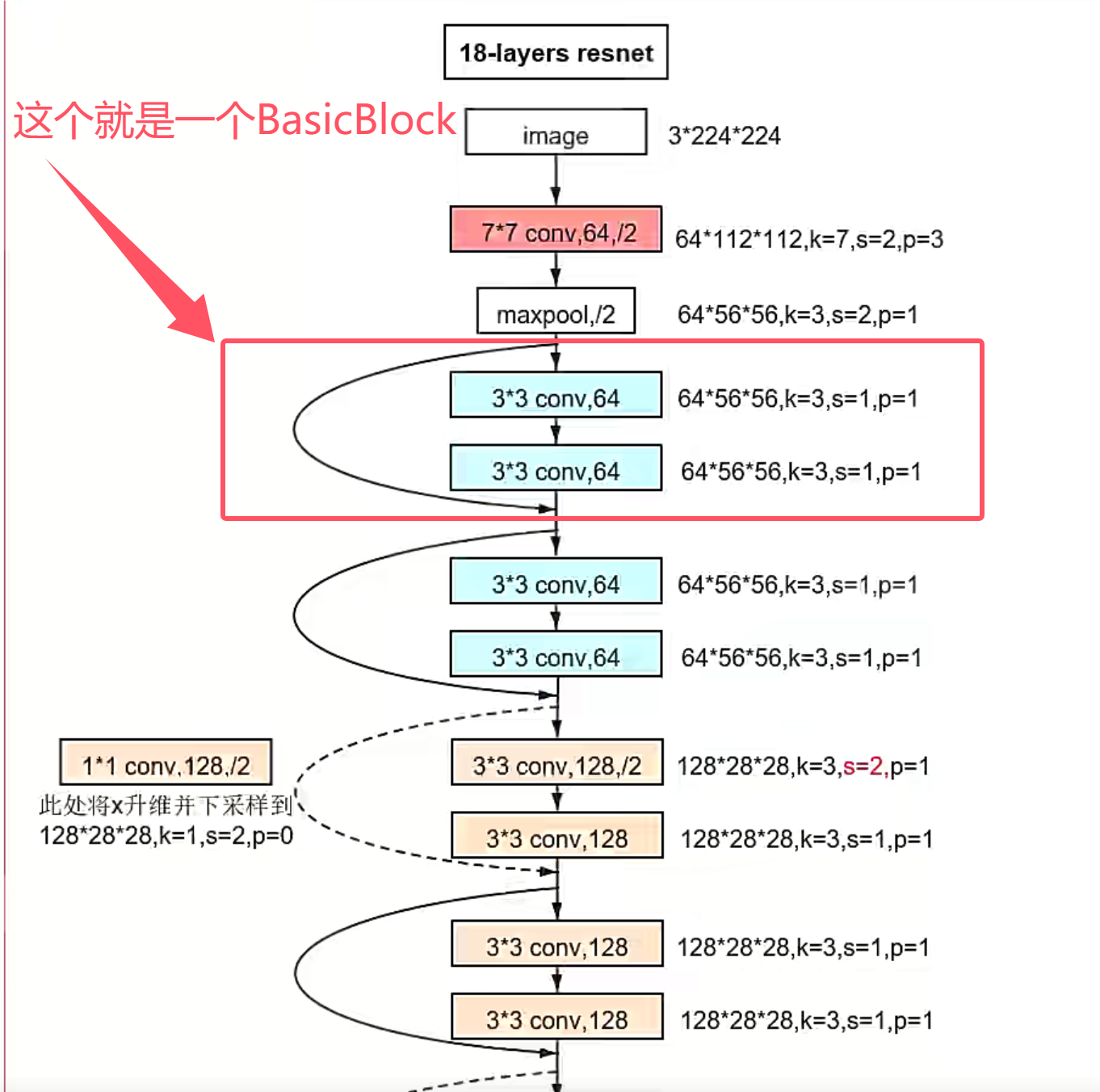
传入的第二个参数是输出图像的channel通道数目,第三个参数num_block[],表示做几组这样的Basci_Block。最后的stride是卷积时的步长,会影响到h和w。
因为我们控制了Basic_Block中的两次卷积后的结果保持和输入一样的规模,所以需要将输入加入到输出的卷积结果上,但是这里在加上输入的时候为什么还要做一个shortcut操作呢?我们来看看shortcut操作是在干什么:
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*planes)
)
这里的shortcut居然是一个空序列!只有当stride和输入图像的通道数满足一定的条件时,Sequential中才会进行一些操作。所以这里代码在layer1中执行num_block[0]个Basic_Block后【根据上面的图可以看出来是两个】,也就运行结束了。
六.特征图升维与降采样操作
layer1我们就此分析结束,下面我们来分析layer2,layer2就很不同了,因为它的in_channel和out_channel是不一样的!
