






注意:本次案例使用的是pycharm编辑器
1、导入相关的包
# 导入相关的包
import pandas as pd
import numpy as np
# 导入预处理的库
import sklearn.preprocessing as pre
# 训练集、测试集划分
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegression
# 模型评估
from sklearn import metrics
2、读取数据
# 1、读取数据
data = pd.read_csv(open(r"风险识别.csv", encoding="gbk"))
首先,我们读取下数据,因为我们的数据名有中文,所以加上 open( )
此时如果打印查看数据 data ,在pycharm里会省略不少字段(显示不全)
所以加上以下字段才会显示全:
# 显示全部列
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.expand_frame_repr', False) # 设置不折叠数据
# 下面配置显示行
# pd.set_option('display.max_rows', None) # 显示完整的行
# pd.set_option('display.max_colwidth', 100)
上面我注释了一些,因为如果数据太多,也就是行太多那就要加载好久来显示,除非你加上data.head()
这段完整代码:
# 1、读取数据
data = pd.read_csv(open(r"风险识别.csv", encoding="gbk"))
pd.set_option('display.max_columns', None) # 显示完整的列
pd.set_option('display.expand_frame_repr', False) # 设置不折叠数据
# pd.set_option('display.max_rows', None) # 显示完整的行
# pd.set_option('display.max_colwidth', 100)
print(data.head())

异常值识别与处理:
如果发现异常值较多,也可能是分类的影响,因此不做处理
3、相关分析
corr = data.corr()
print(corr)
data.corr()表示了data中的两个变量之间的相关性,取值范围为[-1,1],取值接近-1,表示反相关,类似反比例函数,取值接近1,表正相关
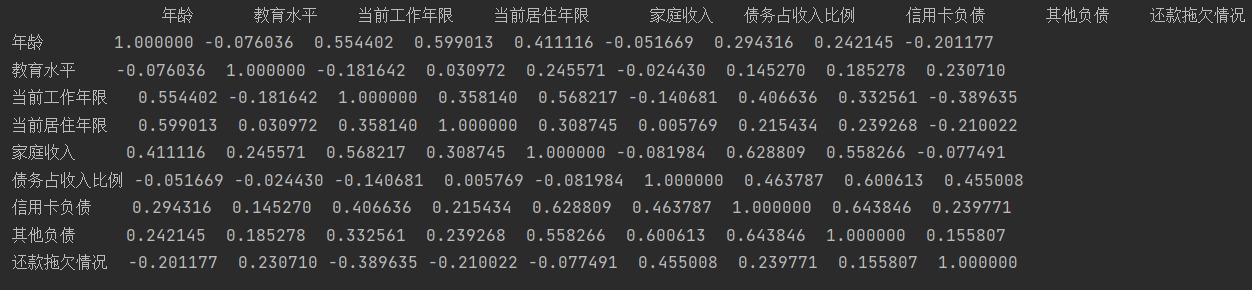
由相关举证可以看出变量之间虽有相关,但也不是很强,因此可以进行逻辑回归。如果相关性强则进行特征筛选
4、分出目标列
# 3、分出目标列
X = data.drop("还款拖欠情况", axis=1)
Y = data["还款拖欠情况"]
print(X)
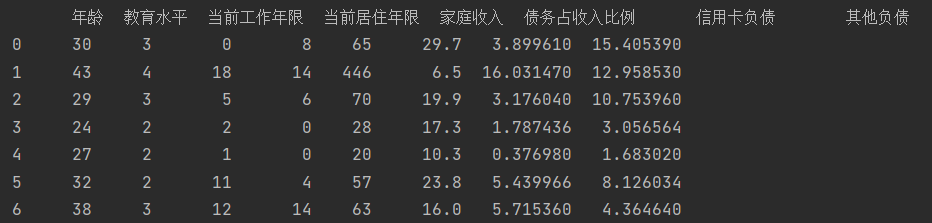
5、标准化
前面我们导入了标准化的包
# 4.标准化
std = pre.StandardScaler()
# 调用fit_transform提取并转换数据; 一步导出结果(训练和导出一步完成)
X_std = std.fit_transform(X)
print(X_std)
print(X_std.shape)
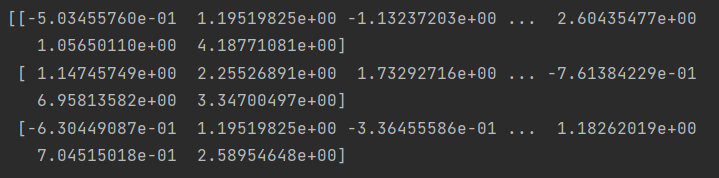
6、划分训练集和测试集
# 5、划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X_std, Y, test_size=0.3, random_state=0)
7、训练模型
# 6、训练模型之 逻辑回归
lr = LogisticRegression(solver="sag") # 实例化
lr.fit(X_train, Y_train) # 训练数据
8、预测模型
# 7、预测模型
Y_pred = lr.predict(X_test)
9、模型评估
最前面我们导入了模型评估的包,这里就不演示了
# 8、模型评估
matrix = metrics.confusion_matrix(Y_test, Y_pred) # 混淆矩阵
# 8、模型评估
matrix = metrics.confusion_matrix(Y_test, Y_pred) # 混淆矩阵
print(matrix)
print("准确率:{:.2%}".format(metrics.accuracy_score(Y_test, Y_pred)))
# 即正确预测为正类的占全部预测为正类的的比例
print("精确率:{:.2%}".format(metrics.precision_score(Y_test, Y_pred)))
# 正确预测为正类的占全部实际为正类的的比例
print("召回率:{:.2%}".format(metrics.recall_score(Y_test, Y_pred)))
print("F1值::{:.2%}".format(metrics.f1_score(Y_test, Y_pred, average='binary')))















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









