









目录
2.KNOWLEDGE GRAPHS AND SUMMARIES
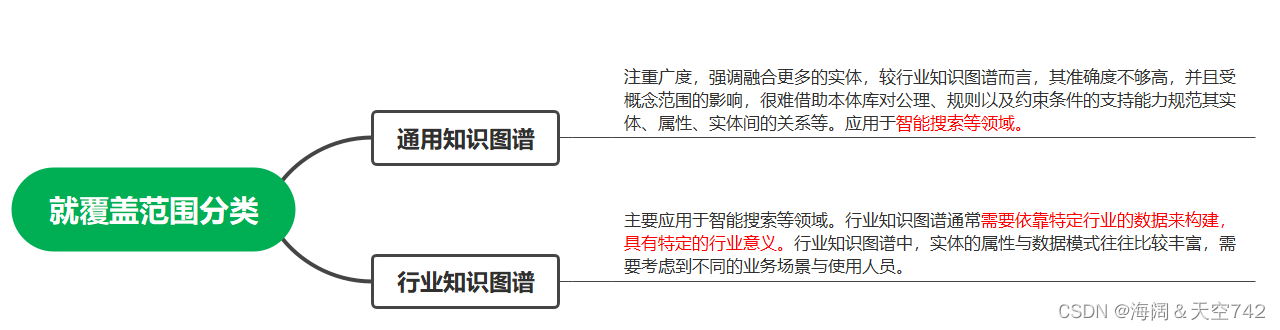
A. Knowledge Graphs and summaries
C. Diversified Knowledge Graph Summarization
4.KNOWLEDGE GRAPH SEARCH WITH SUMMARIES
写在前面(KG知识补充):
知识图谱是Google用于增强其搜索引擎功能的知识库。本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。现在的知识图谱已被用来泛指各种大规模的知识库。
三元组是知识图谱的一种通用表示方式,即,其中
是知识库中的 实体集合,共包含|E|种不同实体;
是知识库中的关系集合,共包含|R|种不同关系;
代表知识库中的三元组集合。三元组的基本形式主要包括实体1、关系、实体2和概念、 属性、属性值等,实体是知识图谱中的最基本元素, 不同的实体间存在不同的关系。概念主要指集合、 类别、对象类型、事物的种类,例如人物、地理等; 属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988-09-08等。每个实体(概念的外延)可用一个全局唯一确定的ID来标 识,每个属性-属性值对(attribute-value pair,AVP)可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
知识图谱主要有自顶向下(top-down)与自底向 上(bottom-up)两种构建方式。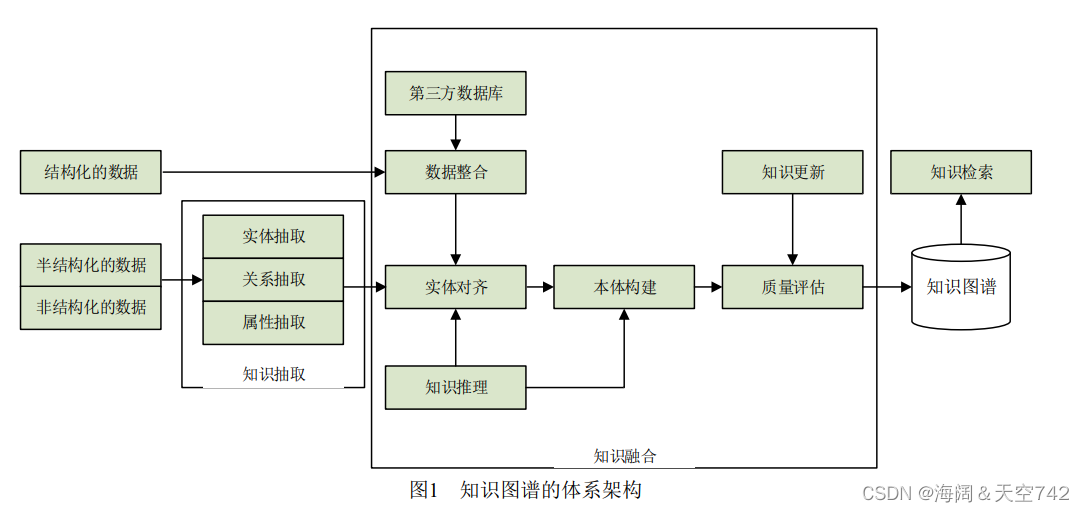
关键技术:
1.知识抽取
(1)实体抽取
从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步。
1) 基于规则与词典的实体抽取方法
主要采用的是基于规则 与词典的方法,例如使用已定义的规则,抽取出文 本中的人名、地名、组织机构名、特定时间等实体。然而,基于规则模板的方法不仅需要依靠大量的专家来编写规则或模板,覆盖的领域范围有限,而且很难适应数据变化的新需求。
2) 基于统计机器学习的实体抽取方法
将机器学习中的监督学习算 法用于命名实体的抽取问题上。例如文献利用KNN算法与条件随机场模型,实现了对Twitter文本 数据中实体的识别。单纯的监督学习算法在性能上 不仅受到训练集合的限制,并且算法的准确率与召 回率都不够理想。相关研究者认识到监督学习算法 的制约性后,尝试将监督学习算法与规则相互结合, 取得了一定的成果。例如文献基于字典,使用最大熵算法在Medline论文摘要的GENIA数据集上进 行了实体抽取实验,实验的准确率与召回率都在70%以上。
