







Pytorch分类模型
分类问题中,输出并不是像回归一样是一个确定的数值,而是一个概率;
假如10分类问题中,我们输入一个x,得到的是它的输出对于某个分类最大的概率,而这10个概率值加起来要等于1
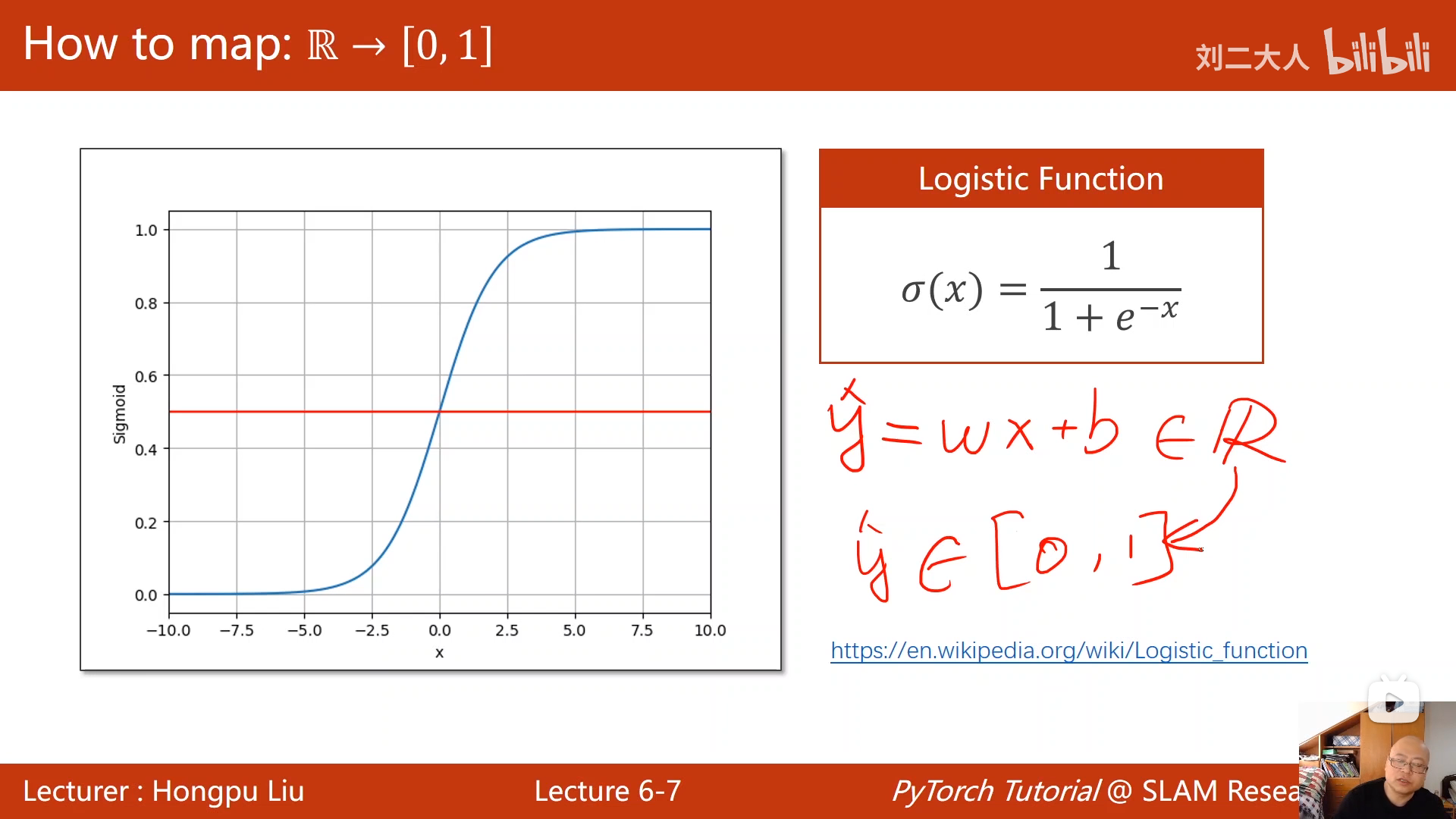
回归问题的输出是一个实数值,而分类问题的输出是一个概率,所以我们需要找一个函数,把实数值映射到概率 [0,1] 区间,sigmoid函数。
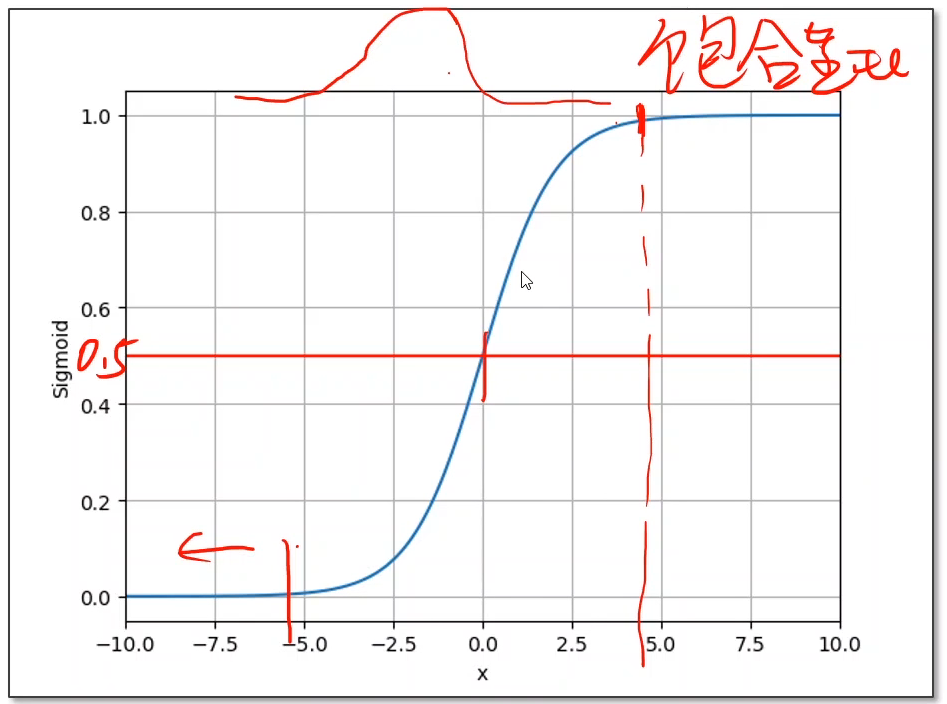
sigmoid函数是一个饱和函数,因为当x大于某个值时,函数值上升得很慢,即导数值变小,梯度很小
不同的sigmoid函数
loss的问题,由于是多分类任务,故y_pred与y之间不能再求均方误差,而是求分布的误差

在概率论中,计算分布的误差有:KL散度、cross-entropy(交叉熵)
cross-entropy 交叉熵的计算
给定两个分布PD和PT ,那么交叉熵的计算就是下述求和公式
