






 本文全面介绍目标检测技术,涵盖传统方法、基于深度学习的单阶段和两阶段算法,以及基于Transformer的检测方法。分析各算法优缺点,如传统算法受背景影响大,单阶段速度快但定位弱,两阶段定位准但速度慢。还提及常用数据集和评价指标,如检测速度、准确率等。
本文全面介绍目标检测技术,涵盖传统方法、基于深度学习的单阶段和两阶段算法,以及基于Transformer的检测方法。分析各算法优缺点,如传统算法受背景影响大,单阶段速度快但定位弱,两阶段定位准但速度慢。还提及常用数据集和评价指标,如检测速度、准确率等。
目录
3.1 作为Neck的Transformer目标检测方法... 8
3.2 作为Backbone的Transformer目标检测方法... 9
1 传统目标检测
传统的目标检测算法通常分为两个主要阶段:目标区域提取和目标分类。
在目标区域提取阶段,传统算法通常使用一些手工设计的特征提取方法来寻找图像中可能存在目标的候选区域。常用的特征包括梯度方向直方图(Histogram of Oriented Gradients,HOG)、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)和积分图像特征(Integral Image Feature)。这些特征能够通过计算图像中的梯度,边缘和纹理等信息来表示图像中不同位置的特征。
目标分类阶段,传统算法采用一些机器学习算法来对候选区域进行分类,判断其是否为目标。常用的分类器包括支持向量机(Support Vector Machine,SVM)、决策树和随机森林等。这些分类器使用提取得到的特征作为输入,通过训练样本的标签信息进行学习,以建立目标和非目标之间的分类边界。
传统目标检测算法的主要缺点是它们通常需要手工设计的特征提取方法,并且在复杂的背景下容易受到光照、尺度变化和遮挡等因素的影响,导致检测性能有限。此外,这些算法对于多尺度目标检测和物体姿态变化的处理能力较弱。
然而,传统目标检测算法仍然具有一定的应用价值,尤其在计算资源受限或需要快速实时检测的场景下。近年来,随着深度学习的发展,基于深度学习的目标检测算法如Faster R-CNN、YOLO和SSD等已经取得了显著的性能提升,并成为当前主流的目标检测方法。
2 基于深度学习的目标检测
基于深度学习的目标检测算法可以分为单阶段和两阶段目标检测算法。
2.1 单阶段目标检测
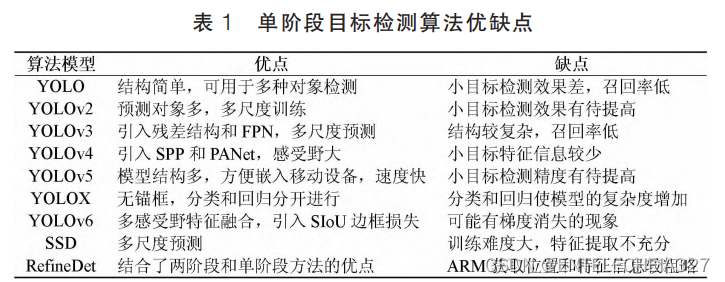
单阶段目标检测算法通过卷积网络提取图像的高级特征,再对特征图进行融合处理,然后完成对目标的定位。目前单阶段检测算法主要包括 YOLO 系列、SSD[Wei Liu et al. SSD: Single Shot MultiBox Detector (ECCV) 2016]和 RefineDet[Shifeng Zhang et al. Single-shot Refinement Neural Network for Object Detection (IEEE CCVPR) 2018]算法,在检测领域具有很高的应用价值。
2.1.1 YOLO系列
YOLO:
2015 年,Redmon J 等[Joseph Redmon et al. You Only Look Once: Unified, Real-Time Object Detction (IEEE CVPR) 2016]提出 YOLO 算法,其整体思想是将一整张图像分成 S*S 个网格,如果这个网格存在着预测物体的中心位置,就由这个网格进行预测,并且每个网格会产生多个边界框, 但在训练期间每个边界框只能选择一个对象预测, 这就导致一个网格内有多个物体时难以检测,使目标的检测精度受到限制,但大大提高了检测速度。
YOLOv2:
2017年,考虑到YOLO算法定位不够准确等问题,Redmon J又提出了YOLOv2[Joseph Redmon et al. YOLO9000: Better, Faster, Stronger (IEEE CCVPR) 2017],该算法采用Darknet-19网络,采用了一系列设计决策提高速度和精度,主要包括:批量标准化(BN层)稳定模型训练、设计高分辨分类器,让网络更好地适应高分辨输入、引入多尺度训练以提升检测精度;采用K-Means对目标框进行聚类,使模型更好地训练学习。YOLOv2提供了更好的模型选择灵活性,将检测对象延伸到了9000个,因此称之为YOLO9000
YOLOv3:
2018年,Redmon J又提出了YOLOv3[Joseph Redmon et al. Yolov3: An incremental improvement],该算法采用Darknet-53为特征提取网络。在网络中加入ResNet[KaiMing He et al. Deep Redidual Learning for Image Recognition (IEEE CCVPR) 2016]残差网络连接,降低了网络带来的梯度负面影响;并结合FPN[Tsung-Yi Lin et al. Feature pyramid networks for objection detection (IEEE CCVPR) 2017]的思想将深浅尺度的特征图融合,以提取更丰富的特征;采用K-Means聚类先验框,利用三个不同尺度的特征图来预测边界框,由于多尺度预测的优势,可以更多地检测小物体,但在中大型物体上的性能相对较差。
YOLOv4:
2020年,Bochkovskiy A发表了YOLOv4[Alexey Bochkovskly et al. Yolov4: Optimal speed and accuracy of object detection 2020],利用CSPNet[Chien-Yao Wang et al. CSPNet: A New Backbone that can Enhance Learning Capability Of CNN (IEEE CCVPR) 2020]构建了CSP Darknet-53网络,结构模型由Backbone、Neck和Head三部分组成。
其中Backbone包含了1个CBM和5个CSP模块,Mish激活函数弥补了非线性能力消失的问题,CSP是跨阶段局部网络,能实现丰富的梯度组合。Neck网络中使用SPPNet[KaiMing He et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (IEEE) 2015]结构增大感受野和PANet[Shu Liu et al. Path Aggregation Network for Instrance Segmentation (IEEEE CCVPR) 2018]路径聚合结构,SPP结构使用三种尺度的卷积核对输入特征层进行最大池化,提取更多的上下文信息;PANet通过融合自底向上和自顶向下两条路径提取的特征层,增强主干网络的表征能力。Head模块是一个解码的过程,可以预测多个尺度的物体,使用K-Means聚类9个尺寸的先验框,并采用非极大值抑制冗余的框。该算法在训练时采用了mosaic数据增强丰富数据集、Label Smoothing标签平滑和CioU[Zhao Hui Zheng et al. Distance loU Loss: Faster anf Better Learning for Bounding Box Regression (AAAI) 2020]损失函数,CIoU考虑了预测框与真实框的中心距离、尺度等影响检测效果的因素,使得目标框回归更加稳定。
YOLOv5:
YOLOv5主要由Backbone、Neck和输出端三部分组成。YOLOv5的Backbone主要采用C3结构作为特征提取网络,将输入沿通道分割成两部分,一部分直接进行特征提取,一部分通过残差网络(Resunit)后与另一部分提取的特征输出级联;接着对提取的特征利用最大池化进行特征提取,使网络的感受野提高。YOLOv5的Neck采用了FPN和PANet结构,FPN通过上采样传递和融合高层特征信息,PANet可以增加低层特征信息,两种结构组合增强了对不同尺度物体的检测能力,实现了局部特征和全局特征的融合,最后得到三个新的特征层。输出层是网络的预测部分,将三个尺度的特征层映射到原图像,生成原图像中目标的预测边界框和类别。YOLOv5在训练时使用了mosaic数据增强丰富图像的信息;针对不同训练集设计不同的锚框和自适应的将图片缩放为统一尺寸。
