






机器学习———前程无忧数据清洗
一.初步清洗
import numpy as np
import pandas as pd
import warnings
#定义函数
def data_clean(data):
# 统一岗位名称为数据分析师
for i, j in enumerate(data['工作名称']):
if '数据分析' in j:
j = '数据分析师'
data['工作名称'] = j
# 对薪资这一列进行清洗,替换掉其中的千,万等字
for i, j in enumerate(data['薪资']):
j = j.replace('[', '').replace(']', '').replace("'", '')#去除其中存在的"["等脏数据
j1 = j.split('·')[0] # 对数据进行拆分,去掉后面的13薪等
data['薪资'][i] = j1
# 对公司名称这一列进行清洗
for i,j in enumerate(data['公司名称']):
j = j.replace('[','').replace(']','').replace("'",'')#去除其中存在的"["等脏数据
data['公司名称'][i] = j
#对工作地点这一列进行数据清洗
for i,j in enumerate(data['工作地点']):
j = j.replace('[','').replace(']','').replace("'",'')#去除其中存在的"["等脏数据
data['工作地点'][i] = j
#对学历这一列进行数据清洗
for i,j in enumerate(data['学历']):
j = j.replace('[','').replace(']','').replace("'",'')#去除其中存在的"["等脏数据
data['学历'][i] = j
data['学历'].value_counts()
#对详情页链接这一列去掉[]
for i,j in enumerate(data['详情页链接']):
j = j.replace('[','').replace(']','').replace("'",'')#去除其中存在的"["等脏数据
data['详情页链接'][i] = j
return data
if __name__=='__main__':
warnings.filterwarnings('ignore')#忽略其中存在的某些警告
data = pd.read_csv('./qiancheng.csv', encoding='gbk') # 读入数据
data = data_clean(data)
data.to_csv('QCdata_clean.csv',encoding='gbk')#将清洗后的数据存储
# print(data)
效果如下

进一步对薪资一列进行清洗,将数据转换为int
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')#忽略其中存在的某些警告
data = pd.read_csv('./QCdata_clean.csv', encoding='gbk') # 读入数据
data['薪资'] = data['薪资'].astype('str')#将该列的数据转换为str,否则下列代码会报错
#由于之前的代码中替换万等脏数据会报错,所以只能在这里替换
for i, j in enumerate(data['薪资']):
j = j.replace('万','').replace('千','').replace('/年','').replace('及以下','')
data['薪资'][i] = j
#将数据统一格式并取中间值
for i, j in enumerate(data['薪资']):
j1 = float(j.split('-')[0])#以-为分割符取下标为0
if j1>2:#由于所爬去的数据有千或万的单位,经过分析万的并不超过3,所以判断超过3的单位为千,不超过的单位为万
j1= j1*1000
else:
j1 = j1*10000
j2 = float(j.split('-')[-1])#以-为分割符取下标为1的
if j2>2:
j2= j2*1000
else:
j2 = j2*10000
j3 = 1/2*(j1+j2)#取中间值
data['薪资'][i] = j3
data['薪资'].fillna(data['薪资'].mean(),inplace=True)#以中间值填充其中空白的
for i, j in enumerate(data['薪资']):
j=int(j)
data['薪资'][i] = j
data.to_csv('QCdata_clean_change.csv',encoding='gbk')#将清洗后的数据存储
效果如下
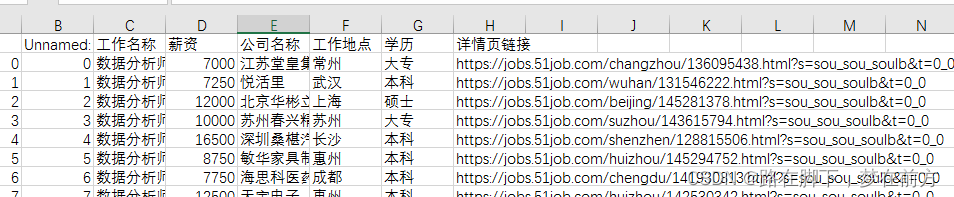 以上只是简单的数据清洗,其余的由于本案例并没有涉及更脏的数据所以并没有用到更多的数据清洗方法,另外由于对正则表达式掌握不够所以也并没有用到,感兴趣的可以自己学习,接下来就是数据可视化
以上只是简单的数据清洗,其余的由于本案例并没有涉及更脏的数据所以并没有用到更多的数据清洗方法,另外由于对正则表达式掌握不够所以也并没有用到,感兴趣的可以自己学习,接下来就是数据可视化
#未完待续















 7348
7348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









