






CIFAR-10 数据集简介 CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32,RGB三通道 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。 CIFAR-10 的图片样例如图所示。

LeNet-5是一种经典的卷积神经网络结构,于1998年投入实际使用中。该网络最早应用于手写体字符识别应用中。普遍认为,卷积神经网络的出现开始于LeCun 等提出的LeNet 网络(LeCun et al., 1998) ,可以说LeCun 等是CNN 的缔造者,而LeNet-5 则是LeCun 等创造的CNN 经典之作 。 所以我们选择采用简单改造过一点点的LeNet-5网络(添加了ReLu非线性激活函数和dropout防止过拟合)去训练CIFAR10数据集。下图是本次介绍的网络模型图。其中卷积核的大小是5x5,步长为1,padding为2。池化是2x2。最后输出的是10个预测值。

导入相关的库
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter准备数据集和加载数据
加载好之后我们再用Dataloader把图片进行批量处理(64张图片每一批) 注意:如果CIFAR10数据集未下载,download为True会帮你下载
data_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),#随机翻转
torchvision.transforms.ToTensor()
])##先将图片数据进行随机翻转再转化为tensor数据类型
#准备数据集
train_data = torchvision.datasets.CIFAR10("X:\\pycharm\\chengxu\\new\\dataset", train=True, transform=data_transform, download=True)
test_data = torchvision.datasets.CIFAR10("X:\\pycharm\\chengxu\\new\\dataset", train=False, transform=data_transform, download=True)
#看看数据集的长度
train_data_size = len(train_data) ##50000个训练图片 一个图片是(3,32,32)
test_data_size = len(test_data)##10000个测试图片
print(train_data_size, test_data_size)
#利用Dataloader来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)## 从五万个训练图片中,64个图片一起训练(批量训练)数据变为了(64,3,32,32)
test_dataloader = DataLoader(test_data, batch_size=64)##从一万个测试图片中,64个图片一起测试(批量测试)
#创建网络模型
class Flatten(nn.Module):##展平操作
def forward(self, input):
return input.view(input.size(0), -1)搭建LeNet-5卷积神经网络
数据准备好后,我们需要搭建好模型,按照上述LeNet神经网络的图,我们照搬它的参数搭建此网络的类,然后初始化这个模型,参数放在GPU上存储运算。
#创建网络模型
class Flatten(nn.Module):##展平操作
def forward(self, input):
return input.view(input.size(0), -1)
#搭建神经网络
class Tudui(nn.Module):
def __init__(self, num_classes=1): ##num_classes是最终的输出的类别数,需要人为传入,若不传入默认为1,CIFAR10是10分类,所以需要传入10
super(Tudui, self).__init__()
