







1. GAN概述
GAN包含有两个模型,一个是生成模型,一个是判别模型。
生成模型的任务是生成看起来自然真实的、和原始数据相似的实例。
判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的(真实实例来源于数据集,伪造实例来源于生成模型)。
·结合整体模型图示,再以生成图片作为例子具体说明下面。我们有两个网络,G(Generator)和D(Discriminator)。
·Generator是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
·Discriminator是一个判别网络,判别一张图片是不是“真实的”。它的输入是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
2. GAN模型优化训练
在训练过程中,生成网络的目标就是尽量生成真实的图片去欺骗判别网络D。
网络D的目标就是尽量把网络G生成的图片和真实的图片分别开来。
这样,G和D构成了一个动态的“博弈过程”。
纳什均衡
纳什均衡是指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。对应的,对于GAN,情况就是生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。这是双方网路都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。
GAN模型的目标函数如下

简单理解:对于辨别器,如果得到的是生成图片辨别器应该输出 0,如果是真实的图片应该输出 1,得到误差梯度反向传播来更新参数。对于生成器,首先由生成器生成一张图片,然后输入给判别器判别并的到相应的误差梯度,然后反向传播这些图片梯度成为组成生成器的权重。
直观上来说就是:辨别器不得不告诉生成器如何调整从而使它生成的图片变得更加真实。
基本流程如下:
- 初始化判别器D的参数
和生成器G的参数
。
- 从真实样本中采样 m 个样本 { x1,x2,...x
} ,从先验分布噪声中采样 m 个噪声样本 { z1,z2,...,zm } 并通过生成器获取 m 个生成样本 { x~1,x~2,...,x~m } 。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分正确样本和生成的样本。
- 循环k次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误。
- 多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自于生成器的输出还是真实的输出。亦即最终样本判别概率均为0.5。
Tips: 之所以要训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够教好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。更直观的理解可以参考下图:

图四 生成器判别器与样本示意图
注:图中的 黑色虚线表示真实的样本的分布情况, 蓝色虚线表示判别器判别概率的分布情况, 绿色实线表示生成样本的分布。 Z 表示噪声, Z 到 x 表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在 (a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。
通过多次训练判别器来达到 (b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到 (c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。
经过多次反复训练迭代之后,最终希望能够达到 (d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。
3. 生成器
对于生成器,输入需要一个n维度向量,输出为图片像素大小的图片。因而首先我们需要得到输入的向量。
Tips: 这里的生成器可以是任意可以输出图片的模型,比如最简单的全连接神经网络,又或者是反卷积网络等。这里大家明白就好。
这里输入的向量我们将其视为携带输出的某些信息,比如说手写数字为数字几,手写的潦草程度等等。由于这里我们对于输出数字的具体信息不做要求,只要求其能够最大程度与真实手写数字相似(能骗过判别器)即可。所以我们使用随机生成的向量来作为输入即可,这里面的随机输入最好是满足常见分布比如均值分布,高斯分布等。
Tips: 假如我们后面需要获得具体的输出数字等信息的时候,我们可以对输入向量产生的输出进行分析,获取到哪些维度是用于控制数字编号等信息的即可以得到具体的输出。而在训练之前往往不会去规定它。
class gen(keras.Model):#继承自keras.Model的自定义模型类
def __init__(self):#定义了类的初始化方法
super().__init__();#调用了父类keras.Model的初始化方法
self.layer1 = keras.layers.Dense(7*7*256, use_bias=False)#全连接层,输出节点数为7*7*256,不使用偏置项
self.layer2 = keras.layers.BatchNormalization()#批量归一化层
self.layer3 = keras.layers.LeakyReLU()#LeakyReLU激活层
self.layer4 = keras.layers.Reshape((7, 7, 256))#重塑层,将输入重塑为(7, 7, 256)的形状
self.layer5 = keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)
#转置卷积层,输出通道数为128,卷积核大小为(5, 5),步长为(1, 1),使用"same"填充,不使用偏置项。
self.layer6 = keras.layers.BatchNormalization()
self.layer7 = keras.layers.LeakyReLU()
self.layer8 = keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.layer9 = keras.layers.BatchNormalization()
self.layer10 = keras.layers.LeakyReLU()
self.layer11 = keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
#描述了生成器模型中层的连接方式,将输入逐步通过各个层处理,最终生成输出
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.layer8(x)
x = self.layer9(x)
x = self.layer10(x)
output = self.layer11(x)
return output4. 判别器
对于判别器不用多说,往往是常见的判别器,输入为图片,输出为图片的真伪标签。
Tips: 同理,判别器与生成器一样,可以是任意的判别器模型,比如全连接网络,或者是包含卷积的网络等等
目标函数:

判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性,交叉熵公式如下图6所示:

Tips: 公式中和
为真实的样本分布和生成器的生成分布。
在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开如下

Tips: 其中,假定 y1 为正确样本分布,那么对应的( 1−y1 )就是生成样本的分布。 D 表示判别器,则 D(x1) 表示判别样本为正确的概率, ((1−D(x1)) 则对应着判别为错误样本的概率。这里仅仅是对当前情况下的交叉熵损失的具体化。相信大家也还是比较熟悉。
将上式推广到N个样本后,将N个样本相加得到对应的公式如下:

OK,到目前为止还是基本的二分类,下面加入GAN中特殊的地方。
对于GAN中的样本点 ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本
( 这里的
是服从于投到生成器中噪声的分布)。
其中,对于来自于真实的样本,我们要判别为正确的分布 。来自于生成的样本我们要判别其为错误分布( 1−
)。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让
为 1/2 且使用
表示生成样本可以得到如下图8的公式:

OK,现在我们再回过头来对比原本的的 minGmaxD 公式,发现他们是不是其实就是同一个东西呢!:-D
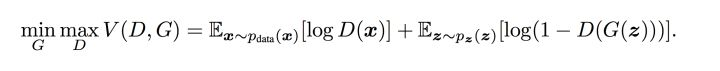
图9 损失函数的min max表达
我们回忆一下上面2.2.3中介绍的流程理解一下这里的 minGmaxD 。
- 这里的 V(G,D相当于表示真实样本和生成样本的差异程度。
- 先看 maxDV(D,G) 。这里的意思是固定生成器G,尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。
- 再将后面部分看成一个整体令 L = maxDV(D,G) ,看 minGL,这里是在固定判别器D的条件下得到生成器G,这个G要求能够最小化真实样本与生成样本的差异。
- 通过上述min max的博弈过程,理想情况下会收敛于生成分布拟合于真实分布。
class dis(keras.Model):
def __init__(self):
super().__init__()
self.layer1 = keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same')
self.layer2 = keras.layers.LeakyReLU()
self.layer3 = keras.layers.Dropout(0.3)#Dropout层,用于随机断开输入神经元,防止过拟合
self.layer4 = keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')
self.layer5 = keras.layers.LeakyReLU()
self.layer6 = keras.layers.Dropout(0.3)
self.layer7 = keras.layers.Flatten()#展平层,用于将输入展平为一维向量
self.layer8 = keras.layers.Dense(1)#全连接层,输出节点数为1,用于二分类
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
output = self.layer8(x)
return output5. GAN的优缺点
优点
- GNs是一种以半监督方式训练分类器的方法
- G的参数更新不是直接来自数据样本,而是使用来自D的反向传播
- 理论上,只要是可微分函数都可以用于构建D和G,因为能够与深度神经网络结合做深度生成式模型
- GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据.
- 模型只用到了反向传播,而不需要马尔科夫链
- 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,因为他们优化对数似然的下界,而不是似然度本身,这看起来导致了VAEs生成的实例比GANs更模糊.
- 相比非线性ICA(NICE, Real NVE等,),GANs不要求生成器输入的潜在变量有任何特定的维度或者要求生成器是可逆的.
- 相比玻尔兹曼机和GSNs,GANs生成实例的过程只需要模型运行一次,而不是以马尔科夫链的形式迭代很多次.
劣势
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多.
- 它很难去学习生成离散的数据,就像文本
- 相比玻尔兹曼机,GANs很难根据一个像素值去猜测另外一个像素值,GANs天生就是做一件事的,那就是一次产生所有像素, 你可以用BiGAN来修正这个特性,它能让你像使用玻尔兹曼机一样去使用Gibbs采样来猜测缺失值,
- 可解释性差,生成模型的分布 Pg(G)没有显式的表达
在这里其实还多了一个我之前没有去了解的一个转置卷积层,我探求了一下卷积层和转置卷积层的区别
转置卷积层(Transpose Convolutional Layer)和卷积层(Convolutional Layer)是神经网络中常用的两种层,它们在实现上有一些不同:
卷积层(Convolutional Layer):
- 卷积层是神经网络中的基本组件之一。
- 通过卷积核(过滤器)在输入图像上进行卷积操作,提取特征信息。
- 在卷积过程中,卷积核与输入图像进行逐元素相乘并求和,从而生成输出特征图。
- 正常的卷积操作会减少输出特征图的尺寸(根据步幅和填充设置)。
- 常用于提取图像的局部特征、边缘、纹理等。
转置卷积层(Transpose Convolutional Layer):
- 也称为反卷积层(Deconvolutional Layer),是卷积的逆操作。
- 转置卷积层可以将输入特征图的尺寸扩大,与普通的卷积层相反。
