






简单线性回归
本文主要是构建简单线性回归,是一个自变量与因变量之间的关系,构建发动机排量与二氧化碳排放量简单线性模型。并解释如何进行模型评估。以下数据来源任选其一
数据集来源
数据集来源
一.数据描述
MODELYEAR:年份例如 2014
MAKE:制造 例如讴歌
MODEL:型号 例如 ILX
VEHICLECLASS:车辆类别,例如 SUV
ENGINESIZE:发动机排量例如 4.7
CYLINDERS:气缸,例如 6
TRANSMISSION:传输例如 A6
FUELTYPE:燃料类型,例如 z
FUELCONSUMPTION_CITY:城市油耗(升/100 公里)例如 9.9
FUELCONSUMPTION_HWY:高速公路燃油消耗量(升/100 公里)例如 8.9
FUELCONSUMPTION_COMB:油耗组合 (L/100 km)例如 9.2
FUELCONSUMPTION_COMB_MPG:油耗组合 (每加仑)
CO2EMISSIONS:CO2 排放量(克/公里)例如 182 --> 低 --> 0
二.读取数据
data = pd.read_csv("FuelConsumption.csv")
data.head()
print(data.shape)
data.info()
print("重复值个数", data.duplicated().sum())
print(data.describe())
df = data[['ENGINESIZE', 'CYLINDERS', 'FUELCONSUMPTION_COMB', 'CO2EMISSIONS']]
三.绘制直方图散点图
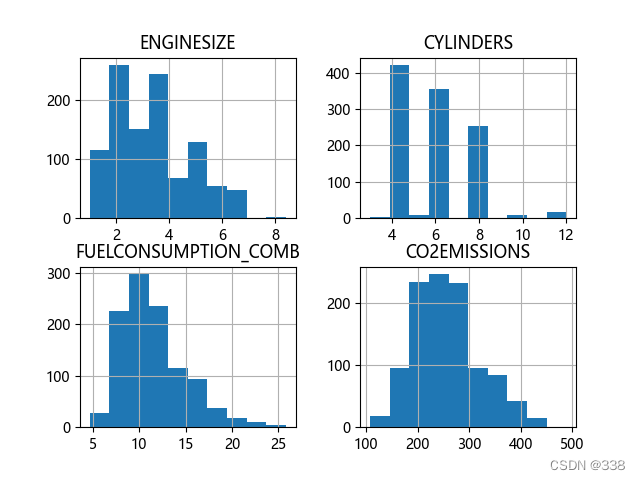
‘ENGINESIZE’, ‘CYLINDERS’, ‘FUELCONSUMPTION_COMB’,三者分别排放量作直方图再绘制三者各自与排放量的散点图
df.hist()
plt.show()
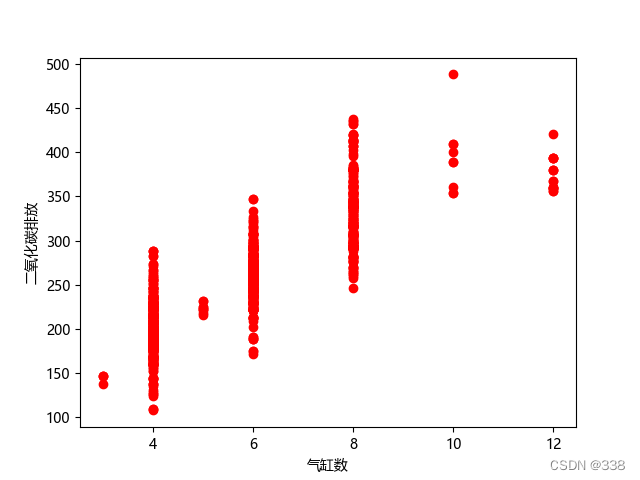
# 气缸数与二氧化碳排放
plt.scatter(df.CYLINDERS, df.CO2EMISSIONS, color='red')
plt.xlabel('气缸数')
plt.ylabel('二氧化碳排放')
plt.show()
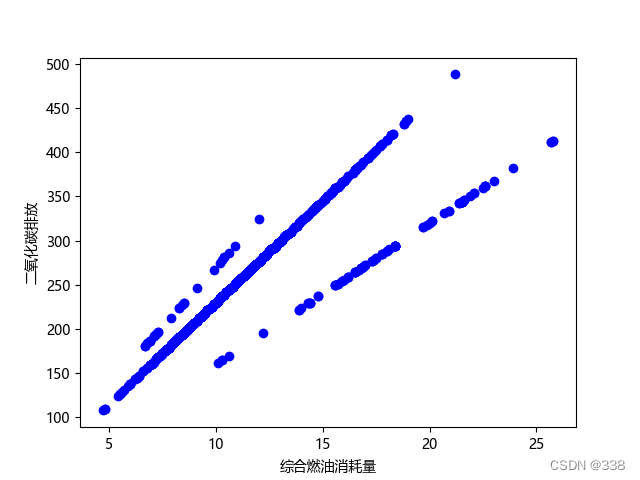
# 综合燃油消耗量与二氧化碳排放
plt.scatter(df.FUELCONSUMPTION_COMB, df.CO2EMISSIONS, color='blue')
plt.xlabel("综合燃油消耗量")
plt.ylabel('二氧化碳排放')
plt.show()
# 发动机排量与而二氧化碳排放
plt.scatter(df.ENGINESIZE, df.CO2EMISSIONS, color='blue')
plt.xlabel("发动机排量")
plt.ylabel('二氧化碳排放')
plt.show()

