







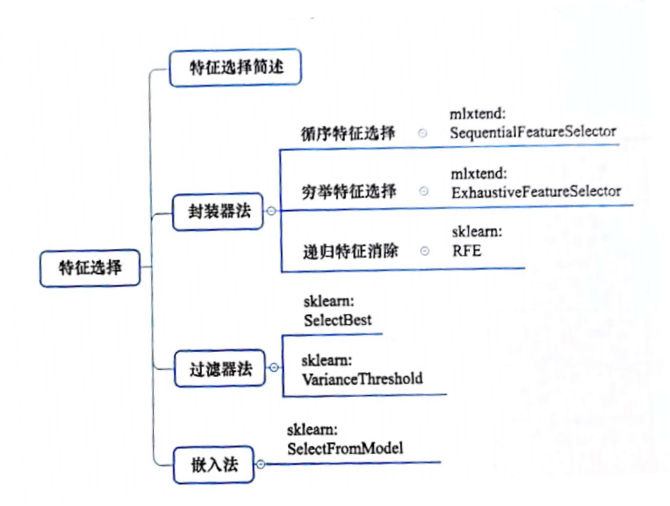
目录
import pandas as pd
df_wine = pd.read_csv("wine_data.csv").iloc[:,1:-1]
df_wine.head()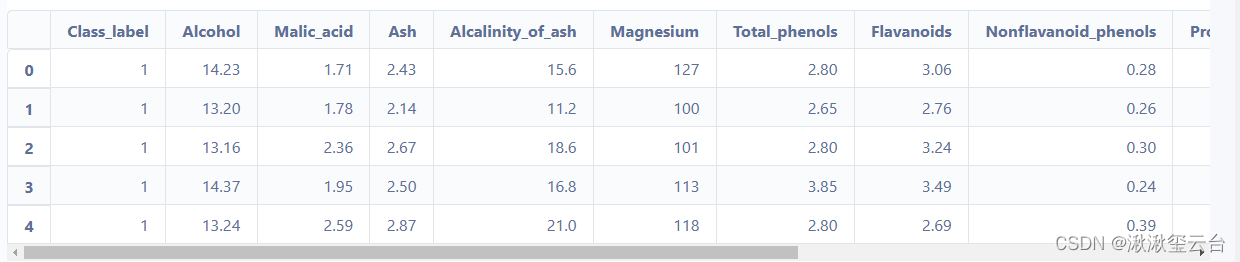
df_wine.info()
df_wine["Class_label"].unique()array([1, 2, 3])
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:*
- X_train,X_test, y_train, y_test =
- train_test_split(train_data,train_target,test_size=0.4, random_state=0)
- 参数解释:
- train_data:所要划分的样本特征集
- train_target:所要划分的样本结果
- test_size:样本占比,如果是整数的话就是样本的数量
- random_state:是随机数的种子。
- 随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。不填的话默认值为False,即每次切分的比例虽然相同,但是切分的结果不同。
- 随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
- 种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。 参数stratify: 依据标签y,按原数据y中各类比例,分配给train和test,使得train和test中各类数据的比例与原数据集一样。
- A:B:C=1:2:3
- split后,train和test中,都是A:B:C=1:2:3 分层抽样
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
x=df_wine.iloc[:,1:]
y=df_wine.iloc[:,0]
#type(train_test_split(x,y,test_size=0.3,random_state=0,stratify=y))
#把数据集划分为训练集和测试集
x_train, x_test, y_train, y_test=train_test_split(x, y, test_size=0.3, random_state=0, stratify=y)
#对测试集和训练集分别实现特征标准化
#pd.DataFrame(x_train)
std = StandardScaler()
x_train_std = std.fit_transform(x_train)
x_test_std = std.fit_transform(x_test)
x_train_std[0]
#以特征“Class_label”为标签,建立对数概率回归(logistic回归)模型,寻找另外13个特征与标签之间的关系
from sklearn.linear_model import LogisticRegression
#lr = LogisticRegression(penalty='l1', C=1.0) # ①
lr = LogisticRegression(C = 1.0, penalty = 'l1',solver='liblinear')
lr.fit(x_train_std, y_train)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l1',
random_state=None, solver='liblinear', tol=0.0001, verbose=0,
warm_start=False)
logistic回归)模型:实际上分类算法



机器学习-逻辑回归(LogisticRegression)详解_yuxj记录学习的博客-CSDN博客_logisticregression
C:正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。
C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩得越来越小。
Solver lbfgs supports only 'l2' or 'none' penalties, got l1 penalty.解决办法_J符离的博客-CSDN博客
lr.coef_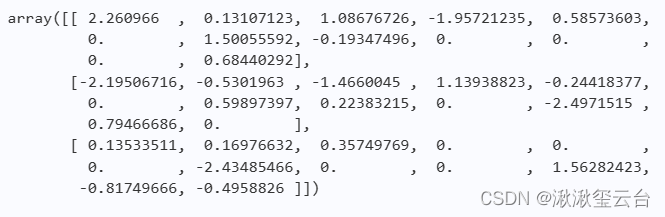
lr.coef_
#Out输出的是13个特征的系数(权重),输出结果显示,
#所创建的模型Ir而言,有的特征的系数为0,说明这类特征与预测结果无关。
pd.DataFrame(data=lr.coef_)
原因: 创建对数概率回归(logishe 回归)模型的时候,使用了参数penalty='l1'和C=1.0,这意味着在本模型中遵照此规则增加了惩罚项,其意图就是避免训练得到的模型过拟合,也正是出于这个原因,模型舍弃了部分特征————表现出来就是系数为0。
lr.intercept_array([-1.67771742, -1.21682777, -2.37190121])
在机器学习项目中,过拟合是比较常见的现象,通常采取如下避免的
- 方法:
- 要有足够多的训练集数据。例如,在划分训练集和測试数据时,没有“五五分”,而是让训练集的占原有数据集样本的比别大一些。
- 在模型中增加惩罚项,简化模型。
- 尽可能选用参数少的模型。
- 降低数据集的维度。
在实际项目中,会综合运用以上方法,并考虑每种方法的成本,比如获取足够多的数据,通常其成本比较高。其他方法则要视工程师的经验而定, 比如“降低数据集的维度”(简称“降维”)。
本章所介绍的特征选择,是实现降维的一种方式;特征抽取,与特征选择有本质区别,它是实现降维的另外一种方式。
- 特征选择(Feature selection),指去除数据集中冗余和无关的特征,从数据集中找出主要特征,最终得到的是原有特征的子集。因此,特征选择也称为“特征子集选择”。
用数学语言定义特征选择如下:
**N个变量中,选取M个变量(M<N)**
从数据集的原有特征中选择了特征子集,再用于机器学习中的预测、分类等计算,这样做不但能够缩短模型的训练时间,还因为特征数量减少了,使得模型更易于理解和解释。
如何实现特征选择?