- 它通过对输入图像进行填充和卷积操作,可以将特征图的尺寸放大,通常用于上采样。
- 转置卷积层的参数(卷积核大小、步幅、填充等)可以调整输出特征图的尺寸。
- 常用于图像分割、图像生成(生成对抗网络中的生成器部分)等任务中,能够扩大特征图的空间维度。
总的来说,卷积层用于从输入提取特征,减小特征图尺寸;转置卷积层则是用于上采样,增大特征图的尺寸。两者在神经网络中有着不同的作用和应用场景。
6.完整代码
import tensorflow as tf
import numpy as np
import time
import os
import time
from tensorflow import keras
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_train = (x_train - 127.5) / 127.5#进行了归一化处理,将像素值缩放到[-1, 1]之间
buffer_size = 60000;#定义了一个缓冲区大小为60000,用于对训练数据进行洗牌操作。
batch_size = 256#定义了批处理大小为256
dataset = tf.data.Dataset.from_tensor_slices(x_train).shuffle(buffer_size).batch(batch_size)
#这行代码将处理后的训练集数据 x_train 转换为 tf.data.Dataset 对象,
#并对数据进行洗牌(shuffle)和批处理(batch)操作,最终得到了一个用于训练的数据集 dataset。
class gen(keras.Model):#继承自keras.Model的自定义模型类
def __init__(self):#定义了类的初始化方法
super().__init__();#调用了父类keras.Model的初始化方法
self.layer1 = keras.layers.Dense(7*7*256, use_bias=False)#全连接层,输出节点数为7*7*256,不使用偏置项
self.layer2 = keras.layers.BatchNormalization()#批量归一化层
self.layer3 = keras.layers.LeakyReLU()#LeakyReLU激活层
self.layer4 = keras.layers.Reshape((7, 7, 256))#重塑层,将输入重塑为(7, 7, 256)的形状
self.layer5 = keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)
#转置卷积层,输出通道数为128,卷积核大小为(5, 5),步长为(1, 1),使用"same"填充,不使用偏置项。
self.layer6 = keras.layers.BatchNormalization()
self.layer7 = keras.layers.LeakyReLU()
self.layer8 = keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.layer9 = keras.layers.BatchNormalization()
self.layer10 = keras.layers.LeakyReLU()
self.layer11 = keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh')
#描述了生成器模型中层的连接方式,将输入逐步通过各个层处理,最终生成输出
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
x = self.layer8(x)
x = self.layer9(x)
x = self.layer10(x)
output = self.layer11(x)
return output
class dis(keras.Model):
def __init__(self):
super().__init__()
self.layer1 = keras.layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same')
self.layer2 = keras.layers.LeakyReLU()
self.layer3 = keras.layers.Dropout(0.3)#Dropout层,用于随机断开输入神经元,防止过拟合
self.layer4 = keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same')
self.layer5 = keras.layers.LeakyReLU()
self.layer6 = keras.layers.Dropout(0.3)
self.layer7 = keras.layers.Flatten()#展平层,用于将输入展平为一维向量
self.layer8 = keras.layers.Dense(1)#全连接层,输出节点数为1,用于二分类
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
x = self.layer7(x)
output = self.layer8(x)
return output
#创建了一个二分类交叉熵损失函数的实例,设置from_logits=True表示输入的预测输出是经过 Sigmoid 函数处理之前的结果。
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output);
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output);
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
#创建了一个Adam优化器实例,用于优化生成器模型的参数。学习率设置为1e-4
