







1.全连接网络
全连接NN特点:每个神经元与前后相邻的每一个神经元都有连接关系。(可以实现分类和预测)
全连接网络的参数个数位:(前层*后层+后层)
如下面构建的这个全连接神经网络,其参数量为28*28*128w+128b+128*10w+10=101770个
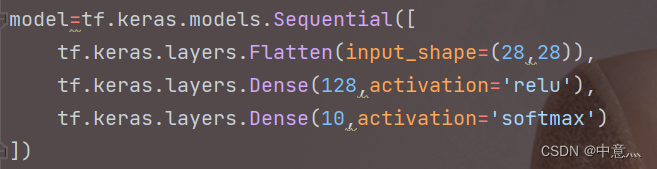
而上面的代码就是Mnist数据集分类的全连接神经网络模型,而在实际应用中,我们所处理的图像不是灰度图,大部分是彩色图,这样会涉及到更多的参数,虽然全连接网络一般被认为是分类预测的最佳网络,但是当待优化参数过多,容易导致模型过拟合。
为了解决参数过多而导致过拟合的问题,一般不会将原始图像直接输入,而是先对图像进行特征提取,再将提取到的特征输入全连接网络,如对一张红蓝绿三通道的彩色图像,我们可通过将其转化成单通道的灰度图,再喂入全连接网络(仅仅举个例子)。
2.卷积神经网络
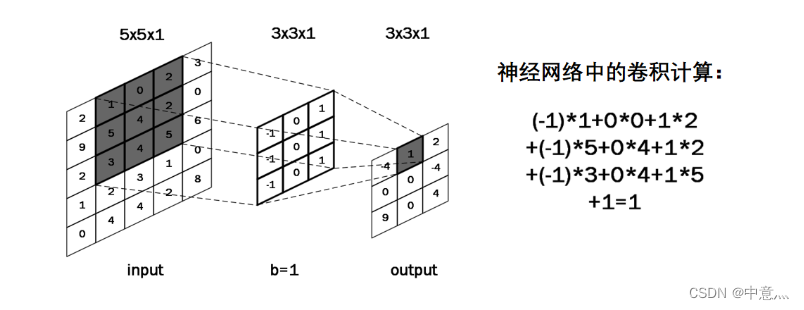
卷积的概念:卷积可以认为是一种有效提取图像特征的方法。一般会用一个正方形的卷积核,按指定步长,再输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点,如下图所示,利用大小为3*3*1的卷积核对5*5*1的单通道图像做卷积计算得到相应结果。
对于彩色图像(多通道来说),卷积核通道数与输入特征一致,套接后在对应位置上进行乘加和操作,如下图,利用三通道卷积核对三通道的彩色特征图做卷积计算。
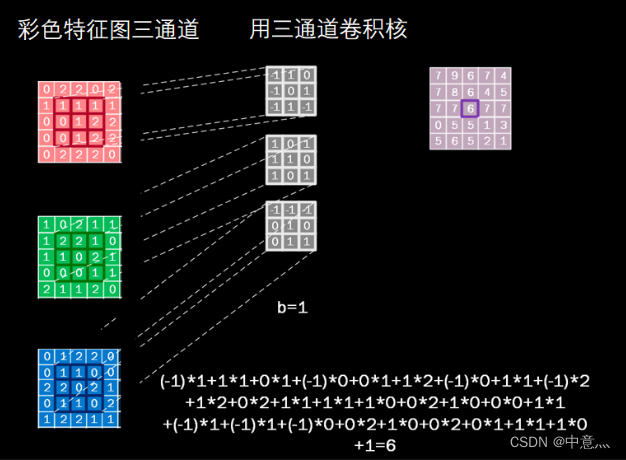
用多个卷积核可实现对同一层输入特征的多次特征提取,卷积核的个数决定输出层的通道(channels)数,即输出特征图的深度。
感受野(Receptive Field)的概率:卷积神经网络各输出层每个像素点在原始图像上的映射域大小。
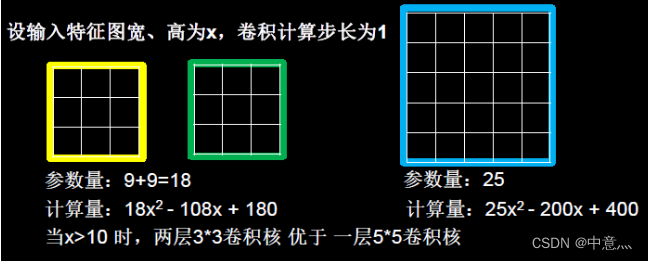
当我没采用尺寸不同的卷积核时,最大的区别就是感受野的大小不同,所以经常会采用多层小卷积核来替换一层大卷积核,在保持感受野相同的情况下减少参数量和计算量,例如十分常见的用2层3*3卷积核来替换1层5*5卷积核的方法,如下图
输出特征尺寸计算:在了解神经网络中卷积计算的整个过程后,就可以对输出特征图的尺寸进行计算,如下图所示
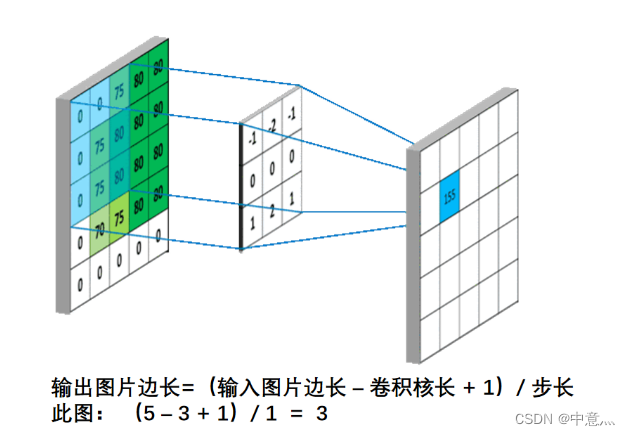
全零填充(padding):为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如下图所示:
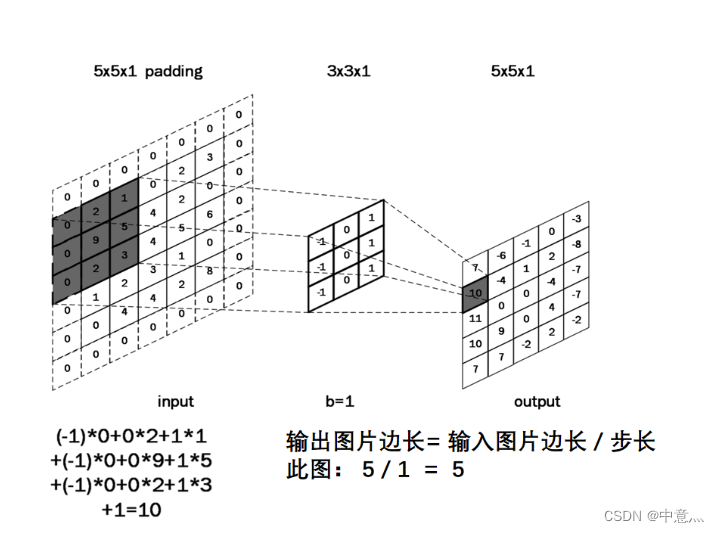
在tensorflow框架 中,用参数padding=‘SAME’或padding=‘VALID’表示是否进行全零填充,其对输出特征尺寸大小的影响如下:

具备以上知识,我们就可以在tensorflow框架下利用Keras搭建CNN中的卷积层。
tf.keras.layers.Conv2D
tf.keras.layers.Conv2D(
input_shape=(高,宽,通道数),#仅在第一层
filters=卷积核个数,