本章将介绍三类方法∶封装器法、过滤器法和嵌入法。这些方法各有各的特色和适用领域,供读者在具体项目中选择应用。
封装器法:
封装器(Wrapper)法的基本思路(如图4-1-1所示)是∶
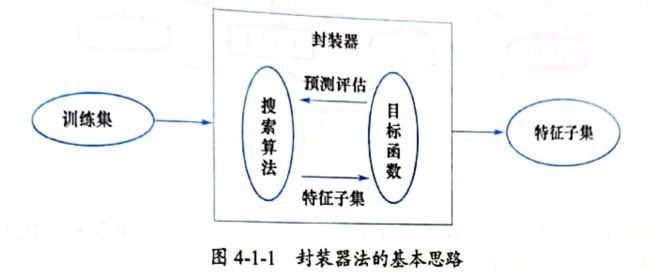
- 选用一个特征子集训练模型。此处的“模型”通常是一种机器学习算法,也称为目标函数(Objective function)。
- 用验证数据集对模型进行评估。
- 依据某种搜索方式,对不同的特征子集进行上述操作。
- 依据评估结果,选出相对最佳的特征子集。
这种方法属于"贪心搜索算法(或“贪婪捜索算法”,穷举暴力搜索)其计算量比较大。
理论上,原特征集合中的特征有多少种组合,都要经过目标函数评估,最终才能选择最佳的特征子集。如果真的这样做,在遇到特征数量多的数据集时,就会很麻烦了。
1.1. 穷举特征选择
穷举特征选择(Exhaustive Feature Selection)指封装器中搜索算法先将所有特征组合都实现一遍,然后通过比较各种特征组合后的模型表现,从中选择出最佳的特征子集。比如有4个特征,就会出现15种(2^4-1 )组合方式 (m个特征,就会有2^m-1种组合):
- •1个特征→4种组合。
- •2个待征→ 6种组合。
- ・3个特征→4种组合。
- •4个特征→1种组合。

1.2. 循序特征选择
1971年,Whitney提出了 “循序向前/向后特征选择” [Whitney, A. W. (1971). A direct method of nonparametric measurement selection.IEEE Trans. Comput., 20(9), 1100-1103.]。 循序向前选择的英文是 Sequential Forward Selection(SFS)0 循序向后选择的英文是 Sequential Backword Selection(SBS)。
下面以SFS为例,说明其实现步骤:
- 创建一个空的集合X,作为特征子集
- 从原特征集合中“一次挑选一个”——这就是“循序”的含义,与特征子集X中的特征组合,并使得目标函数(选定的某个机器学习模型)结果最佳(模型预测的误差最小)
- 将挑选出来的特征从特征集合中移除,同时将其追加到x中。
- 重复第(2)、第(3)步, 直到集合X中的特征数量达到规定的数量为止,中止上述循环。
显然,SFS不是把所有可能都实现一遍,而是找到一种可能最优解即终止寻找。这样就大大降低了计算量。 可以依据SFS的思想编写程序。但是,这个工作不需要我们做了. 因为有一个名为mlxtend的第三方库提供了实现包括SFS的多种循序特征选择方法(官方网站:http://rasbt.github.io/mlxtend/)。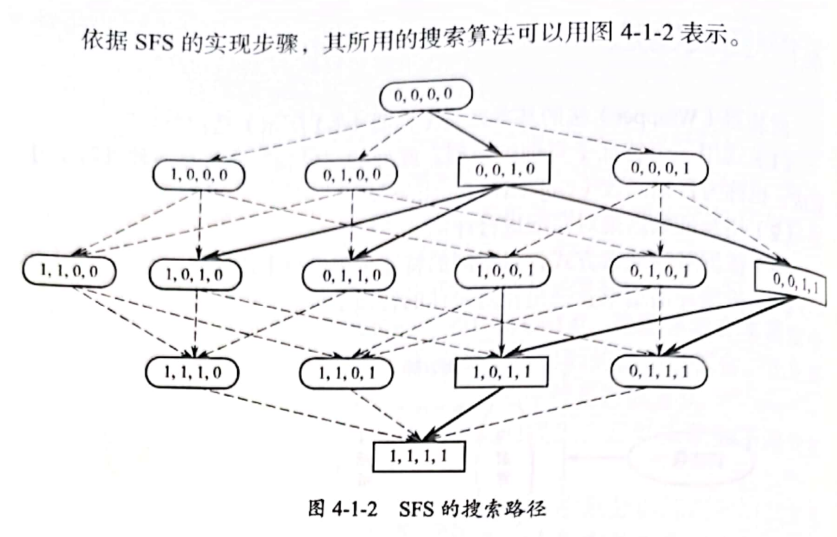
!pip install mlxtend
from mlxtend.feature_selection import SequentialFeatureSelector as SFS #SFS
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
#(1)导入数据
wine = load_wine( )
X, y = wine.data, wine.target
X.shape(178, 13)
load_wine中集成了几个数据集,这里使用关于葡萄酒的数据。
X有13个特征178个样本。y是每个样本的标签,即每种葡萄酒的等级(共有3级,用 整数0, 1, 2表示)。其中,X的13个特征依次对应的名称是:
- (1)Alcohol
- (2)Malic acid
- (3)Ash
- (4)Alcalinity of ash
- (5)Magnesium
- (6)Total phenols
- (7)Flavanoids
- (8)NonflaVanoid phenols
- (9)Proanthocyanins
- (10)Color intensity
- (11)Hue
- (12)OD280/OD315 of diluted wines
- (13)Prolinco
X_train, X_test, y_train, y_test= train_test_split(X, y,
stratify=y,
test_size=0.3,
random_state=1)
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
