






Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
1、Introduction
-
拜占庭鲁棒联邦学习简介
-
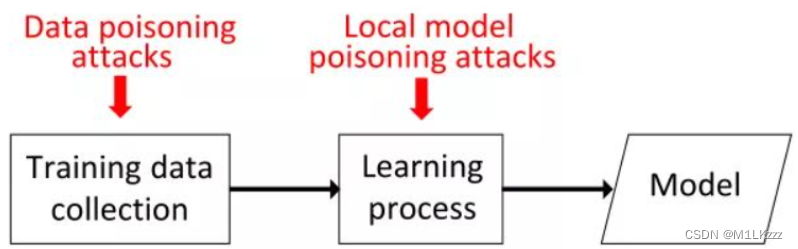
现有的data poisoning attacks 效果差
-
local model poisoning attacks简介
-
主要贡献:
- 对拜占庭-鲁棒联邦学习进行了第一次系统研究
- 提出了localmodel poisoning attacks
- 结合了两种现有的防御方式
2、 Background and Problem Formulation
-
联邦学习三步:
- master device发送现有的全局模型参数到worker devices
- worker devices通过自己的本地训练集更新参数,完成后发送给master device
- master device聚合本地模型得到一个新的全局模型
-
拜占庭-鲁棒聚集规则
-
Krum and Bulyan***(存疑)***
在m个本地模型中选一个最相似的作为全局模型
-
Trimmed mean
先去掉2β个极大&极小模型参数,再对剩下的求平均
(β一般要≥compromised worker的数量,<worker总数的一半)
-
Median
先去掉2β个极大&极小模型参数,再找到剩下数据中的中位数
-
-
问题定义和攻击模型
目标是使global model朝着无攻击方向最相反的方向偏移
攻击者能力:
- 是否知道聚集规则
- full knowledge or partial knowledge
3、Our Local Model Poisoning Attacks
-
优化问题
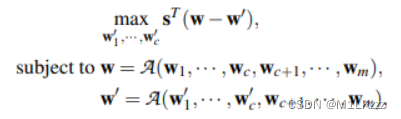
前c个为compromised workers,控制w_1`到w_c`,目的是使得s(全局模型参数变化方向的列向量)最大化。
-
Attacking Krum
首先,将 w’_1 限制如下:w’_1=w_Re-λs,其中 w_Re 是当前迭代中从主设备接收的全局模型(即上一次迭代中获得的全局模型),并且λ> 0。其次,为使 w_1 更有可能被 Krum 选择,将其他 c-1 折衷的局部模型设计为接近 w’_1
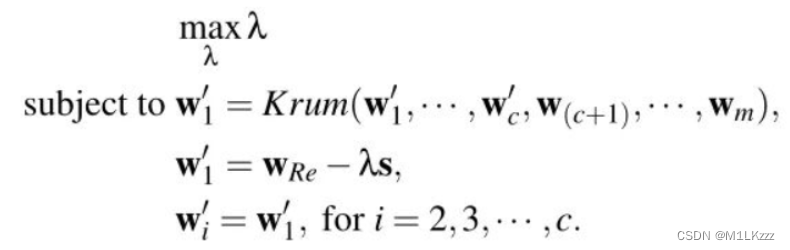
full knowledge和partial knowledge的区别就是一个用全部的模型参数预估s、一个用compromised workers预估s
-
Attacking Trimmed Mean
在full knowledge下,如果 s_j = -1,那么将在间隔 [w_(max,j) ,b·w_(max,j) ] 中随机采样 c 个数字,否则,将以[w_(min,j)/ b, w_(min,j)] 间隔对 c 个数字进行随机采样。
Our attack does not depend on b once b > 1. In our experiments, we set b = 2. 在partical knowledge下,使用compromised workers上的局部模型来估算变化方向的变量和w_(max,j)、w_(min,j)
