






https://github.com/aLler00/hello/tree/main/102001102
一、PSP表格
| PSP21 | PSP2.1Personal SoftwareProcess Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 180(计划零零散散的需要改动) |
| Estimate | 估计这个任务需要多少时间 | 3000 | 2520左右 |
| Development | 开发 | 600 | 720 |
| Analysis | 需求分析 (包括学习新技术) | 420 | 300 |
| Design Spec | 生成设计文档 | 120 | 60 |
| Design Review | 设计复审 | 30 | 90 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 120 | 180 |
| Coding | 具体编码 | 180 | 300 |
| Code Review | 代码复审 | 30 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 40 | 120 |
| Test Repor | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 120 |
| 合计 | 4980 | 5080 |
二、任务要求的实现
-
(3.1)项目设计与技术栈。从阅读完题目到完成作业,这一次的任务被你拆分成了几个环节?你分别通过什么渠道、使用什么方式方法完成了各个环节?列出你完成本次任务所使用的技术栈。
-
这一次的任务大概被我拆分成了7个环节,分别是
<1>获取爬取方法
<2>获取疫情信息每页中每日疫情的url链接
<3>获取每个url中的内容
<4>从内容中筛选出正文
<5>对正文信息数据进行正则匹配
<6>导出数据
<7>可视化 -
大致是通过不断去CSDN查询方法,根据模块分开查询,综合多篇文章意见进行实验寻找适合本次作业的方法,爬取使用了调用火狐浏览器,隐藏headers,爬取链接和内容采用了find函数对’li a’和browser.page_source进行了查找,筛选正文用到了find’id": “xw_box”'下的find_all(p)。技术栈为re + bs4 + selenium.webdriver + time+ pandas + pyecharts