#利用StandardScaler对数据集中的特征标准化而后创建knn模型,用作②SFS的目标函数。
knn = KNeighborsClassifier(n_neighbors=3) # ①
##############################################
############前后 研究一下 ###########################
#############################################
sfs = SFS(estimator=knn, # ②
k_features=4,
forward=True,
floating=False,
verbose=2,
scoring='accuracy',
cv=0)
sfs.fit(X_train_std, y_train)
# mlxtend提供的循序特征选择类SequentialFeatureSelector (引入的时候更名为SFS)的实例,
#可以理解为创建本节所说的“封装器”。
#estimator=knn:也可以直接写knn。封装器内的目标函数一般为分类或回归算法。
# k_features=4 :通过循序特征选择方法选择4个最佳特征,
# 即共有10 个组合(特征子集中有〃个特征,则共有m(m+1)/2个组合)。
# fbrward=True :声明此次使用的是循序向前特征选择.如果设置为 False,则为循序向后特征选择。
# floating=False :默认值为False。如果为True,则意味着启用所谓“浮动选择算法”。
# verbose=2:设置为2,表示要输出训练过程的全部日志信息;如果为0, 则不显示;如果为1,则显示当前特征集合中的1个特征信息。
# scoring='accuracy':对模型的评估方法。
# 对于分类模型,可选值有accuracys、fl、precision、recall、roc_aucc
# 対于冋归模型,可选值有mean_absolute_error、mean_squared_error、neg_mean_squared_error、median_absolute_error、r2.
# 使用的knn是一个分类模型。
# cv=0:设置为0,表示不进行交叉验证。默认值是5,表示要进行交叉 验证,将训练集分为5份,4份用于训练(训练集),1份用于验证(验证集)。
# 除了上述参数,在SFS类中还可以有参数n_jobs、pre_dispatch、lone_estimator,相关解释请参考官方文档
#(htp∶//asbt.github.io/mlxtend/api_subpackages/mlxtend,feature_selection/#sequentialfeatureselector )。再仔细查看In【2】执行过程中输出的日志信息(为了简化,仅以时间代表该条日志信息)。
- (1)从13个特征中选择了一个最佳的特征,并将其加入空集合中,同时从原来的13个特征集合中删除此特征。根据scoring参数所设定的评估方法,此特征对于模型KNN得分为0.85(score∶0.8548387096774194)。
- (2)从12个特征中选一个,与上一步所选择的特征组合之后,模型knn的得分最高者胜出(score∶0.9596774193548387)。
- (3)从11个特征中选一个,依照前述原则评估模型(score∶0.9919354838709677)。
- (4)从10个特征中选一个,依照前述原则评估模型(score∶0.9838709677419355)。因为参数k_features=4规定了最多选出4个特征,所以到此结束选择。
通过输出的日志信息可以很明确地看出,当选择3个特征的时候,模型knn表现最好。
sfs.subsets_ 
利用Sfs的属性subsets.得到了毎次选择出来的特征及其相应的评估分数,'feature_ names'表示特征名称。
除了循序向前选择(SFS),还冇循序向后选择(SBS)。
SBS的基本含义是先将所有特征纳入特征子集中,然后从中选出一个特征,并评估特征子集。当得到最优特征子集之后,把选出的特征移除。如此不断循环,直到最后达到规定的特征数与为止。
从实施的方法上,SBS就是将参数forward设置为False即可。
实践: SFS和SBS都是简单的特征选择方法,从前面的输出的日志信息中可以看出,因为并没有穷尽所有的特征组合,所选出来的特征不一定是最优的组合。只是按照顺序进行组合,这样做避免了“穷举”导致的计算量过大问题。但是,如何找到"最佳的次优"组合?
