







目录
简介
该项目由阿里通义团队开源,提供解决“谁在何时说话”问题的说话人日志方法,包含两种处理流程:提供解决“谁在何时说话”问题的说话人日志方法,包含两种处理流程:
- 纯音频说话人日志:由多个模块组成,包括重叠检测(可选)、语音活动检测、语音分段、说话人特征提取和说话人聚类。
- 多模态说话人日志:融合音频和视频图像输入以生成更精确的结果。
论文地址(ICASSP2025)
论文阅读
摘要(原版翻译)
我们介绍了3D-Speaker-Toolkit,一个开源的多模态说话人验证和日志工具包,旨在满足学术研究者和工业从业者的需求。3D-Speaker-Toolkit巧妙地结合了音频、语义和视觉数据的优势,无缝融合这些模态以提供强大的说话人识别能力。
音频模块从音频特征中提取说话人嵌入(embeddings),采用全监督和自监督学习方法。
语义模块利用先进的语言模型理解口语的内容和上下文,从而增强系统通过语言模式区分说话人的能力。
视觉模块应用图像处理技术分析面部特征,提高多说话人环境中说话人日志的精度。
这些模块共同使3D-Speaker-Toolkit在说话人相关任务中显著提高了准确性和可靠性。通过3D-Speaker-Toolkit,我们为多模态说话人分析设立了新标杆。该工具包还包含多个开源的最新模型和一个包含超过10,000名说话人的大规模数据集。
INTRODUCTION
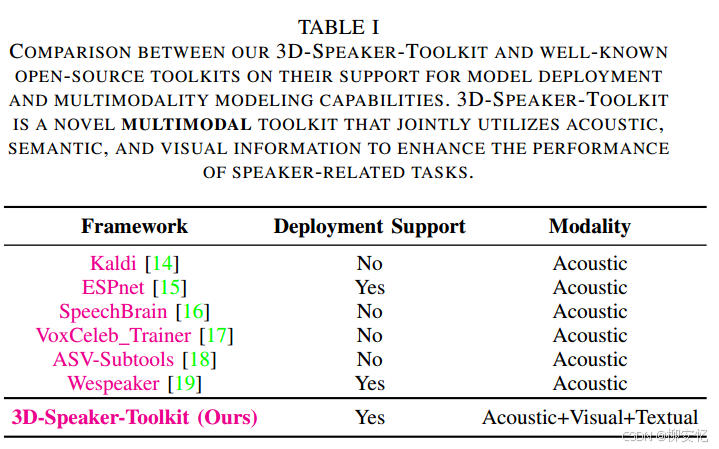
多模态性:主流的说话人相关方法主要依赖音频信息,但在恶劣音频条件下性能可能会下降。3D-Speaker是首个多维(除音频外)开源音频工具,通过整合音频、语义和视觉模态,对说话人身份和特征进行多维度分析。
开箱即用、方便部署:
- 提供了数十个说话人嵌入提取器。
- 所有模型都可以导出为ONNX格式。
大型数据集3D-Speaker dataset,多维音频数据的受控组合产生了多样化的语音表征混合矩阵:
- 包含超过10,000名说话人,分为训练集和测试集。
- 每位说话人通过多个设备同时录制,说话人与录制设备之间的距离各不相同。
- 部分说话人还使用多种方言。
在说话人验证和日志任务上SOTA。
自监督学习(SSL)支持。
轻量化。
一些开源模型:
3D-SPEAKER-TOOLKIT
主要由音频模块、语义模块和视觉模块三部分组成。
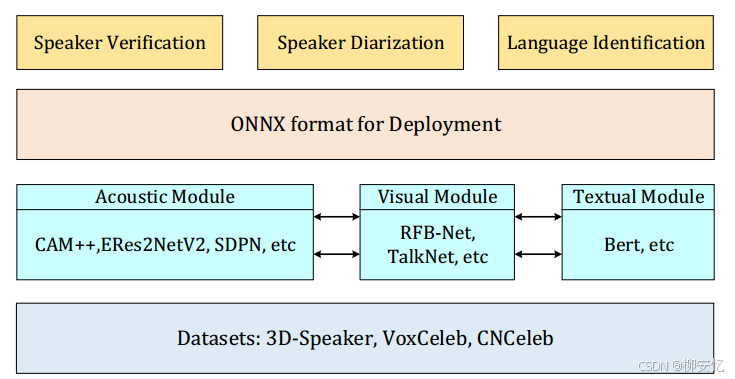
A. 音频模块
该模块引入传统音频信息以提取具有区分性的说话人表征,可用于说话人验证、日志等任务。
特征准备( Feature Preparation)
- 传统学习特征是静态的。
- 3D-Speaker-Toolkit实时处理原始波形数据:1.不存储数据增强与处理好的特征,减少占用磁盘。2.每轮训练数据增强不同,高鲁棒性。
支持的模型
- 全监督模型,如ECAPA-TDNN、ResNet34、Res2Net、ERes2Net、ERes2NetV2、CAM++
- 自监督模型,如DINO、RDINO和SDPN。
- 经典模型如ResNet34、Res2Net、ECAPA-TDNN和DINO
- 原创模型,即ERes2Net、ERes2NetV2、CAM++、RDINO和SDPN
对全监督模型的创新中,ERes2Net在Res2Net的基础上通过融合局部和全局特征来提升性能。其继任者ERes2NetV2则针对更有效地从短时语音中捕获特征进行了优化。