3) 面向开放域的实体抽取方法
一种方法是通过少量的实体实例建立特征模型,再通过该模型应用于新的 数据集得到新的命名实体。另一种方法是基于已知实体的语义特征去搜索日志中识别出命名的实体,然后进行聚类。
(2)关系抽取
关系抽取的目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则 以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。
1) 开放式实体关系抽取
开放式实体关系抽取可分为二元开放式关系抽取和n元开放式关系抽取。
基于语义角色标注的OIE分析显示:英文语句中40%的实体关系是n元的,如处理不当,可能会影响整体抽取的完整性提出了一种可抽取任意英文语句中n元实体关系的方法KPAKEN, 弥补了ReVerb的不足。
但是由于算法对语句深层语法特征的提取导致其效率显著下降,并不适用于大规模开放域语料的情况。
2) 基于联合推理的实体关系抽取
联合推理的关系抽取中的典型方法是马尔可夫逻辑网MLN(Markov logic network),它是一种将马尔可夫网络与一阶逻辑相结合的统计关系学习框架,同时也是在OIE中融入推理的一种重要实体关系 抽取模型。基于该模型,提出了一种无监督学习模型StatSnowball,不同于传统的OIE,该方法可自动产生或选择模板生成抽取器。在StatSnowball的基础上,提出了一种实体识别与关系 抽取相结合的模型EntSum,主要由扩展的CRF命名 实体识别模块与基于StatSnowball的关系抽取模块 组成,在保证准确率的同时也提高了召回率。文献[37,47]提出了一种简易的Markov逻辑TML(tractable Markov logic),TML将领域知识分解为若干部分, 各部分主要来源于事物类的层次化结构,并依据此结构,将各大部分进一步分解为若干个子部分,以此类推。TML具有较强的表示能力,能够较为简洁地表示概念以及关系的本体结构。
(3) 属性抽取
属性抽取主要是针对实体而言的,通过属性可 形成对实体的完整勾画。由于实体的属性可以看成 是实体与属性值之间的一种名称性关系,因此可以 将实体属性的抽取问题转换为关系抽取问题。
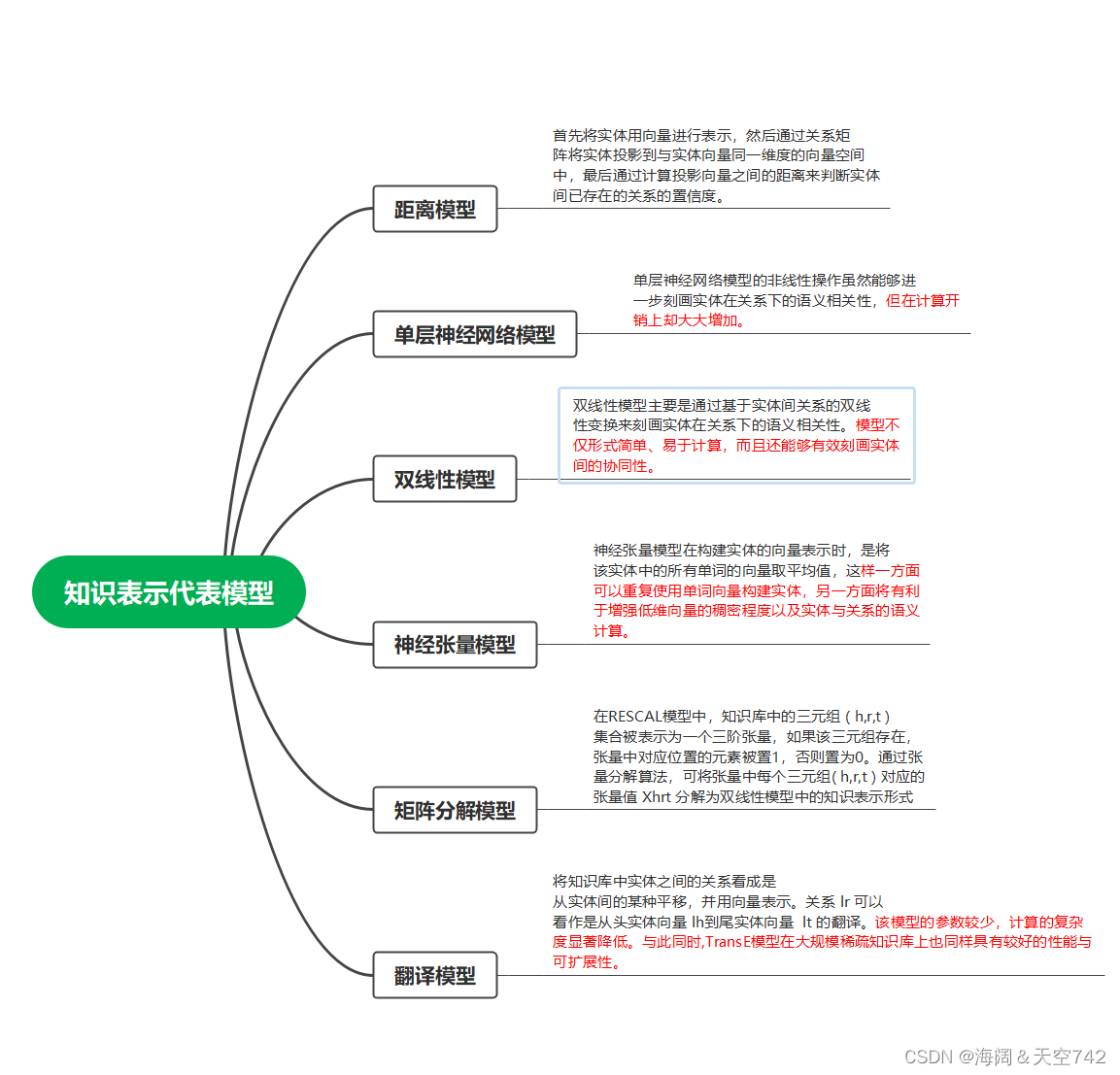
2.知识表示
虽然,基于三元组的知识表示形式受到了人们 广泛的认可,但是其在计算效率、数据稀疏性等方 面却面临着诸多问题。近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联, 对知识库的构建、推理、融合以及应用均具有重要的意义。
