





心电图语义集成器(ESI):一种采用经大型语言模型(LLM)增强的心血管领域文本进行预训练的心电图基础模型
源代码:https://github.com/comp-well-org/ESI
摘要
将深度学习应用于心电图(ECG)分析,显著提升了心脏健康诊断的准确性与效率。在本研究中,我们针对深度学习心电图分析领域的一项关键挑战展开研究:如何在缺乏大规模标注数据集的情况下学习鲁棒的特征表示。为此,我们提出了心电图语义整合器(ECG Semantic Integrator,简称 ESI)—— 这是一种新型多模态对比预训练框架,能够同时从心电图信号及相关文本描述中学习特征。ESI 采用包含对比损失函数和字幕生成损失函数的双目标函数,构建心电图数据的特征表示。
为构建规模充足且数据多样的训练数据集,我们开发了一个基于检索增强生成(retrieval-augmented generation,简称 RAG)的大型语言模型(Large Language Model,简称 LLM)流水线,命名为心脏查询助手(Cardio Query Assistant,简称 CQA)。该流水线旨在为来自不同数据库的心电图生成详细的文本描述,生成的文本包含人口统计学信息和波形模式信息。通过这种方法,我们构建了一个包含超过 66 万组 “心电图 - 文本” 对的大规模多模态数据集,用于 ESI 的预训练;最终,ESI 成功学习到 12 导联心电图的鲁棒且具有泛化性的特征表示。
我们通过多种下游任务对所提方法进行验证,包括心律失常检测和基于心电图的受试者身份识别。实验结果表明,在这些任务中,我们的方法相较于性能强大的基准模型实现了显著提升。这些基准模型涵盖有监督学习方法、自监督学习方法以及以往的多模态预训练方法。本研究证实,结合多模态预训练技术对改进心电图信号分析具有巨大潜力。
1. 引言
心电图(ECG)能够以无创方式全面反映心脏电活动,是心血管疾病诊断与临床决策中的重要工具(Kligfield 等,2007)。例如,心电图已被广泛应用于多种临床场景,如诊断心血管疾病(Jain 等,2014)、阻塞性睡眠呼吸暂停(Faust 等,2016)以及帕金森病(Haapaniemi 等,2001)等。另一方面,深度学习的快速发展引发了人们对采用数据驱动方法进行心电图数据分析的广泛关注。这些深度学习方法因其具备学习复杂表征的能力,已被证明能有效提升心电图分析的准确性与预测能力(Hannun 等,2019)。通常而言,利用心电图信号的初始步骤是从原始数据中提取特征,提取方式既包括传统的特征工程,也包括近年来涌现的深度学习架构,例如一维卷积神经网络(1D CNN)[Zhu 等(2020);Baloglu 等(2019);Jing 等(2021)] 以及 Transformer 模型 [Meng 等(2022);Behinaein 等(2021);Natarajan 等(2020);Guan 等(2021);Yan 等(2019)]。然而,这些有监督学习方法往往需要大规模、高质量的带标注训练样本,而获取此类样本的成本较高(Mincholé & Rodriguez,2019)。
为减少对大量标注的依赖,研究人员已针对心电图(ECG)信号探索自监督学习(SSL)技术(Eldele 等人,2021;Kiyasseh 等人,2021;Yu 等人,2023;Gopal 等人,2021)。这些方法在预训练深度特征提取器时会利用未标记数据。然而,自监督学习策略(这类策略包含诸如对齐不同信号视图或重建被掩码片段等任务)主要聚焦于信号本身。这意味着这些自监督学习方法主要关注波形特征,却忽略了信号的语义信息。因此,无法保证这些方法在预训练阶段能有效学习到鲁棒表征,进而在下游任务中提升心电图分析性能。
其他研究则借助多模态学习方法,并将描述性文本等额外模态融入预训练过程。通过实现对数据更细致、更全面的理解,该方法已展现出优异的预训练性能(Radford 等,2021;Jia 等,2021;Yu 等,2022b)。受图像 - 文本对多模态预训练成功案例的启发,研究人员针对心电图(ECG)与其他模态的配对数据开发了类似方法,这些配对模态包括标签文本(Li 等,2024)、电子健康记录(EHR)(Lalam 等,2023)以及临床报告(Liu 等,2024)。然而,为心电图获取大量此类模态数据的成本同样较高 —— 相较于通用计算机视觉任务,心电图分析需要依赖专业知识的语义信息。此外,不同心电图数据集及数据来源在术语和细节上存在差异,这给整合多个数据源以构建更大规模预训练数据集带来了挑战。
为应对上述挑战,我们提出一种两步式多模态对比预训练框架,以优化从心电图(ECG)信号中学习到的表征。我们设计了一个基于检索增强生成(RAG)的流程 —— 心脏查询助手(Cardio Query Assistant, CQA),用于为心电图生成标准化且信息丰富的文本描述。借助 RAG 能从心电图教科书中检索相关信息的能力,CQA 可将基础心电图数据转化为包含患者人口统计学信息和特定波形特征的增强型文本描述。此外,基于 CQA 生成的增强型文本描述,我们引入了心电图语义整合器(ECG Semantics Integrator, ESI)—— 这是一种受(Yu 等,2022b)启发、融入描述生成损失(captioning loss)的对比学习框架。ESI 可实现心电图信号与其对应文本标注的对齐,旨在通过预训练编码器,提升对心电图内容的语义理解能力。我们的研究贡献总结如下:
- 我们提出了一个基于检索增强生成(RAG)的心电图描述生成流程 CQA(心脏查询助手),该流程利用人口统计学信息和诊断情况为心电图样本构建描述性文本语境。
- 我们开发了具备对比学习与描述生成双重能力的 ESI(心电图语义整合器)框架,并将其用于预训练过程,在约 65 万份 12 导联心电图信号上训练出一个心电图基础模型。
- 与包括此前最优(SOTA)有监督方法和自监督学习(SSL)方法在内的强劲基准模型相比,我们的评估结果显示,该模型在心律失常检测和基于心电图的用户身份识别任务中表现优异。例如,与此前的自监督学习方法相比,该模型在心律失常类别诊断的曲线下面积(AUC)评分上提升了1.6%,在用户身份识别准确率上提升了 3.5%。
2. 相关工作
2.1 多模态表示学习
近年来的研究提出了用于整合图像与文本的基础模型,这类模型既涉及视觉预训练,也包含视觉 - 语言预训练。视觉 - 语言预训练旨在构建多模态基础模型,以提升其在下游视觉任务与语言任务中的性能。诸如 CLIP(Radford 等,2021)、ALIGN(Jia 等,2021)、Florence(Yuan 等,2021)和 LiT(Zhai 等,2022)等模型均采用双编码器架构,能将图像 - 文本对映射到同一个共享嵌入空间中。这些模型通过对比目标函数进行训练:对于匹配的图像 - 文本对,该函数会拉近它们的嵌入向量距离;而对于不匹配的图像 - 文本对,则会推远其嵌入向量距离。实践证明,这种方法能为图像和文本两种模态构建具有鲁棒性与可迁移性的表征,进而显著提升各类视觉 - 语言任务的性能。
