






强化学习实践五_表格Q-learning.md
Q值更新公式:
Q(s,a) = (1-α) * old_Q(s,a) + α * (γ(r+maxQ(s_,a)))
import gym
import collections
from tensorboardX import SummaryWriter
ENV_NAME = "FrozenLake8x8-v1"
GAMMA = 0.9
ALPHA = 0.2
TEST_EPISODES = 20
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME) # 创建环境
self.state = self.env.reset() # 设置初始状态
self.values = collections.defaultdict(float) # 初始化字典存放Q值
# 随机抽样一个动作,然后只玩一步,返回(s,a,r,s_)
def sample_env(self):
action = self.env.action_space.sample()
old_state = self.state
new_state, reward, is_done, _ = self.env.step(action)
self.state = self.env.reset() if is_done else new_state
return old_state, action, reward, new_state
# 给定一个s,从Q表中找出maxQ(s,a),返回Q(s,a)和动作a
def best_value_and_action(self, state):
best_value, best_action = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_value, best_action
# 更新Q(s,a) = (1-α) * old_Q(s,a) + α * (γ(r+maxQ(s_,a)))
def value_update(self, s, a, r, next_s): # 传入一组(s,a,r,s_) 只更新Q(s,a)
best_v, _ = self.best_value_and_action(next_s)
new_v = r + GAMMA * best_v
old_v = self.values[(s, a)]
self.values[(s, a)] = old_v * (1-ALPHA) + new_v * ALPHA
# 以maxQ(s,a)玩一局游戏,返回该局游戏的总奖励值
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, _ = env.step(action)
