







Efficient Memory Management for Large Language Model Serving with PagedAttention

前言
本篇要看到论文是Efficient Memory Management for Large Language Model Serving with PagedAttention,这篇论文主要是介绍PagedAttention技术,想了解这个技术,所以从这篇文献开始看
这个技术直接去了解,其实对他的介绍是采用虚拟内存的分页技术,减少内存碎片的产生,把内存中的内存碎片充分利用起来,从而提升内存使用率。这个是我目前的了解,希望看完这篇文献能有更好的理解。
这个论文是有开源代码的,在github上。
摘要
大型语言模型(llm)的高吞吐量服务需要一次批处理足够多的请求。然而,现有的系统很困难,因为每个请求的键值缓存(KV缓存)内存很大,并且动态地增长和缩小。当管理效率低下时,这些内存可能会被碎片和冗余复制严重浪费,从而限制了批处理大小。为了解决这个问题,我们提出了PagedAttention,这是一种受操作系统中经典虚拟内存和分页技术启发的注意力算法。在此基础上,我们构建了vLLM,这是一个LLM服务系统,它实现了(1)KV缓存几乎为零的浪费,(2)在请求内部和请求之间灵活地共享KV缓存,以进一步减少内存使用。我们的评估表明,与FasterTransformer和Orca等最先进的系统相比,在相同的延迟水平下,vLLM将流行llm的吞吐量提高了2-4倍。对于更长的序列、更大的模型和更复杂的解码算法,改进更加明显。vLLM的源代码可在https://github.com/vllm-project/vllm上公开获得。
论文解决的问题:KV缓存在内存方面存在内存可能会被碎片和冗余复制严重浪费,从而限制了批处理大小的问题。
核心思想:提出了PagedAttention,这是一种受操作系统中经典虚拟内存和分页技术启发的注意力算法。在此基础上,我们构建了vLLM,这是一个LLM服务系统,它实现了(1)KV缓存几乎为零的浪费,(2)在请求内部和请求之间灵活地共享KV缓存,以进一步减少内存使用。
实验结果:与最先进的系统相比,在相同的延迟水平下,vLLM将流行llm的吞吐量提高了2-4倍。对于更长的序列、更大的模型和更复杂的解码算法,改进更加明显。
引言
想增加LLM的吞吐量
像GPT[5,37]和PaLM[9]这样的大型语言模型(llm)的出现使编程助理[6,18]和通用聊天机器人[19,35]等新应用成为可能,它们开始深刻地影响我们的工作和日常生活。许多云计算公司[34,44]正在竞相提供这些应用程序作为托管服务。然而,运行这些应用程序是非常昂贵的,需要大量的硬件加速器,如gpu。根据最近的估计,处理LLM请求的成本可能是传统关键字查询的10倍[43]。考虑到这些高成本,增加LLM服务系统的吞吐量(从而降低每个请求的成本)变得更加重要。
llm的核心是自回归的Transformer模型,所以想优化的是自回归部分,对这部分提出优化问题
llm的核心是自回归的Transformer模型[53]。该模型基于输入(提示)和迄今为止生成的输出标记的前一个序列,一次生成一个单词(标记)。对于每个请求,重复这个昂贵的过程,直到模型输出一个终止令牌。这种顺序生成过程使工作负载受到内存限制,使gpu的计算能力得不到充分利用,并限制了服务吞吐量。
由图可知,模型权重是恒定的,并且激活仅占用GPU内存的一小部分,因此管理KV缓存的方式对于确定最大批大小至关重要,故最终优化目标优化kv cache。
通过将多个请求批处理在一起,可以提高吞吐量。但是,为了批量处理许多请求,应该有效地管理每个请求的内存空间。例如,图1(左)说明了在具有40GB RAM的NVIDIA A100 GPU上13b参数LLM的内存分布。大约65%的内存分配给模型权重,这些权重在服务期间保持静态。接近30%的内存用于存储请求的动态状态。对于transformer,这些状态由与注意力机制相关的键和值张量组成,通常被称为KV缓存[41],它表示来自早期令牌的上下文,以按顺序生成新的输出令牌。剩余的一小部分内存用于其他数据,包括激活——在评估LLM时创建的短暂张量。由于模型权重是恒定的,并且激活仅占用GPU内存的一小部分,因此管理KV缓存的方式对于确定最大批大小至关重要。当管理效率低下时,KV高速缓存可以显著限制批处理大小,从而限制LLM的吞吐量,如图1(右)所示。