与此同时,其他研究探索了采用生成式目标函数的编码器 - 解码器架构。CoCa(Yu 等,2022b)、SimVLM(Wang 等,2021)、BLIP(Li 等,2022)、BLIP-2(Li 等,2023b)以及 OFA(Wang 等,2022)等模型均整合了编码与解码过程,这使得模型能够从视觉输入中生成文本。这些模型将语言建模与图像 - 文本匹配相结合,可生成具有语义意义的输出结果。该研究方向同样展现出多模态学习所具备的灵活且强大的潜力,并且在各类视觉 - 语言基准测试中均表现出优异性能。
这些多模态预训练技术的优势并非仅限于通用图像与文本数据。研究人员已将这类方法应用于医学影像领域,尤其在放射影像与临床报告的配对分析中(Liu 等,2023;You 等,2023;Wan 等,2024)。然而,尽管基于图像的应用已取得进展,将这些多模态预训练方法用于心电图(ECG)信号处理的研究仍相对不足。在本研究中,我们将这些先进技术拓展至心电图数据,以期在临床场景下获得更具鲁棒性与泛化性的表征。
2.2使用深度学习进行ECG诊断
2.2.1监督方法
深度学习在心电图(ECG)诊断中的应用已引起广泛关注(Liu 等,2021;Pyakillya 等,2017;Sannino & De Pietro,2018;Wagner 等,2020;Śmigiel 等,2021;Mostafa 等,2019)。例如,Śmigiel 等(2021)提出了一种结合额外熵基特征的卷积神经网络(CNN)模型,用于心律失常分类。该方法在 5 个类别上的曲线下面积(AUC)评分达到 0.91。Mostafa 等(2019)则对深度学习在心电图分析中用于睡眠呼吸暂停检测的应用进行了全面综述,重点强调了卷积神经网络(CNN)和循环神经网络(RNN)等模型的成效 —— 这些模型在特定数据集上的准确率可超过 90%。尽管这些方法的有效性已得到证实,但其所需的临床标注数据获取成本往往较高。
2.2.2 ECG中的单峰表示学习
鉴于临床标注成本较高,旨在减少对带标签心电图(ECG)序列依赖的预训练方法已引起越来越多的关注(Sarkar & Etemad,2020;Mehari & Strodthoff,2022;Oh 等,2022)。例如,Mehari & Strodthoff(2022)将 SimCLR(Chen 等,2020)、BYOL(Grill 等,2020)和 CPC(Oord 等,2018)等知名自监督学习(SSL)框架应用于 12 导联心电图数据的模型预训练。这些模型展现出更强的鲁棒性,具体表现为:在 5 分类心律失常任务中,其曲线下面积(AUC)评分较纯有监督模型提升了 2%。然而,尽管预训练策略通常能为性能提升提供思路并降低对带标签数据的依赖,但这类方法往往存在局限 —— 它们仅关注信号波形。仅强调波形无法确保捕捉到具有临床意义的语义信息。因此,结合心电图波形与对应临床文本的多模态方法,有助于为各类下游任务获取更具意义且可迁移的心电图表征。
2.2.3 ECG中的多模态表示学习
尽管相关研究数量较少,但已有部分研究开始探索心电图(ECG)信号与其他模态(如文本描述、电子健康记录(EHR)及临床记录)的对齐方法(Li 等,2023a;Lalam 等,2023;Liu 等,2024)。例如,Lalam 等(2023)采用相同的编码器,从心电图、电子健康记录和临床记录中提取嵌入向量,并通过对比学习实现模态对齐。经预训练的模型在临床诊断任务中展现出良好效果。Liu 等(2024)则采用类似方法,将心电图信号与临床记录关联,提升了心电图编码器在零样本心律失常检测任务中的效能。然而,这些方法的预训练过程依赖于临床记录、电子健康记录等成本高昂的标注数据,而大规模获取此类数据存在较大挑战。此外,由于临床医师的记录习惯、术语使用差异及临床场景不同,与心电图配套的文本描述或报告在细节、术语和风格上存在变异性,这可能导致模型难以学习到心电图信号与文本之间稳定一致的映射关系。这种变异性最终可能造成心电图 - 文本对的对齐偏差。
在本研究中,我们提出采用基于检索增强生成(RAG)的流程构建心电图文本语境数据,无需依赖成本高昂的临床记录与电子健康记录。同时,我们在模型中引入描述生成任务(captioning task),以获取更细致的表征。
3. 方法
在本节中,我们将从三个主要部分介绍我们的方法:(1)基于检索增强生成(RAG)的心电图描述生成流程 —— 心脏查询助手(Cardio Query Assistant, CQA);(2)对比描述生成预训练框架 —— 心电图语义整合器(ECG Semantics Integrator, ESI)。
3.1 Cardio Query Assistant(CQA)框架
如图1 所示,心脏查询助手(CQA)框架旨在将心电图(ECG)状态标签转化为详细的描述性文本。生成的文本包含人口统计学信息、心电图状态以及丰富的波形细节。图 2 提供了一份原始心电图信号、其相关元数据以及生成的心电图波形描述示例。所开发的 CQA 框架具体说明如下:
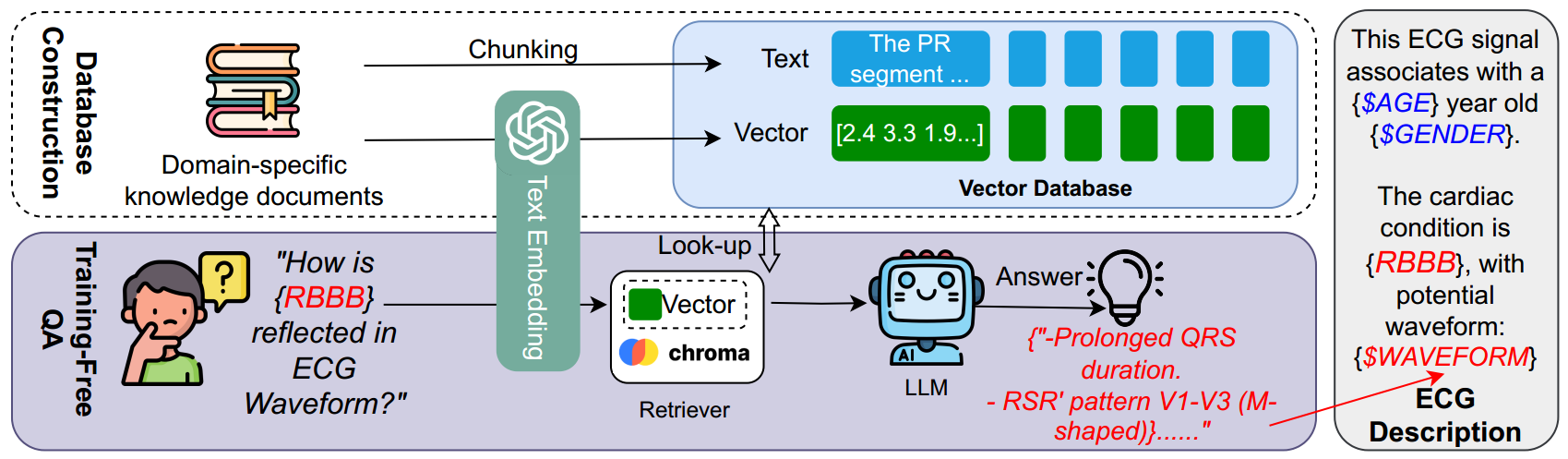
图 1:心脏查询助手(Cardio Query Assistant, CQA)框架采用一种新颖的基于知识的方法,为心电图(ECG)信号生成详细且具有临床相关性的文本描述,该方法可将心电图病症转化为更丰富的心电图波形模式。
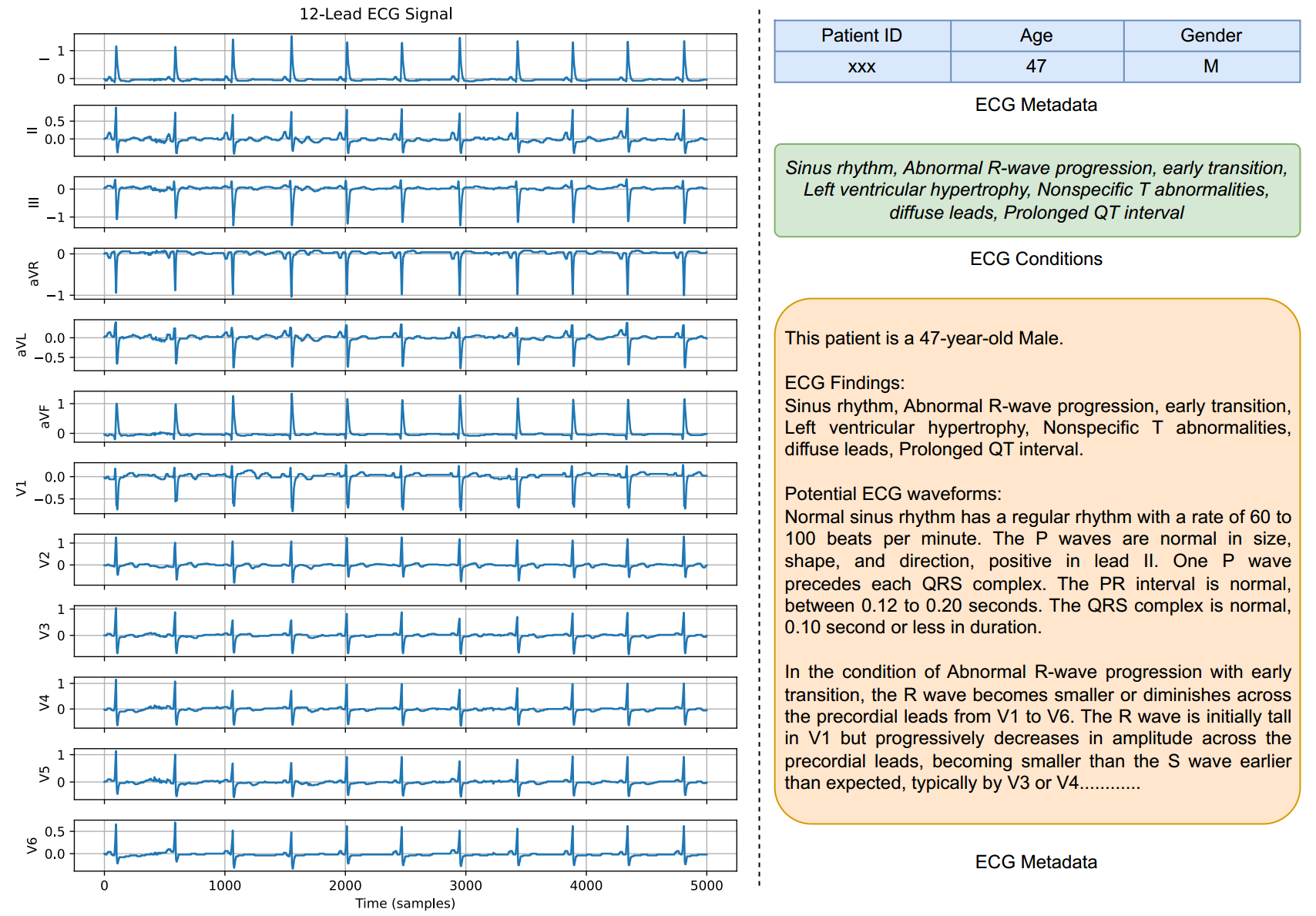
图 2:12 导联心电图信号及其相关元数据示例。左侧展示 12 导联心电图波形,该波形直观呈现了心脏的电活动情况;右侧包含患者相关的人口统计学信息(年龄、性别)、心电图元数据摘要(其中涵盖高层级临床发现,如窦性心律、R 波进展异常等),以及通过 CQA(心脏查询助手)流程生成的心电图病症详细文本描述。
3.1.1建立特定领域知识数据库
为借助领域专业知识增强对心电图(ECG)状态的解读能力,我们以两本权威医学教材为指导,从特定领域的文献中构建了一个全面的向量数据库。这两本教材分别是:(1)赫夫(Huff)所著的《心电图实操:心律失常判读训练》(ECG Workout: Exercises In Arrhythmia Interpretation,2006 年);(2)加西亚(Garcia)所著的《12 导联心电图:判读技巧》(12-Lead ECG: The Art of Interpretation,2015 年)。为将这些信息提取并编码为可用格式,我们采用了 text-embedding-ada-002 接口(OpenAI,2023),其选择依据是该接口兼具高效性与优异性能。随后,我们使用 Chroma 数据库管理工具对生成的嵌入向量进行系统化整理 —— 选择该工具的原因在于其具备良好的鲁棒性,且易于与 LangChain Python 库集成(Mendable,2023)。
3.1.2 ECG语义的增强
