







1.非平行运算 non parallel computation
2.大量串列计算 lots of sequential computation
x=f1(x) x=f2(x)...x=fn(x) 层数多才明显
cuda可以把函数融合为一个函数 只需要一次运算
pytorch-->C++(桥梁)-->cuda平行运算后回传
trilinear interpolation 三线性插值
创建interpolation.cpp,声明引入tensor的#include <torch/extension.h> 报错
vscode 中Ctrl+Shift+P打开命令面板,找到Edit configuration(json)
在includepath中输入:
"includePath": [
"${workspaceFolder}/**",
"/home/lys/miniconda3/envs/mmrotate/include/python3.8",
"/home/lys/miniconda3/envs/mmrotate/lib/python3.8/site-packages/torch/include",
"/home/lys/miniconda3/envs/mmrotate/lib/python3.8/site-packages/torch/include/torch/csrc/api/include"vscode 中Ctrl+Shift+P打开命令面板,输入Python: Select Interpreter配置环境
interpolation.cpp:
#include <torch/extension.h>//tensor进入,需要让c+=知道
//定义一个调cuda的函数
torch::Tensor trilinear_interpolation(
torch::Tensor feats,//八个点的特征
torch::Tensor point
) {
return feats;
}
//提供一个python调c++的桥梁
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
//""python名称,c++函数
m.def("trilinear_interpolation", &trilinear_interpolation);
}为了build C++文件,创建setup.py
from setuptools import setup
from torch.utils.cpp_extension import CppExtension, BuildExtension
setup(
name = 'cppcuda_tutorial',
version = '1.0',
author = 'lys',
author_email = '2322349003@qq.com',
description = 'cppcuda example',
ext_modules = [#需要build的代码在哪里
CppExtension (
name = 'cppcuda_tutorial',
sources = ['interpolation.cpp'])#代码指定
],
cmdclass = {
'build_ext' : BuildExtension#需要build
}
)查看pip --version
pip install .#安装当前目录下的c++代码创建test.py,测试build和代码是否正常运行
import torch #必须先引入torch才可以引入自建c++文件
import cppcuda_tutorial
feats = torch.ones(2)
point = torch.zeros(2)
out = cppcuda_tutorial.trilinear_interpolation(feats, point)
print(out)输出
(mmrotate) (base) lys@lys:~/pytorchcppcuda$ python test.py
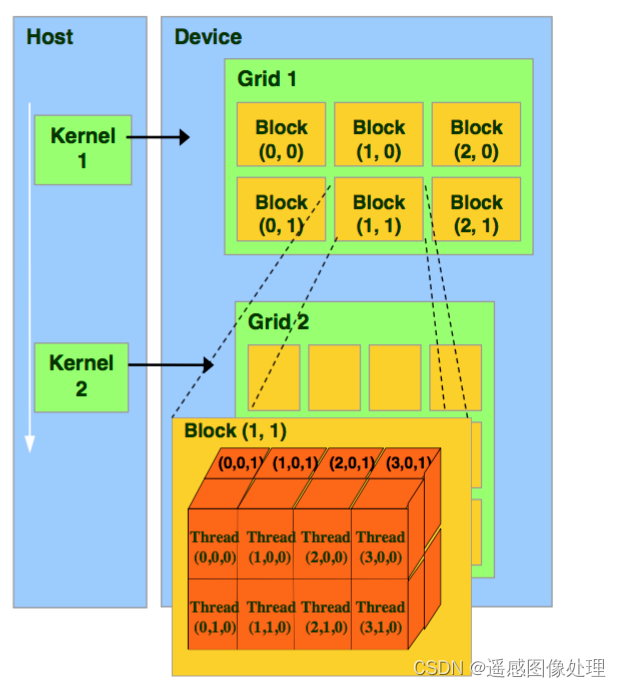
tensor([1., 1.])cuda平行计算原理,通过block让整体运算资源达到更多
CPU中呼叫Kernel-->GPU中的Grid-->n*Block(上限2^31 * 2^8)-->细分为n*nThread(上限1024)
trilinear 运算公式
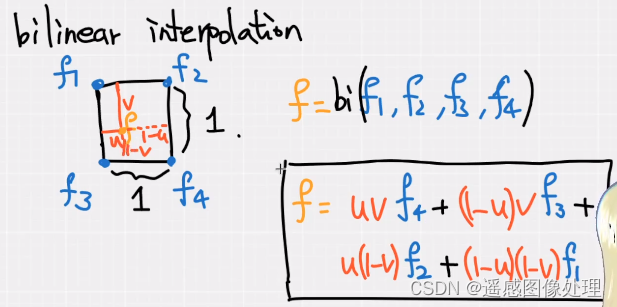
bilinear 双线性插值
f = uvf4+(1-u)vf3+u(1-v)f2+(1-u)(1-v)f1
三线性插值 uvw
feats:(N,8,F) N个正方体,8个顶点,每个顶点对应的特征
points:(N,3) N个点,3D
如何平行运算:
1.N平行
2.F平行
创建 interpolation_kernel.cu,要在C++中呼叫cuda
//平行运算
#include <torch/extension.h>
torch::Tensor trilinear_fw_cu(//forward计算的cu函数
torch::Tensor feats,//八个点的特征
torch::Tensor points
) {
return feats;
}创建include文件夹,创建utils.h保存头文件, 引入声明,函数头和magicline CHECK INPUT是不是可用的tensor
#include <torch/extension.h>
//检查是否是cuda tensor
#define CHECK_CUDA(x) TORCH_CHECK( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