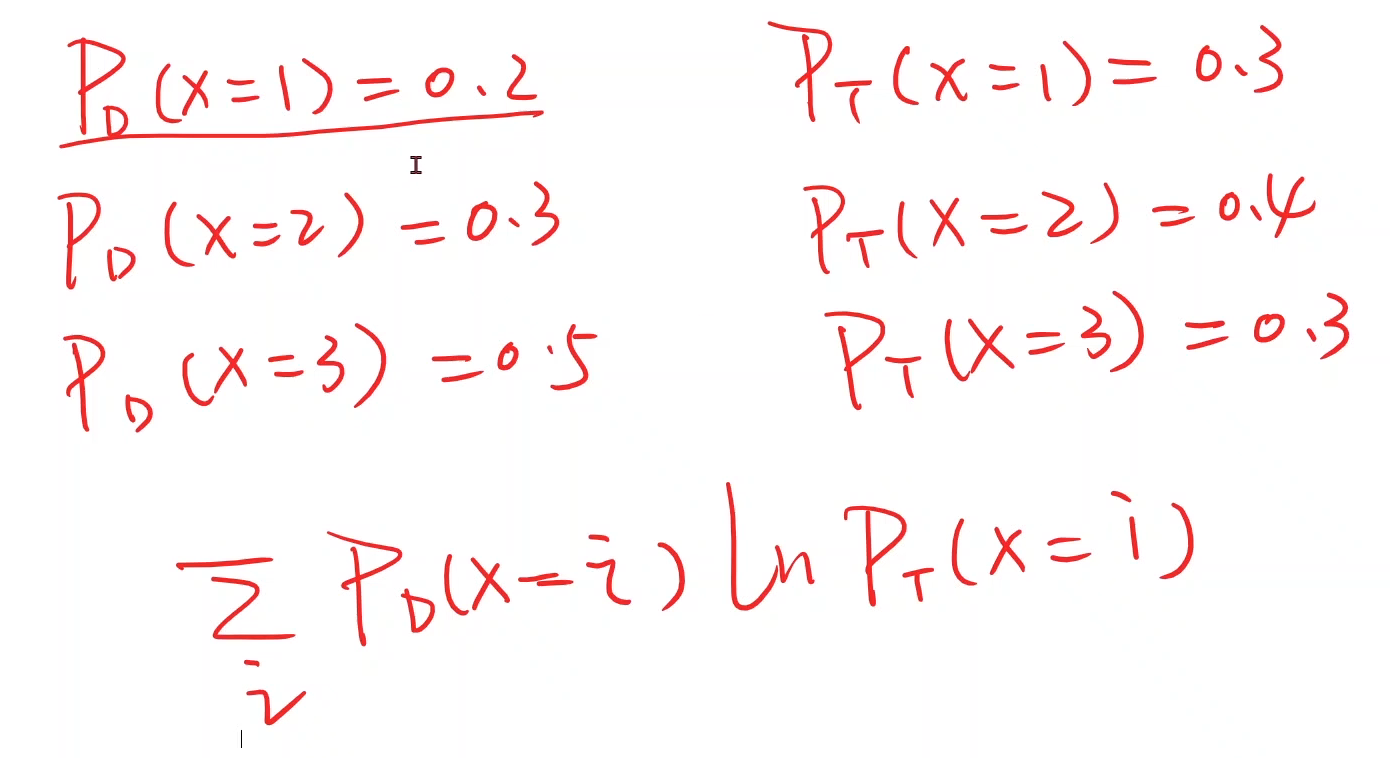


code
import torch
import torchvision
#tanh、relu也在下面这个包里面
import torch.nn.functional as F
#download 如果第一次使用则为true,已经下载过就写false
# torchvision.datasets.CIFAR10() 是另一个多分类数据集
# train_set=torchvision.datasets.MNIST(root='../dataset/mnist',train=True,download=False)
# test_set=torchvision.datasets.MNIST(root='../dataset/mnist',train=False,download=False)
x_data= torch.Tensor([[1.0],[2.0],[3.0]])
y_data= torch.Tensor([[0],[0],[1]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