-
Attacking Median
和Attacking Trimmed Mean几乎相同
4、Evaluation
-
实验基本设置
数据集采用 MNIST, FashionMNIST, CH-MNIST and Breast Cancer Wisconsin (Diagnostic) 这四个。
机器学习分类:(存疑)
1、Multi-class logistic regression (LR) 多类逻辑回归
2、Deep neural networks (DNN)深度神经网络
-
对比攻击
-
高斯攻击
用compromised workers的参数构造一个高斯分布,用其中特定的数字作为局部模型参数
-
标签反转攻击
即字面意义的换标签
-
基于反向梯度优化的攻击
存疑
-
全部知识攻击和部分知识攻击(本文)
参数设置如图所示:
-
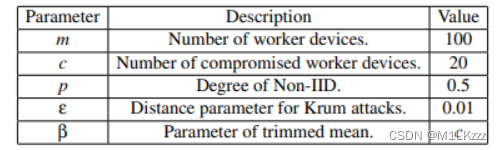
-
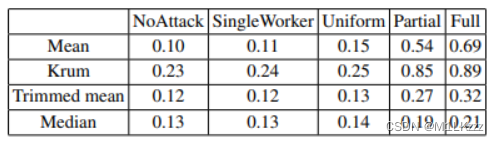
攻击结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-igBFmPt6-1688571855490)(D:\typora\photograph\image-20220914222137101.png)]](https://img-blog.csdnimg.cn/1619c28e63374377a28d512e03bcd646.png)
使用本文的攻击方法得到的错误率大多显著高于其他已知的攻击方法
-
其他因素对于实验结果的影响
如随机梯度下降轮数、worker devices数目、compromised workers数目、修剪均值攻击中的β、Krum中的参数以及中毒迭代的占比
-
Results for Unknown Aggregation Rule
对于未知聚集规则,本攻击具有可移植性
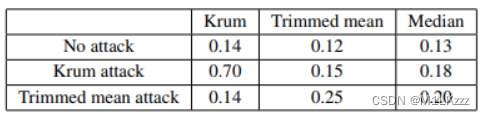
- 与基于反向梯度优化的攻击的对比
5、Defenses
-
Error Rate based Rejection (ERR)
删除了对全局模型的错误率具有较大负面影响的局部模型(受 RONI 的启发,后者删除了对模型的错误率具有较大负面影响的训练示例)
-
Loss Function based Rejection (LFR)
删除了导致大量损失的局部模型(受 TRIM 的启发,删除了对损失有较大负面影响的训练示例)
-
Union (i.e., ERR+LFR)
防御结果:Union>LFR>ERR,但仍然有些情况无法防御
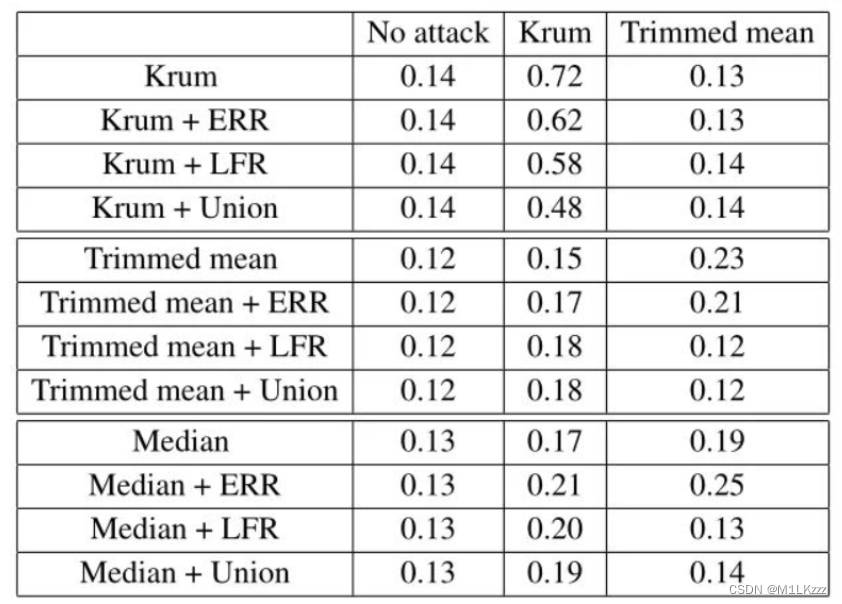
6、Future Work
-
对定向攻击的研究
-
对本文攻击的防御手段的研究















 2292
2292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