knn = KNeighborsClassifier(n_neighbors=3)
sfs2 = SFS(estimator=knn, k_features=4,
forward=True, #区别在于floating=True。
floating=True,
verbose=2,
scoring='accuracy',
cv=0)
#floating=True SFS算法成为“循序向前浮动选择”,它是在SFS(循序向前特征选择算法)基础上的优化
sfs2.fit(X_train_std, y_train)sfs.subsets_ 
#为了更直观地观察特征选择的结果,可以绘制特征子集与模型评分之间的关系图。
#%matplotlib inline #结果嵌入到浏览器中
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
#sfs.get_metric_dict(),是以字典的方式返回利用knn模型对特征子集各个特征组合进行评估的结果
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err') 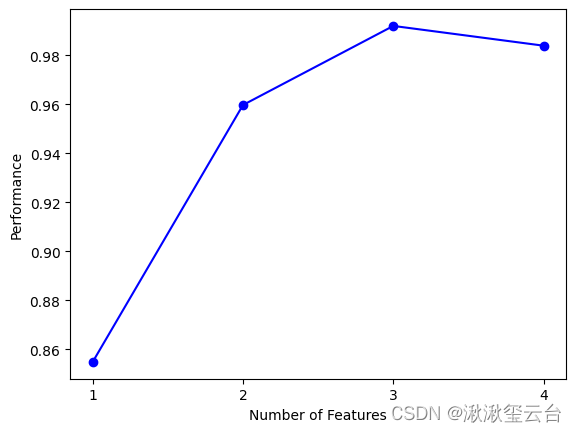
sfs.get_metric_dict() 
前面循序特征选择规定了要选择4个特征,这其实是很武断的,没有什么理由。一种改进的做法是设置特征数量的范围,在这个范围内找出最佳个数的特征。
knn = KNeighborsClassifier(n_neighbors=3)
sfs2 = SFS(estimator=knn, k_features=(3, 10),
#参数k_features=(3,10),表示特征子集中的特征数量为3~10个
forward=True,
floating=True,
verbose=0,
scoring='accuracy',
cv=5)
sfs2.fit(X_train_std, y_train)
fig = plot_sfs(sfs2.get_metric_dict(), kind='std_err') 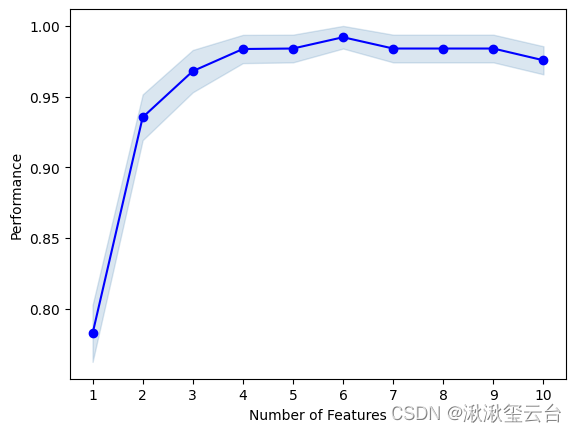
当特征子集中有6个特征时,显然模型表现最佳,以下为这6 个特征的详细信息。
sfs2.subsets_[6]
封装器法之03递归特征消除
递归特征消除(Recursive 英[rɪˈkɜːsɪv] 递归的 Feature Elimination,RFE)也是封装器法的种具体实施,其主要思想是利用训练集数据生成模型,再根据模型的特征权重(通过模型对象的coef_属性或者feature_importances_获得),对特征进行取舍,消除权重不高的特征,从而得到数据集的特征子集。
然后,对这个特征子集重复上述过程,直到特征数量达到规定值为止。显然,每一次迭代寻找最优特征子集的方法依然是贪心搜索算法。
具体:
递归特征消除的主要思想是反复的构建模型(如SVM或者回归模型)然后选出最好的(或者最差的)的特征(可以根据系数来选),把选出来的特征选择出来,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
基础知识
在 scikit-leam 中提供了RFE 类,可以用于创建特征消除封装器的实例。此外,还有名为RFECV的类,其特点在于能够通过交叉验证对特征进行排序。
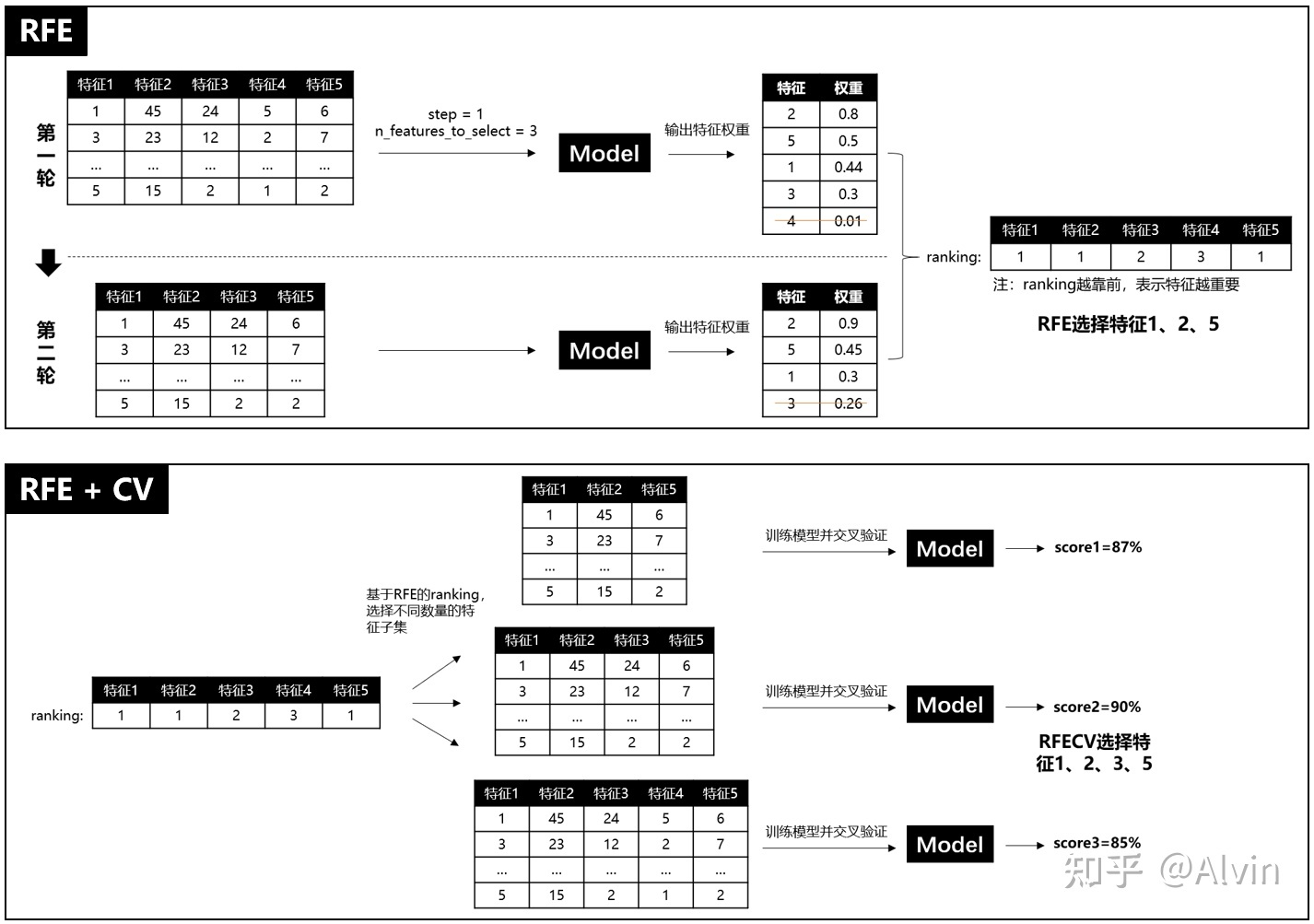
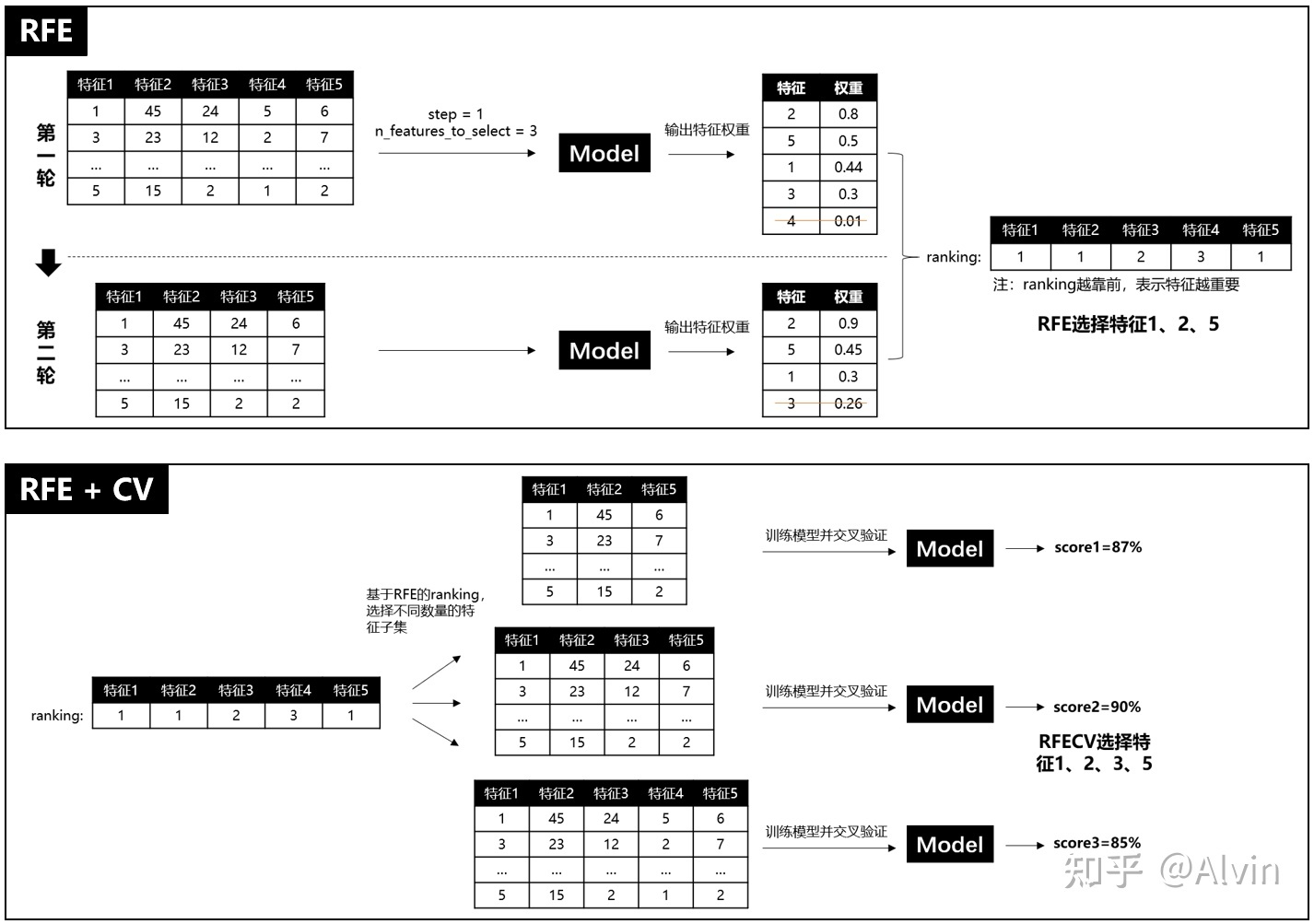
每轮根据特征权重,减少一个变量,年轮后,得到全部的特征变量的rank*顺序)表
数据中有train.csv和test.csv两个数据文件,分别从其中读出数据,在对数据进行清理之后,使用随机森林回归模型作为封装器目标函数,针对训练集(train.csv)运用递归特征消除方法实现特征选择,并记录特征选择耗费的时间。