#linear线性构造函数与之前无区别
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
#就多了下面F.sigmoid() 其他与线性逻辑回归一样
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
#求交叉熵loss
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace(0,10,200)
x_t = torch.Tensor(x).view((200,1)) #把x变为 200*1的矩阵,相当于np.rashape
y_t = model(x_t)
y=y_t.data.numpy() #得到一个n维数组
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('hours')
plt.ylabel('probability of pass')
plt.grid()
plt.show()
多维输入的分类模型
上面的例子都是当x为一维的情况下,如果当x为多维,比如8维时(即x具有8个特征)模型公式有所改变,
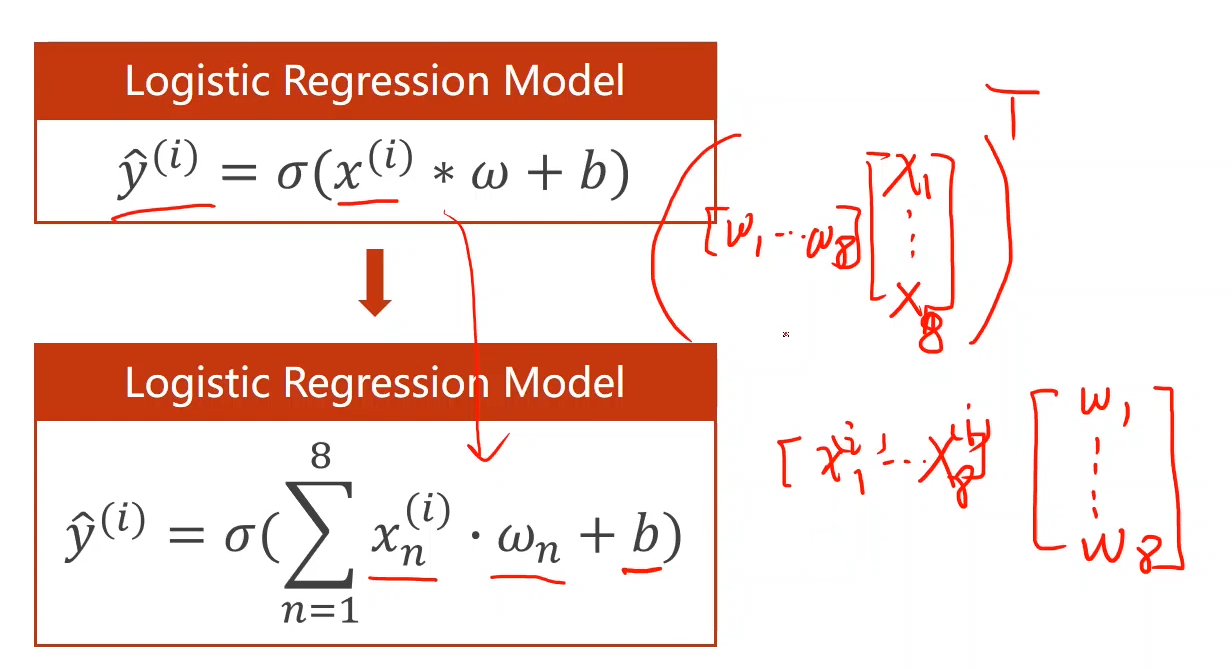
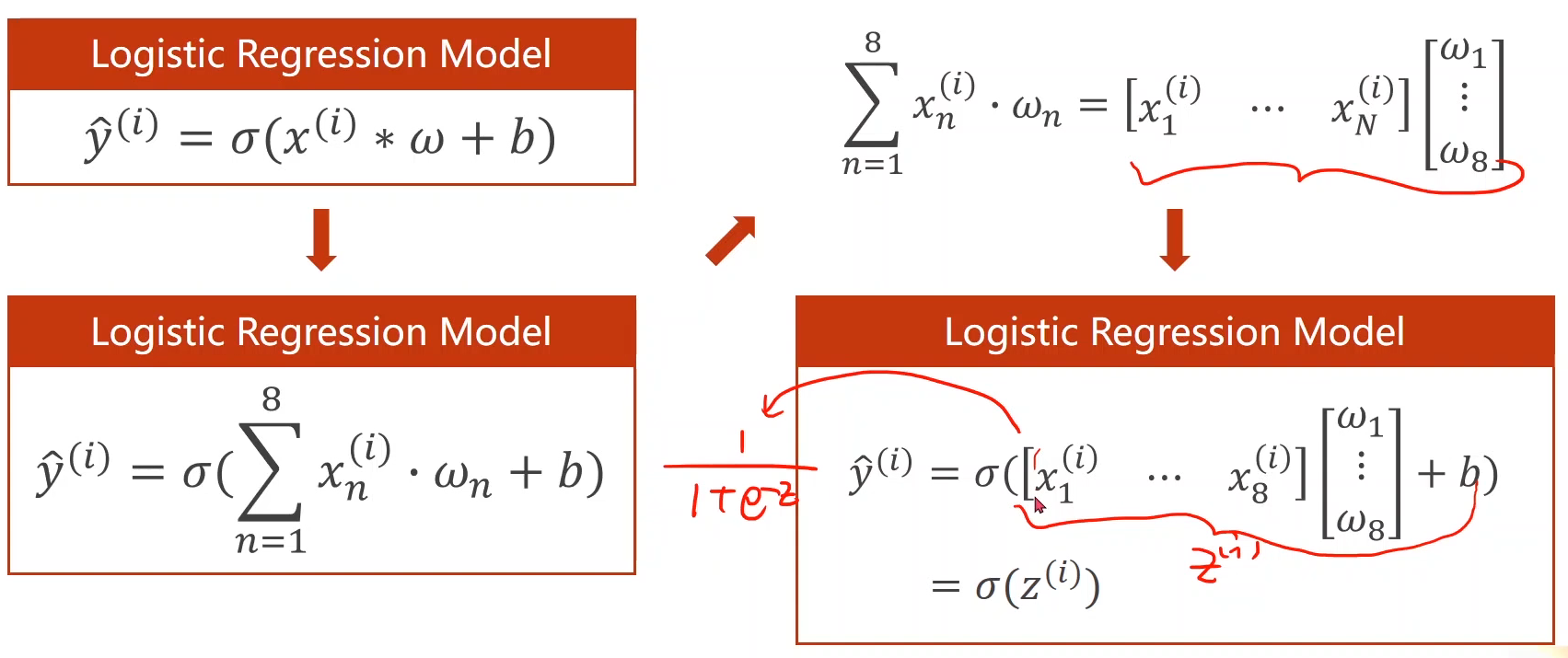
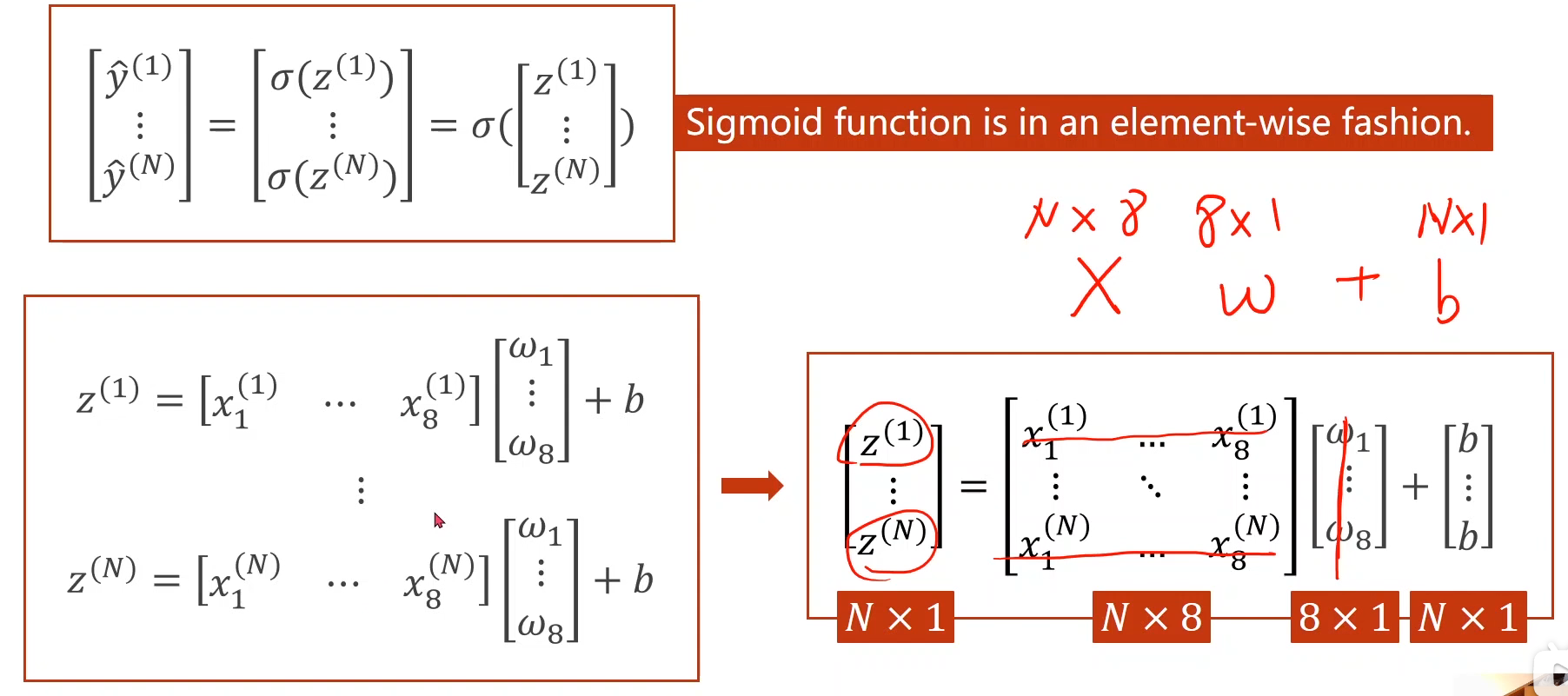
多层非线性结构

把输入从8维,降为6维,再依次降低到一维,就增加了隐藏层
code
import torch
import torchvision
#tanh、relu也在下面这个包里面
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
xy=np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:,[-1]])
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.ReLU()
self.sigmoid2 = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid2(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
#下述第一个参数表示对model所有的参数都更新
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
loss_list=[]
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(np.linspace(1,100,100),loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()















 2480
2480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









