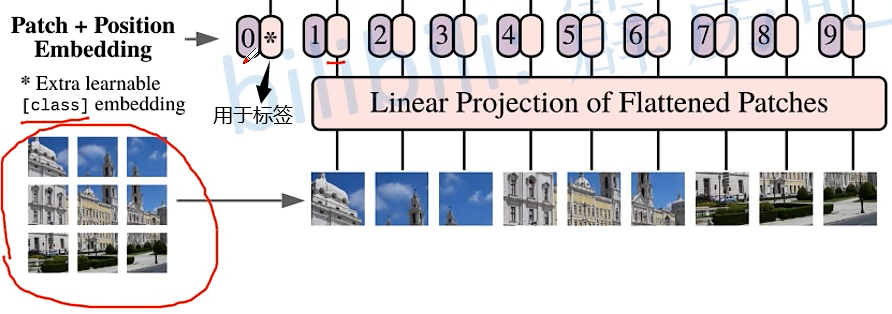
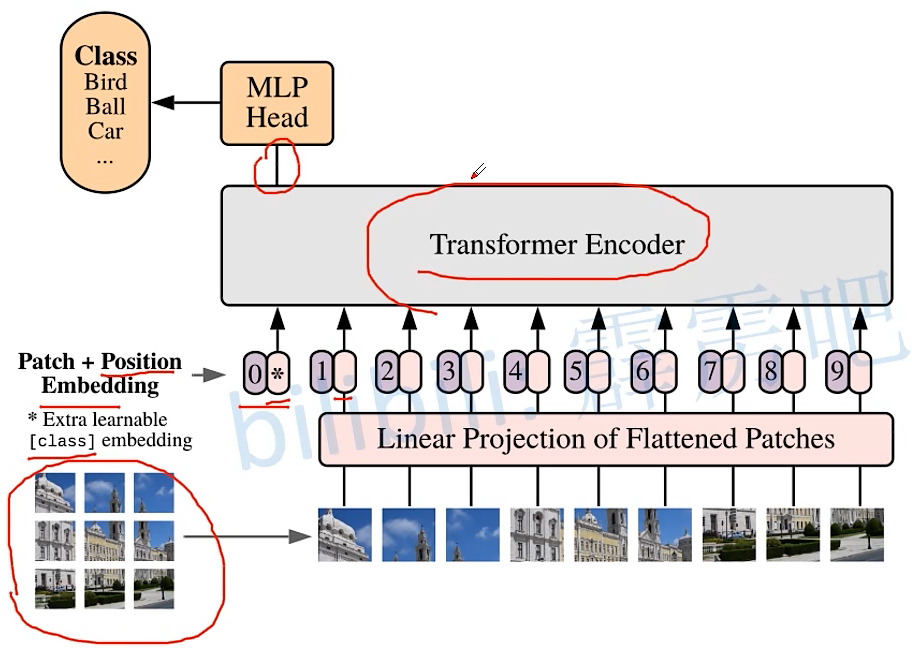
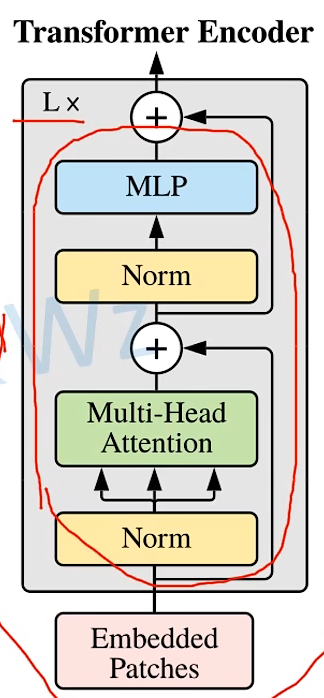
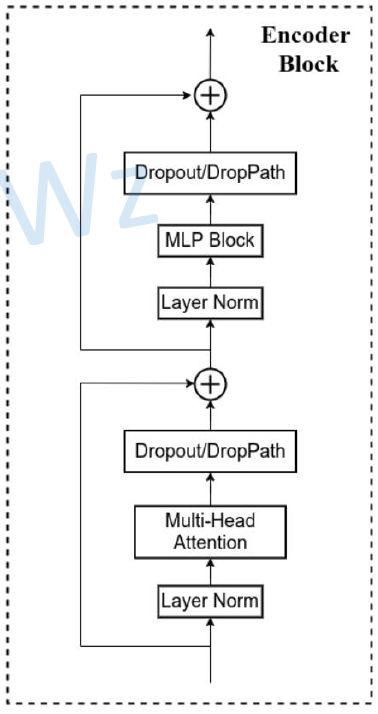
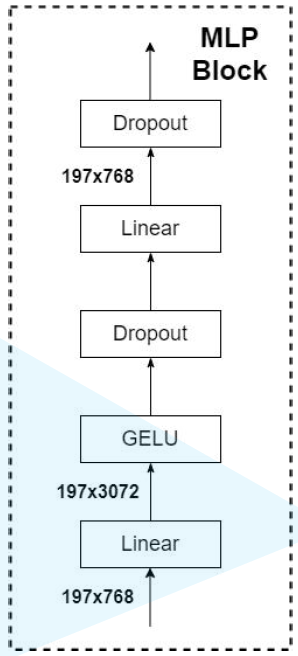
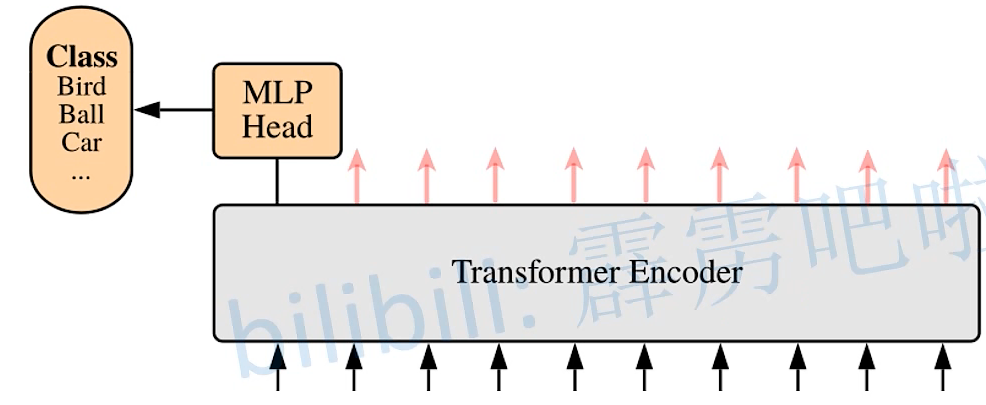
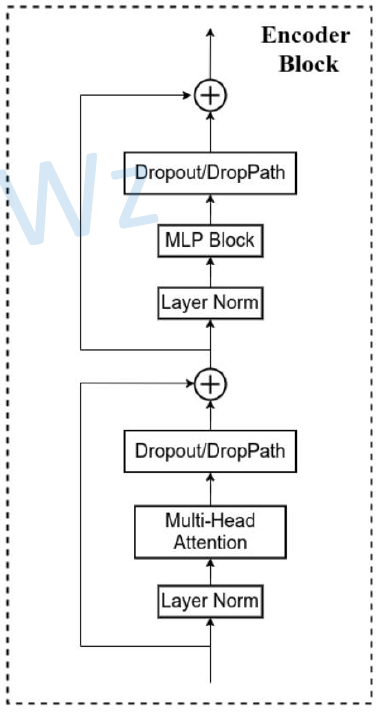
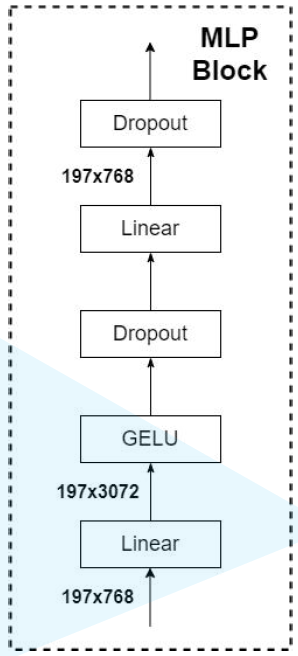
1. 原理图 将一张图片拆分开来如下图所示,下图的 0,1,2,…,8,9 是用于记录图片的位置信息 2.Transformer Encoder结构图 (L× 指重复堆叠L次) 3.实现过程: 更为详细的Encoder Block图 上图中的 MLP Block 图解为 4.MLP Head层 注意:在Transformer Encoder 前有一个Dropout层,后有一个Layer Norm层 训练自己的网络时,可简单将MLP Head层看作一个全连接层 5. 总结ViT-B/16 网络结构 其中:Encoder Block 其中:MLP Block


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























 4058
4058





