






嵌入式系统概述
一. 计算机的组成
什么是计算机?
计算机是由软件和硬件组成。可以浅显的理解为一个可以跑程序的电子元器件。
计算机可以分成两类:
(1)通用计算机
硬件和软件都是通用的,典型的代表:个人PC,服务器。(通用计算机C的软件A或者硬件B,都可以给通用计算机D用(通用计算机))
比如从联想的电脑上拆硬件也可以装在惠普的电脑上使用......
(2)专用计算机
搭载着嵌入式系统的计算机称之为专用计算机
典型代表:手机(除了PC外所有智能产品)
那么什么是嵌入式系统?
1.嵌入式系统
以应用为中心,以现代的计算机技术为基础,能够根据用户的需求(功能,可靠性,成本,功耗和体积)灵活裁剪软硬件的专用计算机系统
以应用为中心:强调嵌入式系统的目标是满足用户的特定需求。(专门的功能)
灵活裁剪软硬件:嵌入式系统之间存在很大的差异性,嵌入式系统应用的场景很多,所以现实上很难有一套方案可以满足所有的系统要求。
根据需求的不同,灵活裁剪软硬件是嵌入式系统的必须要做的。
嵌入式系统也分成两部分:
(1)硬件:分成两部分
1.芯片:CPU+总线+控制电路
2.外围电路:服务于芯片工作的电路。
比如最小系统的组成:
芯片:运行程序
复位电路:从断电到上电的过程,让芯片重新开始工作
晶振电路:提供时钟,时钟是设备的"心脏",没有时钟,那么设备是无法工作,后续在使用某些设备的时候,都必须开启时钟
供电电路:提供元器件工作所需要的能源
(2)软件:运行在硬件环境上
1.Boot loader:引导加载程序,引导加载程序一般是系统上电之后运行的第一段代码,用于引导OS运行。
为什么需要引导?
OS的运行必须要当硬件环境配置好之后,才能运行,但是我们一上电的时候,硬件环境是没有准备好的。
比如:GEC-M4的晶振是8M,但是OS运行的频率是168M.
这时候,Boot loader就利用CPU以及内部很小ROM(Read Only Memory)可以在低频下工作对硬件初始化
简单的说,Boot loader由两部分:引导和加载,前者用来初始化硬件运行起来(类似PC的BIOS),后者用来引导OS加载到内存
中去,跳转过去运行。
2. OS:操作系统
操作系统是为了让后续的开发者进行程序的设计的时候,可以不需要过多的去关注硬件但是可以利用硬件去实现想要的功能,而
设计的一款"程序"
当下的操作系统主要分成实时操作系统和分时操作系统
实时操作系统:以任务的优先级为主进行系统调度,优先级低的程序必须等到优先级高的程序运行结束或者主动让出CPU才能
执行。当一个低优先级的程序在运行的时候,来了一个高优先级程序就会打断低优先级的程序去执行(抢占)
比如:UCOS/FreeRTOS.....
分时操作系统:以时间片轮转的形式进行任务调度。
给每个程序"一段时间"去执行,时间到了,就必须让出CPU给下一次程序执行。以此反复。
比如:windows/linux.....