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
df_train = pd.read_csv("/home/aistudio/data/data169614/train.csv")
df_test = pd.read_csv("/home/aistudio/data/data169614/test.csv")
df_test.head(3)
df_train.info()
df_test.info()
train_samples = df_train.shape[0] #train_samples样本数量
test_samples = df_test.shape[0] #test_samples样本数量
print(train_samples,test_samples)
train_test = pd.concat((df_train, df_test), axis=0, ignore_index=True, sort=False)
df_train.head(3)
df_train.info() 
#df_train.columns
#features=list(df_train.columns)
#features
features = [x for x in df_train.columns]
cat_features = [x for x in df_train.select_dtypes(include=['object']).columns]
num_features = [x for x in df_train.select_dtypes(exclude=['object']).columns]
print("\n Categorical features:\n" , len(cat_features))
print("\n Numerical features: \n" , len(num_features)) 
print(cat_features)
#特征数值化转换
le = LabelEncoder()
for c in cat_features:#针对字符分类变量一列一列进行处理
train_test[c] = le.fit_transform(train_test[c])
X_train = train_test.iloc[:train_samples, :].drop(['id', 'loss'], axis=1)
y_train = df_train['loss']
X_test = train_test.iloc[train_samples:, :].drop(['id'], axis=1)from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestRegressor
from datetime import datetime
rfr = RandomForestRegressor(n_estimators=100, max_features='sqrt', max_depth=12, n_jobs=-1)
rfecv = RFECV(estimator=rfr, #
step=10,#递减幅度
cv=3,
min_features_to_select=10,
scoring='neg_mean_absolute_error',
verbose=2)
start_time = datetime.now()
rfecv.fit(X_train, y_train)
end_time = datetime.now()
m, s = divmod((end_time - start_time).total_seconds(), 60) #divmod得到商和余数