total_reward += reward
if is_done:
break
state = new_state
return total_reward
# 训练完毕后玩一局游戏,并渲染
def playgame(agent):
env = gym.make(ENV_NAME)
s = env.reset()
env.render()
while True:
_,action = agent.best_value_and_action(s)
s_,r,is_done,_ = env.step(action)
env.render()
if is_done:
break
s = s_
agent = Agent()
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
writer = SummaryWriter(comment="table-q-learning")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
s, a, r, next_s = agent.sample_env() # 随机抽样一步动作
agent.value_update(s, a, r, next_s) # 更新(s,a,r,s_)中Q(s,a)的值
reward = 0.0
for _ in range(TEST_EPISODES): # 玩20局游戏,测试Q(s,a)表的性能
reward += agent.play_episode(test_env)
# 得到该20局游戏的平均奖励
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (
best_reward, reward))
best_reward = reward
if reward > 0.90:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
playgame(agent)
缺陷:
每一次循环只更新一个Q值,收敛速度慢
达到平均奖励0.85 花费56s
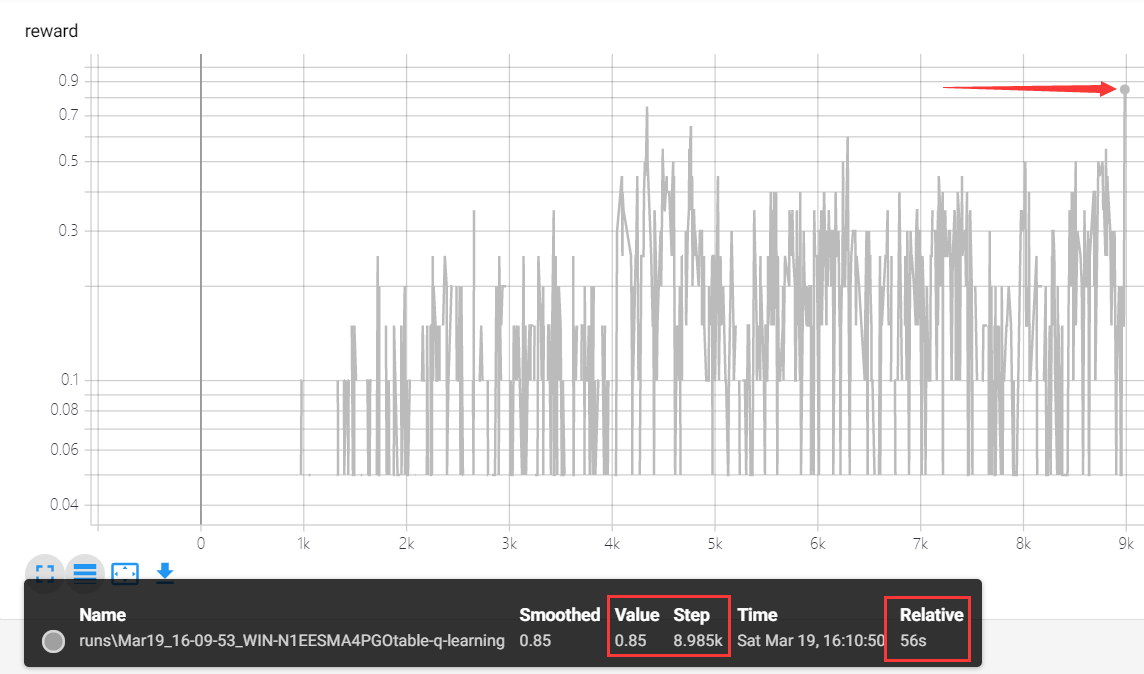
改进一:
# 删除sample_env()函数,新增updataQ() 函数
import gym
import collections
from tensorboardX import SummaryWriter
ENV_NAME = "FrozenLake-v1"
GAMMA = 0.9
ALPHA = 0.2