当然操作系统并没有绝对,分时操作系统里面也有实时,实时操作系统里面也会有分时。
3.应用程序(包括文件系统)
我们之前写的代码也是属于应用程序
2.计算机的结构
计算机系统,主要分成两个流派:
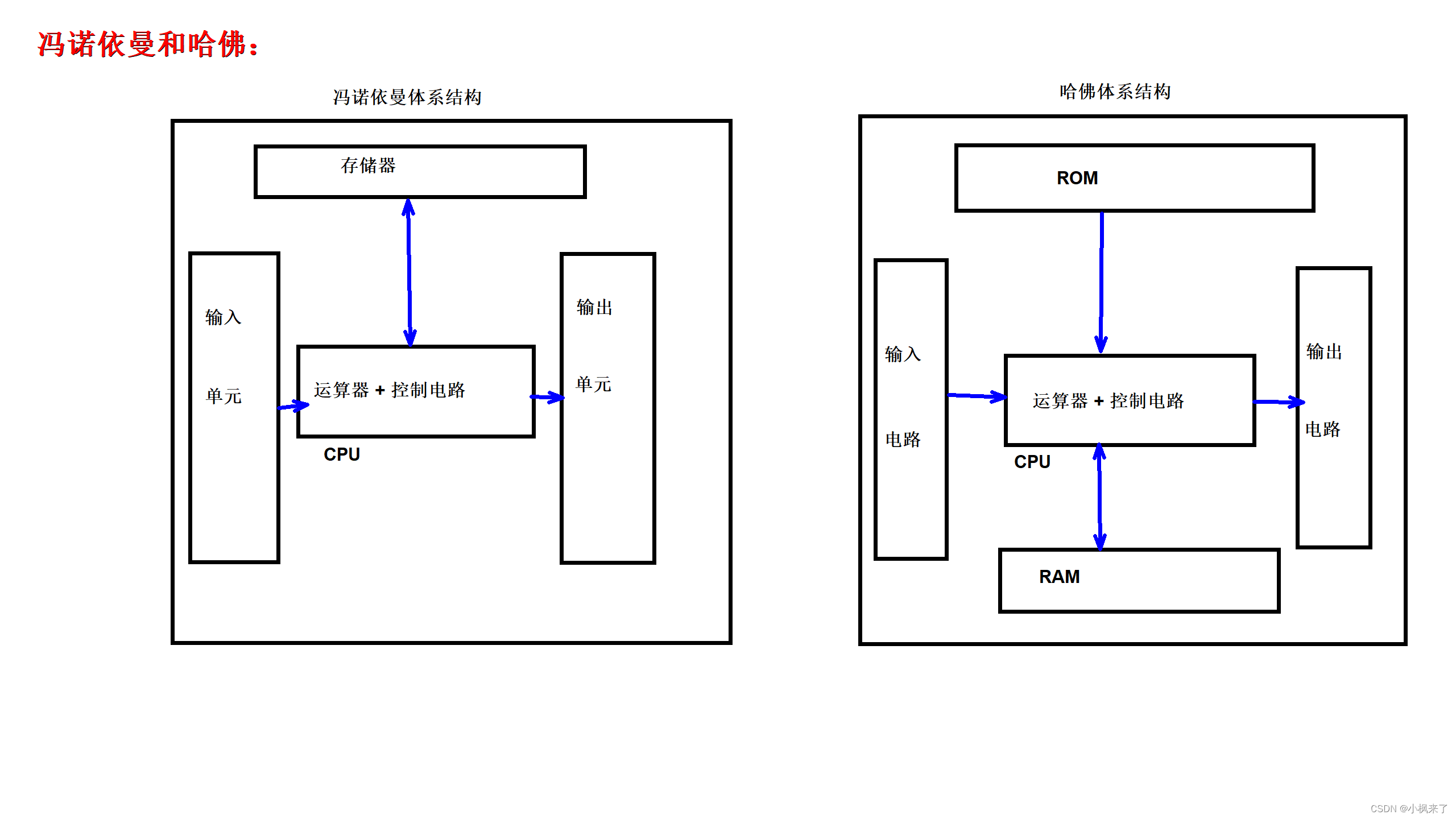
冯诺依曼体系结构和哈佛体系结构
(1)冯诺依曼体系结构(存储程序型电脑)
最开始的计算机只有固定的数学计算程序,它不能用来处理文字......
1943年第一台电子计算机(巨人机)诞生用来破解恩尼格密码系统(普遍认为1946年诞生的ENIAC(埃尼爱克)才是第一台计算机)
冯诺依曼把计算机系统分成如下几个部分:
1.算数逻辑单元(运算器)
2.控制器(CPU = 运算器 + 控制器)
3.存储器:用来存储指令和数据(都是以二进制形式存储)
4.输入设备/输出设备
冯诺依曼体系结构特点:
1.计算机处理的数据和指令都是用二进制表示
2.指令和数据混合存储在同一个存储器中
3.顺序执行
有人提出:对于计算机而言,虽然数据和指令本质上就是"二进制数据",但是属性是不一样的
指令:只读属性
数据:可读可写属性
所以指令和数据应该分开存放。
也就是说应该把存储器分成只读存储器和可读可写存储器
ROM:Read Only Memory 只读存储器
RAM:Random Access Memory 随机存取存储器(可读可写存储器)
因此衍生出了第二种体系结构:哈佛体系结构
(2)哈佛体系结构
是一种将程序的数据存储和指令存储分开的存储器结构。
但是哈佛并没有完全突破冯诺依曼体系结构。
刚才在图示中看到ROM是只读存储器,那么ROM中的指令和数据哪里来?怎么写进去的?