generator_optimizer = keras.optimizers.Adam(1e-4)
discriminator_optimizer = keras.optimizers.Adam(1e-4)
generator = gen()
discriminator = dis()
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir,"ckpt");
checkpoint = tf.train.Checkpoint(generator_optimizer = generator_optimizer,
discriminator_optimizer = discriminator_optimizer,
generator = generator,
discriminator = discriminator)
Epochs = 50
noise_dim = 100
num_example_to_generate = 16
seed = tf.random.normal([num_example_to_generate, noise_dim]);
@tf.function()
def train_step(images):
noise = tf.random.normal([batch_size, noise_dim])# 生成噪声输入
with tf.GradientTape() as gen_tape, tf.GradientTape() as dis_tape:
generator_images = generator(noise, training = True)
real_output = discriminator(images)
fake_output = discriminator(generator_images)
gen_loss = generator_loss(fake_output)
dis_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)# 计算生成器的梯度
gradients_of_discriminator = dis_tape.gradient(dis_loss, discriminator.trainable_variables)# 计算判别器的梯度
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))# 使用生成器优化器来更新生成器参数
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))# 使用判别器优化器来更新判别器参数
#生成并保存生成器模型在给定输入上的图像预测结果
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training = False)
fig = plt.figure(figsize = (4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)# 保存模型的 checkpoint
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
generate_and_save_images(generator,
epoch,
seed)
train(dataset, Epochs)
7.对模型进行修改
生成器模型修改
·添加一个的卷积层、一个批量归一化层和一个激活层。(添加在第二个转置卷积层后面)
self.layer8 = keras.layers.Conv2DTranspose(128, (5, 5), strides=(2, 2), padding='same', use_bias=False)
self.layer9 = keras.layers.BatchNormalization()
self.layer10 = keras.layers.LeakyReLU()增加的卷积层,输出128个特征图,使用5x5的卷积核进行卷积操作,步幅为2,padding为'same',不使用偏置。批量归一化层和LeakyReLU激活层和原始模型里的一样,没有做改变。
增加的卷积层有助于捕获更多数据特征,提高生成图像的质量和多样性。批量归一化层和LeakyReLU激活层的增加有助于加速训练过程并稳定模型训练。
判别器模型修改
self.layer4 = keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same', kernel_regularizer=regularizers.l2(0.01))在原始模型的第二个卷积层,增加了正则化项,在这一层的权重矩阵中的每个系数都将受到L2正则化的约束。这个约束将会增加在损失函数中,由0.01乘以权重的平方和组成。
有助于防止模型过度拟合训练数据,使其更倾向于学习简单的模式,并且对大权重值进行惩罚。正则化有助于改善模型的泛化能力。
self.layer7 = keras.layers.Conv2D(256, (5, 5), strides=(2, 2), padding = 'same', kernel_regularizer = regularizers.l2(0.01))
self.layer8 = keras.layers.LeakyReLU()
self.layer9 = keras.layers.Dropout(0.3)在展开层前添加了一个卷积层,输出64个特征图,使用大小为5x5的卷积核进行卷积操作。步幅为2,padding为'same',当然这一卷积层也加了正则化,扩增了模型的复杂度,有助于捕获更多数据特征,提高判别器的性能。LeakyReLU激活层的增加有助于避免神经元饱和问题,进而改善梯度流和模型收敛性。

ps:本人未对生成对抗网络做更深入的了解,只限于完成老师的作业,上述为乱七八糟的一些我四处搜罗的内容,有错误请别介意















 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