CQA 框架通过全面的检索增强流程丰富与心电图(ECG)相关的信息。借助预先构建的领域知识数据库,这种基于检索增强生成(RAG)的方法使 CQA 能够利用给定信息查询相关知识,这些信息包括标准临床标签、心电图计算机辅助诊断标准通信协议(SCP)表述、诊断解读以及与心电图数据相关的机器生成报告。其中,SCP 表述是标准化文本格式,遵循心电图计算机辅助诊断国际协议,为心电图检查结果提供一致性记录。尽管这些数据集提供了有价值的诊断信息,但它们通常缺乏关于波形模式的明确细节 —— 而这些细节对于全面的心电图分析至关重要。
为填补这一空白,CQA 框架采用了检索增强生成(RAG)方法,使其能够查询前一节中介绍的知识数据库以获取相关信息,并生成关于潜在波形特征的全面文本描述。例如,心电图计算机辅助诊断标准通信协议(SCP)表述及标准心律失常诊断结果可能未直接包含详细的波形描述;但通过查询领域知识数据库,CQA 框架能够整合这些丰富信息,生成与特定心电图(ECG)状态相对应的波形模式详细描述。
为填补这一空白,心脏查询助手(CQA)框架采用了检索增强生成(RAG)方法,使其能够查询前一节中介绍的知识数据库以获取相关信息,并生成关于潜在波形特征的全面文本描述。例如,心电图计算机辅助诊断标准通信协议(SCP)表述及标准心律失常诊断结果可能未直接包含详细的波形描述;但通过查询领域知识数据库,CQA 框架能够整合这些丰富信息,生成与特定心电图(ECG)状态相对应的波形模式详细描述。
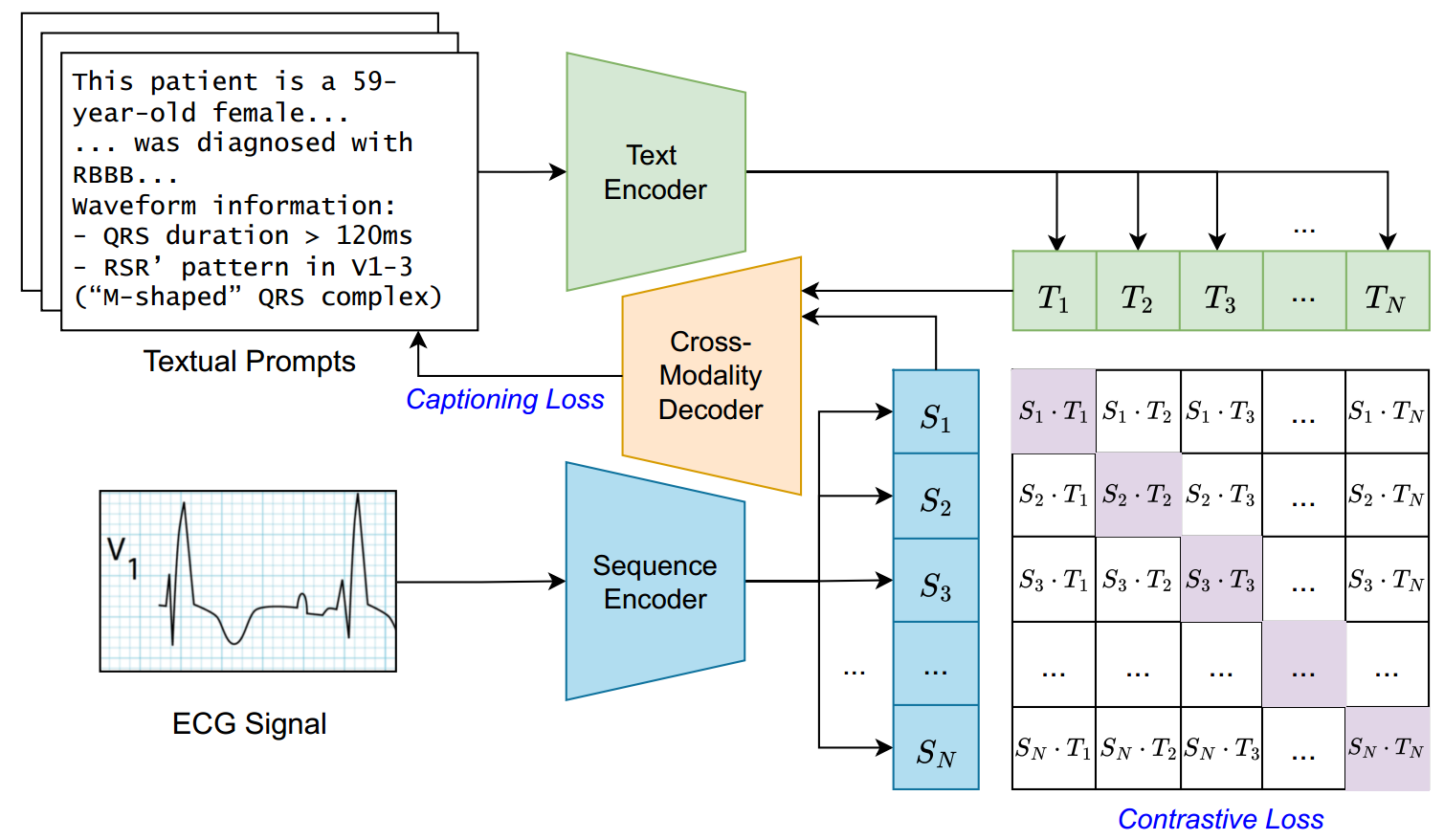
图 3:心电图语义整合器(ECG Semantics Integrator, ESI)以心电图信号编码器和文本编码器为基础构建,通过描述生成损失与对比损失实现统一表征。该架构从详细文本提示与对应心电图波形数据的对齐关系中学习,旨在捕捉细微的临床洞察,以优化诊断任务性能。
3.2基于ESI框架的多模态对比字幕
心电图语义整合器(ESI)框架旨在通过对专用心电图(ECG)编码器与文本编码器进行联合预训练,提升从心电图信号中提取的表征质量。这种双模态训练方法已得到对比语言 - 图像预训练(CLIP)(Radford 等,2021)和 CoCa(Yu 等,2022b)等前沿研究方法的验证。受这两项研究的启发,我们设计了兼具对比学习目标与生成式学习目标的预训练架构。尽管我们注意到,如 2.1 节所述,在多模态对比学习领域,除 CLIP 和 CoCa 之外还存在更新的方法,但选择基于上述两者进行架构开发,主要出于以下几方面原因:首先,CLIP 结构的有效性已得到多项前期研究的充分验证,这些研究涵盖医学图像与语言的联合预训练(Liu 等,2023;You 等,2023;Wan 等,2024)以及生理信号与语言的联合预训练(Li 等,2023a;Lalam 等,2023;Liu 等,2024)。CLIP 的核心对比学习目标,与我们实现 “心电图信号与其文本解读对齐” 的主要目标高度契合。此外,CLIP 架构相对简洁,便于无缝整合我们借鉴自 CoCa(Yu 等,2022b)的描述生成损失(captioning loss)。关于对比学习目标与生成式学习目标的作用,我们将在 5.1 节通过消融实验进一步验证。
对于心电图编码器,考虑到心电图波形数据的时序特性,我们选择了 ConvNext v2 架构的一维改进版本(Woo 等,2023)。该架构经证实,能够通过其设计的卷积核提取局部和全局上下文信息。同时,文本编码器采用 BioLinkBERT—— 这是 BERT 架构的一个衍生模型,通过在生物医学文本上预训练,可有效嵌入医学术语(Yasunaga 等,2022)。BioLinkBERT 是标准 BERT 模型(Devlin 等,2018)的扩展,专为提升生物医学文本的理解能力而设计。与传统 BERT(独立处理每个文档)不同,BioLinkBERT 在 PubMed 的生物医学文献上进行预训练,充分利用了文档间的天然关联(如引用和参考文献)。这种预训练策略促使我们在需要深入理解生物医学概念和术语的任务中采用 BioLinkBERT。
3.2.1多模态对比学习
受此前视觉 - 语言预训练方法(Radford 等,2021;Yu 等,2022b)的启发,我们的框架采用两个预训练目标以实现全面学习,包括用于鲁棒表征学习的对比损失(contrastive loss)和用于语义对齐的描述生成损失(captioning loss)。
对比损失(Contrastive Loss):本研究参照前期研究,采用双编码器对比学习框架。与 SimCLR(Chen 等,2020)、BYOL(Grill 等,2020)等聚焦信号、采用单编码器的预训练框架不同,本研究中的双编码器方法充分利用了文本模态所包含的语义信息。两个编码器的目标均为将输入的心电图(ECG)信号与文本数据映射至同一个统一嵌入空间。在此基础上,通过在采样批次中对比配对文本与其他非配对文本,对两个编码器进行联合优化,具体过程如下:
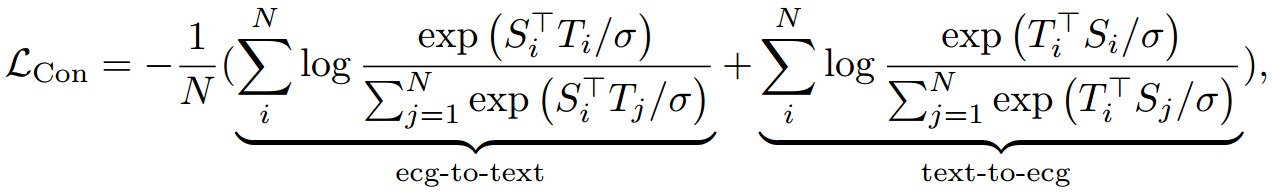

描述生成损失(Captioning Loss):在双编码器方法中,文本被编码为嵌入向量以用于对比学习;而生成式方法则追求更细致的粒度,要求模型结合心电图(ECG)信号与前文文本,预测出精确的分词文本(tokenized texts)。该方法可促使编码器主动捕捉文本中蕴含的语义信息。受图像 - 文本多模态预训练研究 CoCa(Yu 等,2022b)的启发,我们额外定义了一个描述生成损失(L_{cap})(其设计参考了图像描述生成任务中使用的损失函数(Vinyals 等,2015)),以此实现生成的文本描述与对应心电图信号的对齐,具体定义如下:
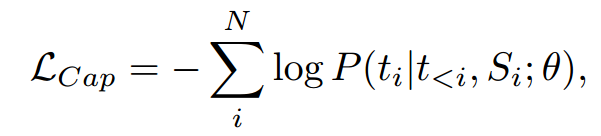

整体预训练目标是对比损失(contrastive loss)与描述生成损失(captioning loss)的结合,具体表示为:
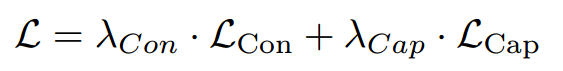
其中,lambda_{Con} 和 lambda_{Cap} 是所引入损失函数(对比损失与描述生成损失)对应的损失权重超参数。本研究中,我们将这两个权重参数均设为 1。通过对这些损失函数进行联合优化,心电图语义整合器(ESI)框架旨在学习一种多模态表征,该表征能够强化心电图波形与其文本解读之间的语义关联。这种方法有望提升下游任务的性能 —— 这些任务需利用波形细节与人口统计学信息,例如心律失常诊断以及基于心电图数据进行大规模患者身份识别。
4评价
在本节中,我们将介绍评估设置与实验结果。首先,我们会说明本研究中使用的数据集信息、执行的任务,以及用于对比的基准方法。我们的实验探索了三种设置:零样本学习(zero-shot learning)、线性探测(linear probing,特征冻结)和微调(fine-tuning)。实验过程中,我们通过多次重采样运行来评估模型的鲁棒性,尤其是在线性探测和微调设置下。由于在线性探测评估阶段编码器处于冻结状态,随机性仅作用于线性探测设置中的输出线性层(linear heads)。对于每种设置,我们均对五次不同运行的结果取平均值,并在报告平均性能指标的同时,附上标准差。