通过知识表示而得到的分布式表示形式在知识图谱的计算、补全、推理等方面将起到重要的作用。
3. 知识融合
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间 的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到 数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
4.知识推理
知识推理则是在已有的知识库基础上进一步挖 掘隐含的知识,从而丰富、扩展知识库。 知识推理方法主要可分为基于逻辑的推理与基于图的推理两种类别。
知识图谱的应用
智能搜索( 1) 集 成的语义数据。例如当用户搜索梵高,搜索引擎将 以知识卡片的形式给出梵高的详细生平,并配合以 图片等信息;2) 直接给出用户查询问题的答案。例如当用户搜索“姚明的身高是多少?”,搜索引擎的 结果是“226 cm”;3) 根据用户的查询给出推荐列表等。)
深度问答 (多数问答系统更倾向于将给定的问 题分解为多个小的问题,然后逐一去知识库中抽取 匹配的答案,并自动检测其在时间与空间上的吻合 度等,最后将答案进行合并,以直观的方式展现给 用户。目前,很多问答平台都引入了知识图谱,例如华盛顿大学的Paralex系统和苹果的智能语音助 手Siri,都能够为用户提供回答、介绍等服务; 亚马逊收购的自然语言助手Evi,它授权了Nuance的语音识别技术,采用True Knowledge引擎 进行开发,也可提供类似Siri的服务。)
社交网络 (通过知识图谱将人、 地点、事情等联系在一起,并以直观的方式支持精 确的自然语言查询,例如输入查询式:“我朋友喜欢 的餐厅”“住在纽约并且喜欢篮球和中国电影的朋友”等,知识图谱会帮助用户在庞大的社交网络中找到与自己最具相关性的人、照片、地点和兴趣等。Graph Search提供的上述服务贴近个人的生活,满足了用户发现知识以及寻找最具相关性的人的需求。)
垂直行业应用 (金融、医疗、电商行业)
0.Abstract
在响应时间等资源约束条件下,挖掘,搜索异构和大型知识图具有挑战性。 本文研究了一种基于发现的知识图搜索框架。 1)引入了一类以图模式为特征的摘要。 与传统的由频繁子图定义的摘要相比,该摘要能够自适应地对具有相似邻居的实体进行有界的总结。2)我们将图摘要的计算描述为一个双准则模式挖掘问题。 给定一个知识图G,问题是发现K个使信息量最大的多样化摘要。 虽然这个问题是NP难的,但我们证明了它是2-逼近的。 在给定资源约束条件下,我们还提出了一种在线挖掘算法,该算法在速度和准确性之间进行了权衡。 3)开发了以摘要为视图的查询评估算法。 这些算法高效地计算(近似)答案,精确度高,只引用少量摘要。 实验研究表明,在大型知识图上进行在线挖掘是可行的,并且可以在知识图上进行有界搜索。