CAM++基于密集连接的时间延迟神经网络(D-TDNN)骨干构建,并采用了一种新颖的多粒度池化技术,以在降低计算复杂度的同时捕获多层次的上下文信息。
对自监督模型程序方面,RDINO在DINO中引入了两个应用于嵌入的正则化项,以缓解非对比自监督说话人验证框架中的模型坍塌问题。
SDPN框架将语音增强视图的表征分配给与原始视图相同的原型,从而促进学习具有区分性的自监督说话人表征。
模型导出与部署
- 导出为ONNX格式以部署在Triton Inference Server上。
- 提供了工具包中发布的模型的开箱即用功能。用户只需指定模型名称即可轻松加载预训练的说话人嵌入提取器。
嵌入提取与推理
通过部署的特征提取器,用户只需几行代码即可快速提取说话人嵌入。在得分层会应用额外的处理。在计算出所有试验的得分后,根据配置进行得分归一化。
B. 多模态模块
视觉和语义线索(如面部活动和对白模式)可以增强人类对听觉信息的感知,帮助识别当前活跃的说话人。目前仍有许多挑战,例如不可靠的视觉信息、被遮挡或不在画面中的说话人,以及自然对话场景的复杂性。
3D-Speaker-Toolkit主要专注于多模态说话人日志任务。说话人日志是识别给定多人对话中“谁在何时说话”的过程。传统的日志技术包括语音活动检测、语音分段、嵌入提取和聚类。然而,这一过程可能会因复杂的声学环境而受到影响。我们提出了一种模块化的多模态说话人日志系统,该系统为每种观察类型使用独立的模块,并在统一的聚类框架中融合这些信息。
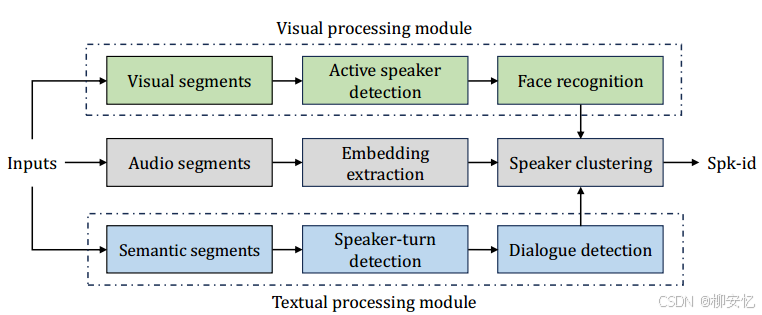
1) 视觉模块
引入了一个视觉日志流程,包括面部跟踪、活跃说话人检测和面部识别。流程如下:
- 面部跟踪模块使用RFB-Net[42]等模型来检测和定位视频内容中的面部,从而为每个出现的面部创建一致的轨迹。只有那些与语音活动检测(VAD)识别的可听语音段相对应的面部轨迹才会被保留以进行进一步处理。
- 活跃说话人检测(如TalkNet[43])将裁剪的面部视频和相应的音频作为输入,并判断跟踪的面部是否在任何给定时刻对应于活跃说话人。
- 面部质量评估模型过滤掉低质量帧。
- 面部识别模型(如CurricularFace[44])为每个面部轨迹提取嵌入。这些嵌入以均匀间隔从每个面部轨迹中提取
- 凝聚层次聚类(AHC)进行聚类。每个面部及其聚类标签可以沿时间轴与相应的音频嵌入对齐,并为纯音频聚类提供指导。
2) 文本模块
文本数据提供了丰富的上下文和语义内容,可以揭示清晰的语言模式并基于语义断点识别说话人转换。文章设计了两项语义任务:对话检测和说话人转换检测。对话检测被定义为一项二分类任务,用于确定文本段是否为对话。说话人转换检测是一项序列标注任务,旨在识别文本中说话人转换的位置。
流程:首先调用对话检测系统以确定文本段是否构成对话。对于那些对话段,应用说话人转换检测模块以精确定位说话人转换发生的位置。
模型基于BERT[46]在AISHELL-4[45]和AliMeeting[8]数据集上进行训练,实验表明,方法在多模态说话人日志任务中的表现优于只使用说话人转换检测模块。
支持替换文本模块,使用基于不同框架的新模块,并以包括大语言模型在内的先进语言模型为骨干。
3) 音频-视觉-文本模块
采用基于约束优化的聚类方法。通过构建视觉和语义约束,多模态信息可以通过使用E2CP方法[47]的联合约束传播过程有效整合。更多细节请参阅[22]。
实验
A. 说话人验证
基于VoxCeleb[29]、3D-Speaker数据集[23]和CN-Celeb[30][31]数据集构建了实验方案,并使用两种指标进行评估:等错误率(EER)和归一化检测代价函数的最小值(MinDCF)。