4.1训练设置
预训练数据集:本文所提出的心电图语义整合器(ESI)信号编码器采用从头开始预训练(pretrained from scratch)的方式。因此,预训练数据集直接影响模型的泛化能力。我们构建了一个大型预训练数据集,该数据集融合了三个大规模数据集,包含超过 65 万对心电图 - 文本(ECG-text)训练样本。这三个数据集分别是 Chapman-Shaoxing 数据集(Zheng 等,2020)、PTB-XL 数据集(Wagner 等,2020)和 MIMIC-ECG 数据集(Gow 等,2023)。每个数据集均包含 12 导联、时长 10 秒、采样率为 500 赫兹(Hz)的心电图记录。以下是各数据集的详细说明:
- PTB-XL 数据集:该数据集包含来自 18,885 名受试者的 21,837 条 12 导联、10 秒时长的心电图记录。我们遵循原始文献(Wagner 等,2020)中规定的训练集与测试集划分准则,在预训练任务中仅使用训练样本(1.7 万条)。这些样本包含人口统计学数据和心电图计算机辅助诊断标准通信协议(SCP)编码。
- Chapman-Shaoxing 数据集:该数据集提供了规模更大的样本集,共 4.5 万条样本,附带有人口统计学信息和心律失常诊断结果。
- MIMIC-IV-ECG 数据集:这是规模最大的数据集,包含 60 万条样本,同时附带人口统计学信息和机器生成的心电图报告。
数据的多样性与体量为模型预训练提供了全面的基础。表 1 总结了预训练所用各数据集的概况信息。

表 1:预训练阶段所用数据集汇总
实现细节:在心电图语义整合器(ESI)模型的预训练阶段,我们针对编码器架构、优化器、学习率调度器、训练硬件及批次大小做出了具体选择。ESI 中的心电图(ECG)信号编码器默认采用 1D ConvNeXt-base(Woo 等,2023)作为骨干网络。该选择能让模型有效捕捉心电图信号数据中的空间特征。在文本编码方面,我们默认采用 BioLinkBert(Yasunaga 等,2022),其原因是该模型在处理生物医学文本数据上的能力已得到验证。预训练过程中,优化环节采用 AdamW 优化器。我们将初始学习率设定为 5×10⁻⁵,以实现高效收敛。为在整个训练过程中进一步调整学习率,在总共 30 个训练周期(epoch)中,前 5 个周期设置为热身阶段(warm-up phase)。此热身阶段可让模型在启用主学习率前,逐步适应训练数据。此外,每完成 10 个周期便引入 0.1 倍的学习率衰减(learning rate decay),以防止训练后期出现过拟合现象。
预训练过程在一台配备了 4 块英伟达(Nvidia)A100 图形处理器(GPU)的服务器上进行。这种硬件配置能够提供高效处理预训练所用大型数据集所需的计算资源。为有效利用这些 GPU 的性能,训练期间每块 GPU 上的批次大小(batch size)设置为 48 个样本。
除主 ESI 模型外,我们还实现了一个参数高效的变体模型,命名为 ESI-tiny。该变体模型采用 ConvNeXt-tiny 架构作为心电图(ECG)编码器,所预训练出的模型整体规模更小。这在计算资源有限的场景下会具备显著优势。
4.2用于下游任务的ECG语义集成器(ESI)
预训练阶段结束后,编码器可通过三种不同方式应用于各类下游任务,包括零样本推理(zero-shot inference)、线性探测(linear probing)和微调(fine-tuning)。此举旨在验证所学表征的鲁棒性,以及模型在真实临床场景中的实际应用价值。其中,零样本推理与线性探测可直接评估该框架所学表征的质量;而在这三种方法中,微调模型通常能实现最佳性能 —— 其通过下游任务对模型参数进行更新优化。如图 4 所示,在不同下游任务中,我们的 ESI 方法经微调后的编码器,性能均优于有监督学习(supervised)和自监督学习(self-supervised)基准模型。
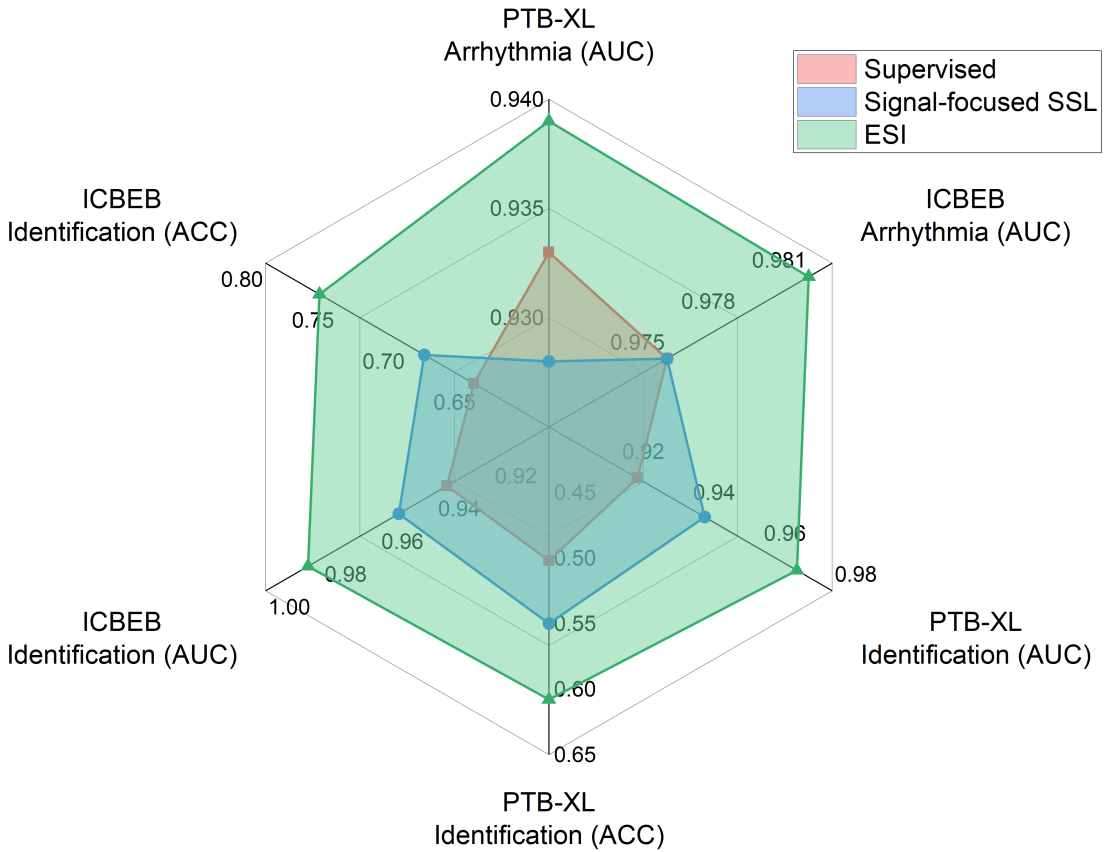
图 4:所提心电图语义整合器(ECG Semantics Integrator, ESI)与基准方法(包括有监督模型及聚焦信号的自监督学习(SSL)预训练模型)最佳性能的对比。与基准方法相比,ESI 是一种多模态对比预训练框架,它同时利用心电图(ECG)信号和对应文本描述,学习更优的心电图表征。心律失常诊断与识别任务的评估在 PTB-XL 和 ICBEB 等数据集上开展,采用的评估指标为受试者工作特征曲线下面积(AUC)和准确率(ACC)。
4.2.1 零样本评估
零样本评估旨在评估模型无需任何任务特定微调,即可从心电图(ECG)信号中理解并推断信息的能力。参照 CoCa(Yu 等,2022b)和 CLIP(Radford 等,2021)相关研究中采用的定义,我们的零样本评估策略确保:尽管模型在预训练阶段接触过大量心电图 - 文本对,但它从未见过任何来自下游任务的有监督样本。在心电图语义整合器(ESI)框架中,无需任务特定微调,即可将每个心电图信号的嵌入向量与一系列对应不同心脏疾病的潜在文本标签进行比较。模型会选择与心电图信号嵌入向量距离最近的文本描述,该距离由余弦相似度(cosine similarity)这一相似性度量指标确定。此过程可体现模型对心电图数据的理解能力,以及预训练完成后直接将其与准确临床描述关联的能力 —— 这一设计旨在证明:无需针对特定任务进行微调,模型所学表征仍具备潜在的泛化能力。
4.2.2 线性探测(Linear Probing)
线性探测是一种利用 ESI 框架编码器所学表征的策略。在此设置中,在冻结的编码器之上部署一个线性分类器,以用于心律失常检测、患者识别等不同下游任务。由于模型中唯一可训练的部分是分类器头,因此,预训练编码器输出表征的质量与鲁棒性在该线性探测策略中起着至关重要的作用。
4.2.3 微调(Fine-Tuning)
为给预训练的信号编码器引入更多灵活性,我们也可在一系列下游任务上对整个框架进行微调。与线性探测策略类似,但此处编码器是可训练的;这种微调策略旨在将预训练参数作为下游任务的初始化参数,以此探索该结构的全部有效性。
4.3 下游任务:心律失常诊断
心律失常是导致心血管疾病的重要因素之一,临床实践中亟需准确、可靠的心律失常检测方法。本研究采用两个数据集 ——PTB-XL 数据集(Wagner 等,2020)与 ICBEB 数据集(Liu 等,2018),对所提方法在心律失常检测任务上的性能进行评估。如 4.1 节所述,我们依据 PTB-XL 数据集原始文献(Wagner 等,2020)中规定的训练集与测试集划分准则,对该数据集进行划分:训练集用于模型微调,而预训练阶段未接触过的测试集则用于性能评估。ICBEB 数据集在预训练阶段未被使用,该数据集包含来自 9458 名患者的 9831 条 12 导联心电图信号(Liu 等,2018)。我们采用此前一项基准研究(Strodthoff 等,2020)中的数据处理设置,最终得到 6877 条训练样本与 2954 条测试样本。基于上述配置,我们在微调(fine-tuning)、线性探测(linear probing)与零样本学习(zero-shot learning)三种设置下,对模型的有效性进行了评估。