1.Introduction
知识图通常被用来表示和管理知识库。 与熟悉的关系数据不同,现实世界的知识图缺乏定义良好的模式和类型系统的支持。 在没有任何基础图的先验知识的情况下,通常很难识别有意义答案的相关数据。 由于查询的模糊性和资源限制(例如,允许访问的数据、响应时间),知识搜索也具有挑战性。
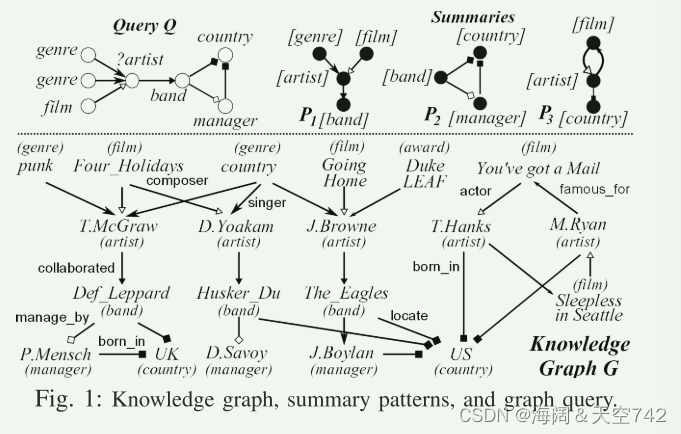
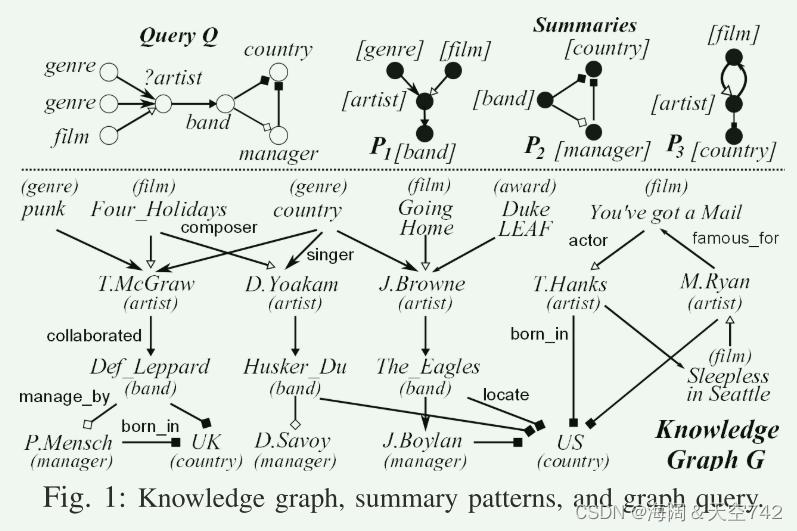
etc.1:图 1说明了艺术家和乐队的知识图样本G。 假设一个音乐出版商想要找到两个流派(流派)的专家(艺术家),在一部(电影)中表演,还与一个乐队合作,而这个乐队的经理与乐队位于同一个国家。 该搜索可以表示为图查询Q,如图1所示。 Q的答案是指在G的子图中用Artist键入的与Q同构的实体的集合。在这个例子中,T.McGraw是Q的正确答案。
在G上评价Q是昂贵的。 例如,模棱两可的标签“Artist”要求检查具有该类型的所有实体。 此外,在没有G先验知识的情况下,用户很难指定Q。
观察到图G可以用三个小的图模式来描述,即总结P1、P2和P3,如图所示 1. 每个模式通过将一组实体概括为单个节点,以及它们在G中的共同相邻实体来抽象G的一部分。例如,P1将G中的三个艺术家J.Browne,T.McGraw和D.Yoakam指定为单个节点艺术家,他们与他们的乐队相关联,题材和电影作为1跳邻居,表示“音乐人”; P3区分了只与电影和乡村(即“演员”)相关联的艺术家T.Hanks和M.Ryan。 这些摘要帮助用户理解G,而无需对低级实体进行令人生畏的检查。 更好的是,他们提出了一些小的“相关”数据来评估查询Q。实际上,通过只访问G2中P1和P2总结的实体,就可以正确地回答Q。
问题:为无模式的、有噪声的知识图计算摘要,但这并不是一件简单的事情。 传统的图摘要是由频繁子图模式定义的,它们在图中捕获它们的同构对应体。 对于具有类似的、相关的邻居直到某个跳点的实体来说,这通常是一种矫枉过正的做法。 例如,两个实体J.Browne和T.McGraw及其相关的1跳邻居应该用一个摘要P1来概括,尽管由这两个实体诱导的两个子图彼此不同构。 我们如何在无图式知识图中构造摘要? 此外,我们如何利用摘要来支持知识图搜索?
在这项工作中,我们利用知识图的摘要来促进高效的查询评估。 我们引入了一类图模式,根据相似实体的标签和邻域信息总结出一个有界跳的相似实体。 提出了一种流式挖掘算法来发现一组多样化的摘要,并引入了将摘要作为“视图”的查询评估算法。
Related work.