TEST_EPISODES = 20
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME) # 创建环境
self.state = self.env.reset() # 设置初始状态
self.values = collections.defaultdict(float) # 初始化字典存放Q值
# 玩一局,更新每一步中(s,a,r,s_)中的Q(s,a)
def updataQ(self):
while True:
action = self.env.action_space.sample()
old_state = self.state
new_state, reward, is_done, _ = self.env.step(action)
self.value_update(old_state, action, reward, new_state)
if is_done:
self.state = self.env.reset()
break
self.state = new_state
# 给定一个s,从Q表中找出maxQ(s,a),返回Q(s,a)和动作a
def best_value_and_action(self, state):
best_value, best_action = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_value, best_action
# 更新Q(s,a) = (1-α) * old_Q(s,a) + α * (γ(r+maxQ(s_,a)))
def value_update(self, s, a, r, next_s): # 传入一组(s,a,r,s_) 只更新Q(s,a)
best_v, _ = self.best_value_and_action(next_s)
new_v = r + GAMMA * best_v
old_v = self.values[(s, a)]
self.values[(s, a)] = old_v * (1-ALPHA) + new_v * ALPHA
# 以maxQ(s,a)玩一局游戏,返回该局游戏的总奖励值
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, _ = env.step(action)
total_reward += reward
if is_done:
break
state = new_state
return total_reward
def playgame(agent :Agent):
env = gym.make(ENV_NAME)
