







目录
项目信息
3D-Speaker是阿里通义多模态说话人开源项目,详细介绍可见我之前博客:【说话人日志】《3D-Speaker-Toolkit: An Open-Source Toolkit forMultimodal Speaker》阿里通义多模态说话人开源项目3D-Speaker_3d-speaker 导出onnx-CSDN博客
复现环境:腾讯云高性能空间
配置情况:
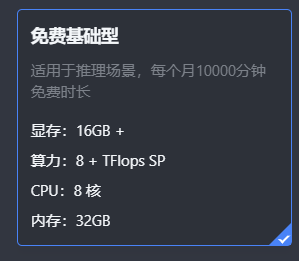
步骤
1.克隆及项目搭建
首先在腾讯云中新建一个Pytorch模板。
路径:空间模板->AI模版->Pytorch2.0
一般来说,在项目界面的readme都会有快速项目搭建的指令,如果是需要复现看看性能,可以直接搭建,如果是需要作为baseline深入研究,还是建议先完整看看项目代码。
本项目的快速安装部分:
git clone https://github.com/modelscope/3D-Speaker.git && cd 3D-Speaker
conda create -n 3D-Speaker python=3.8
conda activate 3D-Speaker
pip install -r requirements.txt因为环境里已经有了pytorch,只需要输入第一行即可。
为了避免网络波动,最后一行的pip指令加入-i https://pypi.tuna.tsinghua.edu.cn/simple。
2.项目分析
readme界面说明,运行实验有两种模式,一种为项目中运行,还有一种为 Modelscope预训练模型进行推理。本次只需跑通推理验证性能,所以选择魔塔框架的预训练模型推理。
# Install modelscope
pip install modelscope
# ERes2Net trained on 200k labeled speakers
model_id=iic/speech_eres2net_sv_zh-cn_16k-common
# ERes2NetV2 trained on 200k labeled speakers
model_id=iic/speech_eres2netv2_sv_zh-cn_16k-common
# CAM++ trained on 200k labeled speakers
model_id=iic/speech_campplus_sv_zh-cn_16k-common
# Run CAM++ or ERes2Net inference
python speakerlab/bin/infer_sv.py --model_id $model_id
# Run batch inference
python speakerlab/bin/infer_sv_batch.py --model_id $model_id --wavs $wav_list
# SDPN trained on VoxCeleb
model_id=iic/speech_sdpn_ecapa_tdnn_sv_en_voxceleb_16k
# Run SDPN inference
python speakerlab/bin/infer_sv_ssl.py --model_id $model_id
# Run diarization inference
python speakerlab/bin/infer_diarization.py --wav [wav_list OR wav_path] --out_dir $out_dir
# Enable overlap detection
python speakerlab/bin/infer_diarization.py --wav [wav_list OR wav_path] --out_dir $out_dir --include_overlap --hf_access_token $hf_access_token提示先按照魔塔框架:pip install modelscope
然后要看懂这个在讲什么,我们能得到什么信息:
- 有多种backbone可选择:ERes2Net、ERes2NetV2等等,还有其对应的model_id.
- 主要跑推理的文件路径为speakerlab/bin/infer_XXX.py,根据任务情况选择。
- 需要填入的参数一般为model_id、需要推理的文件地址、输出路径。
我们需要跑的是说话人分离,对应指令是:
# Run diarization inference
python speakerlab/bin/infer_diarization.py --wav [wav_list OR wav_path] --out_dir $out_dir我个人不推荐这种跑法,因为在终端填入各种路径很麻烦,我们直接打开对应的文件speakerlab/bin/infer_diarization.py 赋值,然后运行文件,这样也方便排查错误。
3.跑通代码,得到结果
打开文件找到parser部分,一般都是通过这种方式赋值的。
parser = argparse.ArgumentParser(description='Speaker diarization inference.')