YOLOX:
2021年,旷视科技提出了YOLOX[Zheng Ge et al. Yolox: Exceeding Yolo Series in 2021],使用SiLU激活函数,加入Focus结构扩充通道,进行不丢失信息的下采样。在以前YOLO系列的算法中,分类回归是在卷积中同时进行的,YOLOX认为给网络带来了影响,因此YOLOX将分类和回归分为两部分进行预测;YOLOX还使用mosaic和mixup两种数据增强策略,采用anchor free方式直接对预测框参数进行预测,提高模型泛化性;在为目标设定样本数量时,改进了OTA[Zheng Ge et al. OTA: Optimal Transport Assignment for Object Detection (IEEE CCVPR) 2021]方式,采取SimOTA自动分析目标需要的正样本数量,避免产生额外参数。
YOLOv6:
2022年,美团视觉智能部研发YOLOv6框架,专注于提高移动端的检测速度。该算法主要在Backbone、Neck、输出层及训练策略等方面进行改进,YOLOv6的Backbone使用比Rep[XiaoHan Ding et al. Erpvgg: Making vgg-style convnets great again (IEEE CCVPR) 2021]更高效的EfficientRep,能够更好地使用GPU训练,并将空间金字塔SPPF结构优化为SimSPPF;Neck也是基于Rep和PANet搭建了Rep-PAN,能在高速推理时拥有较好的多尺度融合能力;而Head将分类和回归分为两部分,在增加两个3x3卷积的同时设计了更为高效的结构,能缓解带来的额外计算开销。YOLOv6考虑到真实框与预测框回归的向量角度,引入SIoU[Zhora Gevorgyan SloU Loss: More Powerful Learning for Bounding Box Regression 2022]新的边框回归损失函数,提高训练速度和回归精度。
2.1.2 SSD
2015年,由W.Liu等提出SSD算法,使用VGG16[Karen SimonYan et al. Very deep convolutional networks for large-scale image recognition 2014]作为骨干网络,不生成候选框,允许在多个尺度上提取特征。SSD算法利用数据增强、定位和置信度损失的加权和来训练模型,速度较快,但训练难度大,导致算法准确率较低。在预测时,SSD针对每个默认边框输出每个类别的分数,同时微调边框使得其能更好地匹配物体的真实框。
2.1.3 RefineDet
2018年,Shifeng Zhang等提出RefineDet检测算法[Shifeng Zhang et al. Single-shot Refinement Neural Network for Object Detection (IEEE CCVPR) 2018],主要由ARM模块、TCB模块和ODM模块组成,ARM网络主要负责细化锚框,减少负样本的比例,并调整锚框的大小和位置,更好地为回归分类提供结果;TCB将ARM输出转换为ODM的输入,实现高层语义信息与低层信息特征融合;RefineDet利用两个阶段的回归,提高了物体检测的精度,实现了端到端的多任务训练。
2.2 两阶段目标检测
2014年,R-CNN搭载着“Region Proposal(候选框)+CNN”提取的分类网络的组合模式出现在大众视野中,这种两阶段目标检测算法以其优秀的准确度给目标检测算法提供了新思路。Two stage(两阶段)目标检测算法将目标检测分为两大部分:候选区域的选取、目标的分类识别。