4.3.1 微调与线性探测
为进行全面评估,我们将所提方法与专门的有监督方法进行了对比,包括长短期记忆网络(LSTM)、XResNet101、ResNet50、一项心电图基准研究(Strodthoff 等,2020)中实现的集成方法、多导联分支融合网络(MLBF-Net)(Zhang 等,2021)以及多视图多尺度神经网络(MVMSN)(Yang 等,2023)。除有监督学习方法外,我们还将所提方法与聚焦信号的自监督学习(SSL)方法进行了对比,包括 SimCLR(Chen 等,2020)、BYOL(Grill 等,2020)、CLOCS Kiyasseh 等,2021)和 LEAVES(Yu 等,2022a)。为确保对比的公平性,训练这些方法所使用的深度学习骨干网络与所提 ESI 方法相同,均为 ConvNeXt-base。我们对这些预训练方法均采用了线性探测和微调两种策略,以评估其在预训练阶段所学表征的质量。此外,我们还在其研究所述的编码器冻结设置下,与 MERL(Liu 等,2024)进行了基准性能对比。
表 2 展示了各评估方法的性能表现。在有监督学习方法中,ConvNeXt 和 ConvNeXt-tiny 编码器的性能低于多导联分支融合网络(MLBF-Net)、多视图多尺度神经网络(MVMSN)等专门设计的方法。其中,ConvNeXt-tiny 的性能优于规模更大的 ConvNeXt 模型,这可能是因为在较小数据集上,ConvNeXt 模型出现了过拟合现象。经过预训练后,基于 ConvNeXt 的 ESI 方法在编码器冻结和微调两种设置下,均在 PTB-XL 和 ICBEB 两个数据集上取得了最佳性能。值得注意的是,多模态预训练方法(ESI 和 MERL)的性能显著优于 SimCLR、BYOL 等聚焦信号的方法。这一结果印证了我们的假设:与多模态预训练方法相比,聚焦信号的方法在学习适用于下游任务的鲁棒且可迁移的表征方面可能存在局限性。此外,预训练的 ESI 编码器相较于有监督学习方法中的冻结编码器表现更优,这也证明了其所学特征在心律失常诊断任务中的鲁棒性。
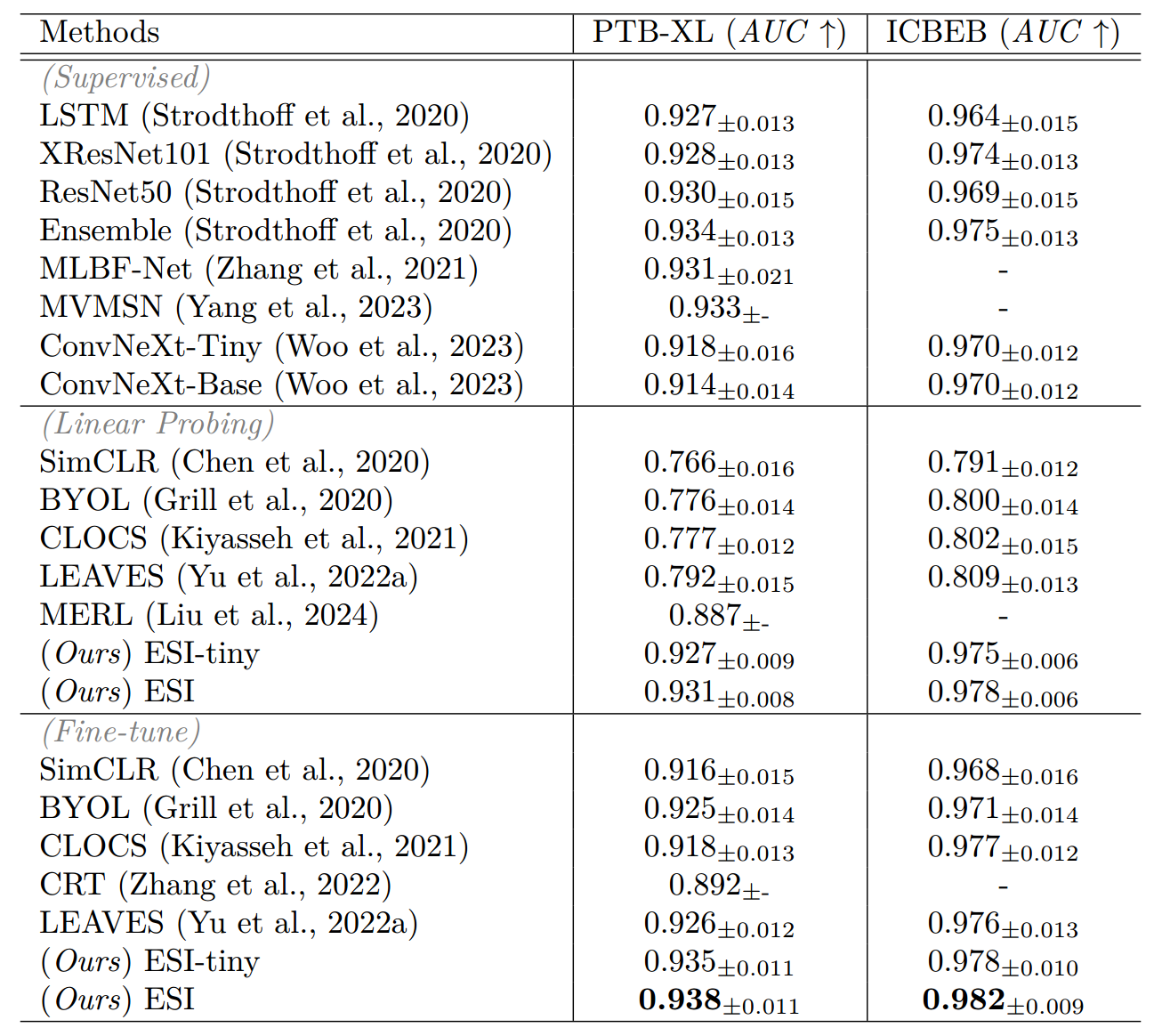
表 2:不同设置下心律失常诊断任务的评估结果,设置包括有监督学习、线性探测(编码器冻结)和微调。所使用的评估指标为受试者工作特征曲线下面积(AUC)。最佳结果以粗体突出显示。
4.3.2 零样本推理
为进一步评估预训练阶段所学的表征,我们还参照 METS(Li 等,2023a)和 MERL(Liu 等,2024)的方法,开展了零样本学习推理评估。除零样本评估外,我们还在对比中纳入了现有聚焦信号的自监督学习(SSL)方法的少样本设置 —— 包括 SimCLR(Chen 等,2020)、BYOL(Grill 等,2020)、CLOCS(Kiyasseh 等,2021)和 LEAVES(Yu 等,2022a),在 PTB-XL 数据集上使用原始训练集的 5% 作为训练样本进行实验。
表 3 展示了所提 ESI 方法与基准方法(METS、MERL)的零样本学习推理性能,以及聚焦信号的自监督学习(SSL)方法的少样本微调结果。与所有其他方法相比,所提方法在曲线下面积(AUC)和宏 F1 分数(macro F1 score)两项指标上均取得了最佳性能。此外,即便在微调阶段未使用样本,基于心电图 - 文本 (ECG-text)预训练的模型总体上仍优于聚焦信号的预训练方法。这一结果凸显了多模态预训练技术所获表征的鲁棒性得到了提升。
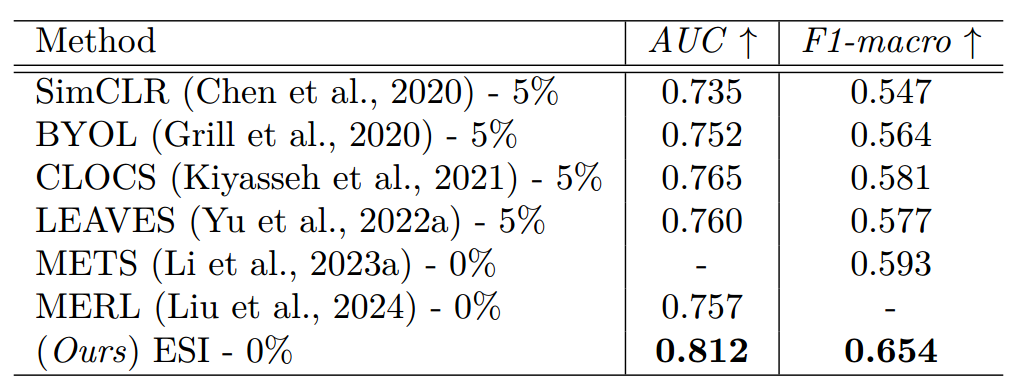
表 3:PTB-XL 数据集上零样本学习(zero-shot learning)模式下,不同设置中心律失常诊断任务的评估结果。本表使用的评估指标为受试者工作特征曲线下面积(AUC)和宏 F1 分数(F1-macro)。其中,“X − %” 表示在对预训练编码器进行微调时,所使用的训练样本占训练集的百分比为 X。最佳结果以粗体突出显示。
4.4下游任务:基于ECG的用户识别
心电图(ECG)通常呈现出可区分个体的独特模式,这使得其适用于受试者身份识别任务,且相较于其他生物特征具有潜在优势(Melzi 等,2023)。例如,与通过面部图像进行身份识别相比,使用心电图在应用过程中能进一步保护用户隐私。本研究利用此前在心律失常诊断任务中已使用过的 PTB-XL 数据集(Wagner 等,2020)和 ICBEB 数据集(Liu 等,2018),设计了一个用于心电图身份识别的单样本学习(one-shot learning)基准。与 4.3 节中的心律失常诊断任务类似,本任务仅关注 PTB-XL 和 ICBEB 数据集的测试集部分。对于 PTB-XL 数据集,我们从 1907 名受试者中每人选取一段 5 秒的信号序列,分别用于训练和测试,由此构成一个 1907 分类任务。同理,我们从 ICBEB 数据集中选取 4 秒的信号样本并确定类别,形成一个 689 分类任务。
在本任务中,我们在线性探测与微调两种设置下,将所提 ESI 方法的性能与多种方法进行了对比。对于专门的有监督方法,我们将所提方法与已验证的有监督学习模型进行对比,包括长短期记忆网络(LSTM)、XResNet101、ResNet50,以及集成方法(Strodthoff 等,2020)。除有监督学习方法外,我们还在线性探测与微调设置下,将 ESI 方法与聚焦信号的自监督学习(SSL)方法进行性能评估对比,这些 SSL 方法包括 SimCLR(Chen 等,2020)、BYOL(Grill 等,2020)、CLOCS(Kiyasseh 等,2021)和 LEAVES(Yu 等,2022a)。由于在预训练阶段已对患者信息进行了去标识化处理,模型未接触过可用于身份识别的患者信息,因此无法在该身份识别任务中进行零样本学习。
表 4 总结了相关研究结果。结果显示,在线性探测与微调两种设置下,ESI 方法的性能均显著优于各基准方法。值得注意的是,与有监督 ConvNeXt 基准模型相比,经微调的 ESI 方法在准确率上实现了大幅提升(PTB-XL 数据集提升 12.0%,ICBEB 数据集提升 12.2%)。此外,在线性探测设置下,ESI 方法的性能也远超聚焦信号的 SSL 方法,优势显著。这些结果表明,结合心电图(ECG)与文本数据的多模态预训练,在学习可迁移表征以用于心电图身份识别任务方面具有显著有效性。
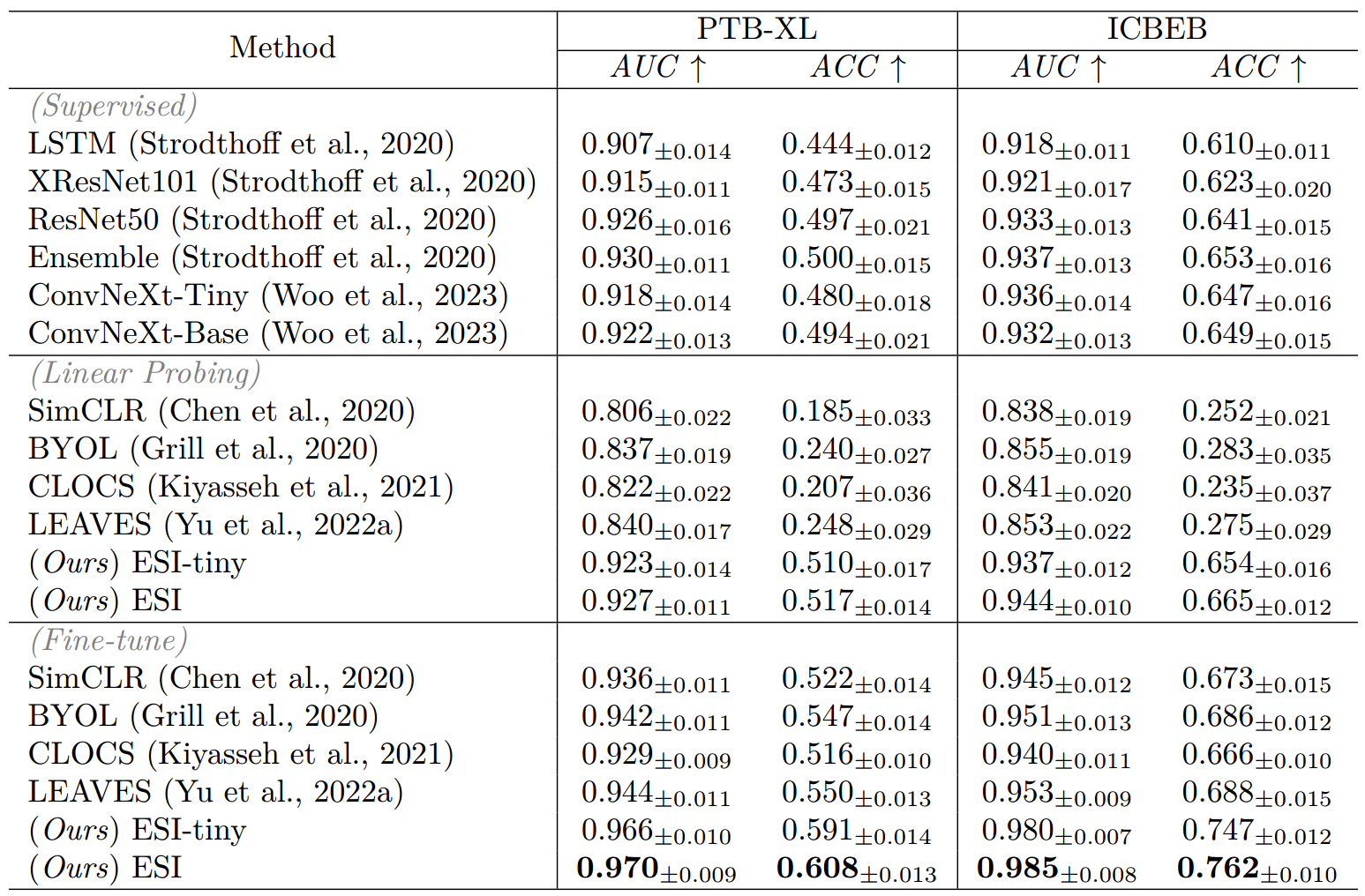
表 4:基于心电图(ECG)的 1 样本用户识别任务在不同设置下的评估结果,设置包括有监督学习、线性探测和微调。所使用的评估指标为受试者工作特征曲线下面积(AUC)和准确率(ACC)。最佳结果以粗体突出显示。