我们说的"只读"只是针对于CPU的,我们通过烧写器进行程序烧写。
一般的,硬件厂商在设计硬件平台的时候,设计一个烧写电路。
通过上面的学习,我们知道计算机的组成:运算器+控制电路+存储器+输入设备+输出设备
这么多的单元之间是如何通信 ---- 总线。
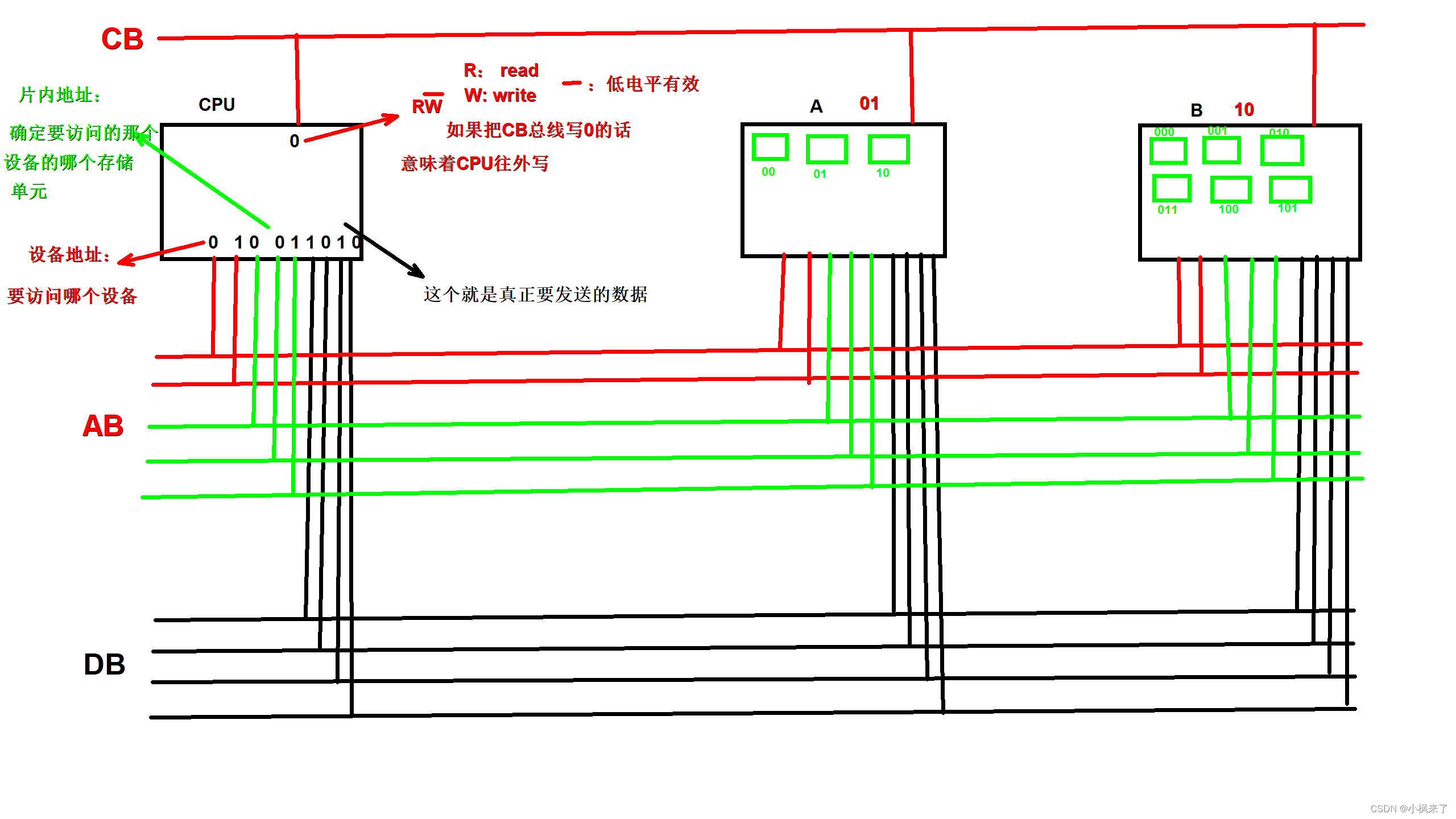
3.总线
计算机系统内部各器件之间都是通过总线进行通信的。
现代计算机基本都是电子计算机,那么组件之间传递都是电信号(高电平1 低电平0)
总线: 多根"电线"
总线有两个特点:
1.多个部件可以同时从总线上接收消息,总线通信方式是广播式。
2.任意时间只允许一个设备向总线上发送消息,称之为总线瓶颈。
总线按功能分类:
1.数据总线DB:负责部件与部件之间的数据传输
特点:双向传输
2.地址总线AB:负责传递地址数据
特点:单向传输,只能由CPU传输。地址总线的宽度与寻址空间有关。比如:如果是32bit的寻址空间,就有32根地址总线。
地址总线实际就是由设备地址和片内地址组成
设备地址:表示要通信的那个设备
片内地址:表示要访问的是那个设备的哪个存储单元
3.控制总线CB:负责命令和状态的传输
比如:
读写信号.....
