






FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping
注:与前一篇重叠的内容在此省略
1、Introduction
-
联邦学习(FL)的介绍以及过程中遇到的问题阐述
-
本文主要工作
clean training dataset
-
可防御现有的攻击以及适应性攻击(model poisoning attack)
-
主要贡献:
- 提出FLTrust,引导信任实现防御
- 可抵御大部分攻击
- 对针对本防御的自适应攻击仍具有较强的鲁棒性
2、BACKGROUND AND RELATED WORK
-
聚合规则
FedAvg:(用于非对抗)最基本的模型平均方法
3、 PROBLEM SETUP
-
攻击模型
攻击者为full knowledge
-
防御目标
Fidelity:在没有攻击时,应实现全局模型的高精度。
Robustness:应该在恶意客户端进行强中毒攻击的情况下,保持全局模型的精度。
Efficiency:该方法不应引起额外的计算和通信开销。
-
防御者能力认定
- 可以获得一个干净的小训练数据集(根数据集)
- 可以完全访问全局模型以及所有客户机的本地模型更新
4、FLTrust
-
概述
三个关键特征:一个根数据集、使用ReLU剪辑余弦相似度评分、标准化每个本地模型更新(方向和大小)。
ReLU:大于零的为本身,小于零的取零
-
ReLU-clipped cosine similarity based trust score
使用余弦相似度来计算本地模型更新和服务器模型更新之间的方向相似度,不能为负面影响,故采用ReLU
-
Normalizing the magnitudes of local model updates
对每个本地模型更新进行标准化,使其具有与服务器模型更新相同的量级。
-
Aggregating the local model updates
计算归一化的本地模型更新的平均值,以其信任分数加权作为全局模型更新
-
自适应攻击
存疑
5、EVALUATION
- 参数设置
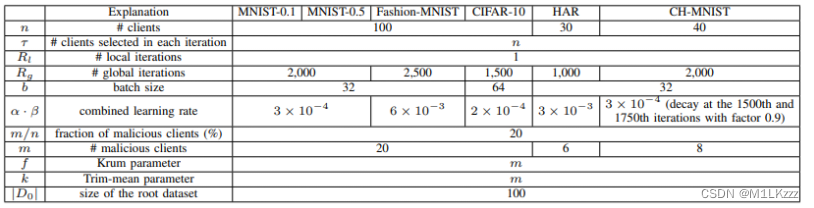
-
实验结果
实现了预设的三个目标:保真度、健壮性和效率性。
-
五种变体

实验结果表明, FLTrust优于FLTrust-NoReLU,FLTrust-NoNorm和FLTrust-ParNorm,证明了ReLU操作和规范化的必要性
6、Future Work
- 设计更强的local model poisoning attack
- 考虑根数据集信任度














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