5 讨论
在本节中,我们首先对所设计组件的消融实验结果进行讨论,包括对比 - 问答(CQA)模块的有效性、信号编码器的选择,以及 captioning 损失(描述生成损失)和对比损失对所学表征的贡献。消融实验主要基于 ESI-tiny 这一小型模型变体开展,该变体采用 ConvNeXt-tiny 作为信号骨干网络。此外,我们还探究了预训练数据规模对模型的影响,以及可能存在的 “模态错位” 问题对所提方法的影响。
5.1 消融实验:组件分析与影响
我们通过开展消融实验,评估预训练框架中各独立组件的贡献。实验基于采用 ConvNeXt-tiny 信号编码器的 ESI-tiny 模型变体,在 PTB-XL 数据集上分别评估了预训练模型在心律失常诊断和基于心电图(ECG)的用户身份识别两项任务上的性能。模型评估采用编码器冻结的线性探测设置,以曲线下面积(AUC)分数作为主要评价指标。
表 5 (a) 总结了本消融实验的结果。移除对比 - 问答(CQA)模块会导致两项任务的 AUC 分数均下降。这表明 CQA 有助于将心电图(ECG)信号与其丰富的文本标注对齐;通过对齐这些模态,CQA 能帮助模型学习到更鲁棒的表征,从而捕捉心电图模式与相关诊断之间的内在联系。移除描述生成损失(LCap)同样会使心律失常诊断和心电图身份识别任务的性能下降,这说明模型从预训练阶段明确生成描述文本的过程中受益。而移除对比损失(LCon)时,观察到的性能影响最为显著:通过将心电图与不同文本表征进行对比,模型被促使识别出与下游任务相关的细微差异。

表 5:消融实验结果。在 PTB-XL 数据集上对心律失常诊断与识别两项任务的评估性能。实验在编码器冻结的线性探测设置下开展,所使用的评估指标为 AUC(受试者工作特征曲线下面积)分数。在以下表格中,贡献度最高的组件所对应的性能结果以粗体突出显示。
5.2 消融实验:仅使用 MIMIC-IV-ECG 数据集预训练的影响
在用于 ESI 模型预训练的所有数据集中,MIMIC-IV-ECG 数据集是单个包含心电图样本数量最多的数据集。为探究仅使用 MIMIC-IV-ECG 数据集进行预训练所产生的影响,我们开展了一项实验:让模型仅在 MIMIC-IV-ECG 数据集上进行预训练。随后,我们在 PTB-XL 和 ICBEB 两个数据集上评估该模型的性能,重点关注三项任务:心律失常检测(含线性探测和零样本两种设置)与受试者身份识别(线性探测设置)。
表 6 展示了这些任务的性能结果。结果表明,与仅在 MIMIC-IV-ECG 数据集上进行预训练相比,在完整数据集上预训练的模型,在所有任务和所有数据集上均表现出更优的性能。具体而言,当预训练过程中纳入额外数据集时,心律失常检测和受试者身份识别两项任务的性能均有显著提升。

表 6:仅在 MIMIC-IV-ECG 数据上对 ESI-Tiny 模型进行预训练的消融实验结果。该表对比了仅在 MIMIC-IV-ECG 数据集上预训练的模型,与在完整数据集上预训练的模型,在不同任务和数据集上的性能表现。
在心律失常检测任务中,零样本设置下的性能差异更为明显:在所有数据集上预训练的模型,在 PTB-XL 数据集上的性能提升了 0.015,在 ICBEB 数据集上提升了 0.014。而在身份识别任务中,在所有数据集上预训练的模型仅表现出轻微提升。
这些结果表明,尽管 MIMIC-IV-ECG 为预训练提供了坚实基础,但纳入额外数据集仍能进一步增强模型在不同任务和数据集间的泛化能力。此外,对于零样本学习任务而言,预训练阶段从同一数据集(例如 PTB-XL)的样本中学习并获取标注信息,可能会对相应的下游任务产生帮助。
5.3 消融实验:信号编码器骨干网络的选择
我们探究了信号编码器采用不同骨干网络架构对模型性能的影响。此前有关视觉 - 文本预训练的研究为我们选择候选骨干网络提供了参考,这些候选架构包括视觉 Transformer(ViT,Dosovitskiy 等,2020)和 ConvNeXt(Woo 等,2023)。此外,正如表 2 所示,XResNet1D101 在有监督心律失常诊断任务中表现出优异性能(Strodthoff 等,2020),因此我们也探究了其在多模态预训练后作为基础编码器的潜力。
表 5 (b) 总结了相关结果。基于 ConvNeXt 的模型(ConvNeXt-tiny 和 ConvNeXt-base)在心律失常诊断和心电图(ECG)身份识别两项任务上均取得了最高的曲线下面积(AUC)分数。值得注意的是,ConvNeXt-base 作为参数数量最多(8556 万)的大型模型,整体性能最佳(心律失常诊断任务 AUC 为 0.932,心电图身份识别任务 AUC 为 0.926)。ConvNeXt-tiny 是一种参数效率更高的选择(参数数量 2681 万),其性能虽略低于基础版(ConvNeXt-base),但仍实现了具有竞争力的 AUC 分数,且参数规模显著更小。在两项任务中,与 ConvNeXt 系列模型规模相当的视觉 Transformer(ViT)模型,性能却明显更低,这可能表明卷积核更适合处理心电图信号。此外,XResNet1D101 骨干网络的 AUC 分数低于 ConvNeXt 系列架构,这可能是由于 XResNet 模型的参数规模显著更小所致。
5.4 消融实验:预训练数据规模与分布偏移的影响
在本消融实验中,我们还探究了预训练数据集规模对 ESI-tiny 模型在两个心律失常分类数据集(PTB-XL 和 ICBEB)上性能的影响。我们通过从所有预训练样本中随机采样选取的方式,将无标签预训练数据集的规模人为地从 0 调整至全部可用样本。在训练完 ESI-tiny 编码器后,我们采用编码器权重冻结的线性探测方法,在上述两个数据集上对模型进行评估,并以曲线下面积(AUC)分数作为性能指标。
图 5 所示结果表明,随着预训练数据集规模的增大,模型在 PTB-XL 和 ICBEB 两个数据集上的性能均呈现出稳定提升的趋势。在预训练数据集规模增大的初期阶段,模型性能的提升最为显著。这表明,适量的预训练数据即可帮助模型学习到具有信息价值的表征,从而实现性能的大幅提升。
此外,为探究预训练对分布偏移的影响,我们还测量了随着预训练数据集规模增大,预训练数据集与各测试集(PTB-XL 和 ICBEB)之间的最大均值差异(Maximum Mean Discrepancy, MMD)。如图 6 所示,随着预训练数据集规模的增大,预训练数据集与测试集之间的分布偏移逐渐减小。这表明,更大规模的预训练数据集有助于模型学习到对目标数据集更具泛化性的表征。MMD 的减小与图 5 中观察到的 AUC 分数提升呈现出相关性,这可能表明:通过扩大预训练数据集规模来减小分布偏移,有助于提升模型在下游任务中的性能。
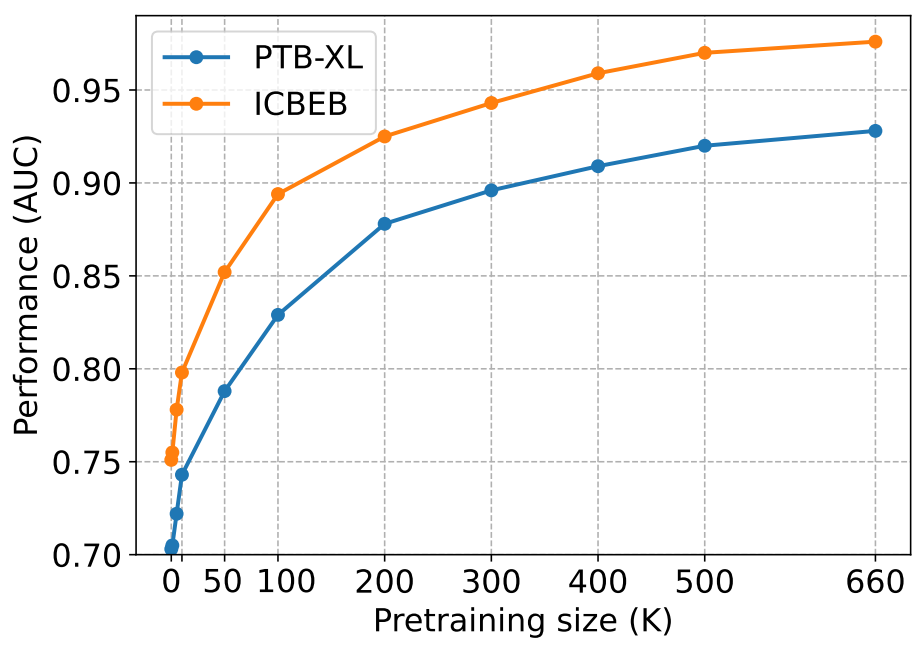
图 5:使用训练样本数量不同的预训练编码器,在 PTB-XL 和 ICBEB 数据集上进行心律失常诊断(评估指标为 AUC,即受试者工作特征曲线下面积)任务时的线性探测推理性能。