self.model = nn.Sequential( ##输入的图片tensor数据是(3,32,32)大小
nn.Conv2d(3, 32, 5, stride=1, padding=2),##3是输入通道,32是输出通道,5是卷积核大小,步长为1,padding为2
nn.ReLU(inplace=True),
nn.MaxPool2d(2), ##第一次卷积池化后的数据是(32,16,16)
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), ####第二次卷积池化后的数据是(32,8,8)
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(2), ####第三次卷积池化后的数据是(64,4,4)
Flatten(), ##把上面的卷积结果拉直,成为一个向量(64*4*4),即(1024)
nn.Dropout(0.5),
nn.Linear(1024, 64), ##1024=64*4*4 线性层,也即全连接层
nn.ReLU(inplace=True),
nn.Linear(64, num_classes),
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui(num_classes=10) ##模型对象
tudui = tudui.cuda()##.cuda,把模型里面的需要学习的参数放在GPU上存储运算优化器和损失函数的选择,学习率和epoch(训练次数)
在这里选择了学习率为0.01的随机梯度下降 使用tensorboard的SummarWriter进行可视化 损失函数我们选择了CrossEntropyloss CrossEntropyloss会把模型最终的10个输出先做softmax,然后再与真实的标签进行交叉熵计算。
#损失函数
loss_fn = nn.CrossEntropyLoss()##CrossEntropyloss是先做softmax再进行利用交叉熵进算损失
loss_fn = loss_fn.cuda()##.cuda,运算放在GPU上
#优化器
learn_rate = 0.01
optimizer = torch.optim.SGD(tudui.parameters(), lr=learn_rate)##采用SGD随机梯度下降法
#设置训练网络的一些参数
total_train_step = 0 #记录训练集的训练次数
total_test_step = 0 #记录测试集的训练次数
epoch = 70 ##训练70遍
#添加tensorboard
writer = SummaryWriter("../logs_train") ##生成可视化运行过程中正确率变化的文件训练和测试
前面的代码定义了epoch=70,所以会训练70遍 首先从dataloader中加载数据和标签,数据扔进模型进行计算输出,再和标签进行交叉熵损失计算,然后采用随机梯度下降法,反向传播更新模型的参数,每训练100次图片记录一次训练上的交叉熵损失
每一次训练之后,模型的参数都会有所改变。所以会在训练后的模型上进行测试,检查它的正确率和测试集上的交叉熵损失 上图是测试集上测试的代码
for i in range(epoch):##每训练五万张图片,我们就要测试一万张图片,检测每一次训练后模型的效果
print(".....第{}轮训练开始.....".format(i+1))
tudui.train() ##说明开始训练
#total_accuracy1 = 0
for data in train_dataloader:##从dataloader中加载数据
imgs, targets = data ##imgs是图片数据,targets是图片所对应的标签
imgs = imgs.cuda()
targets = targets.cuda()##图片和标签都防止GPU上存储运算
output = tudui(imgs)##图片数据进入上面拟定好的LeNet模型对象
loss = loss_fn(output, targets) ##利用上面拟定好的CrossEntropyloss先做softmax再进行利用交叉熵进算损失