print('Time taken: {0} minutes and {1} seconds.'.format(m, round(s, 2)))Fitting estimator with 130 features. Fitting estimator with 120 features. Fitting estimator with 110 features. Fitting estimator with 100 features. Fitting estimator with 90 features. Fitting estimator with 80 features. Fitting estimator with 70 features. Fitting estimator with 60 features. Fitting estimator with 50 features. Fitting estimator with 40 features. Fitting estimator with 30 features. Fitting estimator with 20 features. Fitting estimator with 130 features. Fitting estimator with 120 features. Fitting estimator with 110 features. Fitting estimator with 100 features. Fitting estimator with 90 features. Fitting estimator with 80 features. Fitting estimator with 70 features. Fitting estimator with 60 features. Fitting estimator with 50 features. Fitting estimator with 40 features. Fitting estimator with 30 features. Fitting estimator with 20 features. Fitting estimator with 130 features. Fitting estimator with 120 features. Fitting estimator with 110 features. Fitting estimator with 100 features. Fitting estimator with 90 features. Fitting estimator with 80 features. Fitting estimator with 70 features. Fitting estimator with 60 features. Fitting estimator with 50 features. Fitting estimator with 40 features. Fitting estimator with 30 features. Fitting estimator with 20 features. Fitting estimator with 130 features. Fitting estimator with 120 features. Fitting estimator with 110 features. Fitting estimator with 100 features. Fitting estimator with 90 features. Fitting estimator with 80 features. Time taken: 9.0 minutes and 30.87 seconds.