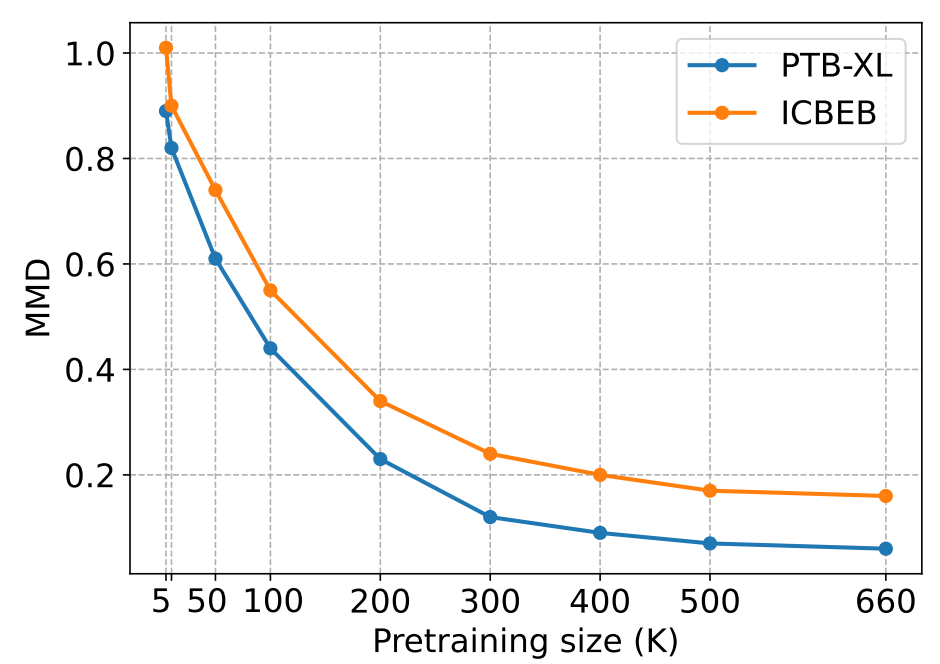
图 6:使用训练样本数量不同的编码器,测量预训练集与测试集之间通过最大均值差异(maximum mean discrepancy, MMD)计算的分布差异。
5.5 消融实验:心电图 - 文本错位的影响
为探究心电图(ECG)信号与其对应文本描述之间可能存在的错位,对所提 ESI 方法产生的影响,我们基于包含 10 万组心电图 - 文本对的子训练集,在 ESI-tiny 模型上开展了一项实验。通过随机打乱预训练数据集中一定比例的心电图 - 文本对,我们引入了不同程度的错位。随后,采用编码器权重冻结的线性探测方法,在两个心律失常分类数据集上对该模型进行了性能评估。
图 7 展示了该实验的结果。随着错位样本对比例的增加,ESI-tiny 模型在两个数据集上的性能均显著下降。这表明,预训练样本对之间的对齐,对于模型学习鲁棒的表征起着至关重要的作用。值得注意的是,错位程度的增加可能导致模型性能劣于采用随机初始化的未预训练模型,这一结果也凸显了在预训练过程中实现心电图 - 文本精准配对的关键重要性。
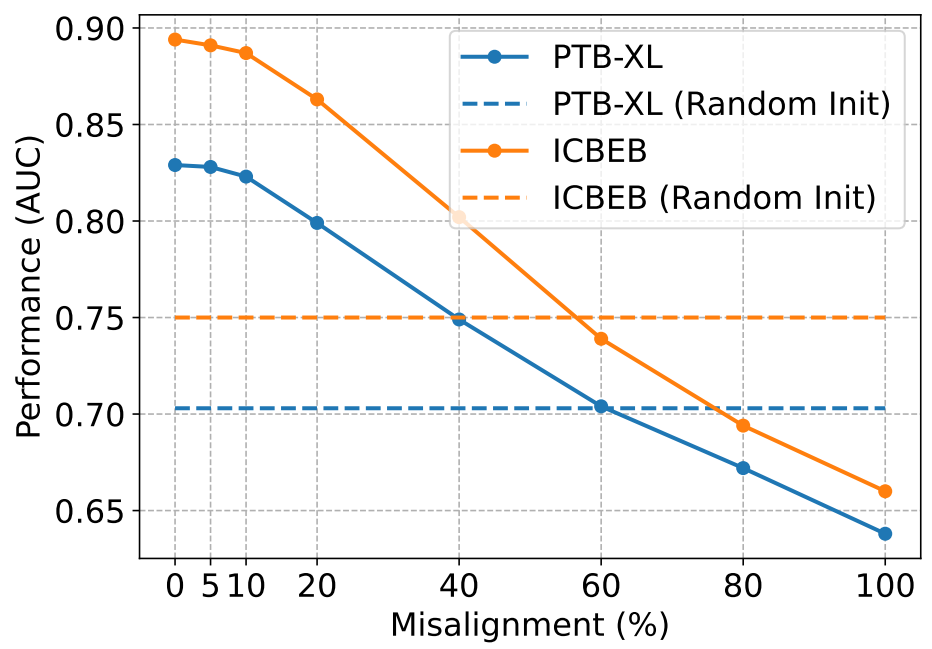
图 7:使用心电图 - 文本错位比例不同的预训练编码器,在 PTB-XL 和 ICBEB 数据集上进行心律失常诊断(评估指标为 AUC,即受试者工作特征曲线下面积)任务时的线性探测推理性能。以随机初始化权重训练的模型作为基准。
6 结论
本研究提出了一种新颖的多模态对比预训练框架,旨在提升从心电图(ECG)信号中学习到的表征的质量与鲁棒性。为解决心电图缺乏相关描述性文本的问题,我们设计了一个基于检索增强生成(RAG)的流程,称为心脏查询助手(Cardio Query Assistant, CQA)。该流程能为心电图数据生成包含人口统计学信息、潜在病症及波形模式的详细文本描述。受视觉 - 语言任务中多模态预训练策略成功案例的启发,我们开发了心电图语义整合器(ECG Semantic Integrator, ESI)。该框架融合了对比学习与描述生成功能,以促进对心电图信号更深入的语义理解。我们通过评估验证了所提方法在多个下游任务中的有效性:在心律失常诊断和基于心电图的用户身份识别任务中,ESI 方法的性能优于涵盖有监督学习和自监督学习(SSL)方法的强劲基准模型,展现出显著优势。这些结果与消融实验共同表明,多模态学习对心电图分析具有显著益处,且将描述生成损失与对比预训练相结合具有重要价值。除心电图领域外,我们认为所提出的 CQA 和 ESI 框架还具有应用于其他类型生物医学时间序列数据的潜力 —— 在这些领域中,上下文信息可被用于增强表征学习效果与下游分析性能。
另一方面,本研究存在一定局限性:预训练过程仅使用了 10 秒时长的心电图信号。尽管我们的方法在这类数据上展现出有效性,但现实世界中的心电图记录在时长上差异显著,且可能包含更多样化的特征。在未来的研究中,我们计划探究使用更多样化的心电图信号对所提框架性能产生的影响。
致谢
本研究工作得到了美国国家科学基金会(项目编号:2047296)和美国国立卫生研究院(项目编号:R01DA059925)的资助。
附录
A CQA的消融实验
本研究在CQA(心脏查询助手)中引入检索增强生成(Retrieval-Augmented Generation, RAG)技术,通过生成详细的心电图(ECG)波形描述来丰富预训练数据集,这一过程发挥了关键作用。在本消融实验中,我们探究了不同RAG设置对模型性能的影响。
为评估RAG生成描述的质量,我们采用(Wen & Kang, 2022)中人工标注的心电图波形描述作为参考标准。该数据集包含28种心律失常类型的标注信息。我们利用RAG方法生成对应的心电图描述,并采用BERTScore(Zhang等,2020)结合RoBERTa-large模型(Liu等,2019),将生成描述与参考描述进行对比评估。BERTScore是一种文本相似度评估指标,其核心原理是利用Transformer模型的预训练上下文嵌入(contextual embeddings),计算生成文本与参考文本之间的相似度。该指标通过嵌入向量的相似度计算,实现对文本语义对齐程度的精细化评估,主要包含以下三个核心子指标:
- 精确率(Precision):衡量生成文本中的词元(token)与参考文本中词元的匹配程度,反映生成内容对参考内容的准确还原程度。
- 召回率(Recall):衡量参考文本中的词元被生成文本捕捉的程度,反映生成内容的完整覆盖程度。
- F1 分数(F1 Score):是精确率与召回率的调和平均数,为生成文本与参考文本在语义对齐上的准确性和完整性提供均衡的衡量指标。
A.1 向量搜索中 Top-k 参数的影响
在本节中,我们探究向量搜索接口中 Top-k 参数的取值变化对模型性能的影响。Top-k 参数用于控制生成过程中会考虑的排名前 k 个候选样本的数量。我们通过 BERTScore 计算不同 Top-k 取值下的精确率(Precision)、召回率(Recall)和 F1 分数,以此评估模型性能。多次实验运行后,这些指标的均值与标准差汇总于表 7 中。
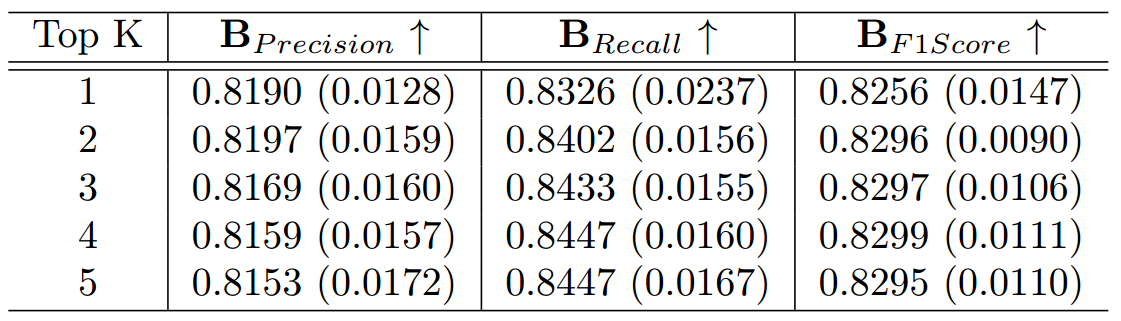
表 7:不同 Top-k 值下的 BERT 分数
结果表明,随着 top-k 值的增大,召回率(Recall)总体略有提升,这意味着考虑更多候选样本有助于检索到更多相关信息。然而,平均精确率(Precision)则往往小幅下降,这体现出一种权衡关系 —— 纳入更多候选样本可能会引入相关性较低的信息。而作为平衡精确率与召回率的指标,F1 分数在不同 top-k 值下保持相对稳定,这表明模型整体性能具有一致性。
我们的研究结果显示,调整 top-k 参数对检索增强生成(RAG)性能的影响有限但具有规律性。top-k 的取值可根据任务的具体需求进行调整:较大的取值更有利于提升召回率,但会以精确率略有下降为代价;而较小的取值则能得到更精准的结果,但输出的完整性会略有降低。本研究中,我们将 top-k 值设定为 2。
A.2教科书数量对RAG的影响
我们探究了 CQA 流程中用作知识库的教材数量所产生的影响。本消融实验的目的是评估纳入教材数量的多少是否会影响生成的心电图(ECG)波形描述质量。本研究中使用的教材包括 Huff(2006)所著的《ECG 实践:心律失常判读训练》(ECG Workout: Exercises In Arrhythmia Interpretation)和 Garcia(2015)所著的《12 导联心电图:判读技巧》(12-Lead ECG: The Art of Interpretation)。我们采用三种不同配置开展实验:不使用任何教材、单独使用每一本教材、将两本教材组合使用。实验结果汇总于表 8 中。
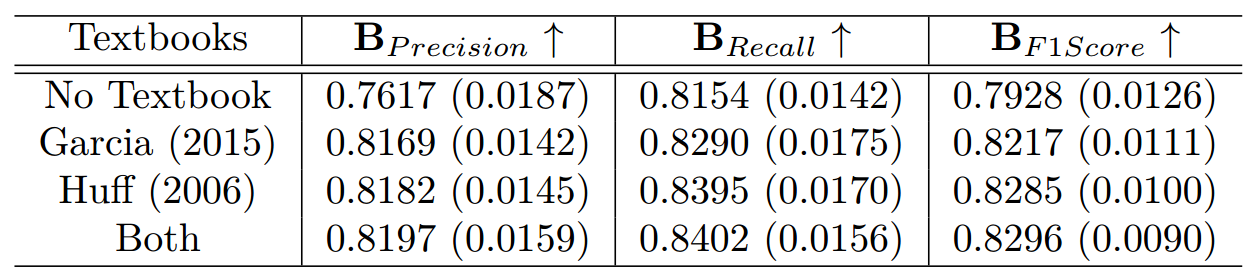