s = env.reset()
env.render()
while True:
_,action = agent.best_value_and_action(s)
s_,r,is_done,_ = env.step(action)
env.render()
if is_done:
break
s = s_
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="enhance-table-q-learning")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
agent.updataQ()
reward = 0.0
for _ in range(TEST_EPISODES): # 玩20局游戏,测试Q(s,a)表的性能
reward += agent.play_episode(test_env)
# 得到该20局游戏的平均奖励
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (
best_reward, reward))
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
playgame(agent)
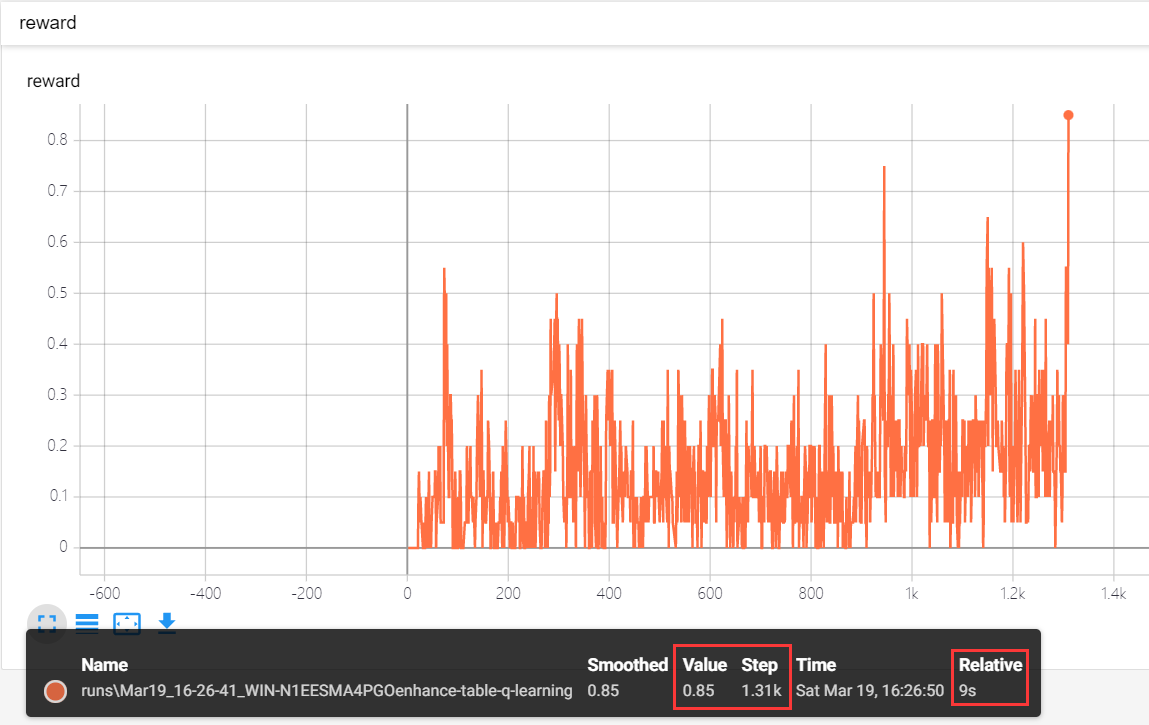
改进后性能显著提升!
但是还存在一个问题,改进后的代码对Q值做的更新都是采用随机动作来更新,所以有很多重复的Q(s,a)要计算,我们可以再做一次改进,让agent在测验中以Q策略边玩游戏边更新Q值
需要变动的代码,其他部分与第二次改动一样
# 以maxQ(s,a)玩一局游戏,每一步都更新Q(s,a),并返回该局游戏的总奖励值
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, _ = env.step(action)
# 改进,边玩边更新
self.value_update(state, action, reward, new_state)
total_reward += reward
if is_done:
break
state = new_state
return total_reward
结果:
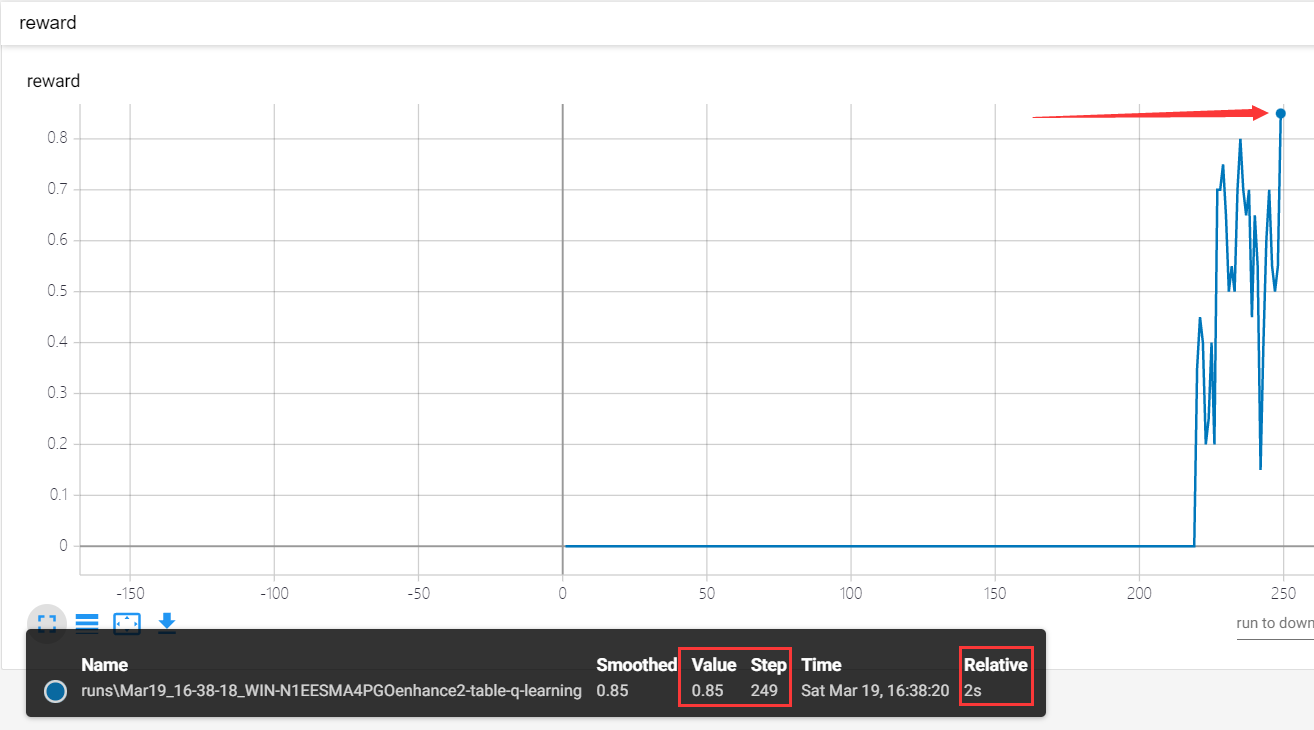
相较于前两次,其提升更加明显
即使平均回报到达0.95,其训练时间也短
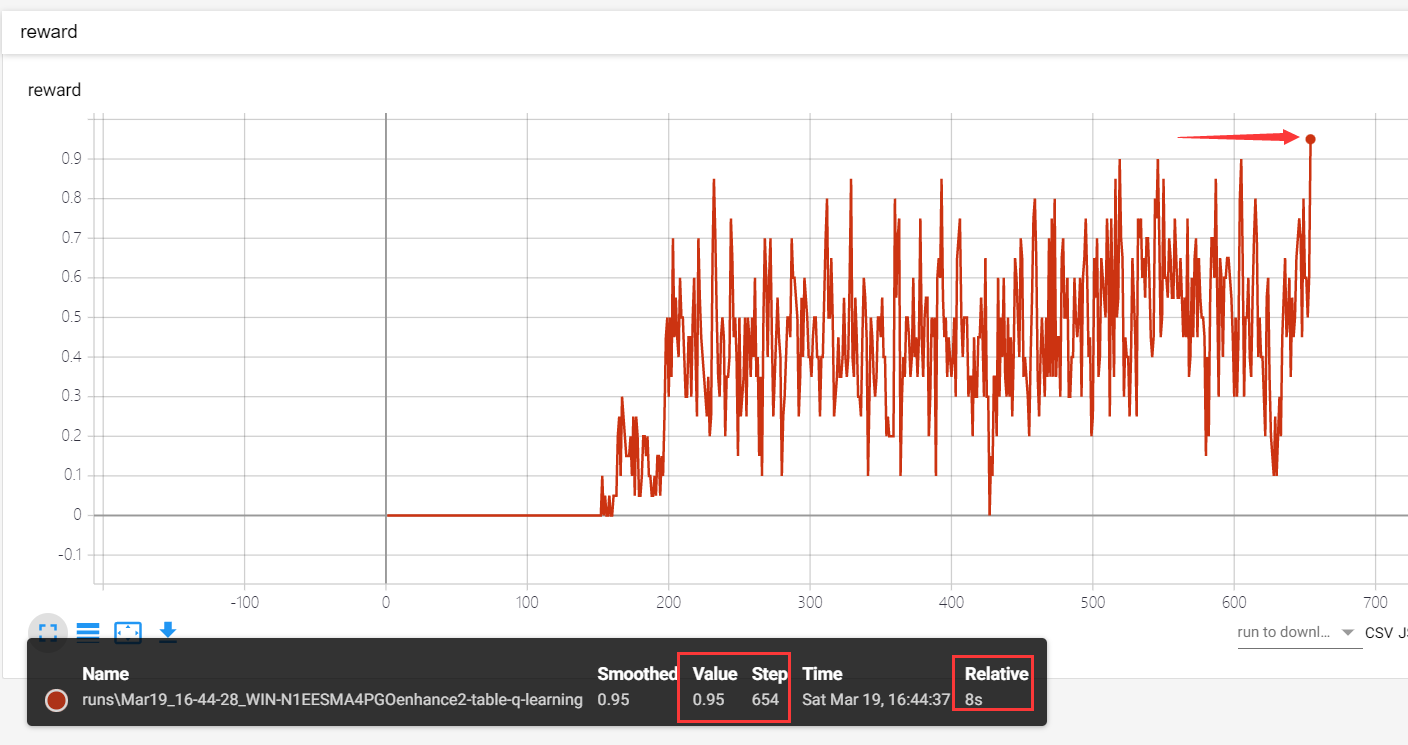
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