四.划分训练集测试集
train_size = 0.8
train_data_size = int(train_size * len(df))
# 随机选择80%数据作为训练集
train_data = df[:train_data_size]
五.构建模型
# 构造一元线性回归模型,并用训练集拟合模型
regressor = LinearRegression()
x_train = train_data['ENGINESIZE'].values.reshape(-1, 1)
y_train = train_data['CO2EMISSIONS'].values.reshape(-1, 1)
regressor.fit(x_train, y_train)
print('系数:',regressor.coef_)
print('截距为',regressor.intercept_)
六.模型评估

**MAE(Mean Absolute Error)**是指平均绝对误差,是回归模型中用来评估模型预测结果的误差大小的指标之一。
MAE的计算方法是将测试数据的预测值与真实值之差取绝对值后累加,然后再除以测试数据总数,得到预测误差的平均值。MAE越小,则说明模型预测结果的精度越高。
**MSE(Mean Squared Error)**是指平均平方误差,是回归模型中用来评估模型预测结果的误差大小的指标之一。
MSE的计算方法是将测试数据的预测值与真实值之差平方后累加,然后再除以测试数据总数,得到预测误差的平均平方值。MSE越小,则说明模型预测结果的精度越高。
**RMSE(Root Mean Square Error)**是指均方根误差,是回归模型中用来评估模型预测结果的误差大小的指标之一。
RMSE的意义与MSE类似,都是用来评估模型的预测精度,其值越小说明模型的预测精度越高。RMSE相对于MSE有更好的可解释性,因为它的单位是与原始数据一致的,例如对于CO2排放量这样的物理量,RMSE的值是以g/km为单位的,更容易帮助我们理解模型预测结果的误差大小。
**RAE(Relative Absolute Error)**是指相对绝对误差,也是回归模型中用来评估模型预测结果的误差大小的指标之一。
RAE主要是用来比较同一自变量模型在不同数据集上的预测结果,或比较不同自变量模型在同一数据集上的预测结果。RAE是用预测误差的平均绝对值除以真实值的平均绝对值得到的,它的值一般是小于1的,越小说明模型的预测精度越高。
**RSE(Relative Squared Error)**是指相对平方误差,也是回归模型中用来评估模型预测结果的误差大小的指标之一。
RSE主要是用来比较同一自变量模型在不同数据集上的预测结果,或比较不同自变量模型在同一数据集上的预测结果。RSE是用预测误差的平方除以真实值的平均平方值得到的,它的值一般是小于1的,越小说明模型的预测精度越高。
在模型的训练中
# 测试模型,用测试集计算R平方值
test_data = df[train_data_size:]
x_test = test_data['ENGINESIZE'].values.reshape(-1, 1)
y_test = test_data['CO2EMISSIONS'].values.reshape(-1, 1)
r_squared = regressor.score(x_test, y_test)
print('R平方值:', r_squared)
在模型训练完之后
test_x = np.asanyarray(test_data[['ENGINESIZE']])
test_y = np.asanyarray(test_data[['CO2EMISSIONS']])
test_y_ = regressor.predict(test_x)
print("Mean absolute error: %.2f" % np.mean(np.absolute(test_y_ - test_y)))
print("Residual sum of squares (MSE): %.2f" % np.mean((test_y_ - test_y) ** 2))
print("R2-score: %.2f" % r2_score(test_y , test_y_) )
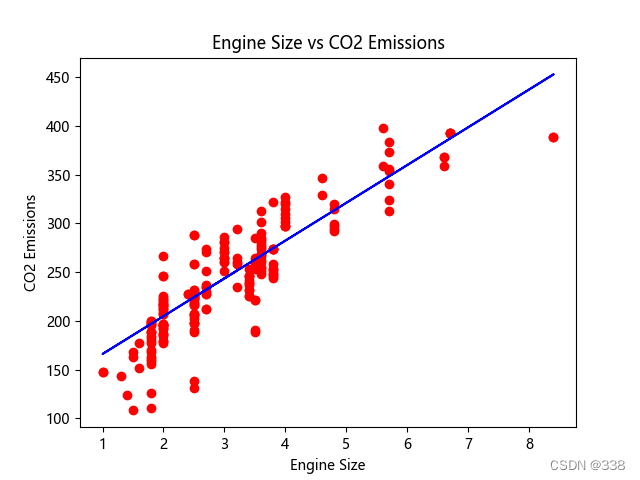
七.模型构建完成
plt.scatter(x_test, y_test, color='red')
plt.plot(x_test, regressor.predict(x_test), color='blue')
plt.title('Engine Size vs CO2 Emissions')
plt.xlabel('Engine Size')
plt.ylabel('CO2 Emissions')
plt.show()















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