#优化器优化模型
optimizer.zero_grad()##随机梯度下降法的梯度清0
loss.backward()
optimizer.step() ##反向传播进行参数更改
total_train_step = total_train_step + 1 ##记录训练图片的张数
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("tran_loss", loss.item(), total_train_step)##看看每100次图片训练中的损失
# accuracy1 = (output.argmax(1) == targets).sum()
# accuracy1 = accuracy1.item()
# total_accuracy1 = total_accuracy1 + accuracy1
# print("整体训练集上的正确率:{}".format(total_accuracy1 / train_data_size))
# writer.add_scalar("训练集正确率", total_accuracy1 / train_data_size, total_train_step)
total_test_loss = 0 ##初始化测试集上的损失
total_accuracy = 0##初始化测试集上预测正确的个数
#测试步骤开始
tudui.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data ##imgs是图片数据,targets是图片所对应的标签
imgs = imgs.cuda()
targets = targets.cuda() ##图片和标签都防止GPU上存储运算
outputs = tudui(imgs) ##图片数据进入上面拟定好的LeNet模型对象
#print(outputs.shape)
loss = loss_fn(outputs, targets)##利用上面拟定好的CrossEntropyloss先做softmax再进行利用交叉熵进算损失
total_test_loss = total_test_loss + loss.item()##计算测试集上的损失
accuracy = (outputs.argmax(1) == targets).sum()##计算预测准确个数
accuracy = accuracy.item()
total_accuracy = total_accuracy + accuracy ##计算总的正确个数
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size)) ##正确率=正确个数/测试集图片总数
writer.add_scalar("test_loss", total_test_loss, total_test_step+1)##可视化测试集上损失的变化
writer.add_scalar("测试集正确率", total_accuracy/test_data_size, total_test_step+1)##可视化正确率的变化
total_test_step = total_test_step + 1##记录测试集的轮数
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")##保存第i轮训练的模型
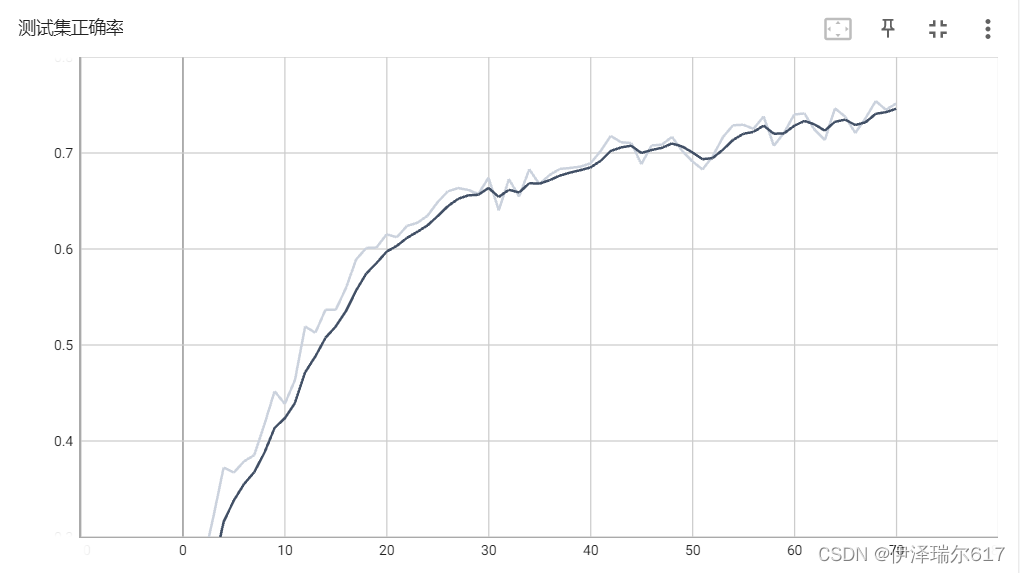
writer.close()##关闭文件下图中x轴是epoch(训练次数) y轴是测试集上正确率 如图所示,随着在训练集上训练epoch的次数增加,优化过的模型参数在测试集上的做出预测的正确率越高,但极限是大概75%的正确率左右
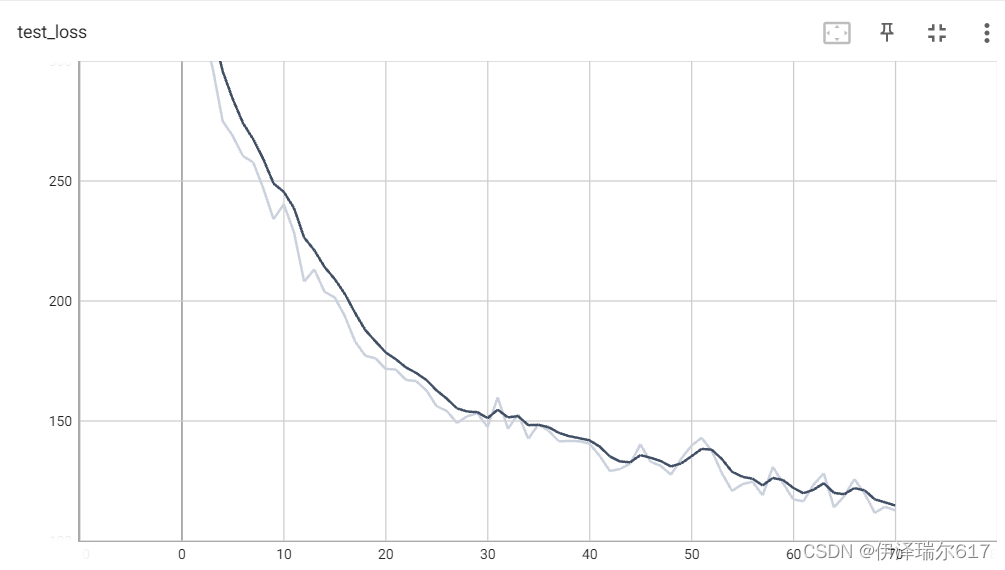
从下图我们也可以发现,随着训练的次数增多,模型在测试集上的交叉熵损失也在减小。














 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









