







 本文介绍了增强学习的基本概念,通过“熊瞎子掰苞米”的故事阐述了决策优化的重要性。文章以Q-Learning为例,解释了Q-table的构建、更新过程,并通过一个小迷宫的案例展示了Q-Learning如何训练Agent进行决策。最后提到了深度增强学习是将神经网络应用于Q-Learning,以实现更复杂的决策策略。
本文介绍了增强学习的基本概念,通过“熊瞎子掰苞米”的故事阐述了决策优化的重要性。文章以Q-Learning为例,解释了Q-table的构建、更新过程,并通过一个小迷宫的案例展示了Q-Learning如何训练Agent进行决策。最后提到了深度增强学习是将神经网络应用于Q-Learning,以实现更复杂的决策策略。
本文首发于集智:https://jizhi.im/blog/post/intro_q_learning
“机器学习”的话题一直很火热,相关的概念也是层出不穷,为了不落后于时代,我们都还是要学习一个。
第一次听到“增强学习”(Reinforcement Learning)的时候,我以为只是在“深度学习”的基础上又玩儿的新花样。后来稍微了解了一下,发现其实是完全不同的概念,当然它们并非互斥,反而可以组合,于是又有了“深度增强学习”(Deep Reinforcement Learning)。
这让人不由得感慨起名的重要性,“增强”这个名称就给人感觉是在蹭“深度”的热点,一个下五洋,一个上九天。而“卷积神经网络”(Convolutional Neural Network)这个名字就好的多,其实这里的“卷积”跟平时说的那个卷积并不是一回事,但是就很有科技感、Geek范。更好的还有“流形学习”(Manifold Learning),洋溢着古典人文主义气息。
天地有正气,杂然赋流形。——文天祥《正气歌》

军师,就是掌握了决策艺术的人。
增强学习是关于决策优化的科学,其背后正是生物趋利避害的本能。
“熊瞎子掰苞米”就是一个典型的决策过程。因为胳肢窝只能夹一个苞米,所以对每个苞米,熊瞎子都要做一个决策——掰,还是不掰?这是个问题。
在俗话故事里,熊瞎子并不知道自己掰一个丢一个,所以他的决策就是“掰掰掰”(Buy, Buy, Buy),最后结果就是拿了一个很小的苞米,后悔地想要剁手。而聪明的智人却选择“只掰比自己胳肢窝里大的”,那么理想状况下,就是得到了最大的。

熊瞎子不高兴
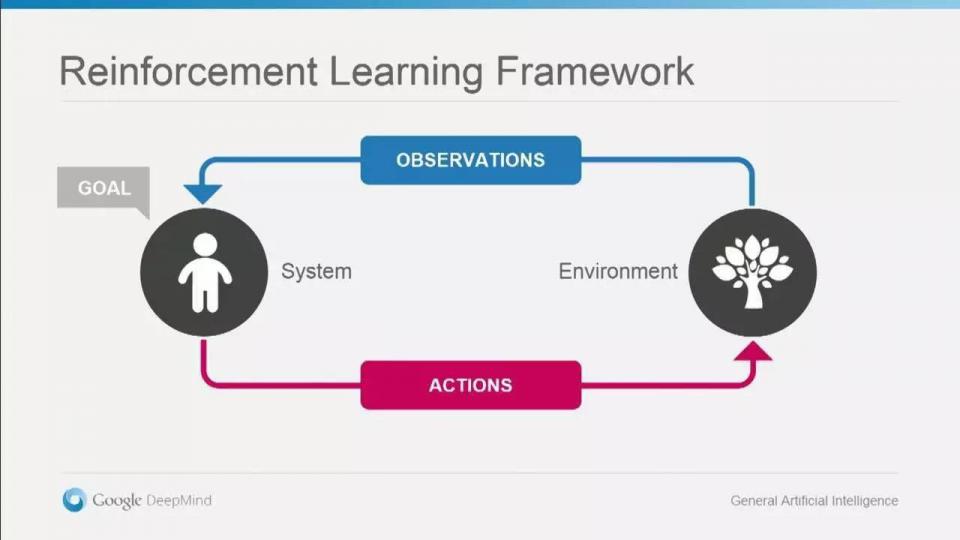
这里,熊瞎子或智人表示Agent,也就是决策过程里的行为主体。玉米地就是Environment,而现在胳肢窝里的苞米大小则是State,而眼前一个等待采摘的苞米,是熊瞎子对环境的Obervation。掰还是不掰?无论哪一种,都是对环境做出的Action。
当你走出玉米地时,最终拿到的苞米,才是自己的,这是你的Reward。“掰掰掰”,“只掰大的”或是“只掰贵的,不掰贵对的”——这些都是Policy。以上就是增强学习里的几个核心基本概念。
增强学习所解决的问题,介于“有监督”和“无监督”之间。决策是有目标的,或是“最大的苞米”,或是“赢下这盘棋”,这就与聚类任务不同。但是这个“目标”又不是固定明确的,最终获胜的棋路,就一定是最佳的吗?未必,不像图片分类或是价格预测,能评判个准确率。
如果要用知乎的方式来描述增强学习,应该是“如何评价”。比如一手“炮五平二”,是好是坏呢?不是立即就能得到反馈的,而可能是在终盘才能体现出来,这就是Reward的滞后性。所以做增强学习,心里应该时刻装着“婆婆婆婆这是真的吗?我不信,等反转!”
你从昏迷中醒来,发现自己被锁着,面前一个电视自动打开了。画面上有一个眼神和善的玩偶,用Kaiser一样的山东口音说"I wanna to play a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









