







话者分离或者叫说话人日志,主要是解决说话人什么时候说了什么的问题。典型的应用场景:多人会议、坐席销售/客服场景。
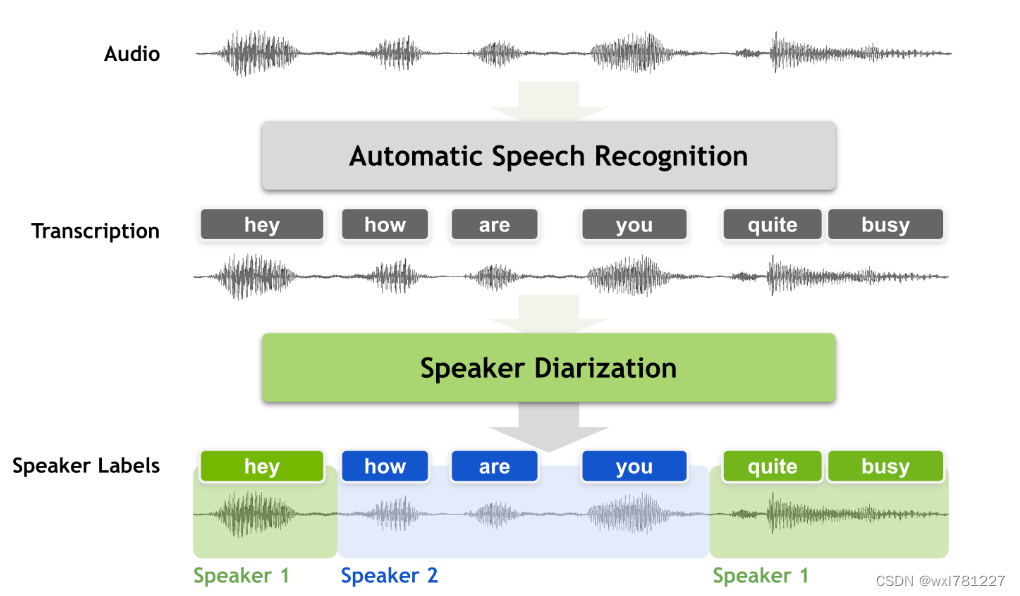
典型的实现过程是基于管道。
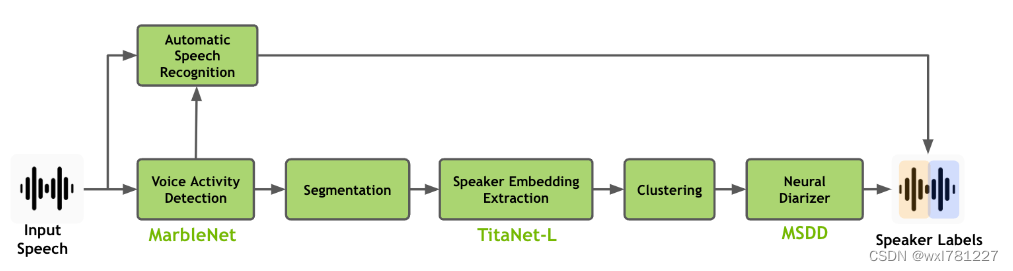
首先基于VAD(声音活动检测)的MarbleNet,分割声音片段,然后基于TitaNet-L提取话者特征,然后通过聚类区分话者,最后通过神经网络分离话者标签。
1、Nemo 环境安装
参考NeMo中文/英文ASR模型微调训练实践_wxl781227的博客-CSDN博客
2、引用依赖
import nemo.collections.asr as nemo_asr
import numpy as np
from IPython.display import Audio, display
import librosa
import os
import wget
import matplotlib.pyplot as plt
import nemo
import glob
import pprint
pp = pprint.PrettyPrinter(indent=4)
3、本地分离样本
ROOT = os.getcwd()
data_dir = os.path.join(ROOT,'data')
print(data_dir)
os.makedirs(data_dir, exist_ok=True)
AUDIO_FILENAME = os.path.join(data_dir,'test.wav')
audio_file_list = glob.glob(f"{data_dir}/test.wav")
print("Input audio file list: \n", audio_file_list)
signal, sample_rate = librosa.load(AUDIO_FILENAME, sr=16000)
print(sample_rate)
display(Audio(signal,rate=sample_rate))
3、使用NeMo中文/英文ASR模型微调训练实践_wxl781227的博客-CSDN博客训练好的模型
my_asr_model = nemo_asr.models.EncDecCTCModel.restore_from("my_stt_zh_quartznet15x5.nemo")
4、定义波形输出函数及波形上色函数
def display_waveform(signal,text='Audio',overlay_color=[]):
fig,ax = plt.subplots(1,1)
fig.set_figwidth(20)
fig.set_figheight(2)
plt.scatter(np.arange(len(signal)),signal,s=1,marker='o',c='k')
if len(overlay_color):
plt.scatter(np.arange(len(signal)),signal,s=1,marker='o',c=overlay_color)
fig.suptitle(text, fontsize=16)
plt.xlabel('time (secs)', fontsize=18)
plt.ylabel('signal strength', fontsize=14);
plt.axis([0,len(signal),-0.5,+0.5])
time_axis,_ = plt.xticks();
plt.xticks(time_axis[:-1],time_axis[:-1]/sample_rate);
COLORS="b g c m y".split()
import soundfile
def get_color(signal,speech_labels,sample_rate=sample_rate):
c=np.array(['k']*len(signal))
for time_stamp in speech_labels:
start,end,label=time_stamp.split()
start,end = int(float(start)*sample_rate),int(float(end)*sample_rate),
corp_wav = signal[start:end]
soundfile.write(f"/NeMo/tutorials/speaker_tasks/data/test_{start}_{end}_{label}.wav", corp_wav, sample_rate)
print(label,my_asr_model.transcribe([f"/NeMo/tutorials/speaker_tasks/data/test_{start}_{end}_{label}.wav"]))
if label == "speech":
code = 'red'
else:
code = COLORS[int(label.split('_')[-1])]
c[start:end]=code
return c
5、输出未分离前的波形
display_waveform(signal)