表 8:检索增强生成(RAG)中使用不同数量教科书时的 BERT 分数
结果显示出明确趋势:在检索增强生成(RAG)流程中纳入教材后,所有 BERTScore 指标(精确率、召回率、F1 分数)的性能均有所提升。具体而言,将两本教材组合使用时得分最高,精确率为 0.8197、召回率为 0.8402、F1 分数为 0.8296。这表明纳入多源知识能丰富生成的描述内容。当仅使用单本教材时,在所有三项指标上,Huff(2006)的教材表现均略优于 Garcia(2015)的教材,尽管两者差异较小。这说明虽然每本教材都能独立对生成质量产生积极作用,但将它们组合使用可为 RAG 流程提供更稳健的知识库。相比之下,不使用任何教材会导致性能显著下降,所有指标均取得最低分。这凸显了纳入领域特定知识对提升大型语言模型(LLMs)生成内容的相关性与准确性的重要性。因此,在本研究中,在 RAG 流程中使用多本教材不仅提高了生成的心电图描述质量,还确保了输出内容的一致性。
A.3 不同大型语言模型(LLM)提示策略的影响
在本小节中,我们探究了 RAG(检索增强生成)流程内大型语言模型(LLM)所使用的提示结构变化,对生成的心电图(ECG)波形描述质量产生的影响。为评估不同提示下生成结果的一致性,我们开展了消融实验:将标准提示 “{心电图病症} 在 12 导联心电图中如何体现?”(How is {ECG condition} reflected in 12-lead ECG?)改写为五种不同变体,例如 “描述 {心电图病症} 在 12 导联心电图中的表现”(Describe how {ECG condition} appears in a 12-lead ECG.)以及 “在 12 导联设置下,与 {心电图病症} 相关的心电图表现有哪些?”(What are the ECG findings associated with {ECG condition} in a 12-lead setup?)。设计这些替代提示的目的,是验证措辞上的细微变化是否会影响 RAG 流程的性能。尽管提示形式不同,但其核心查询目标始终聚焦于生成 “特定心电图病症在 12 导联心电图中的表现” 相关描述。
实验结果显示,所有改写后的提示策略均呈现出显著的一致性:不同提示变体的平均 F1 分数为 0.8295,且标准差极低(仅为 0.0003)。这表明,CQA(心脏查询助手)生成相关描述的能力对提示措辞的变化具有稳健性。这种稳健性使得提示的构建具有一定灵活性,即使调整措辞也不会损害生成内容的质量。
B 心电图模型训练所用心电图数据集说明书
本节中,我们参照 Gebru 等人(2021)的方法,整理了训练过程中所用数据的数据集说明。
B.1 研究目的
用途:收集并处理这些数据集,旨在为自动化心电图处理算法的开发与评估提供支持,尤其用于训练能从心电图信号中提取通用嵌入特征的基础模型。这些数据集包含大量心电图记录,且每条记录均配有人工或机器标注信息及元数据,可为医疗领域机器学习模型的稳健训练提供数据支撑。
创建机构:这些数据集由多个机构联合创建,包括 PhysioNet(生理网络)、查普曼大学(Chapman University)、绍兴市人民医院(Shaoxing People’s Hospital)以及德国联邦物理技术研究院(Physikalisch-Technische Bundesanstalt,简称 PTB)。
资助信息:这些数据集的开发与发布得到了多项资助支持,资助方包括美国国立卫生研究院(NIH)、凯家族基金会(Kay Family Foundation)以及柏林大数据中心(Berlin Big Data Center)。
B.2 数据集构成
数据实例:
- MIMIC-IV-ECG 数据集:包含诊断性 12 导联心电图记录,每个数据实例均为一组心电图信号,且配有机器生成的标注信息及元数据。
- PTB-XL 数据集:包含 17415 条临床 12 导联心电图记录,所有记录均由心脏病专家完成标注,覆盖多种诊断类别。
- Chapman-Shaoxing 数据集:包含 45152 条来自患者的 12 导联心电图记录,由专业人员标注,涉及的病症包括心房颤动、心肌梗死及其他心律失常。
数据量:
- MIMIC-IV-ECG 数据集:包含数千条心电图记录。
- PTB-XL 数据集:包含 17415 条心电图记录。
- Chapman-Shaoxing 数据集:包含 45152 条心电图记录。
数据特征:每个数据集均包含心电图波形数据、人口统计学信息(如年龄、性别等)以及与心脏病症相关的临床标注。其中,PTB-XL 数据集和 Chapman-Shaoxing 数据集还包含诊断流程相关的元数据,例如 SCP-ECG(标准化临床心电图)表述。
B.3 数据收集流程
数据获取方式:
- MIMIC-IV-ECG 数据集:数据源于常规临床诊疗过程,并存储于 MIMIC-IV 数据库中。
- PTB-XL 数据集:心电图信号采用席勒股份公司(Schiller AG)的设备采集,采集周期长达 7 年,标注信息由心脏病专家提供。
- Chapman-Shaoxing 数据集:数据从多家医院收集而来,心电图信号的记录与标注工作均由持证医师完成。
伦理考量:所有数据集均为公开可用数据,且已进行去标识化处理,以保护患者隐私。原始数据的收集均获得了相关机构伦理委员会的批准。本研究未开展新的数据收集工作。
B.4 数据预处理 / 清洗 / 标注
MIMIC-IV-ECG 数据集:采用机器生成的标注信息进行数据标注。对数据进行清洗,以去除噪声和伪影。
PTB-XL 数据集:对心电图数据进行预处理,确保波形格式的一致性,并采用 SCP-ECG(标准化临床心电图)编码进行标准化标注。
Chapman-Shaoxing 数据集:对心电图数据进行去噪处理;诊断信息经多名医师核实后,以结构化格式存储。
B.5 数据用途
当前用途
这些数据集已用于开发和评估心电图分析相关的机器学习模型,尤其在心电图模型预训练及心律失常检测领域。
潜在用途
该数据集可用于更广泛的心脏健康研究,包括开发诊断工具以及研究心脏疾病的流行病学特征。
使用限制
尽管数据集已进行去标识化处理,但使用者在将其用于研究时仍需遵守伦理准则。
B.6 数据分发
获取方式
这些数据集可通过 PhysioNet 平台公开获取,遵循知识共享署名 4.0 国际许可协议(Creative Commons Attribution 4.0 International License)。
监管问题
目前无特定监管限制,但使用者必须遵守相关许可条款。
B.7 数据维护
支持服务
使用者若有疑问或需要支持,可通过 PhysioNet 平台联系数据集维护人员。
更新机制
数据集的任何更新或新版本发布,都将在 PhysioNet 平台上公告。
社区贡献
鼓励研究人员通过发表论文,或直接向数据集仓库提交成果与改进内容,为社区贡献力量

















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