- RFECV方法实现特征选择分成两个部分:
- RFE(Recursive feature elimination):递归特征消除,用来对特征进行重要性评级。
- CV(Cross Validation):交叉验证,在特征评级后,通过交叉验证,选择最佳数量的特征。
- 具体过程如下:
- RFE阶段
- 1 初始的特征集为所有可用的特征。
- 2 使用当前特征集进行建模,然后计算每个特征的重要性。
- 3 删除最不重要的一个(或多个)特征,更新特征集。
- 4 跳转到步骤2,直到完成所有特征的重要性评级。
- CV阶段
- 1 根据RFE阶段确定的特征重要性,依次选择不同数量的特征。
- 2 对选定的特征集进行交叉验证。
- 3 确定平均分最高的特征数量,完成特征选择。
在sklearn当中,我们有两种方式调用这个评估指标,一种是使用sklearn专用的模型评估模块metrics里的类mean_squared_error,另一种是调用交叉验证的类cross_val_score并使用里面的scoring参数来设置使用均方误差。cross_val_score的均方误差为负。我们在决策树和随机森林中都提到过,虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字 。 RFECV ,可以通过交叉验证来对的特征进行排序
RFECV方法实现特征选择 RFECV方法实现特征选择_乐无异kop的博客-CSDN博客_rfecv 特征提取 (1) 递归特征消除参数说明与练习 sklearn.feature_selection.RFECV_石�鈺 MeiYu的博客-CSDN博客
提供的RFECV(如③所示)实现了用递归特征消除方法和交叉验证进行特征选择,并得到特征权重排序。
#CV=3 交叉验证 训练集分成3分,2分训练,1分验证 grid_scores_:每个值代表了此次迭代所有特征组合得到的score的平均值。
rfecv.grid_scores_
#len(rfecv.grid_scores_) #13array([-1371.96458936, -1327.55854379, -1297.28710361, -1292.43609584,
-1288.75232876, -1288.25704198, -1287.22201195, -1293.12353293,
-1292.38459241, -1292.68781945, -1295.17461884, -1300.80040118,
-1299.10752167])
#特征数量与交叉验证得分的关系
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure()
plt.xlabel('Number of features tested x 10')
plt.ylabel('Cross-validation score (negative MAE)')
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_) 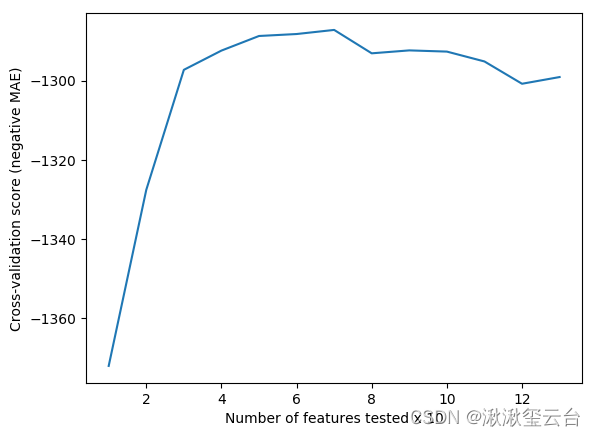
ranking = pd.DataFrame({'Features': features})
ranking.drop([0, 131], inplace=True)
ranking['rank'] = rfecv.ranking_
ranking.sort_values('rank', inplace=True)
ranking
ranking.head(10) 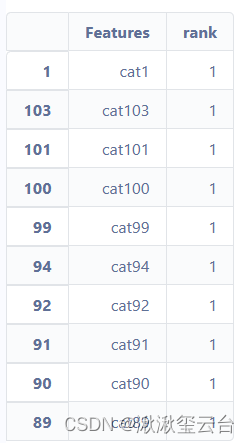
# 第2题 分类器为SVM
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
# 创建数据集
X, y = make_classification(n_samples=1000, n_features=25, n_informative=3,
n_redundant=2, n_repeated=0, n_classes=8,
n_clusters_per_class=1, random_state=0)
# 创建RFEC
svc = SVC(kernel="linear")
rfecv = RFECV(estimator=svc, step=1, cv=StratifiedKFold(2),
scoring='accuracy')
rfecv.fit(X, y)
print("Optimal number of features : %d" % rfecv.n_features_)
# 制图
plt.figure()
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score (nb of correct classifications)")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_) 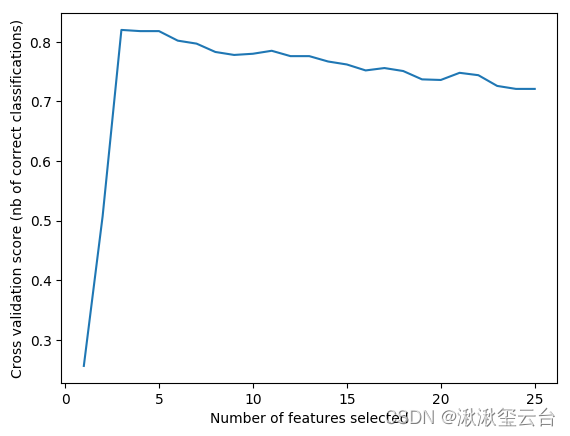
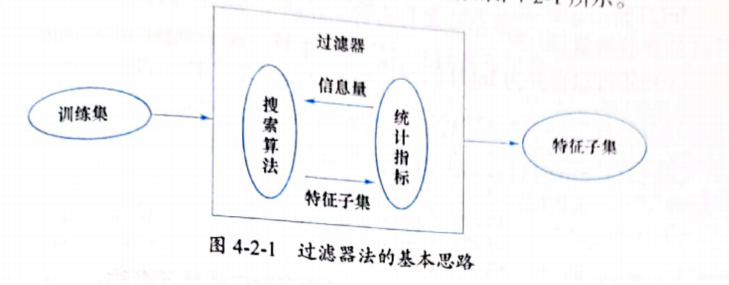
过滤器法
过滤器法是与上一节封装器法并列的特征选择方法之一。与封装器法不同的是,过滤器法不评估特征子集的预测误差,而是使用某些统计指标,比如相关系数、互信息等——目标函数不同,根据这些统计指标,对各特征进行排序,以确定特征的取舍。
过滤器法的基本思路如图:
基础知识
下面用卡方检验(皮尔森卡方检验)作为统计指标选择特征。