两阶段目标检测算法的优势在于选取多个候选框可以充分提取目标的特征信息,检测的准确度高,同时可以实现精准定位,但是因为算法模型复杂且分两个步骤进行,所以检测速度较慢。下面简要介绍一些经典的两阶段检测算法以及它们的优缺点。
2.2.1 R-CNN
R-CNN[Girshick R et al. Rich feature hierarchies for accurate object detection and semantic segmentation (IEEE CCVPR) 2014]算法由Girshick等人在2014年提出,它开启了将深度学习运用在目标检测的大门,并为后续该系列检测算法奠定了基础。此后,目标检测算法的实时性与精确度不断提高。R-CNN目标检测算法可分为四个步骤:第一步,利用选择性搜索算法SS(Selective Search)从图像中提取约2000个候选框。第二步,利用深度卷积神经网络提取各候选框的函数向量。第三步,用AlexNet将各个函数向量发送给各个向量机(SVM),判断是否属于此类。第四步,使用边界框的回归和非极大值抑制算法来获得候选的最佳框。虽然该算法大幅提高了平均精确度,但是因为需要对2000个候选框进行特征提取,所以检测速度较慢。针对此问题,He等人在2015年提出了SPP-Net[He K et al. Spatial pyramid pooling in deep convolutional networks for visual recognition (IEEE)]算法。
2.2.2 SPP-Net
因为R-CNN算法只能对固定大小的图像进行卷积运算,这就会导致特征信息损失和运算速度慢的问题出现。为了解决R-CNN算法提取特征操作冗长的问题,He等人在2015年提出了SPP-Net算法。SPP-Net算法同样大致分为四个步骤:第一步,采用SS(Selective Search)方法让一张图片生成2000个候选区域;第二步,利用空间金字塔池化(Spatial Pyramid Pooling, SPP)操作,把每个候选区域对应的特征转换成固定长度的特征;第三步,输入全连接层;第四步,进行后续SVM的分类和回归。SPP-Net算法通过引入SPP来避免重复进行卷积运算,在保证同样或者更好的检测精度的同时,极大地提升了检测速度,相比R-CNN算法快24~102倍。首先,训练还处于多个阶段,接下来,SPP-Net只对完全连接的层进行了微调,忽略了之前的所有层,添加池化层后,网络只更新下面的完整连接层,忽略了以前层数对模型的影响,从而降低了检测精度。为了解决R-CNN和SPP网络的缺点,Girshick等人在2015年提出了Fast R-CNN算法。
2.2.3 Fast R-CNN
Fast R-CNN[Girshick R. Fast r-cnn (IEEE) 2015]是对R-CNN算法的改进,在卷积计算部分使用VGG16网络代替AlexNet网络,并且融合了SPP-net的思想,将网络的SPP层设计成为单独的一层,即ROI(Region of Interesting) Pooling层,进一步解决了权值更新的问题。该算法引入SVD(Singular Value Decomposition)对全连接层进行分解,使得处理一张图片的速度明显提升。Fast R-CNN将卷积神经网络提取的特征存储在显存中,减少了对磁盘空间的占用,提高了训练性能,加快了训练速度。同时在网络中加入多任务损失函数边框回归,整个训练过程仅包括候选区域提取和CNN训练两个阶段。但是,该算法存在一些缺陷。它仍然使用SS(Selective Search)方法来选择候选区域,这一步仍然会有大量的计算。Fast R-CNN虽然成功地融合了R-CNN和SPP-Net的优点,但仍然无法实现端到端的目标检测。例如,不能同时获得候选区域,速度仍有提高的空间。
2.2.4 Faster R-CNN