现有的LLM服务系统无法有效地管理KV缓存,因为它们需要连续的存储空间。
KV缓存具有独特的特征:随着模型生成新的令牌,它会随着时间的推移动态增长和缩小,并且它的生命周期和长度是未知的。
在本文中,我们观察到现有的LLM服务系统[31,60]无法有效地管理KV缓存。这主要是因为它们将请求的KV缓存存储在连续内存空间中,因为大多数深度学习框架[33,39]要求将张量存储在连续内存中。然而,与传统深度学习工作负载中的张量不同,KV缓存具有独特的特征:随着模型生成新的令牌,它会随着时间的推移动态增长和缩小,并且它的生命周期和长度是未知的。这些特点使得现有系统的方法在两个方面效率低下:
首先,现有系统[31,60]受到内部和外部内存碎片的影响。为了在连续空间中存储请求的KV缓存,它们预先分配了一个具有请求最大长度的连续内存块(例如,2048个令牌)。这可能导致严重的内部碎片,因为请求的实际长度可能比它的最大长度短得多(例如,图11)。此外,即使预先知道实际长度,预分配仍然是低效的:由于在请求的生命周期内保留了整个块,其他较短的请求不能利用当前未使用的块的任何部分。此外,外部内存碎片也很重要,因为每个请求的预分配大小可能不同。事实上,我们在图2中的分析结果显示,在现有系统中,只有20.4% - 38.2%的KV缓存内存用于存储实际令牌状态。
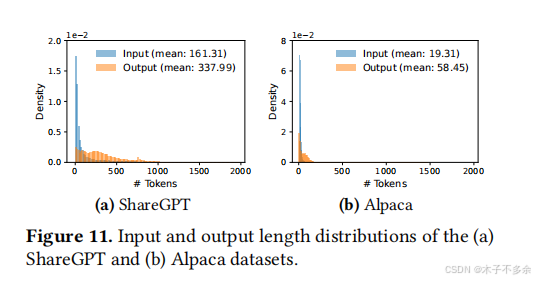
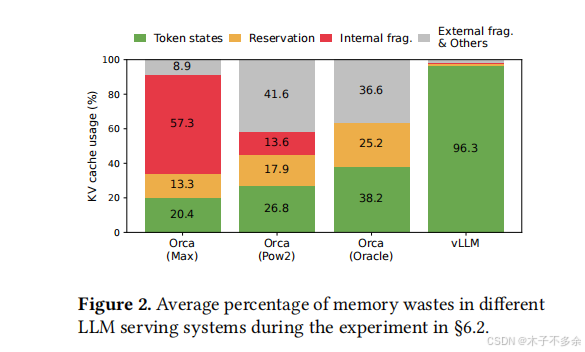
其次,现有系统无法利用内存共享的机会。LLM服务通常使用高级解码算法,例如并行采样和波束搜索,每个请求生成多个输出。在这些场景中,请求由多个序列组成,这些序列可以部分共享它们的KV缓存。然而,在现有系统中,内存共享是不可能的,因为序列的KV缓存存储在单独的连续空间中。
pagedAttention 最终的目标是解决了内部碎片和外部碎片和内存共享
为了解决上述限制,我们提出了PagedAttention,这是一种注意力算法,灵感来自于操作系统(OS)对内存碎片和共享的解决方案:带分页的虚拟内存。PagedAttention将请求的KV缓存划分为块,每个块可以包含注意键和固定数量令牌的值。在PagedAttention中,KV缓存的块不一定存储在连续的空间中。 因此,我们可以像在OS的虚拟内存中那样更灵活地管理KV缓存:可以将块视为页面,令牌视为字节,请求视为进程。这种设计通过使用相对较小的块并按需分配来减轻内部碎片。此外,它消除了外部碎片,因为所有块都具有相同的大小。最后,它支持以块粒度、跨与相同请求关联的不同序列甚至跨不同请求共享内存。
vLLM里面有PagedAttention技术和块级内存管理和抢占式请求调度。
在这项工作中,我们在PagedAttention的基础上构建了一个高吞吐量的分布式LLM服务引擎vLLM,它在KV高速缓存中实现了接近零的浪费。vLLM使用与PagedAttention共同设计的块级内存管理和抢占式请求调度。vLLM支持GPT[5]、OPT[62]、LLaMA[52]等流行的llm,支持不同大小的llm,包括超过单个GPU内存容量的llm。我们对各种模型和工作负载的评估表明,与最先进的系统相比,vLLM将LLM服务吞吐量提高了2-4倍[31,60],而完全不影响模型的准确性。对于更长的序列、更大的模型和更复杂的解码算法,改进更加明显(§4.3)。
总之,我们做出了以下贡献:
阐述了大模型的内存分配时候存在的问题,提出PagedAttention,设计实现建立在PagedAttention之上的分布式LLM服务引擎vllm,评估vllm性能.