(1)Graph summarization 图摘要已经被研究用来描述具有少量信息量的数据图。这些方法可以分为图压缩、属性摘要、基于模拟关系的摘要和实体摘要。 与以前的工作不同,1)我们引入有损摘要来促进知识图查询的高效处理,而不是恢复精确的图。 2)我们通过信息量和多样性来度量摘要,这比基于MDL的方法更加复杂。 3)我们的摘要不需要调整参数来实现近似的摘要。 这些工作都没有把多样化的摘要作为图模式来处理。
(2)Answering queries using views 基于视图的查询评估已经证明对于SPARQL查询和一般的图模式查询是有效的。 基于视图的查询计算通常需要通过访问使用相同查询语言定义的视图来进行等效的查询重写。 我们的工作在以下方面有所不同:1)我们使用D-摘要作为视图来评估由子图同构定义的图查询,而不是要求视图和查询使用相同的语言; 2)开发可行的摘要算法作为视图发现过程。
2.KNOWLEDGE GRAPHS AND SUMMARIES
A. Knowledge Graphs and summaries
Knowledge Graphs我们将知识图G定义为有向标号图(V,E,L),其中V是一个节点集,EV×V是一个边集。 每个节点v∈V表示一个具有标号L(v)的实体,该实体可能携带V的内容,如类型、名称和属性值,如知识库和属性图所示; 并且每个边e∈E表示两个实体之间的关系L(e)。
Summaries给定一个知识图G,G的摘要P是一个有向连通图(,
,
),其中
(即
)是一组摘要节点(即边)。 每个节点u∈Vp(resp.edge e∈ep)都有一个标号Lp(u)(resp.lp(e))。 每一个节点u∈Vp(e∈Ve)表示来自G的一个非空节点集[u](又称边集[e])。
G中P的基图表示G的子图,该子图由节点集和边集
,对于每一个u∈Vp和e∈Ep导出。 请注意,对于已连接的摘要,可以断开基图的连接。 在实践中,可以使用附加的映射结构来跟踪摘要的基本图。
正如前面提到的,摘要应该自适应地描述在G中具有相似邻域直到某些跳数的实体。为了捕捉这一点,我们引入了d-similarity的概念。
直观地说,对于摘要P中具有有界长度d的摘要节点u的任何传入(或传出)路径ρ,必须存在[u]中总结的具有相同标签的每个实体的传入(或呼出)路径。即P 为 P中的每个摘要节点u保留上限长度为d的所有邻域信息。注意,对于直径为dm的给定摘要P,d ≤ dm。
给定一个知识图G和一个整数d,我们将G的摘要定义为一个d-summaries。
example2:图 1说明了包含三个2-摘要P1、P2和P3的知识图G的摘要。 P1的基本图由以下实体归纳而成:[流派]={乡村,朋克},[电影]={回家,四个假期},[艺术家]={J.Browne,D.Yoakam,T.McGraw}和[乐队]={The Eagles,Husker Du,Def Leppard}。 类似地,P2总结了乐队Def Leppard和老鹰,他们的联系国家和经理,P3总结了电影《你有一封邮件》和《西雅图不眠夜》,演员T.Hanks和M.Ryan和他们的国家。 P1不能概括T.Hanks,因为后者没有P1中建议的带的路径。
Verification of d-summaries.给定一个摘要P和一个知识图G,验证问题是确定P是否是G的D-摘要,如果是,则计算P在G中的最大基图。与由频繁子图定义的对应图(NP-hard)相比,d-摘要的验证是容易的,如下所示。
B. Interestingness measure
我们从信息量和多样性两个方面来描述摘要的趣味性。
Informativeness I(P)应该捕获(1)摘要大小,(2)它在知识图G中编码的信息总量(实体及其关系)。我们将信息量函数I(·)定义为:

其中,1)|P|指概要P的大小,即P中节点和边的总数,和(2)supp(P,G)定义为,其中GP(G)指GP(G)中的大小(即实体和关系的总数)。
Summary Diversification第二个挑战是避免摘要之间的冗余。 冗余可能是由于:1)常见的“子摘要”; 2)由两个摘要概括的共同实体。
Difference of Summaries 为了解决通常被总结的实体所造成的摘要冗余问题,我们将两个摘要P1和P2定义为距离函数diff