-
-
(3.2)爬虫与数据处理。说明业务逻辑,简述代码的设计过程(例如可介绍有几个类,几个函数,他们之间的关系),并对关键的函数或算法进行说明。
-
大致的逻辑就是先进行数据爬取,然后用find提取相关内容,最后用正则匹配。我总共上交了两个程序,“各种url及正文内容获取”中是对前8页的疫情数据的一个提取,在这里我用到了两个函数,def getpageurl()与def getContent(html),分别用来获得疫情官网中前n页的大url链接和获取大url链接中每个小url连接中正文的内容。这些配合main函数的for循环进行,最终目的就是提取出所有小循环中正文的内容。”正则处理与可视化“中我对正文的内容进行了正则匹配,获取本土新增确诊病例与新增无症状感染者的数据。(因为疫情数据太多,如果用前一个程序集中提取会出现内存被爬没以及间接性爬取不到,数据不稳定的问题,所以用了整个程序匹配了单个大url链接中单个小url链接的正文内容进行了正则匹配及可视化,正则用多例内容匹配过,可以适用)
-
(3.3)数据统计接口部分的性能改进。记录在数据统计接口的性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(例如可通过VS 2019/JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
- 在程序中消耗最大的函数是def getContent(html)函数爬取7页数据大概需要20分钟。def getpageurl()函数展示所有大链接需要3分钟。暂时没想到怎么改进,因为time.sleep少了就会爬取失败,数据量越大需要的间隔时间越长。可能是我的代码不够完善。
-
(3.5)数据可视化界面的展示。在博客中介绍数据可视化界面的组件和设计的思路。
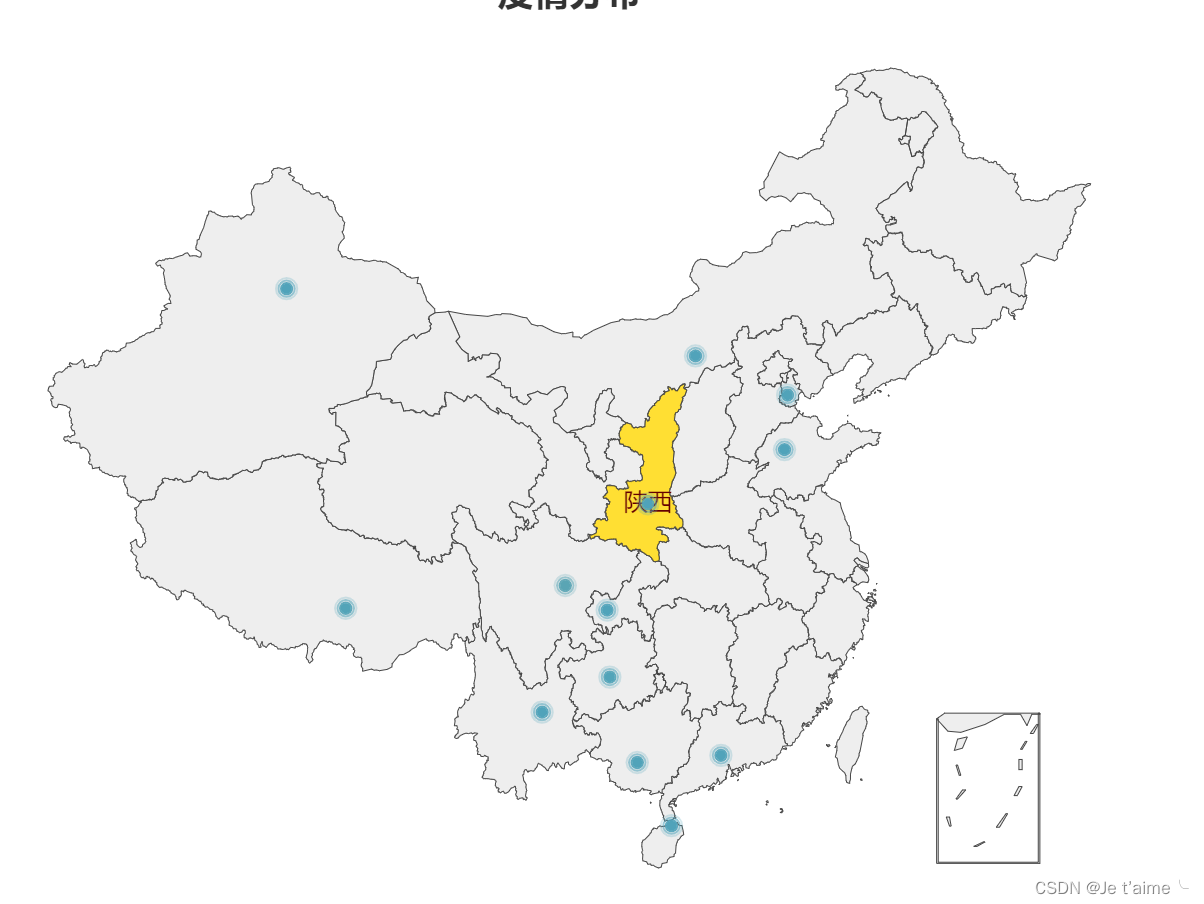
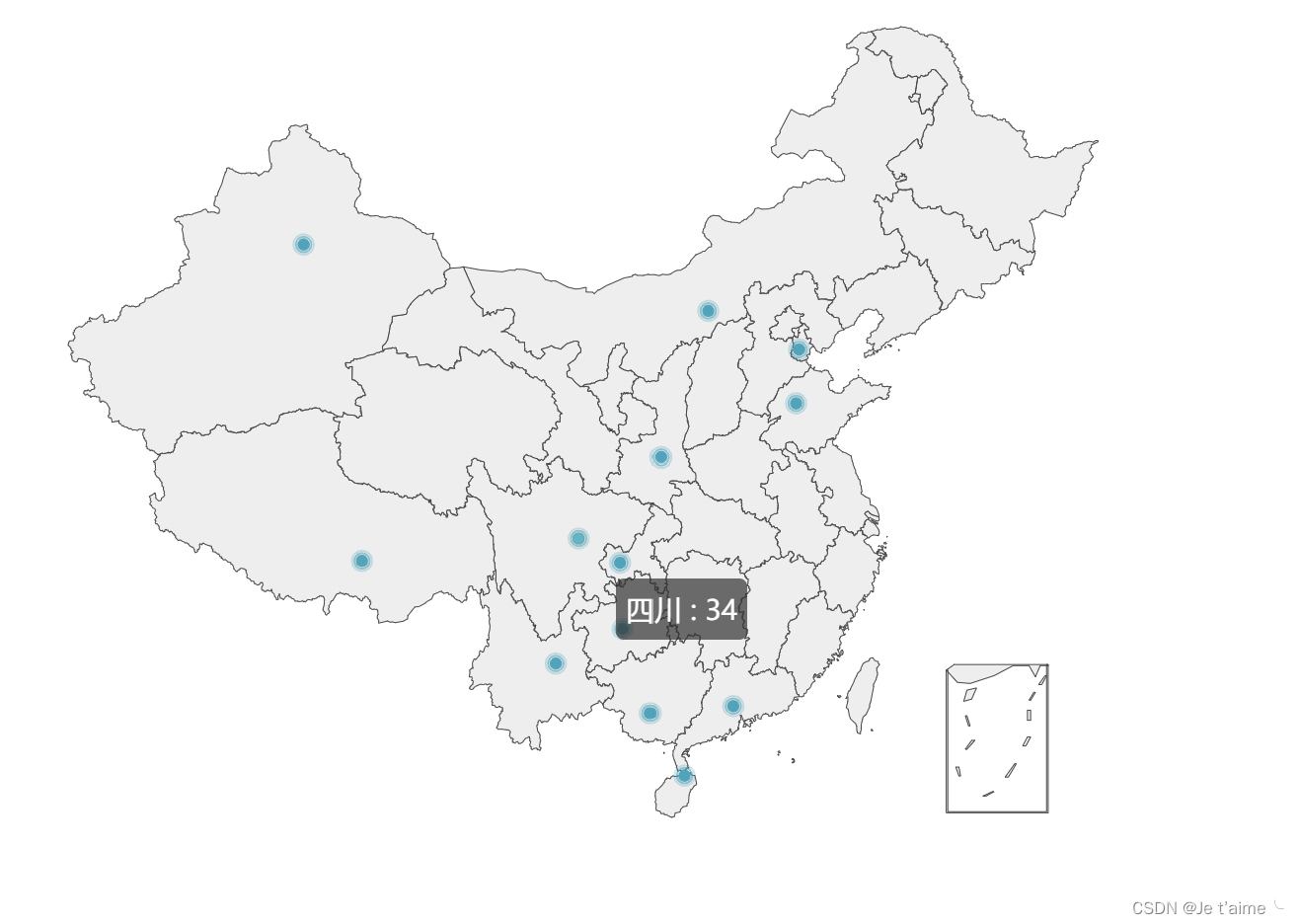
- 我的数据可视化是用了python自带的函数
geo=Geo(init_opts=opts.InitOpts(theme=ThemeType.WHITE),is_ignore_nonexistent_coord = True)#初始化
geo.add_schema(maptype='china')#中国地图