kernel_size=卷积核尺寸,
strides=(1, 1),#卷积步长,沿高度和宽度的步幅
padding='valid' or 'SAME',#是否全零填充
data_format=None,
dilation_rate=(1, 1),
groups=1,
activation=激活函数,#如有BN则此处不用写
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)参数详解如下:
使用此函数构建卷积层时,需要给出的信息有:
- 输入图像的信息,即宽高和通道数
- 卷积核的个数以及尺寸,如filters=16,kernel_size=(3,3) 代表采用16个大小为3*3的卷积核
- 卷积步长,即卷积核在输入图像上滑动的步长,纵向步长与横向步长通常相同,默认值为1
- 是否进行全零填充,全零填充保持输出图像尺寸与输入图像一致
- 采用哪种激活函数,如relu、softmax等,各种函数具体效果可自己了解,但需要注意的是,再利用tensorflow框架构建卷积网络时,一般会利用BatchNormalization函数来构建BN层,进行批归一化操作,所以在Conv2D函数中经常不写BN。
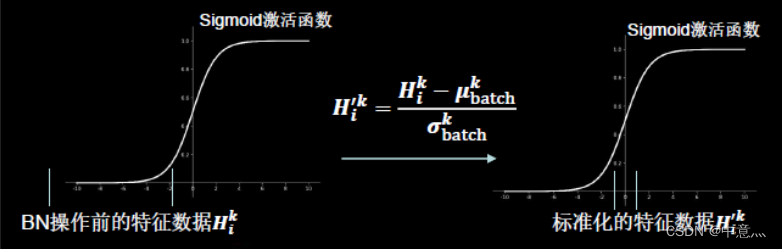
Batch Normalization(批标准化):对一小批数据在网络各层的输出做标准化处理,其具体实现方式如下图所示(标准化:使数据符合0均值,1为标准差的分布)

Batch Normalization将神经网络每层的输入都调整到均值为0,方差为1的标准正态分布,其目的是解决神经网络中梯度消失的问题,如下图所示
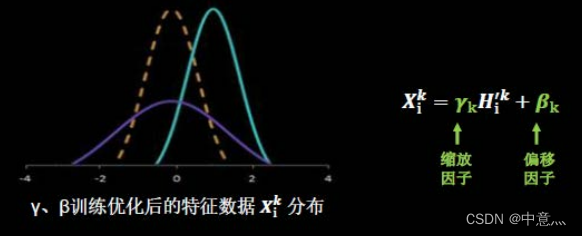
BN操作的另一个重要步骤就是缩放和偏移,其中缩放因子与偏移因子
都是可训练参数,其作用如下图
BN操作通常位于卷积层之后,激活层之前,在tensorflow框架中,通常使用Keras中的tf.keras.layers.BatchNormalization函数来构建BN层。
tf.keras.layers.BatchNormalization
tf.keras.layers.BatchNormalization(
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer='zeros',
gamma_initializer='ones',
moving_mean_initializer='zeros',
moving_variance_initializer='ones',
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
**kwargs
)| 参数 | |
|---|---|
axis | 整数,应规范化的轴(通常为要素轴)。例如,在 中设置了 的图层之后。Conv2Ddata_format="channels_first"axis=1BatchNormalization |
momentum | 移动平均线的动量。 |
epsilon | 将小浮点数添加到方差中以避免除以零。 |
center | 如果为 True,则将 的偏移量添加到归一化张量。如果为 False,则忽略。betabeta |