总线按位置分类:
1.片内总线
2.系统总线
3.通信总线(IO总线)等等
4.CPU的工作原理
CPU = 算术逻辑单元(ALU) + 控制电路(Control Unit) + 寄存器(Register)
(1)算术逻辑单元(ALU)
专门执行算术和逻辑运算的数字电路。早期的算术逻辑单元只有加法器
(2)控制电路(Control Unit)
控制电路是整个CPU的指挥中心。根据用户预先编好的程序,依次从存储器中提取指令,根据指令发送信号决定各器件的行为
(3)寄存器(Register)
寄存器是CPU内部用来存放一些小型的存储区域,寄存器其实是一种非常简单的时序逻辑电路,只不过这种时序逻辑电路只有存储
电路:锁存器/触发器
5.指令流水线
指令流水线是将从存储器中获取指令到CPU处理指令到最后产生结果,分成了多个步骤,并且让不同的组件去完成不同的任务从而实现指令
的流水线运作。指令流水线是为了提高处理器处理的效率。

6.一些基本概念
(1)机器字长
是指CPU一次能处理数据的位数,通常与CPU的寄存器有关
比如:GEC-M4采用的就是STM32F407,寄存器是32bits,所以GEC-M4的机器字长为32位
字长越长,数据的范围越广,精度越高,效率越快。
(2)int 与 机器字长的关系
int 一般是机器中最自然的长度。
其中unsigned long 表示一个地址的值。
比如要去存储一个地址0x12345;
unsigned long *addr = (unsigned long *)0x12345;
(3)bit : 一个存储元件,存储器的最小单元,可以存储一个二进制码 1/0
(4)byte: 一个存储元件,由8bits组成,存储器的最小单位,一个地址对应的就是一个字
节的存储空间
(5)芯片(MCU):CPU+总线+存储器
(6)CPU厂商:负责研发和设计CPU
目前主流的CPU架构有:
(CPU架构是CPU厂商给属于同一系例的CPU产品定的一个规范,主要目的就是区分不同类型的CPU)
x86架构:
Intel公司设计。Intel既可以设计CPU也可以生产CPU。
具有复杂的指令集,功能很强大,功耗大
主要应用于PC
ARM架构:
ARM公司。
ARM公司只设计CPU而不生产,提供CPU方案授权给芯片厂商
精简指令集,功能同样强大,功耗比x86要小,所以非常适用于嵌入式系统
还有一些MIPS架构等其他小众架构
(7)芯片厂商
主要负责生产CPU,当然有些芯片厂商偶尔研发一下CPU。
Intel,三星,海思,ST(STM32,STC89),联发科.....
(8)ARM系例产品
ARM:既是公司名(全球最大的芯片研发中心),也是一种架构,也是一种汇编指令集
比较常见的:ARM7,ARM9.......
ARM12以后,ARM的产品不再以传统的方式命令,而是分成了三个系列:
ARM Cortex-A系列:
性能级CPU,对主频和性能要求很高。
A7,A8,A9...........A53......
ARM Cortex-R系列:
对实时性要求很高,军工和工业上使用比较多
ARM Cortex-M系列
单片机系列
常见的: M0 M1 M2 M3 M4,.....