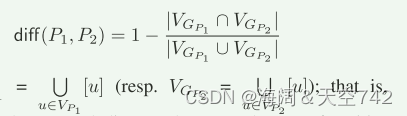
可以验证diff是一个度量,即对于任何三个d-摘要P1、P2和P3,diff(P1,P2)≤diff(P1,P3)+diff(P2,P3)。 我们将实体集差量化为比边集差更重要的汇总差的因素。 实体的标签/类型差异也可以用于量化diff中的加权。
C. Diversified Knowledge Graph Summarization
好的摘要应该是信息丰富和多样化的。 我们引入了一个综合信息量I(·)和距离diff(·)函数的双准则函数F。 给定知识图G的摘要,F定义为:

其中,1)CARD(SG)是指它所包含的摘要的数量; 2)α(∈[0,1])是一个可调谐的参数,可以在信息和多样化之间进行权衡。 注意,我们缩小了F(SG)中的第二个求和(多样化),它有CARD(SG)(CARD(SG)-1)/2 项,以平衡第一个求和(信息量)有CARD(SG)项的事实。
Diversified graph summarization在给定知识图G、整数k和d以及规模预算的情况下,多样性知识图摘要问题是将G的摘要
作为第k个摘要集计算,其中多样性图摘要中的每个摘要是一个最大d-摘要,其大小以
为界;使整体质量函数F(
)最大化。
3.DISCOVERING SUMMARIZATION
我们下一步研究可行的知识图摘要挖掘算法。
给定图G,它调用一个挖掘过程(表示为SUMGEN)来枚举和验证所有最大d-摘要。 然后,它贪婪地从向
添加一个总结对{P,P'},以最大限度地改进函数F(
)
该算法需要等到所有的摘要都经过验证,当G值较大时,可能不可行。我们可以做得更好。引理1表明验证开销不是主要的瓶颈。这意味着在(快速验证的)摘要流上进行“流式”挖掘过程。更好的是,(1)算法可以被中断以根据要求报告摘要;(2)它在“已见”摘要上近似于最佳答案。
该算法保持1)一个由SUMGEN验证的最大摘要集; 2)一个排序列表的集合L,每个最大汇总pi∈
有一个列表Li。
Stream-style Summarization.

该算法被称为StreamDIS,并在图进行了说明 2. 给定G、整数k和两个阈值bp和lp,它首先初始化sg、cp、l和终止条件的标志终止(设置为false)(第1行)。 然后,它迭代地执行以下步骤。 1)它调用sumGEN来获取新生成的摘要Pt(第3行)。 过程sumGEN被修改为一次返回一个经过验证的摘要,而不是等待并在批处理中返回一组摘要。 2)它根据新获取的摘要Pt更新和列表L(第4-6行)。 对于每个摘要pi∈
,它计算质量分数F(Pi,Pt),并在F(Pi,P')<F(Pi,Pt)时,通过将最低得分对(Pi,P')替换为(Pi,Pt)来更新pi的top-lp列表Li. 3)增量更新top-k个摘要
(第7行),其中top[k/2]对摘要具有最大质量F(·)。如果|
|<k,则在
中添加一个使质量F(
∪{P})最大化的摘要P。
在任何时候,它根据请求返回当前(第8-9行)。 重复上述过程,直到无法从sumGEN中获取新的模式。
example3:(1)在第1轮中,它调用sumGEN来发现最大的2-摘要,例如P3,并用P3初始化CP和SG。 (2)在第2轮中,发现了一个新的2-总结P2,验证了F(P2,P3)为0.9*(0.20+0.18)+0.1*0.90=0.43,并将L2={<(P2,P3),0.43},L3={<(P3,P2),0.43},SG更新为{P2,P3}。 (3)在第3轮中,它发现了P1,并证明了F(P1,P2)=0.62和F(P1,P3)=0.61。 因此,L1、L2和L3分别更新为(P1,P2)、(P2,P1)和(P3,P1)。 因此,它将更新为{p1,p2}。 当发现大小为8的所有最大摘要时,Streamdis终止并返回
={p1,p2}。
4.KNOWLEDGE GRAPH SEARCH WITH SUMMARIES
接下来,我们通过开发这样一个查询评估算法,证明了d-Summarties能够在有限的资源范围内推荐相关数据,并支持快速的知识图搜索。
给定一个查询Q、一个知识图G和一个总结,我们的查询评价算法(记作evalSum)有以下两个步骤。