geo.add('',lst,symbol_size=5,itemstyle_opts=opts.ItemStyleOpts(color="red"))#导入数据、设置图中点大小、颜色
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False),type='effectScatter')#设置画图类型
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(min_=1,max_=1000),title_opts=opts.TitleOpts(title="疫情分布",pos_left="center"))#设置岗位阈值、标题位置
geo.render("疫情分布.html")#存储成html格式
因为个人觉得地图可能好看一点所以选择了地图。实现思路大概是先要用正则表达式匹配出来相应的地名和例数,然后形成字典(字典可以导出来excel表格),然后我就试着把字典转换成列表与python函数进行了匹配,得到了我的可视化地图。
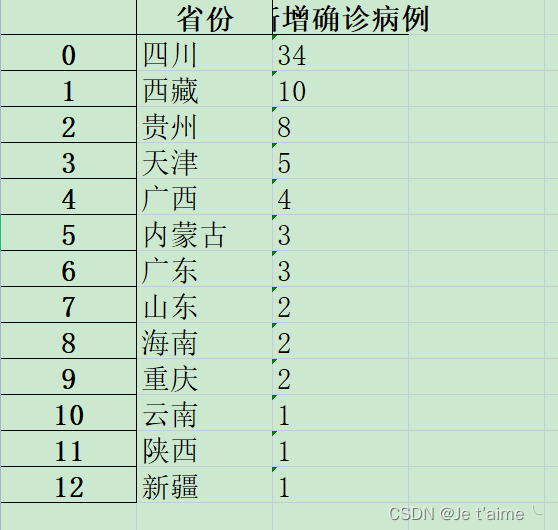
但是导出来的excel有点丑。。。。
三、心得体会
-
(4.1)在这儿写下你完成本次作业的心得体会,当然,如果你还有想表达的东西但在上面两个板块没有体现,也可以写在这儿~
- 首先必须要说,以我的最开始的能力,要完成这个项目真的很难,爬虫我也就是爬过京东,正则也不是很熟,刚开始听到老师的要求我真的挺绝望,听着好难哦。但也不能放弃呀,然后就学嘛,试呀,错了就去各种搜解决方式,中途放弃了好几段写出来的代码因为他们实在是面对卫健委太多数据就会废掉。真的很痛苦,我经常忽然卡在某个点没有思路,然后又很担心做不出来,特别是这周,真的真的无比痛苦。但是其实写这篇文章的时候感觉其实我也没做什么,现在看来好像对我来说都是可以实现的功能了,这就是收获吧。真真实实地痛苦了,也真真实实的收获了,其实转过头来看真的都是一些很基础的功能,而且说实话我也没做的尽善尽美,这个程序还有好多好多需要我以后慢慢改进的东西。但真的会有收获,以前的我看到一个难题可能就直接不想面对了,现在就变成了,试一下,没准就解决了。真的人不逼一把是永远不知道自己能不能做到的。















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









