







这道题是leetcode编号131,在剑指offer中也有本题。
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
示例 1:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
示例 2:
输入:s = "a"
输出:[["a"]]
提示:
1 <= s.length <= 16
s 仅由小写英文字母组成
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/palindrome-partitioning
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解法思路:
这道题的题干相较于leetcode中的某些题可以称得上是十分清晰的了。依照题意以及示例,我们需要找到所有的,可以将字符串分割为一个个回文子串的组合的方式。
最简单的,也是最复杂暴力的方法——我们可以优先找出其子串的所有可能的划分方式,然后将这些字串一个个进行回文判断——不过由于题干及示例显示的要求,我们可能要对答案多进行一步处理——关于怎么优雅的将vector<string>整合为vector<vector<string>>。
不过,在此之前,最重要的还是理清我们的解题思路。
相信有心研究这一道题的朋友都对于二叉树的搜索与遍历一定有过一定了解了。在这里,我们要提到一个与之相差不大的算法思想——回溯算法。
所谓回溯算法:
回溯算法本质上类似枚举搜索尝试的过程,在搜索尝试的过程中寻找问题的解。当探索到某一步时,发现原先选择的路径无法达到目标时,就退回到上一步重新进行选择。
这种走不通就退回重新选择路径的算法就叫做回溯法。
而当前路径不满足条件就放弃的思想可以看做一种简单的剪枝算法——个人感觉。
回溯算法就像我们在二叉树相关知识中所学的深度优先搜索——从一条路往前走,能走下去则走下去,不能则退回,换一条路再试。
而在我们这道题中,我们可以将字符串的不同的分割方法看做一种另类的前缀树,每一层向下的结点,都是在当前分割的基础上通过不同方法分割出的字符串。
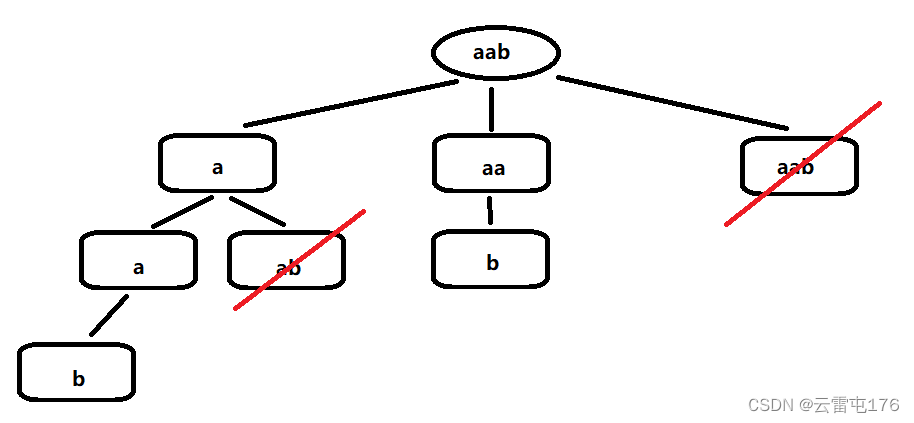
和其他大佬关于此题的题解一样,我也想用 aab 这个示例来进行图示,不得不说,这个示例出的是真的好,简洁明了。
当然,缺点也很明显,比如被我们划去的子串 ab 以及 aab 都是无法再继续往下分割的。但我相信这对于诸君应该不成问题。
回溯算法可以说是一种非常笨的方法,就是穷举加上剪枝算法。
所以它的代码也并不是很难:
1.分割——从字符串首部分割出需要判断的子串
2.判断——判断该子串是否回文串,决定是否剪枝
3.递归——已确定该路径可走,递归进入下一层
class Solution {
private:
vector<vector<string>> ret;
vector<string> pa;
public:
void backtracking(const string& s, int index) {
int len = s.size();
//如果该路径已经完全分割,将当前pa拷贝到ret尾部,返回上一层
if (index >= len) {
ret.push_back(pa);
return;
}
for (int i = index; i < len; ++i) {
//判断,剪枝
if (judge(s, index, i)) {
string str = s.substr(index, i - index + 1);
pa.push_back(str);
backtracking(s, i + 1);
//每层递归返回后都将清除该层写入的元素
//因为我们的pa是要重复使用的
pa.pop_back();
}
}
}
//判断回文串
bool judge(const string& s, int start, int end) {
for (int i = start, k = end; i < k; ++i, --k) {
if(s[i] != s[k]) {
return false;
}
}
return true;
}
vector<vector<string>> partition(string s) {
ret.clear();
pa.clear();
backtracking(s, 0);
return ret;
}
};单纯的回溯算法有着一个非常致命的问题——在字符串比较复杂的时候,有些路它会重复地走——这是穷举法很难回避的缺陷。
这时很容易想到地解决方案就是——动态规划。
我们可以在分割前将我们回溯过程中所有的可能的分割都进行一次判断,并将结果维护在一个数组之中——当我们回溯过程中遇到某种情况分割的字符串,只需要根据数组中的值来判断是否回文便可,以空间换时间,这是动态规划的典型特征。
此处我们引入的二维数组 judge 的下标 i 与 j 代表着字符串第 i 位到第 j 位分割出的子串是否为回文子串。
但是下方代码中还有着一个严重缺陷,看看各位朋友是否可以看出。
class Solution {
public:
vector<vector<string>> ret;
vector<string> pa;
void backtracking(const string& s, int index, vector<vector<bool>> judge) {
int len = s.size();
if (index >= len) {
ret.push_back(pa);
return;
}
for (int i = index; i < len; ++i) {
if (judge[index][i]) {
string str = s.substr(index, i - index + 1);
pa.push_back(str);
backtracking(s, i + 1, judge);
pa.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
int n = s.size();
vector<vector<bool>> judge(n, vector<bool> (n, true));
for (int i = n - 1; i >= 0; --i) {
for (int k = i + 1; k < n; ++k) {
judge[i][k] = (s[i] == s[k]) && judge[i + 1][k - 1];
}
}
ret.clear();
pa.clear();
backtracking(s, 0, judge);
return ret;
}
};我这里动态规划的引入稍有些问题,因为我们是在不停地递归,函数不断压栈,每一次压栈都会将动态规划的数组拷贝一遍——很明显本题的数据是会比较大的,所以对应的数组也会很大,每次压栈所耗费的时间空间都是不可想象的。
所以想要使用回溯+动态规划的代码的朋友,可以自己修改这里的代码,只需要将 judge 改成成员变量,然后相应的做出一些小调整即可。也可以直接去leetcode官网本题题解处找到使用此方法的题解使用。
















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