6、 引入原始的yaml配置文件
from omegaconf import OmegaConf
import shutil
DOMAIN_TYPE = "meeting" # Can be meeting or telephonic based on domain type of the audio file
CONFIG_FILE_NAME = f"diar_infer_{DOMAIN_TYPE}.yaml"
CONFIG_URL = f"https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/speaker_tasks/diarization/conf/inference/{CONFIG_FILE_NAME}"
if not os.path.exists(os.path.join(data_dir,CONFIG_FILE_NAME)):
CONFIG = wget.download(CONFIG_URL, data_dir)
else:
CONFIG = os.path.join(data_dir,CONFIG_FILE_NAME)
cfg = OmegaConf.load(CONFIG)
print(OmegaConf.to_yaml(cfg))
7、创建mainfest文件
# Create a manifest file for input with below format.
# {"audio_filepath": "/path/to/audio_file", "offset": 0, "duration": null, "label": "infer", "text": "-",
# "num_speakers": null, "rttm_filepath": "/path/to/rttm/file", "uem_filepath"="/path/to/uem/filepath"}
import json
meta = {
'audio_filepath': AUDIO_FILENAME,
'offset': 0,
'duration':None,
'label': 'infer',
'text': '-',
'num_speakers': None,
'rttm_filepath': None,
'uem_filepath' : None
}
with open(os.path.join(data_dir,'input_manifest.json'),'w') as fp:
json.dump(meta,fp)
fp.write('\n')
cfg.diarizer.manifest_filepath = os.path.join(data_dir,'input_manifest.json')
!cat {cfg.diarizer.manifest_filepath}
8、设置使用到的管道模型
pretrained_speaker_model='titanet-l.nemo'
cfg.diarizer.manifest_filepath = cfg.diarizer.manifest_filepath
cfg.diarizer.out_dir = data_dir #Directory to store intermediate files and prediction outputs
cfg.diarizer.speaker_embeddings.model_path = pretrained_speaker_model
cfg.diarizer.clustering.parameters.oracle_num_speakers=None
# Using Neural VAD and Conformer ASR
cfg.diarizer.vad.model_path = 'vad_multilingual_marblenet'
cfg.diarizer.asr.model_path = 'my_stt_zh_quartznet15x5.nemo'
cfg.diarizer.oracle_vad = False # ----> Not using oracle VAD
cfg.diarizer.asr.parameters.asr_based_vad = False
cfg.batch_size = 2
9、运行ASR获取时间戳标记
from nemo.collections.asr.parts.utils.decoder_timestamps_utils import ASRDecoderTimeStamps
asr_decoder_ts = ASRDecoderTimeStamps(cfg.diarizer)
asr_model = asr_decoder_ts.set_asr_model()
word_hyp, word_ts_hyp = asr_decoder_ts.run_ASR(asr_model)
print("Decoded word output dictionary: \n", word_hyp['test'])
print("Word-level timestamps dictionary: \n", word_ts_hyp['test'])
10、创建ASR离线分离对象
from nemo.collections.asr.parts.utils.diarization_utils import OfflineDiarWithASR
asr_diar_offline = OfflineDiarWithASR(cfg.diarizer)
asr_diar_offline.word_ts_anchor_offset = asr_decoder_ts.word_ts_anchor_offset
11、执行离线分离
diar_hyp, diar_score = asr_diar_offline.run_diarization(cfg, word_ts_hyp)
print("Diarization hypothesis output: \n", diar_hyp['test'])
12、显示离线分离的结果
def read_file(path_to_file):
with open(path_to_file) as f:
contents = f.read().splitlines()
return contents
predicted_speaker_label_rttm_path = f"{data_dir}/pred_rttms/test.rttm"
pred_rttm = read_file(predicted_speaker_label_rttm_path)
pp.pprint(pred_rttm)
from nemo.collections.asr.parts.utils.speaker_utils import rttm_to_labels
pred_labels = rttm_to_labels(predicted_speaker_label_rttm_path)
color = get_color(signal, pred_labels)
display_waveform(signal,'Audio with Speaker Labels', color)
display(Audio(signal,rate=sample_rate))
[ 'SPEAKER test2 1 0.000 4.125 <NA> <NA> speaker_1 <NA> <NA>',
'SPEAKER test2 1 4.125 4.565 <NA> <NA> speaker_0 <NA> <NA>']
Transcribing: 0%| | 0/1 [00:00<?, ?it/s]
speaker_1 ['诶前天跟我说的昨天跟我说十二期利率是多大']
Transcribing: 0%| | 0/1 [00:00<?, ?it/s]
speaker_0 ['工号要九零八二六十二期话零点八一万的话分十二万期利息八十嘛']



















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