•我们确定了在服务llm时内存分配的挑战,并量化了它们对服务性能的影响。
•受操作系统中虚拟内存和分页的启发,提出了一种基于非连续分页内存中KV缓存的注意力算法PagedAttention。
•我们设计并实现了vLLM,一个建立在PagedAttention之上的分布式LLM服务引擎。
•我们在各种情况下评估了vLLM,并证明它大大优于以前的最先进的解决方案,如FasterTransformer[31]和Orca[60]。
背景
在本节中,我们描述了典型LLM的生成和服务过程,以及LLM服务中使用的迭代级调度。
基于Transformer的大型语言模型
语言建模的任务是为一系列标记(𝑥1, … , 𝑥𝑛)的概率建模。由于语言具有自然的序列排序,因此通常将整个序列的联合概率分解为条件概率的乘积(又称自回归分解 [3]):
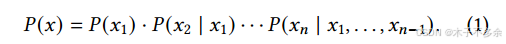
Transformers [53] 已成为对上述概率进行大规模建模的事实上的标准架构。基于Transformer的语言模型最重要的组成部分是其自注意层。对于输入的隐藏状态序列(𝑥1, … , 𝑥𝑛 )∈ R𝑛×𝑑 ,自注意层首先对每个位置 𝑖 进行线性变换,以获得查询、键和值向量:
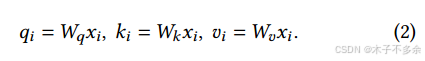
然后,自我关注层通过将一个位置上的查询向量与它之前的所有关键向量相乘,计算出关注度得分 𝑎𝑖𝑗 ,并将输出𝑜𝑖 作为值向量的加权平均值:
a构成的矩阵叫做关注得分矩阵,a*v得到的是加权注意力矩阵
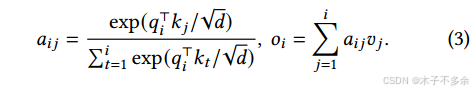
这段话想强调Transformer模型中各个部分的独立性和模块化结构
除了公式 4 中的计算之外,Transformer 模型中的所有其他部分,包括嵌入层、前馈层、层归一化 [2]、残差连接 [22]、输出对数计算以及公式 2 中的查询、键和值转换,都是以 𝑦𝑖 = 𝑓 (𝑥𝑖) 的形式独立应用的。
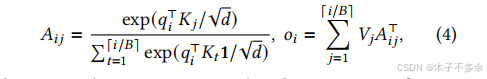
LLM 服务与自回归生成
一旦经过训练,LLM 通常会被部署为条件生成服务(例如,完成 API [34] 或聊天机器人 [19,35])。向 LLM 服务发出的请求会提供一个输入提示标记列表(𝑥1, … , 𝑥𝑛),LLM 服务会根据公式 1 生成一个输出标记列表(𝑥n+1 … , 𝑥n+T )。我们将提示列表和输出列表的连接称为序列。
由于公式 1 中的分解,LLM 只能逐个采样并生成新令牌,而每个新令牌的生成过程都取决于该序列中之前的所有令牌,特别是它们的键和值向量。在这种顺序生成过程中,现有令牌的键和值向量通常会被缓存起来,以便生成未来的令牌,这就是所谓的 KV 缓存。请注意,一个令牌的 KV 缓存取决于它之前的所有令牌。这意味着,出现在序列中不同位置的同一令牌的 KV 缓存会有所不同。
给定一个请求提示,LLM 服务中的生成计算可分解为两个阶段:
提示阶段
将整个用户提示 (𝑥1, . . . , 𝑥𝑛) 作为输入,并计算第一个新标记 𝑃 (𝑥𝑛+1 | 𝑥1, . . . , 𝑥ǔ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