scale | 如果为 True,则乘以 。如果为 False,则不使用。当下一层是线性的(例如nn.relu),这可以被禁用,因为缩放将由下一层完成。gammagamma |
beta_initializer | β 权重的初始值设定项。 |
gamma_initializer | 伽玛权重的初始值设定项。 |
moving_mean_initializer | 移动均值的初始值设定项。 |
moving_variance_initializer | 移动方差的初始值设定项。 |
beta_regularizer | β 权重的可选正则化器。 |
gamma_regularizer | 伽马权重的可选正则化器。 |
beta_constraint | beta 权重的可选约束。 |
gamma_constraint | 伽玛权重的可选约束。 |
池化(pooling):池化作用是减少特征数量(降维)。最大值池化可提取图片纹理,均值池化可保留背景特征,如下图

在tensorflow中,用tf.keras.layers.MaxPool2D函数和tf.keras.layers.AveragePooling2D函数来构建池化层,具体方法使用如下
tf.keras.layers.AveragePooling2D(
pool_size=(2, 2),#池化核大小
strides=None,#池化步长
padding='valid' or 'SAME'#是否全零填充
)tf.keras.layers.MaxPool2D(
pool_size=(2, 2),#池化核大小
strides=None,#池化步长
padding='valid' or 'SAME'#是否全零填充
)舍弃(Dropout):在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃,使用时被舍弃的神经云恢复连接。
在tensorflow框架中,利用tf.keras.layers.Dropout函数构建Dropout层
tf.keras.layers.Dropout(
rate, noise_shape=None, seed=None, **kwargs
)| 参数 | |
|---|---|
rate | 在 0 和 1 之间浮动。要丢弃的输入单位的分数。 |
noise_shape | 1D 整数张量,表示将与输入相乘的二进制压差掩码的形状。 |
seed | 用作随机种子的 Python 整数。 |
3.构建卷积神经网络(CNN)
核心思想:在CNN中利用卷积核(kernel)提取特征后,送入全连接网络。
CNN模型的主要模块:一般包括上述的卷积层、BN层、激活函数、池化层以及全连接层,如下图

搭建卷积神经网络
cifar10数据集介绍:CIFAR-10 数据集由 10 个类中的 60000 张 32x32 彩色图像组成,每个类包含 6000 张图像。有 50000 张训练图像和 10000 张测试图像。数据集分为五个训练批次和一个测试批次,每个批次包含 10000 张图像。测试批次正好包含从每个类中随机选择的 1000 张图像。训练批次包含随机顺序的剩余图像,但某些训练批次可能包含来自一个类的图像多于另一个类的图像。在它们之间,训练批次正好包含来自每个类的 5000 张图像。以下是数据集中的类,以及来自每个类的 10 张随机图像:
 这些类是完全互斥的。汽车和卡车之间没有重叠。“汽车”包括轿车,SUV,诸如此类的东西,“卡车”只包括大卡车,两者都不包括皮卡车。
这些类是完全互斥的。汽车和卡车之间没有重叠。“汽车”包括轿车,SUV,诸如此类的东西,“卡车”只包括大卡车,两者都不包括皮卡车。
基本代码:
# -*- coding: utf-8 -*-
# @Time : 2022/9/1 18:43
# @Author : 中意灬
# @FileName: 基于cifar10的基本CNN模型.py
# @Software: PyCharm
"""导入相关的库"""
import os.path
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Conv2D,BatchNormalization,Activation,MaxPool2D,Dropout,Flatten,Dense
from tensorflow.keras import Model
"""准备数据集"""
(x_train,y_train),(x_test,y_test)=tf.keras.datasets.cifar10.load_data()
x_train,x_test=x_train/255,x_test/255
"""搭建神经网络结构"""
class Baseline(Model):
def __init__(self):
super(Baseline,self).__init__()
self.c1=Conv2D(input_shape=(60000,32,32),filters=6,kernel_size=(5,5),padding='SAME',strides=(1,1))#搭建卷积层
self.b1=BatchNormalization()#批标准化
self.a1=Activation('relu')#激活函数选择
self.p1=MaxPool2D(pool_size=(2,2),strides=2,padding='SAME')#池化
self.d1=Dropout(rate=0.2)#舍弃
self.flatten=Flatten()
self.f1=Dense(128,activation='relu')
self.d2=Dropout(rate=0.2)
self.f2=Dense(10,activation='softmax')
def call(self,x):
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.p1(x)
x=self.d1(x)
x=self.flatten(x)
x=self.f1(x)
x=self.d2(x)
x=self.f2(x)
return x
"""配置训练参数"""
model=Baseline()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
"""断点续训"""
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('==========loading model==========')
