







Hugging face 是什么
Hugging Face 是一个专注于自然语言处理(NLP)和人工智能(AI)的开源社区和平台。它提供了多个工具和库,最著名的是 Transformers 库,里面包含了许多预训练的模型,如 BERT、GPT、T5 等,可以用于文本生成、分类、翻译等多种任务。
此外,Hugging Face 还提供了 Model Hub,用户可以分享和下载各种模型,以及 Datasets Hub,用于管理和共享数据集。Hugging Face 还推动了对大语言模型的研究和应用,致力于使 AI 技术更易于访问和使用。
Hugface 怎么跑
大模型评估指标
要进行大模型评估,首先需要查看开源大模型的官网,看看开源大模型给出了哪些评估指标数据。一般可以在github官网上看到用了多个数据集对此大模型进行了评估,比如下面这个图。
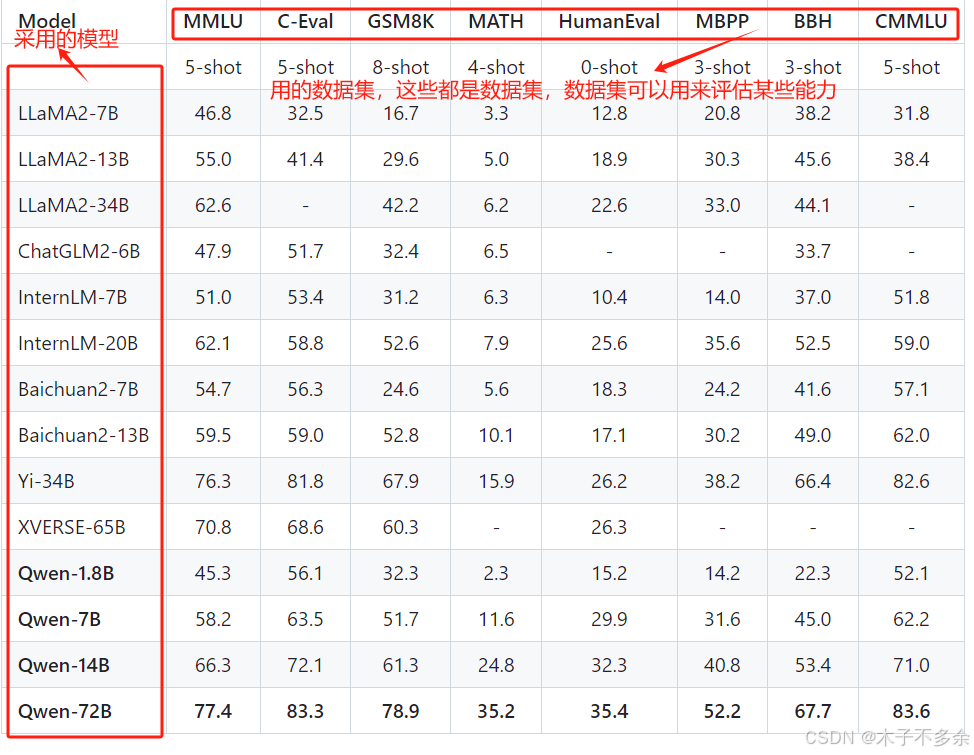
可能是把数据集当作评估指标了?
来看看评估指标含义。

数据集可以看作一个评估基准,去评估模型的某些能力,如推理能力、数学能力、代码生成能力等。

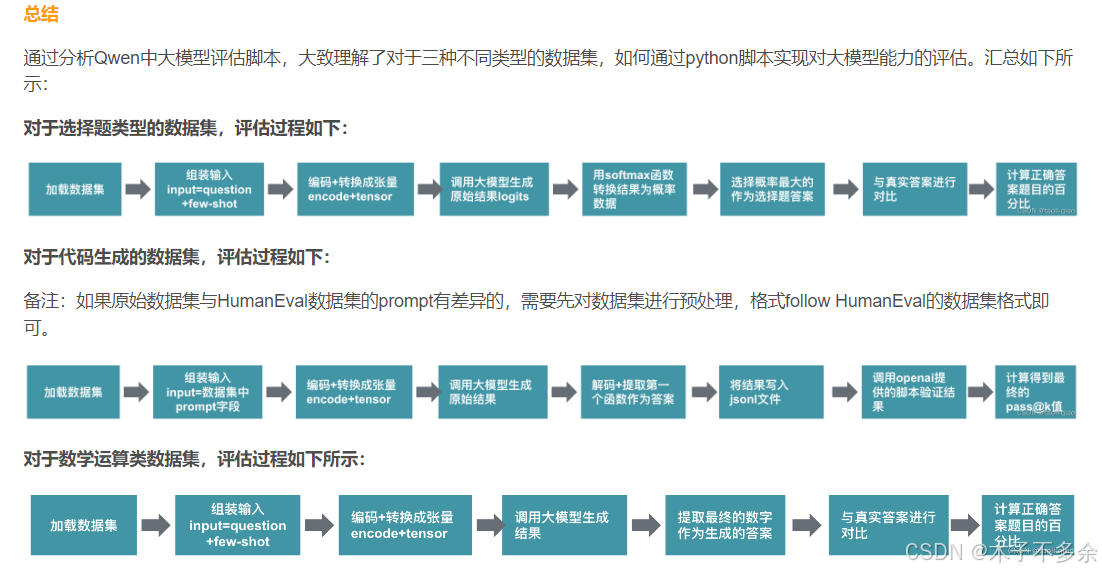
从源代码实现层面浅析如何通过python脚本调用LLM生成这些指标
详细可以看这篇博客,讲的很详细 https://blog.csdn.net/qiaotl/article/details/135013824
用MT-bench评估大模型
上面的数据集都找到了一种方式来评估LLM生成的内容是否正确,但是如果是针对开放性问题,就无法评估LLM的能力。比如让LLM写一篇优美的作文,写一封措辞友好的email等。这类问题,无法通过选择题来做标准数据集,在实际应用中,很多下游任务往往是这种更贴近人类的开放性问题任务,他不会是做一个选择题或者数学题。对于这类任务,MT-Bench评估方法就是解决该类问题的。
MT-Bench是一个专门用于评估大模型能力的测试框架,它涵盖了写作、角色扮演、推理、数学、编码、人文、提取以及STEM(科学、技术、工程、数学)等8个不同领域的问题。这些问题旨在全面考察大模型在各个方面的表现。
MT-Bench评估方法采用的数据集包含了多个类型的问题,每个问题下都有相应的prompt和reference(标准答案)。这些数据集的设计旨在模拟真实世界中的场景,以检验大模型在实际应用中的能力。具体来说,MT-Bench中的数据集不仅要求大模型能够准确理解问题并给出合理答案,还要求其能够处理复杂情境下的多轮对话。


最终,由于电脑配置不高,死活跑不起来,只能了解了解概念,运行不了。
等以后跑起来了在重新补充这部分内容

















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