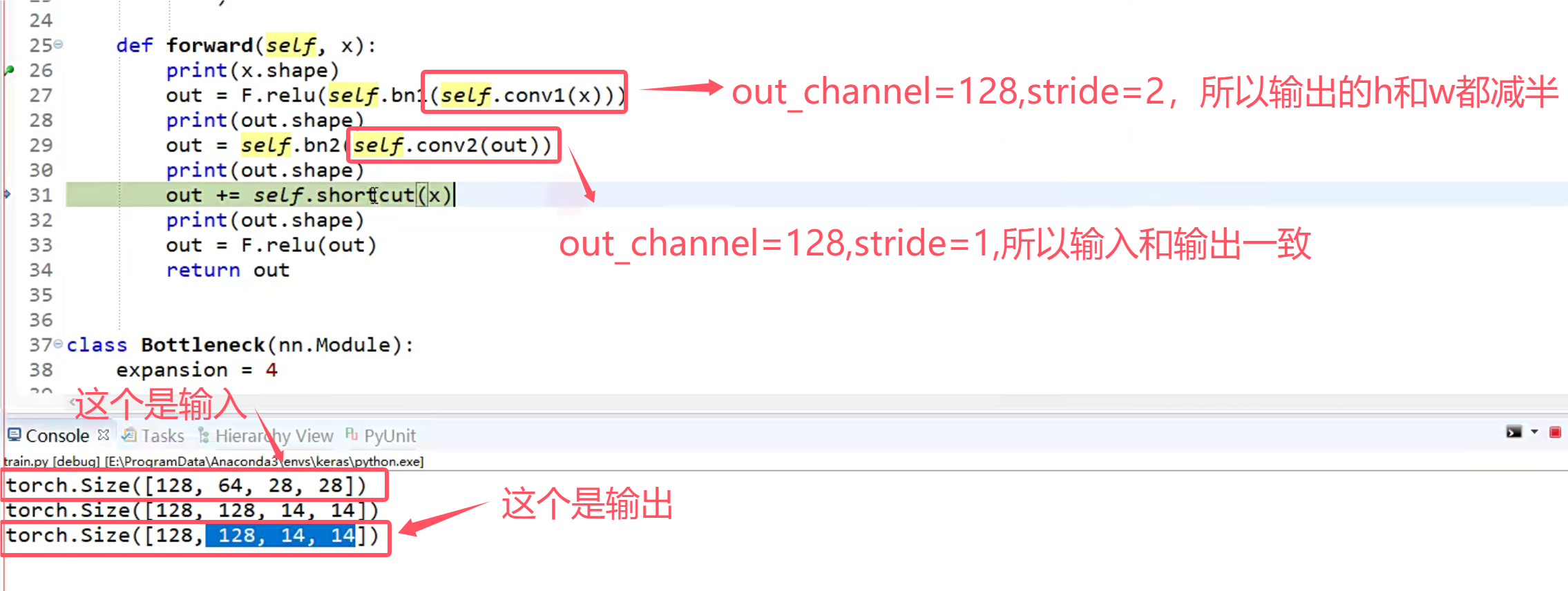
我们发现现在输入和输出的尺寸不一样了,这时候我们应该怎么将输入加到输出上呢?还记得我们之前实现的shortcut函数吗,这个时候就发挥用处啦!
