







此文章,仅代表我个人的理解
目录
1.概述:
-
概念:数据库范式是数据库的设计规范,遵守不同的规范要求,可以设计出合理的关系型数据库;范式越高,数据冗余越小
-
作用:使用数据结构更加合理,使用冗余(重复数据)尽量小,便于增删改
2.依赖:
-
函数依赖:通过唯一的X一定能查找到Y,即为"Y依赖于X"(X —> Y),X没有重复值,Y有重复值
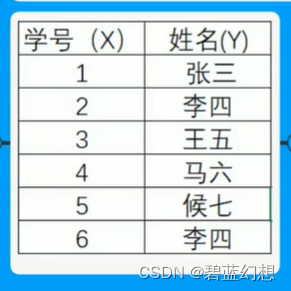
-
完全函数依赖:在一张表中,若X —> Y,且X的任何一个真子集X?——>Y,那么称之为Y完全函数依赖X(一个字段的真子集唯一,那么这个字段就是唯一的)
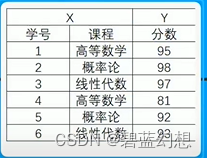
-
部分函数依赖:在一张表中,若X —> Y,且不是X的所有真子集X?——>Y,那么称之为Y部分函数依赖X
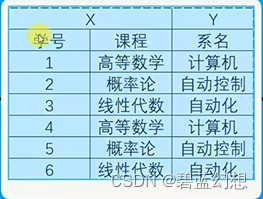
-
传递函数依赖:在一张表中,若Y —> Z,且X—> Y,X不是Y的真子集,Y!——>X,那么称之为Z传递函数依赖X
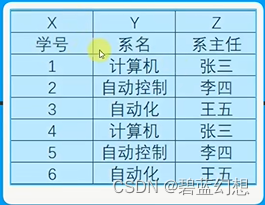
3.码:
-
概念:通过这个码,可以找到这一行所有的字段
-
超码:通过这个码+其他字段也可以确定这一行的所有字段
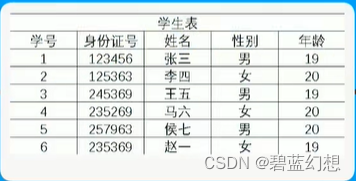
-
候选码:候选码就是超码,最小的超码,候选码的任何一个真子集不能标识这一行
-
主码:用来在同一实体集中区分不同实体的候选码,极少发生变化的属性
-
主属性:非空且唯一
-
非主属性:不包含在候选码中的属性
4.范式:
-
第一范式:表字段不可再分(原子性)
-
第二范式: 在第一方式的基础上,非码属性必须完全依赖于主属性(目的:消除部分依赖)
-
第三范式:在第一,二范式的基础上,任何非主属性一依赖于其他非主属性(目的:消除传递依赖)
-
巴斯-科德范式:在第一,二,三范式的基础上,任何非主属性不能对主键子集的依赖(目的:消除对主码子集的依赖)















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