model.load_weights(checkpoint_save_path)
#回滚操作
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
"""训练模型"""
history=model.fit(x_train,y_train,batch_size=256,epochs=5,validation_data=(x_test,y_test),validation_freq=1,callbacks=[cp_callback])
"""导出最优参数"""
f=open('weights.txt','w')
f.write(str(model.trainable_variables))
f.close()
"""打印网络结构"""
model.summary()
"""绘制acc与loss曲线"""
acc=history.history['sparse_categorical_accuracy']#训练集准确率
val_acc=history.history['val_sparse_categorical_accuracy']#测试集准确率
loss=history.history['loss']#训练集loss
val_loss=history.history['val_loss']#测试集loss
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.figure()
plt.subplot(1,2,1)
plt.plot(acc,label='训练集准确率')
plt.plot(val_acc,label='测试集准确率')
plt.legend()
plt.subplot(1,2,2)
plt.plot(loss,label='训练集loss')
plt.plot(val_loss,label='测试集loss')
plt.legend()
plt.show()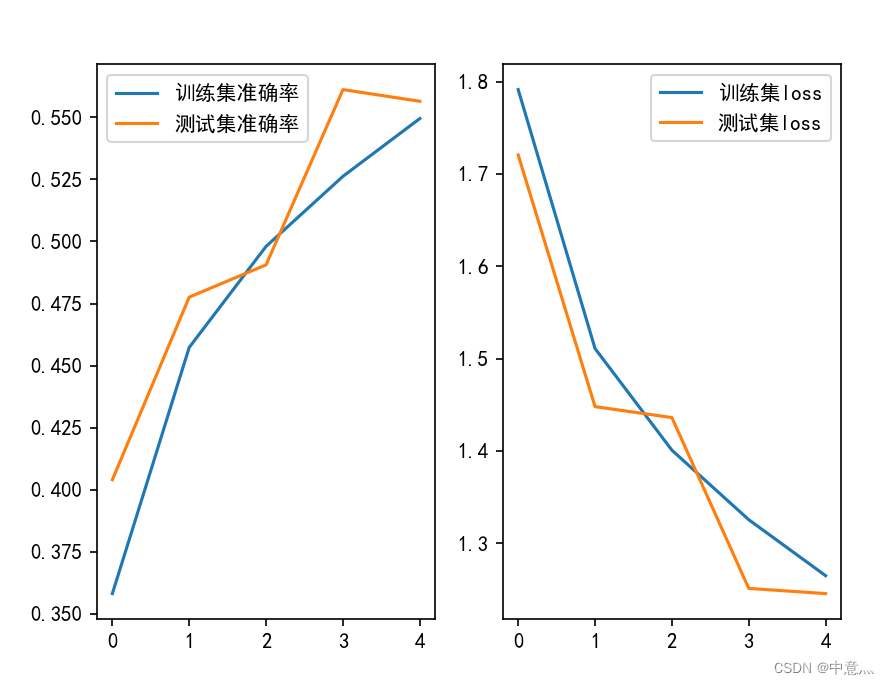
以上只是最基础的卷积神经网络模型,其准确率也较低只有0.5左右,而现如今的ResNet其错误率只有3.57%,以下是ResNet的神经网络代码
# -*- coding: utf-8 -*-
# @Time : 2022/9/6 14:13
# @Author : 中意灬
# @FileName: ResNet.py
# @Software: PyCharm
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = ResNet18([2, 2, 2, 2])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/ResNet18.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()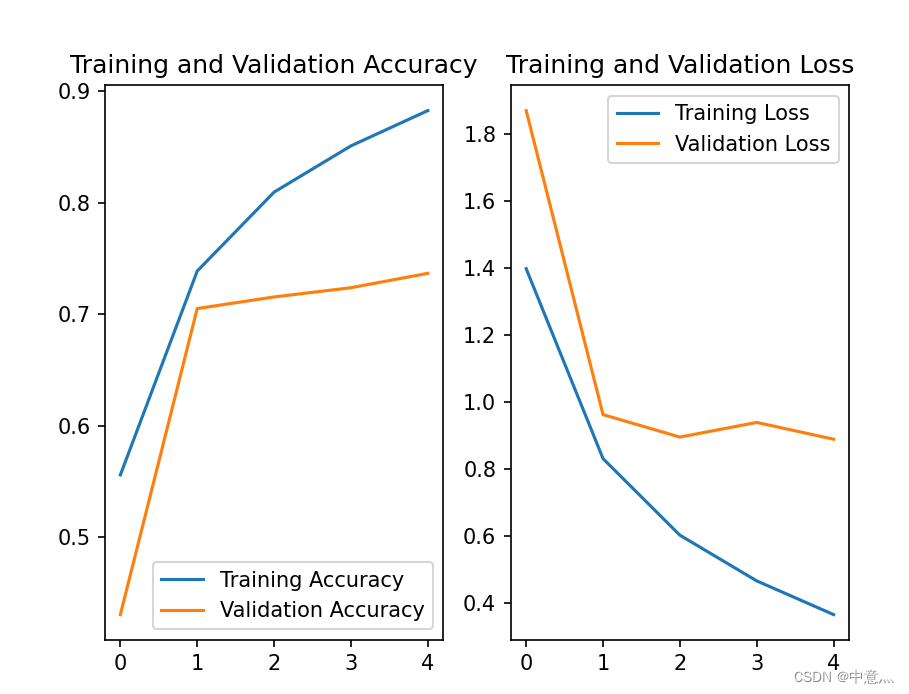















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