如果stride不为1或者输入的channel和输出的channel不匹配的时候,这里会将之前定义的空的序列替换为一个in_channel为64,out_channel为128,stride=(2,2)的卷积层【升维,下采样】。使得输入与输出可以进行加法运算。这里也对应着下图的操作。
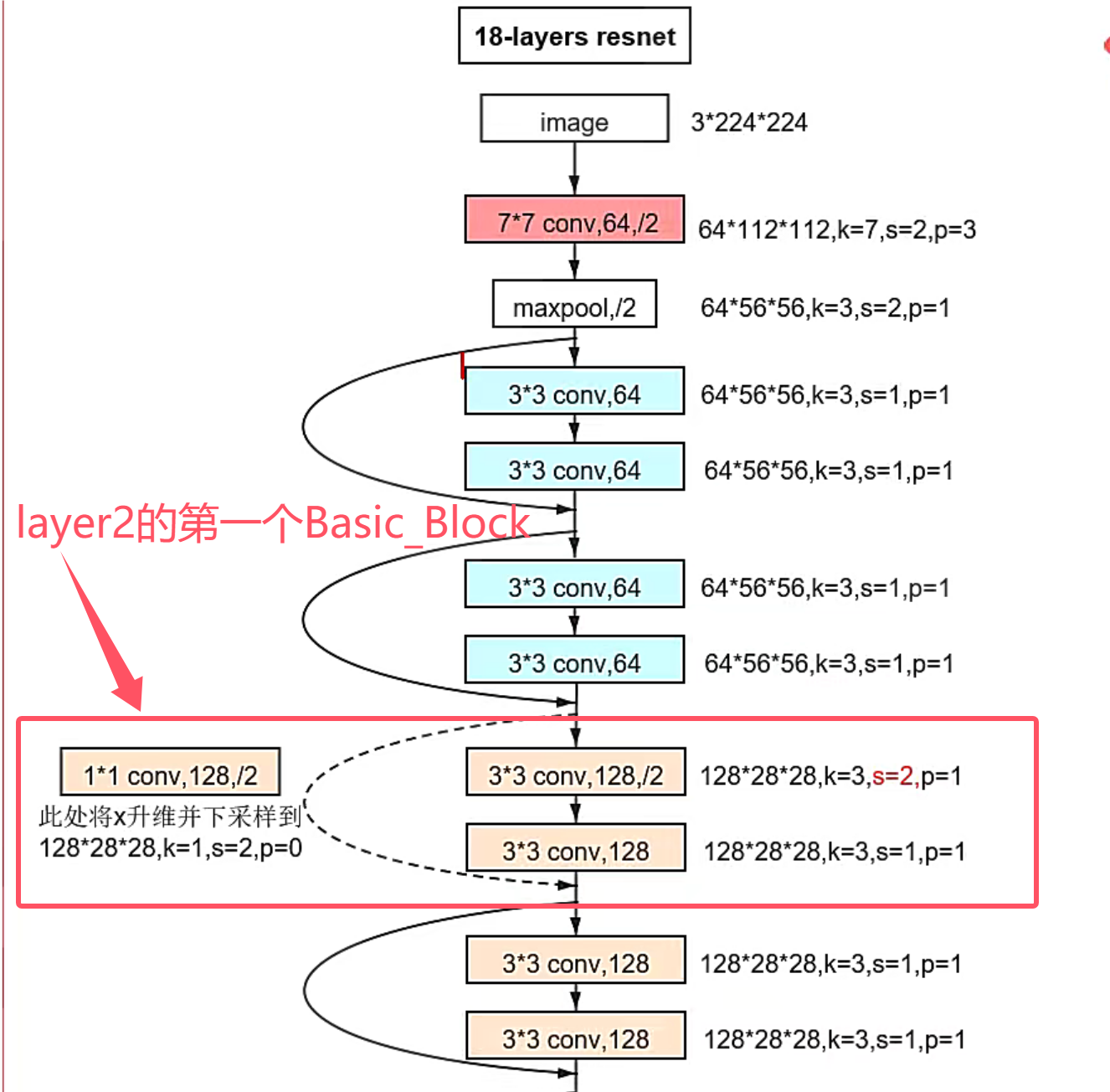
七.网络整体流程与训练演示
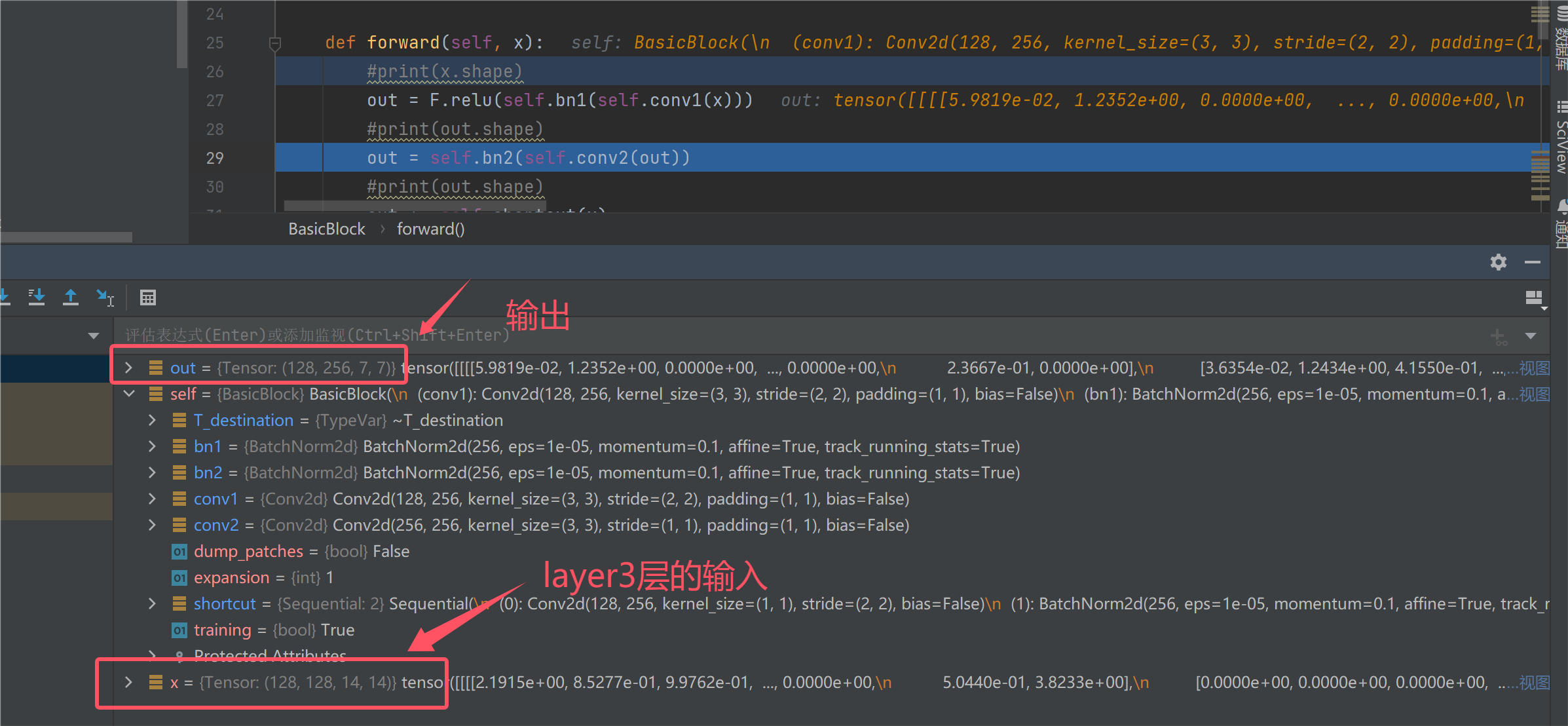
接下来我们继续分析layer3,做法还是跟之前是一样的,这里继续进一步扩大维度然后下采样,通过shortcut连接1*1的卷积,将每一层的输入与输出相加。
最后四层网络都走完了,h和w都下采样变为了1,通过一个View操作拉直:

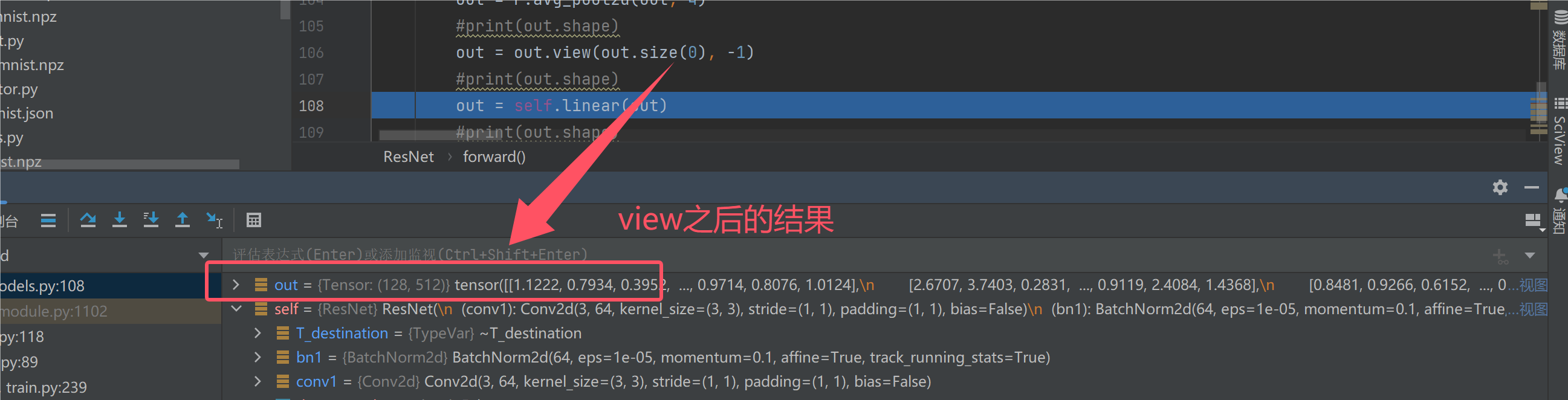
最后通过一个线性层,得到我们的9分类结果:
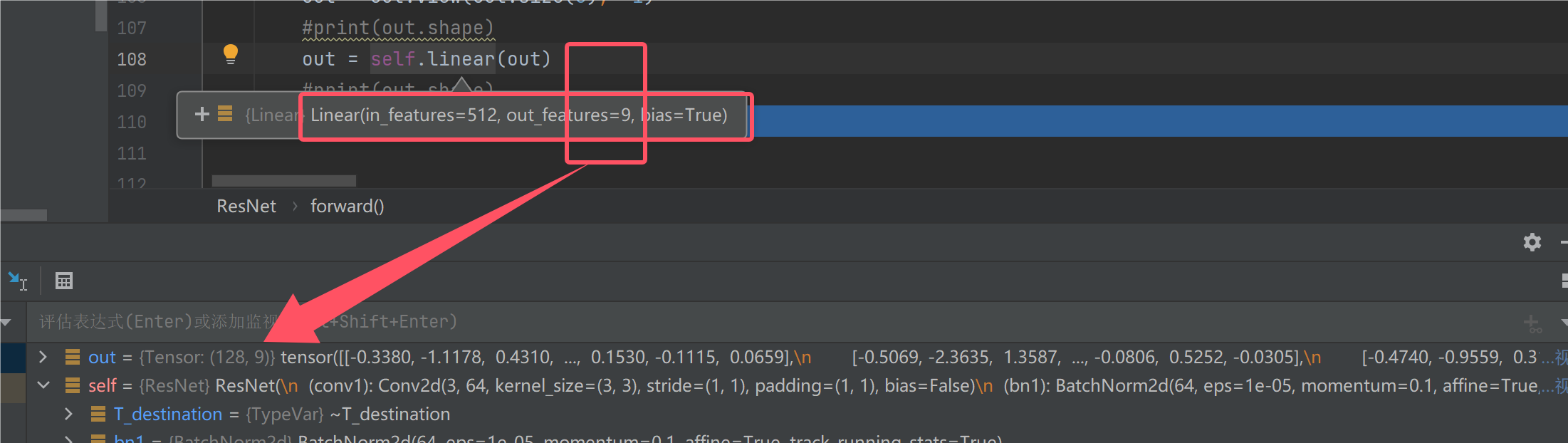
到此我们的网络结果就讲解完了,接下来我们来看训练的步骤:
model.train()