二. Cortex-M4的工作状态(处理器状态)
ARM公司设计的CPU,可以支持多种指令集。
计算机指令就是指挥机器工作的指示,指令集就是CPU中用来计算和控制计算机系统的一套指令的集合。
(1)ARM指令集
ARM公司提供,32bits指令,功能比较强大
通用汇编指令集(所有的ARM产品CPU都支持)
(2)Thumb指令集:
(2.1)Thumb指令集
16bits指令,功能强大
(2.2)Thumb-2指令集
32bits指令,并且增加了不少专用的DSP(数字信号处理)指令
因此我们CPU正在执行何种指令集称之为何种状态
ARM状态:
CPU正在执行ARM指令集
Thumb状态:
CPU正在执行Thumb指令集
需要注意的是,Cortex-M4只支持Thumb指令集,因为Thumb-2指令集包含了ARM中所有的通用指令,不需要特意再去支持ARM指令集。
汇编指令操作的对象是寄存器
三. Cortex-M4的寄存器
按用途划分:通用的寄存器,专用的寄存器,特殊的寄存器。
(1)通用寄存器,共13个
指它没有特殊含义,没有特殊的用途,想怎么用就怎么用
R0~R7:
Thumb和Thumb-2都能访问。
R8~R12:
只有少量的Thumb指令可以访问,Thumb-2都可以访问。
ARM指令集可以访问R0~R12
(2)专用寄存器,共四个分别是R13(SP),R14(LR),R15(PC),xPSR
"专用寄存器":有固定用途的寄存器
2.1 R13(SP):Stack Pointer
堆栈指针:用来保存堆栈的栈顶地址。
"堆栈":是指用"栈的思想"来管理的一段内存。
为什么需要堆栈?
目的就是为了支持过程调用(函数调用),栈用于维护过程调用的上下文,离开了栈函数调用就没法实现了。
过程调用,其实就是跳转,我们在执行一个过程时,遇到了跳转指令,要跳转到另一个过程去执行,而我们所有操作数,都需要存储在寄存器中
CPU才能访问。一个过程的一些操作产生的中间结果也保存在寄存器,如果一个过程(主调函数)去调用了另外一个过程(被调函数),另外一个过程有可能
修改寄存器里面的内容,在代码结束后,返回到主调函数时,寄存器里面的值有可能会被更改了。
因此在过程调用的前后,就需要对寄存器进行保护和恢复。
"现场保护":将寄存器中的数据保存到某块地址连续的空间(存储器)去。
"现场恢复":将原先保存在存储器中的数据,有序的恢复到原本的寄存器中去。
这个过程刚好符合先进后出的思想,所以栈非常合适。
Cortex-M4有两个堆栈:双堆栈结构
主要是为了支持操作系统,把系统用的堆栈和用户线程用的堆栈分开
MSP:主堆栈指针,主要给OS和中断的代码使用
PSP:进程堆栈指针,主要给用户代码使用
我们知道,函数执行结束后会返回到原来调用的地方,过程调用相当于C语言中的函数调用,过程调用是不是也需要返回?需要
那么我们知道指令依次存储在存储器中,按地址寻址。
那么既然要返回,怎么样才能知道返回到哪个地址?
那么这个时候就需要另外一个专用寄存器R14(LR).
2.2 R14(LR):Linked Register
链接寄存器。其作用就是在执行过程跳转指令的时候,LR寄存器就会存储"过程跳转指令"的下一条指令的地址-->需要返回的地址
举个例子:(A C D E F都是假设的指令)
A
BL func
C
D
func
F
E
其中BL func中的BL是带返回的跳转指令,用来跳转到func标记的那个地址中去执行。
"带返回":BL在跳转时,会将C指令的地址存储到LR寄存器中,然后再去跳转
2.3 R15(PC):Program Counter
程序计数器,作用是保存下一条要执行的指令的地址。
通常我们讲的"指令是顺序执行",就是从地址位0x0000 0000的那天指令开始执行,下一条指令的地址就是0x0000 0004,以此类推。
只要我们将地址>>2,就是当前已经执行的指令的条数 -->前提是没有发生跳转
改变PC的方式有两种:
(1)随着程序的运行,自动增加
(2)通过跳转指令或者人为修改
MOV PC,#0x0800 0040 ;这条指令之后,下一条指令就是存储器地址为0x0800 0040的那条指令
BL func ;在执行这条指令的时候,PC里面存储是A的地址,执行完BL func,把func标记的地址重新写入了PC寄存器
指针的长度和地址总线的宽度相关,如果地址总线AB的长度是32位,那么指针的大小一般就是4字节。
机器字长是cpu中一个寄存器的最大位数,64位的寄存器对应计算机的机器字长就是64.
那么它的int型数据一般就是8字节。
















 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