◦ 从SG中选取一组具有“物化”基图的摘要,尽可能多地包含Q的可能答案。
◦ 然后根据这些基图计算出(部分)答案Q(G),并在必要时从G中获取有界量(Δ)的数据来完成Q(G)的计算。
摘要选择 给定一个查询Q和一个摘要,摘要选择的目的是在
中找到一个由N个摘要组成的集合P,使得Q的最大部分被P覆盖,并且基图B的总大小有界。为此,选择过程贪婪地添加“最大”覆盖Q并且在G中有小的基图的摘要P。
它动态地更新SG中摘要的秩r(P)=,其中(1)
是基图QP的边集, 由摘要P和查询Q(作为图)之间的d-相似度导出; (2)
是指Q的已被“覆盖”的边,即已在选定的摘要p∈P的基图中。 在每一轮选择中,在P中添加一个r(P)最高的摘要,并动态更新剩余摘要在
中的排名。 该过程重复直到选择N个模式,或者基图的总大小达到B。
5.EXPERIMENTAL EVALUATION
利用真实世界和综合知识图,我们进行了三组实验来评估1)摘要挖掘算法approxDIS和streamDIS的性能;2)算法evalsum用于查询评估的有效性; 3)摘要的有效性,使用案例研究。
Experimental Setting
数据集。我们使用了三个现实生活中的知识图:
| DB-pedia | 由4.86M节点和15M边组成,其中每个实体携带676个标签中的一个(例如,“定居点”、“人”、“建筑物”); |
| YAGO2 | 一个比DBpedia更稀疏的图,有1.54M节点和2.37M边,但包含更多样化(324343)的标签; |
| Freebase | 拥有40.32万个实体、63.2万个关系和9630个标签。 |
查询。为了评估evalSum算法,我们在真实世界的图上生成了50个子图查询Q=(Vq,Eq,Lq),其大小由(|Vp|, |Ep|)控制。我们检查了在真实世界知识图上提出的有意义的查询,并从它们的数据(域、类型和属性值)中提取标签生成查询。对于合成图,我们用BSBM字母表中的标签生成了500个查询。我们用不同的拓扑(星形、树状和循环模式)和大小( 范围从(4,6)到(8,14))生成查询。
算法. We implemented the following algorithms in Java:
(1) Summarization algorithms approxDis and streamDis
(2) Query evaluation algorithm evalSum
Overview of Results. We summarize our findings below.
1)用d-Summaries(EXP-1)对现实世界中的大型图进行总结是可行的。 我们的算法streamDIS在较小的时间预算(90秒)内产生了高质量的摘要(例如,相对于它的2近似对应的ApproxDIS至少99%的准确率),在Yago上有391万个实体和关系。 它比通过挖掘频繁子图模式(GRAMI)进行总结要快数量级。
2) d- summary显著提高了查询评价的效率(表2)。例如,在YAGO上,evalSum比evalNo(不使用摘要)快40倍。它比使用频繁的子图模式作为视图的同类程序快2.5倍。此外,摘要选择是有效的:evalSum比evalRnd(随机选择摘要)的性能好2倍,最多使用64个摘要。最后,它不需要花费太多额外的成本(Δ≤5%的图大小)来找到确切的答案。
3)实例研究表明,d- summary捕获的摘要信息简洁,能够很好地覆盖多样化实体。
We next report the details of our findings
EXP-1:摘要的效率。我们评估了approxDis、streamDis、heuDis和GRAMI在现实世界知识图中的效率。对于任意时刻的流算法dis和heuDis,我们报告了它们的收敛时间。对于GRAMI,我们仔细地调整了支持阈值,以允许生成与来自approxDis的标签集和大小相似的模式。如图3(a)所示,1)streamDis和approxDis都比GRAMI快一个数量级。后者不会运行到完成10小时内的DBpedia和Freebase;2) streamDis的性能与heuDis相当,streamDis的速度是approxDis的3-6倍,精度与之相当;3)在大型知识图上是可行的。例如,通过仅验证YAGO的64个摘要,生成高质量的摘要只需不到100秒。
