






HTML文档结点的查找工具很多,其中 BeautifulSoup 是功能强大且十分流行的查找工具之一。
1. BeautifulSoup 的安装
安装:
pip install bs4
导包:
from bs4 import BeautifulSoup
2. BeautifulSoup 装载HTML文档
如果 doc 是一个 HTML 文档,通过
from bs4 import BeautifulSoup
soup = BeautifulSoup(doc,"lxml")
就可以创建一个名称为 soup 的 BeautifulSoup 对象,
-
doc 是一个 HTML 文档字符串,
-
"lxml"是一个参数,表示创建的是一个通过"lxml"解析器解析的文档。BeautifulSoup有多种解析器,其中"lxml"是最常用的一个
通过调用:
soup. prettify()
可以把 soup 对象的文档树变成一个字符串。
BeautifulSoup库解析器
| 解析器 | 使用方法 | 条件 |
| bs4的HTML解析器 | BeautifulSoup(doc,'html.parser') | pip install bs4 |
| lxml的HTML解析器 | BeautifulSoup(doc,'lxml') | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(doc,'xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(doc,'html5lib') | pip install html5lib |
BeautifulSoup 装载文档的功能十分强大,它在装载的过程中如果返现HTML文档中元素有缺失的情况,会尽可能地对文档进行修复,使得最后的文档树是一颗完整的树。这一点十分重要,因为大多数网页都或多或少地有些元素是缺失的,BeautifulSoup 都能正确地装载它们。
# BeautifulSoup装载有缺失的HTML文档
frombs4importBeautifulSoup
doc='''
<title>有缺失元素的HTML文档</title>
<div>
<A href='one.html'>one</a>
<p>
<a href='two.html'>two</a>
</DIV>
'''
soup=BeautifulSoup(doc, "html.parser")
s=soup.prettify()
print(s)
程序结果如下:
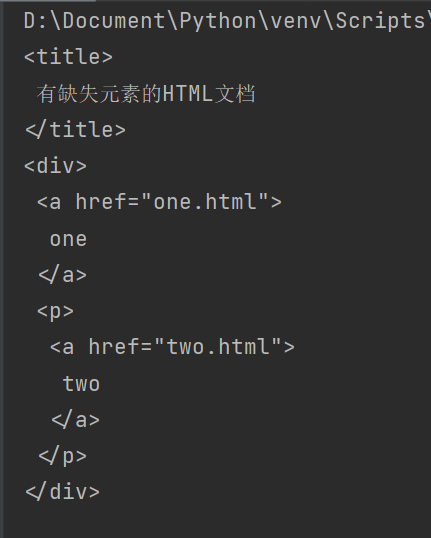
值得注意的是,BeautifulSoup 虽然功能强大能修正一些缺失的HTML元素,但是它还没只能到完全修复所有HTML文档错误的程度。
下一篇文章:2.3 BeautifulSoup 查找文档元素















 1720
1720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