针对以上网络存在的不足,在Fast R-CNN之后不久,Ren等人在2015年提出了Faster R-CNN[Ren S et al. Faster r-cnn:Towards real-time object detection with region proposal networks (2015)]算法。Faster R-CNN是第一个接近实时的深度学习检测算法。Faster R-CNN的主要贡献是引入了区域生成网络(Region Proposal Networks,RPN),代替Selective Search算法。尽管Faster R-CNN已经突破了Fast R-CNN的速度瓶颈,但是后续检测阶段仍存在计算冗余问题。它继续沿用ROI Pooling层,这就会导致降低目标检测中定位的准确性,而且Faster R-CNN对小目标的检测效果不佳,后来提出了各种改进方案,R-FCN和Light head R-CNN都对Faster R-CNN做了进一步的改进。
2.3 总结
单阶段和双阶段目标检测算法是两种常见的目标检测方法,它们在目标检测的处理流程和性能表现上有一些显著的区别。
1.处理流程:
单阶段目标检测算法:单阶段算法一次性完成目标的区域提取和分类。它通常通过密集的候选框或锚点来覆盖整个图像,并直接在这些框或锚点上进行分类和位置回归,以确定目标的位置和类别。
双阶段目标检测算法:双阶段算法将目标检测过程分为两个阶段进行。第一阶段是生成候选框或锚点,在这一阶段,算法通过一些策略生成大量的候选框或锚点。第二阶段是对生成的候选框或锚点进行分类和位置回归,以得到最终的目标检测结果。
2.目标定位精度:
单阶段目标检测算法通常在目标定位精度上比较弱。由于它们需要在单个阶段中同时进行区域提取和分类,容易在目标边界不清晰或有重叠的情况下产生定位误差。这可能会导致一些虚假的检测框或定位不准确的结果。
双阶段目标检测算法在目标定位精度上通常更强。通过生成大量的候选框或锚点,第一阶段可以覆盖更多可能的目标区域,而第二阶段专注于对这些候选框进行筛选和精细调整,以获取更准确的目标位置。
3.处理速度:
单阶段目标检测算法通常具有更高的处理速度。由于整个目标检测过程只有一个阶段,它们可以直接对图像进行密集的分类和回归计算,从而在速度上较快。这使得单阶段算法在对实时性要求较高的应用场景中具有优势。
双阶段目标检测算法通常相对较慢。由于需要进行两个阶段的处理,包括生成候选框和执行分类和位置回归,双阶段算法的处理速度较慢。然而,随着硬件和算法的改进,双阶段算法也在不断提速。
总结起来,单阶段目标检测算法具有处理速度快的优势,适用于对处理速度要求较高的应用场景。然而,在目标定位精度和处理复杂场景下的表现上相对较弱。双阶段目标检测算法具有更强的目标定位精度和处理复杂场景的能力,但处理速度相对较慢。具体选择哪种算法应根据应用场景和需求权衡取舍。
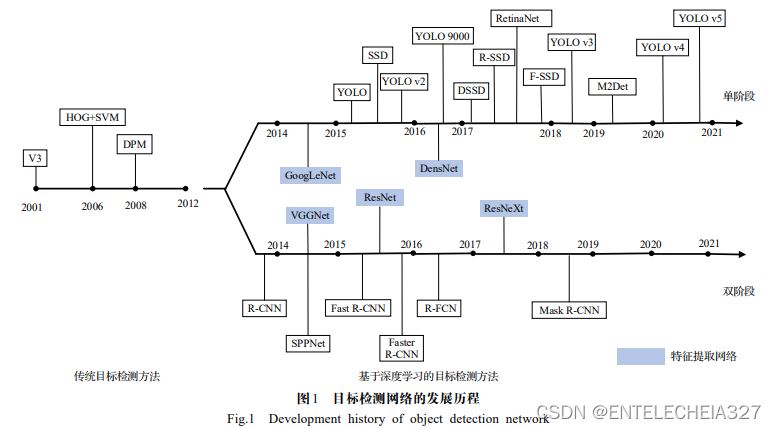
3 基于Transformer的目标检测
在基于深度学习的目标检测研究中,主要有两种算法:单阶段检测算法和双阶段检测算法。随着研究者将Transformer[Vaswani A et al. Attention is all your need]结构从自然语言处理领域引入到计算机视觉领域,Transformer结构打破了CNN有限的感受野限制,凭借与Faster R-CNN相比没有proposal、与YOLO相比没有Anchor、与CenterNet相比没有center也没有NMS后处理步骤、能够直接预测检测框和类别的优点,引起了广泛的关注。