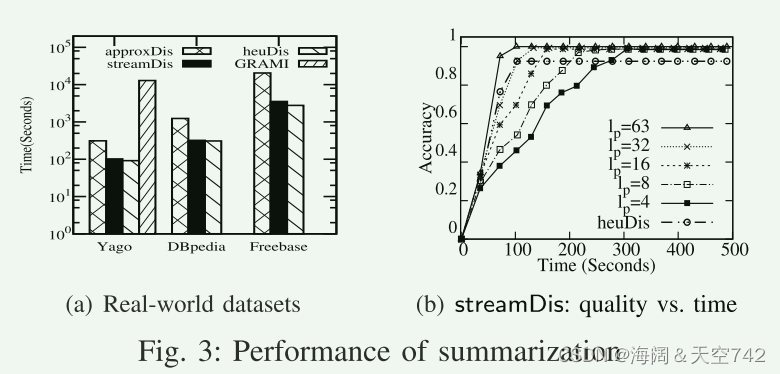
这些结果验证了streamDis提供了一种权衡准确性和时间的有原则的方法,并通过处理少量的摘要提前收敛。
EXP-2 我们评估了由四种评估算法产生的查询答案的准确性。设Q(G)A为查询求值算法A返回的节点和边的匹配集,Q(G)为精确匹配集。我们将算法A的精度定义为Jaccard相似性。对于evalNo,精度为1。如图4(b)所示,Δ越大,所有算法性能越好,evalSum准确率最高,Δ=1.5%。值得注意的是,evalSum在原始图的7.5%的情况下可以获得100%的准确率,但evalGRAMI需要的数据比evalSum更多。
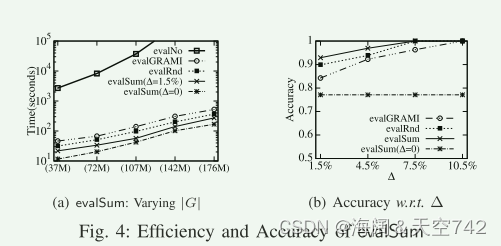
EXP-3 我们进行了案例研究,以测试需要“覆盖”来自DBpedia的50个采样的模糊关键字(例如,“滑铁卢”,“特斯拉”,“阿凡达”)的所有实体类型的总结数量。每个关键字平均有4种不同类型。我们观察到,对于高度多样化的摘要(例如,α =0.9),需要更少的摘要数量(例如,k =9)来覆盖所有实体类型。对于所有情况,最多需要15个摘要来覆盖每个关键字的所有类型。而GRAMI的大部分总结都是冗余的小模式,即使在k=64时也不能涵盖关键字的实体类型。
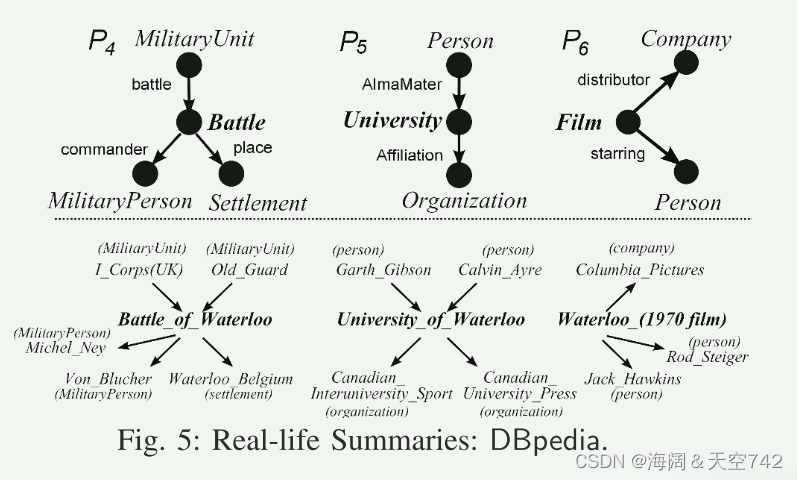
图5显示了从DBpedia中发现的三个关键字“waterloo”的现实生活2-摘要,它们将“waterloo”区分为Battle实体(P1)、University (P2)和Films (P3)。这些摘要建议中间关键字作为增强查询(例如,军事人员);也可以提出答案,例如,Pr´ecis查询发现单一实体的多样化事实。
6.CONCLUSIONS
我们提出了一类d-摘要,并开发了可行的摘要挖掘算法来总结大型的、无模式的知识图。通过选择和访问少量的摘要及其基图,开发了高效的查询评价算法。实验结果表明,该算法能够高效地生成简洁的摘要,显著降低了无模式知识图的查询评价成本。我们未来的工作是通过引用摘要来启用查询建议和资源限制的查询评估,以获得更多类型的查询类。
7.启发
本篇文章使用一些生动的例子使得一些算法和概念更加形象,有助于理解。
与传统的由频繁子图定义的摘要相比,该摘要能够自适应地对具有相似邻居的实体进行有界的概括。
图摘要的重要性:知识图通常用于表示知识库中的实体及其关系。与关系数据不同,真实世界的知识图缺乏定义良好的模式和类型系统的支持。如果没有对底层数据图的任何先验知识,最终用户很难精确查询,从而得到有意义的答案。由于查询中的模糊性、固有的计算复杂性(例如,子图同构)和资源约束(例如,允许访问的数据、响应时间)大型知识图,查询此类知识图是具有挑战性的。
在知识图上开发了一种查询评估算法。该算法选择并引用一小组最能“覆盖”查询的摘要,并仅在必要时从原始知识图中提取实体。
精简摘要可以支持模糊的关键字搜索和对多个知识库的“跨域”查询。
8.问题
1.对于知识图谱的图示方式还不是太理解
1、知识图谱一般用attributed graph表示,也就是每个节点/边有一个(或多个标签label),还有一个或多个attribute(可以认为是key-value pair);
2.StreamDIS算法中调用的挖掘过程sumGEN是如何获取新生成的摘要的?
sumGen就是构建一个个pattern candidate,可以认为是从一条条边开始,不断得聚合,得到更大的pattern;
3.评价一个摘要的好坏除了信息量和多样化,是否还有其他标准?
摘要的好坏还可以通过后续基于摘要的应用来评价(例如基于摘要的查询效率);
4.对于d-summaries中的d不是太理解。
d是一个超参
5.文章中的hop怎么理解?
hop就是跳的概念,如果两个节点是邻居,那就是1-hop,如果A和B相连,B和C相连,那么A和C就是2-hop neighbor。















 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