parser.add_argument('--wav', type=str, required=True, help='Input wavs')
parser.add_argument('--out_dir', type=str, required=True, help='Out results dir')
parser.add_argument('--out_type', choices=['rttm', 'json'], default='rttm', type=str, help='Results format, rttm or json')
parser.add_argument('--include_overlap', action='store_true', help='Include overlapping region')
parser.add_argument('--hf_access_token', type=str, help='hf_access_token for pyannote/segmentation-3.0 model. It\'s required if --include_overlap is specified')
parser.add_argument('--diable_progress_bar', action='store_true', help='Close the progress bar')
parser.add_argument('--nprocs', default=None, type=int, help='Num of procs')
parser.add_argument('--speaker_num', default=None, type=int, help='Oracle num of speaker')上传文件,填入自己的文件路径,记得去除required=True。
parser = argparse.ArgumentParser(description='Speaker diarization inference.')
parser.add_argument('--wav', type=str,default='./data/in/', help='Input wavs')
parser.add_argument('--out_dir', type=str, default='./data/out/',help='Out results dir')
parser.add_argument('--out_type', choices=['rttm', 'json'], default='rttm', type=str, help='Results format, rttm or json')
parser.add_argument('--include_overlap', action='store_true', help='Include overlapping region')
parser.add_argument('--hf_access_token', type=str, help='hf_access_token for pyannote/segmentation-3.0 model. It\'s required if --include_overlap is specified')
parser.add_argument('--diable_progress_bar', action='store_true', help='Close the progress bar')
parser.add_argument('--nprocs', default=None, type=int, help='Num of procs')
parser.add_argument('--speaker_num', default=None, type=int, help='Oracle num of speaker')(base) root@VM-12-69-ubuntu:/workspace# cd /workspace/examples/3D-Speaker/speakerlab/bin
(base) root@VM-12-69-ubuntu:/workspace/examples/3D-Speaker/speakerlab/bin# python infer_diarization.py中间会提示缺少很多很多模块,不停重新跑、再安装上即可。(requirements.txt里面都没提到,这个项目团队得背锅)
其中较严重的是缺少pyannote,安装教程如下:pyannote.audio 安装和配置指南-CSDN博客
成功运行:
(base) root@VM-12-69-ubuntu:/workspace/examples/3D-Speaker/speakerlab/bin# python infer_diarization.py
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_campplus_sv_zh_en_16k-common_advanced
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
[INFO]: Model downloaded successfully.
[INFO]: Detected 1 GPUs.
[INFO]: Set 1 processes to extract embeddings.
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_campplus_sv_zh_en_16k-common_advanced
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
Rank 0 processing: 100%|█████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.24it/s]
(base) root@VM-12-69-ubuntu:/workspace/examples/3D-Speaker/speakerlab/bin# python infer_diarization.py
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_campplus_sv_zh_en_16k-common_advanced
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
[INFO]: Model downloaded successfully.
[INFO]: Detected 1 GPUs.
[INFO]: Set 1 processes to extract embeddings.
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_campplus_sv_zh_en_16k-common_advanced
Downloading Model from https://www.modelscope.cn to directory: /root/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
Rank 0 processing: 100%|█████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.13it/s获得rttm格式的结果:
SPEAKER twospeaker 0 0.000 26.230 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 26.630 1.125 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 27.755 3.315 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 31.350 5.630 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 37.260 13.125 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 50.385 2.250 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 52.635 1.575 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 54.510 1.875 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 56.385 4.115 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 62.040 2.130 <NA> <NA> 0 <NA> <NA>
发现只有说话人分离的结果emmm.
而且对比我的音频,说话人区分不准确。
再加上重叠检测试试,配置一下我的hf。下载模型遇到网络波动,参考:
得到更精细的重叠检查结果。
SPEAKER twospeaker 0 0.031 26.021 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 26.052 0.034 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 26.086 0.169 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 26.660 0.202 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 26.862 0.017 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 26.879 0.152 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 27.031 0.472 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 27.503 0.287 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 27.790 3.308 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 31.385 5.619 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 37.291 13.567 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 50.858 3.342 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 53.035 0.675 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 54.200 0.135 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 54.537 2.363 <NA> <NA> 1 <NA> <NA>
SPEAKER twospeaker 0 56.900 3.628 <NA> <NA> 0 <NA> <NA>
SPEAKER twospeaker 0 62.063 2.160 <NA> <NA> 0 <NA> <NA>
为了提示难度,又选择了一个人声较小的音频,得到结果:
SPEAKER one_hard 0 0.031 26.966 <NA> <NA> 2 <NA> <NA>
这个识别结果还行。

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