基于Transformer的图像检测的总体框架如下:输入的图像首先要经过CNN骨干网络完成特征提取工作,通过Transformer对其进行编码和解码,再通过前馈网络对图像中的对象进行预测并输出类别边界框。当前基于深度学习的目标检测算法多数主要由Backbone(主干网络)、Neck和Head三部分组成。Backbone作为特征提取网络,主要作用是为后面网络提取图像中的特征信息,常用的Backbone主要有:VGG、ResNet等。Neck部分的主要作用是将Backbone提取的特征信息融合和增强,然后提供给后续的Head进行检测,常用的Neck主要有:SPP、ASPP、RFB等。Head利用之前提取的特征来预测目标的位置和类别。最近,有大量学者将Transformer移植到目标检测工作中并取得了非常理想的研究结果。本章主要总结几种常见的作为Neck的Transformer和作为Backbone的Transformer二维目标检测方法。
3.1 作为Neck的Transformer目标检测方法
Neck 作为 Backbone 和 Head 的中间部分,是由一系列混合和组合图像特征的网络层组成,可以从加速收敛或提高性能的角度更好的利用 Backbone 提取的特征解决检测问题。
3.1.1 DETR
Detection Transformer(DETR)[Carion N et al. End-to-end object detection with transformers (ECCV) 2020]是一种基于Transformer的端到端进行目标检测的方法,也是最早将Transformer带入到目标检测领域并取得较好性能的目标检测框架。它主要由CNN主干网、Transformer编解码结构和前馈网络(FFN)组成。首先,采用CNN主干网络提取输入图像的特征。然后,将提取的特征转换为一维特征映射,并发送给Transformer编码器。 利用多头自注意机制和编码器-解码器注意机制,对尺寸均为d的N个嵌入块进行了转换。最后,前馈网络(FFN)完成检测目标类型和边界框的预测。
在COCO数据集上,DETR在AP值上表现效果与Faster R-CNN几乎相当,但结构却得到了极大简化,DETR还可延伸到全景分割等领域,经实验验证都取得了良好的收益。但是,DETR在训练、优化以及小目标检测方面的性能还有待提高。针对这些问题,2020年10月 Zhu等人在经过大量研究后提出一种 新的方法:Deformable DETR,该方法能够改进 DETR 存在的问题[X. Zhu et al. Deformabledetr: Deformable transformers for end-to end object detection]
3.1.2 Deformable DETR
DETR的缺陷主要有:训练收敛较慢、计算复杂度高、训练时间较长以及小目标检测的性能较差。针对这些问题,研究者提出Deformable DETR这一新的模型,在Deformable DETR 中,最明显的特点是使用(多尺度)可变形注意模块取代了原有Transformer的注意力模块。可变形注意模块通常只是关注特征图上一小部分关键的采样点。该模块无需FPN的帮助就可以自然地扩展到聚合多尺度特征。Deformable DETR 比DETR(特别是在小物体上)可以获得更好的性能,训练epoch减少到十分之一,同时小目标检测AP值也提升3.9%,而与Faster RCNN相比,大目标检测AP值提高4.6%。尽管该模型在训练速度方面和小目标检测上得到了比较明显的改进,但在遮挡目标的检测上仍然需要进一步研究提高检测效果。
3.1.3 Conditional DETR
Conditional DETR将条件交叉注意机制用于快速DETR训练,可以缓解DETR收敛速度慢的情况[D. Meng, et al. Conditional detr for fast training convergence (IEEE ICCV) 2021]。它从解码器嵌入中学习条件空间查询,用于解码器的多头交叉注意。每个交叉注意头可以聚焦于包含不同区域的波段,有效缩小不同区域的空间范围,用于定位对象分类和帧回归,从而缓解对内容嵌入的依赖,简化训练。实验表明,在各种骨干网络(R50、R101、DC5-R50、DC5-R101)上的收敛速度约为DETR的6.7-10倍。
3.2 作为Backbone的Transformer目标检测方法
3.2.1 PVT