for batch_idx, (inputs, targets) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(inputs.to(device))
if task == 'multi-label, binary-class':
targets = targets.to(torch.float32).to(device)
loss = criterion(outputs, targets)
else:
targets = targets.squeeze().long().to(device)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
我们刚刚将的网络流程全部都在outputs = model(inputs.to(device))这行代码中走完了,接下来就是常规的计算loss,然后反向传播,更新梯度。然后再进行下一批次的训练。主函数中通过按照epoch调用:
for epoch in trange(start_epoch, end_epoch):
train(model, optimizer, criterion, train_loader, device, task)
val(model, val_loader, device, val_auc_list, task, dir_path, epoch)
val部分跟trian部分代码差别不大,只是不用更新梯度了,需要计算一些指标:
model.eval() #进入val模式
y_true = torch.tensor([]).to(device)
y_score = torch.tensor([]).to(device)
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(val_loader):
outputs = model(inputs.to(device))
if task == 'multi-label, binary-class':
targets = targets.to(torch.float32).to(device)
m = nn.Sigmoid()
outputs = m(outputs).to(device)
else:
targets = targets.squeeze().long().to(device)
m = nn.Softmax(dim=1)
outputs = m(outputs).to(device)
targets = targets.float().resize_(len(targets), 1)
y_true = torch.cat((y_true, targets), 0)
y_score = torch.cat((y_score, outputs), 0)
y_true = y_true.cpu().numpy()
y_score = y_score.detach().cpu().numpy()
auc = getAUC(y_true, y_score, task) #计算指标
val_auc_list.append(auc)
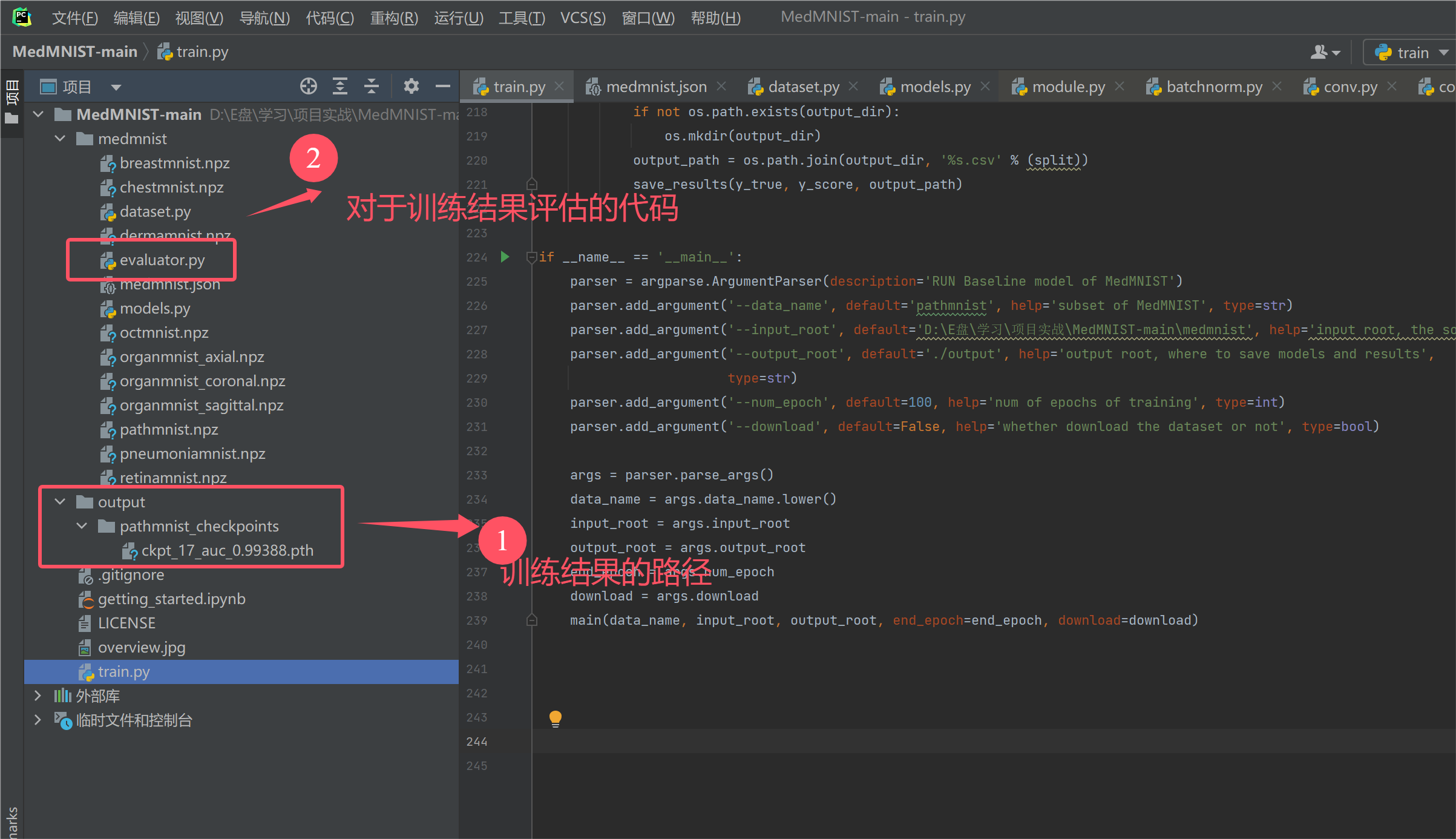
跑完之后,我们就可以拿到训练的结果【每个epoch的结果】,然后打开项目中的evaluator.py,可以对我们的训练结果进行评估。


















 2177
2177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