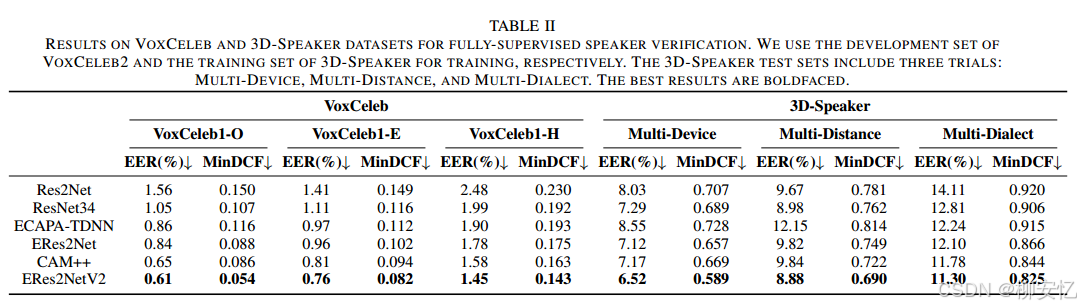
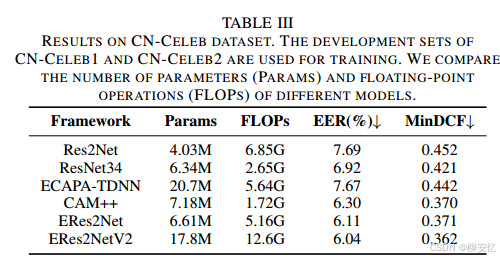
表II和表III列出了全监督模型在VoxCeleb、3D-Speaker数据集和CN-Celeb数据集上的性能。ERes2Net、CAM++和ERes2NetV2的结果是在大间隔微调[48]后使用余弦评分获得的。
在当前支持的六个模型中,ERes2NetV2表现最佳,而CAM++在较低计算复杂度下提供了具有竞争力的结果。在3D-Speaker数据集上的说话人验证性能不如VoxCeleb数据集,主要是由于3D-Speaker数据集包含在不同距离、使用多种设备录制的测试语音,并涵盖多种方言,这对准确的说话人识别提出了更大的挑战。
表III展示了模型在CN-Celeb数据集上的实验结果,并列出了每个模型的参数量(Params)和浮点运算量(FLOPs)。FLOPs是基于3秒长的语音片段测量的。
与表II中观察到的趋势类似,ERes2NetV2优于其他五个模型,而CAM++在较低计算开销的情况下提供了稳健且具有竞争力的性能。

表IV报告了自监督模型(即DINO[34]、RDINO[33]和SDPN[34])的性能。
与最近发布的非对比自监督学习方法(包括[11][12][49])以及结合对比和非对比策略的SSL SOTA C3-DINO[13]进行了比较。在VoxCeleb1-O测试集上,非对比SDPN框架使用与C3-DINO相同的余弦距离评分,实现了1.80%的EER,比C3-DINO(2.50% EER)相对提升了28.0%。
B. 多模态说话人日志
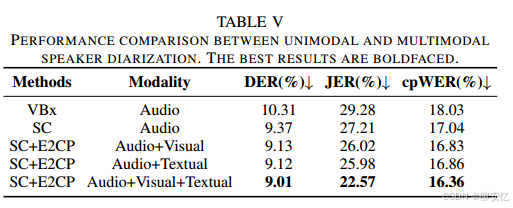
多模态日志方法的实验在一个自收集的视频数据集上进行,该数据集包含2到10名说话人。我们使用VBx[50]和谱聚类(SC)[51]方法建立了纯音频日志的强基线。我们采用E2CP与谱聚类方法结合,利用多模态信息增强说话人日志。使用了常见的说话人日志指标,包括日志错误率(DER)[52]、Jaccard错误率(JER)[53]和拼接最小排列词错误率(cpWER)[54]。
结果表明,与仅基于音频的系统相比,结合视觉或文本信息均实现了显著的性能提升。结合音频、视觉和文本三种模态的数据在所有指标上均取得了更优的结果。
结论(原版翻译)
在本文中,我们介绍了3D-Speaker-Toolkit,这是一个开源工具包,利用多模态说话人信息支持一系列说话人相关任务。该工具包设计精良、轻量化,并在公开数据集和大规模内部数据集上展示了卓越的性能。此外,3D-Speaker-Toolkit提供了兼容CPU和GPU的部署与运行时代码。展望未来,我们的重点将包括有效适配大型预训练模型、压缩模型大小,以及扩展与各种说话人相关任务的集成。
附录(快速安装3D-SPEAKER)
git clone https://github.com/modelscope/3D-Speaker.git && cd 3D-Speaker
conda create -n 3D-Speaker python=3.8
conda activate 3D-Speaker
pip install -r requirements.txt
















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