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X,y = iris.data,iris.target
#引入的SelectKBest类,是sklearn提供的过滤器类,它的参数score_func中chi2函数,
#也可以写成∶score_func=chi2——引用一个统计指标函数。
#卡方检验(Chi-Square Test)是统计学上的假设检验方法。值越大,两个变量之间的偏差越大反之,偏差越小
#参数k表示特征子集中的特征数量。用鸢尾花数据集训练所创建的模型,
skb = SelectKBest(chi2,k=2)
#显然这是有监督的特征选择,计算数据集中每个特征的χ2值(chi2函数返回值之一)
#然后根据从大到小的排序取k个特征
result = skb.fit(X,y)
print("X^2 is:",result.scores_)
print("P-values is:",result.pvalues_)
#输出结果显示了训练之后的模型实例的χ2值和P值。表示卡方检验的字母不是英文字母X,而是希腊字母χ 英文读音:Chi
#P值(P-value)是统计学中用于判断假设检验结果的参数。P值越小,原假设发生的概率就越

X_new =skb.transform(X)
X_new.shape
#利用训练而得的模型对数据集X进行特征选择,得到了含有2个特征的新数据集。(150, 2)
#训练转换可以合并
X_new =skb.fit_transform(X, y)
print(X[:5]) #原始的数据集
X_new[:5,:] #特征选择选择后的数据集

#所得数据对应的特征名称。
import numpy as np
[i for i in X_new[0,:]]
#iris.feature_names[np.where(X[0,:]==1)[0][0]]
[iris.feature_names[np.where(X[0,:]==i)[0][0]] for i in X_new[0,:]]['petal length (cm)', 'petal width (cm)']
对于SelectKBest的参数score_func,除了chi2函数,
- 还可以是以下函数。
- f_classif对于分类任务用F检验计算F值。
- f_regression∶对于回归任务用F检验计算F值。
- mutual_info_classif∶对于离散型特征计算互信息。
- mutual_info_regression∶对于连续型特征计算互信息。
- 不论是什么函数,其基本思路与前述的相同。
- 在Sklearn中,类似 SelectKBest类的还有 SelectPercentile、SelectFpr、SelectFdr、SelectFwe,它们的使用方法与SelectKBest类相同,此处不再赘述。
- 过滤器法中有一种比较特殊的情况,即如果某特征的方差很低,假设一种极端情况,所有数据都一样,如果计算χ2值,即为0,那么在特征排序中,该特征就会排在尾部,这类特征常常被舍弃。针对这种特殊情况,scikit-learn 提供了一个专有模块。
对比过滤器法和封装器法,它们都是特征选择的常用方法,通过前述操作可知,两者各有特点
- 过滤器法通常不对数据集执行迭代计算,因此计算速度比封装器法要快。
- 封装器的目标函数是某个机器学习算法,过滤器的函数则是通用的统计函数,这样使过滤器法所得的特征更具有通用性,非专门针对某个算法有良好表现。
- 利用过滤器法进行特征选择时,用户需要武断地输入阈值,这可能会导致一定的选择成本。
- 如果特征数量过少,过滤器可能无法找到最佳的特征子集,而封装器总能返回特征子集。
- 因为过滤器所得特征子集因为与某种算法无关,所以一般不会出现过拟合现象,而经由封装器法所得特征子集训练的模型,会出现过拟合现象。
在项目中,应依据具体数据和项目要求,确定特征选择的实施方法。
嵌入法
对数概率回归模型(LogisticRegression)研究了葡萄酒的等级与特征的关系。因为在模型中使用了L1惩罚,从而得到了特征系数的稀疏解,某些特征的系数为0。如此,可以对系数排序————特征权重,然后依据某个阈值选择部分特征。
这种特征选择的实现方法显然不是封装器法,也不是过滤器法,而是在训练模型的同时,得到了特征权重,并完成特征选择。像这样将特征选择过程与模型训练融为一体,在模型训练过程中自动进行特征选择,被称为“嵌入法”(Embedded)特征选择。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
df_wine = pd.read_csv("wine_data.csv")
X= df_wine.iloc[:, 1:]
y =df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.fit_transform(X_test)
lr =LogisticRegression(C = 1.0, penalty = 'l1',solver='liblinear')
#创建Logistic回归模型,采用l1惩罚
model = SelectFromModel(lr, threshold='median')
#hreshold='median'规定选择特征的阈值——特征权重的中位数
X_new = model.fit_transform(X_train_std, y_train)
X_new.shape
(124, 7)
X_train_std.shape #原来的列数(124, 14)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