Wang等提出了Pyramid Vision Transformer(PVT),该模型是一种用于密集预测无CNN的简单Backbone结构[W. Wang et al. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions 2021]。与纯Transformer模型的ViT相比,PVT通过将特征金字塔结构引入Transformer结构完成如目标检测、目标分割等下游密集预测任务。总的来说,PVT的优势表现在通过对图像密集预测而获得高输出分辨率以及使用一个逐渐缩小的金字塔来达到减少计算量的效果。经过大量实验验证在COCO数据集上PVT作为通用的无卷积backbone比大部分的CNN backbone都有更好的效果。
3.2.2 Swin transformer
Swin transformer[Z. Liu et al. Swin transformer: Hierarchical vision transformer usingshifted windows 2021]是微软2021年3月月25日公布的一篇利用Transformer架构处理计算机视觉任务的论文,文章提出可以把Transformer作为计算机视觉任务的通用backbone。文章在图像分割、目标检测等各个领域都引起了关注。作者提出使用移动窗口的方式来减少序列长度,即hierarchical Transformer,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。这使得计算效率更高(只在窗口内做注意力计算,而不是计算全局,计算复杂度随图片大小线性增长,而不是平方增长),同时这种窗口的移动也使得相邻的窗口之间有了交互,上下层之间就具有了cross-window connection,从而变相地达到了一种全局建模的能力。Swin Transformer迅速引起学者追捧的主要原因是使用了基于Shifted Window的自注意力,它在有效减少计算量的同时,还能够保持良好的效果,因此对很多视觉的任务,尤其是对下游密集预测型的任务是非常有帮助的。但是如果Shifted Window操作不能用到NLP领域里,优势就会减弱,所以把Shifted Windows应用到NLP里是该方向未来的研究工作。
4 数据集与评价指标
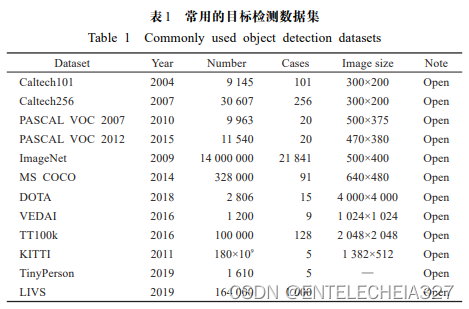
常用目标检测数据集如表1所示。
为对比目标检测算法的性能,常用检测速度、准确率、召回率、平均精确率、平均精确率均值等评价指标进行分析。
目标检测算法的性能分析涉及以下几个常用指标:假定待分类目标仅包含正例(positive)和负例(negative)两种,TP(true positives),正例被识别为正例的图像数量;FP(false positives),负例被识别为正例的图像数量;TN(true negatives),负例被识别为负例的图像数量;FN(false negatives),正例被识别为负例的图像数量。
检测速度(frames per second,FPS)主要用来评估目标检测模型的实时性,它表示的是算法模型中每秒钟能够检测的图片数量。
准确率(precision,P),Precision=TP/(TP+FP),表示的是正样本数据被分类器准确判别为正样本的概率。
召回率(recall,R),Recall=TP/(TP+FN),表示的是分类器把所有正样本数据都找出来的能力。
平均精确率(average precision,AP)是指P-R曲线所围成的面积,而P-R曲线是以检测模型的召回率为横坐标轴,准确率为纵坐标轴所形成的。
mAP(mean average precision)是多个类别的平均AP值,它衡量的是分类器对所有类别的检测效果,是目前目标检测领域应用最广泛的评价指标。
参考文献:


















 2889
2889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









