







综述
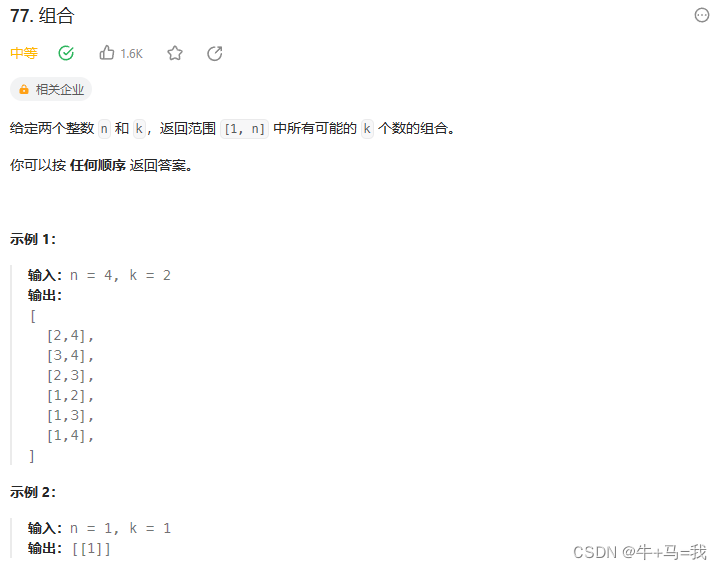
组合:leetcode77
组合总和 III:leetcode216
电话号码的字母组合:leetcode17
组合总和:leetcode39
组合总和 II:leetcode40
分割回文串:leetcode131
复原 IP 地址:leetcode93
子集:leetcode78
子集 II:leetcode90
递增子序列:leetcode491
全排列:leetcode46
全排列 II:leetcode47
重新安排行程:leetcode332
N 皇后:leetcode51
解数独:leetcode37
引言
回溯法概述
回溯法本质是一种暴力搜索,是穷举法,效率很低,用来解决一些复杂的问题,复杂到除了回溯,其他方法没办法解决,比如:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
回溯法可以抽象为树形结构,集合的大小构成了树的宽度,递归的深度,构成了树的深度:

回溯法模板
回溯三部曲:
- 回溯函数模板返回值以及参数
函数名:backtracking,返回值一般是 void,真正需要返回的会写在参数中,用引言传递
void backtracking(参数)
- 回溯函数终止条件
达到终止条件,也就是找到了一条满足条件的答案,那么就将这个答案保存下来,结束本层递归
if (终止条件) {
存放结果;
return;
}
- 回溯搜索的遍历过程
回溯函数遍历过程伪代码如下:
for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历。(见上图)
这样就把这棵树全遍历完了,一般来说,搜索到叶子节点就是找到了其中一个结果
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
所以回溯算法模板框架:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
刷题总结
什么时候需要 startIndex
- 组合问题:一个集合来求组合的话,就需要startIndex
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,比如 电话号码的字母组合 - 分割问题:需要
- 子集问题:需要,并且子集问题不需要递归终止条件return,因为子集就是把所有遍历结果都记录下来
- 排列问题:不需要 startIndex,并且需要 used 记录 path 中加的数据,防止后面再加重复的
结果收集
组合问题、排列问题、切割问题是在树形结构的叶子节点上收集结果
而子集问题就是取树上所有节点的结果。因此子集问题不需要 return,而且也不能剪枝
去重
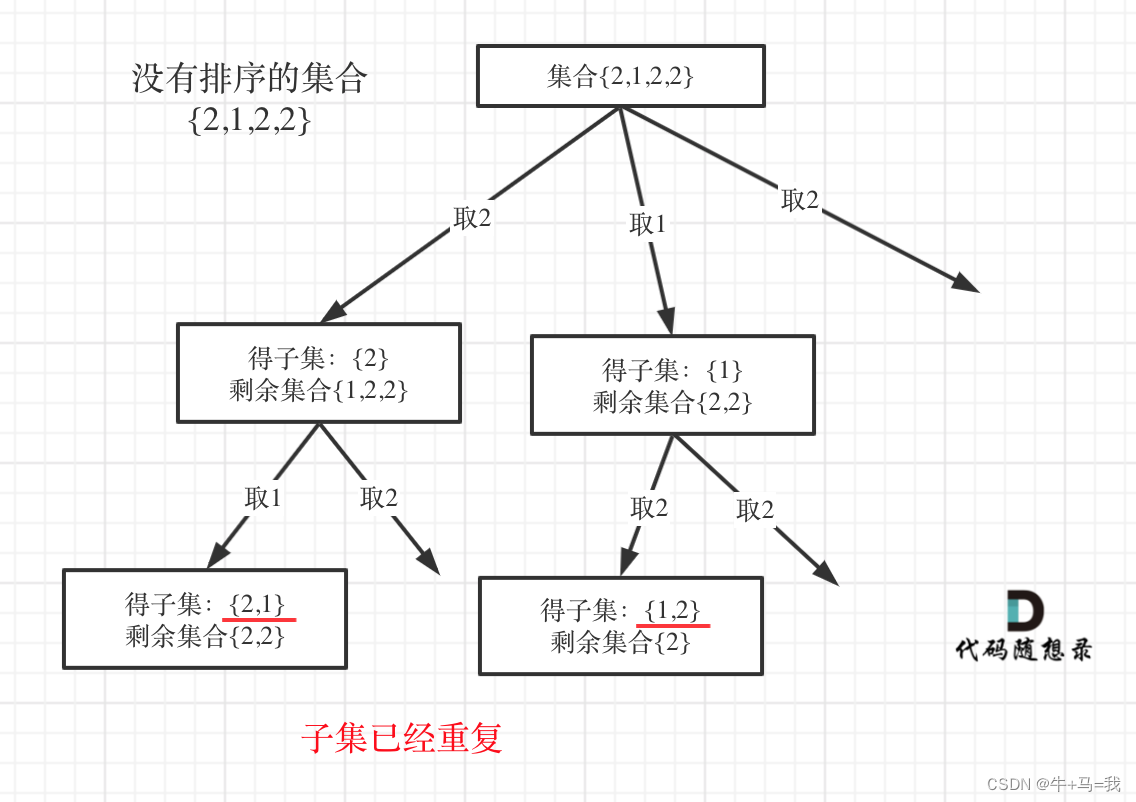
树层去重可以用 unordered_set<int> uset 和 vector<bool> used,used 空间复杂度低,因为 used 是全局的,uset 是每一次递归都有一个。used 时间复杂度也低,因为对 uset 频繁的insert,需要做哈希映射相对费时间,而且 insert 的时候其底层的符号表也要做相应的扩充,也是费时的。
一般使用 used 去重即可,但是对于 递增子序列 是不允许排序的,所以必须用uset。
其他题目用 used 和 uset 都可以,不管用哪个,都需要先排序。使用 uset 排序的原因见图:
时间复杂度和空间复杂度分析
子集问题分析
- 时间复杂度:O(2^n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2^n)
- 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的 res 和 path 都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
排列问题分析
- 时间复杂度:O(n!),这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是
n * n-1 * n-2 * … 1 = n!。 - 空间复杂度:O(n),和子集问题同理。
组合问题分析
- 时间复杂度:O(2^n),组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
- 空间复杂度:O(n),和子集问题同理。
N皇后问题分析
- 时间复杂度:O(n!) ,选完 n 之后,还有 n - 1 种选择,选完 n - 1 之后,还有 n - 2 种选择…
- 空间复杂度:O(n),和子集问题同理。
解数独问题分析
- 时间复杂度:O(9^m) , m是 ‘.’ 的数目。
- 空间复杂度:O(n^2),递归的深度是n^2
组合
题目
题解
如果此题如 for 循环,那么就需要 k 层 for 循环,很难写出代码,因此用回溯法
回溯中的递归相当于解决了多层嵌套循环的问题
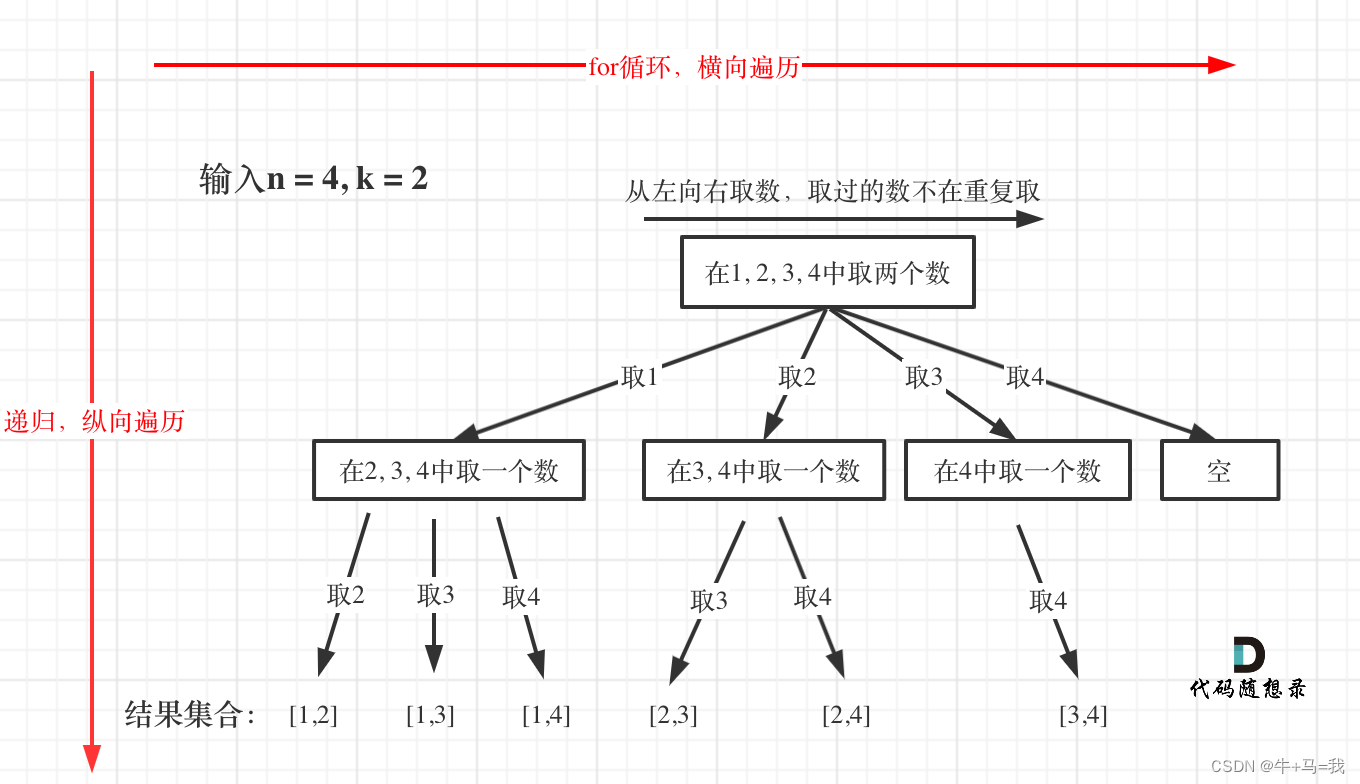
n相当于树的宽度,k相当于树的深度
回溯三部曲直接ac:
class Solution {
public:
vector<vector<int>> combine(int n, int k) {
backtracking(1, n, k);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(int startIndex, int n, int k) {
if (path.size() == k) {
res.push_back(path);
return;
}
for (int i = startIndex; i <= n; i++) {
path.push_back(i);
backtracking(i + 1, n, k);
path.pop_back();
}
}
};
时间复杂度: O(n * 2^n):递归的时间复杂度是 o(2^n),递归中又有 for 循环,因此再乘 n
空间复杂度: O(n * k):res 的存储是 k * n
剪枝操作:

若 n = 4,k = 4 的话,对于第一层,其实遍历到 i = 2 时就没必要遍历了,因为凑不齐 k 了
对于第二层,其实遍历到 i = 3 时就不用遍历了
所以满足: path.size() + [1, n] 中剩余的长度 >= k
即 path.size() + (n - i) >= k
所以: i <= path.size() + n - k
然后需要加1,因为是个数,是左闭右开的,不理解直接手推一下即可
所以是:i <= path.size() + n - k + 1
剪枝代码:
for (int i = startIndex; i <= n && i <= n + path.size() - k + 1; i++) {
path.push_back(i);
backtracking(i + 1, n, k);
path.pop_back();
}
组合总和 III
题目

题解
回溯三部曲直接ac:
class Solution {
public:
vector<vector<int>> combinationSum3(int k, int n) {
backtracking(k, n, 1);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
int sum = 0;
void backtracking(int k, int n, int startIndex) {
if (path.size() == k && sum == n) {
res.push_back(path);
return;
}
for (int i = startIndex; i <= 9; i++) {
path.push_back(i);
sum += i;
backtracking(k, n, i + 1);
path.pop_back();
sum -= i;
}
}
};
剪枝操作:
比如第一个示例:当 path 中有 1,2时,最多遍历到4,到5就超过 n(7)了,所以: i + sum <= n
即i <= n - sum
并且当 path 的长度 大于 k 时也没必要遍历了,不符合题意:path.size() <= k
所以剪枝代码:
for (int i = startIndex; i <= 9 && i <= n - sum && path.size() <= k; i++)
电话号码的字母组合
题目

题解
回溯问题,本题是多个集合求组合,跟之前的一个集合求组合不一样,所以 for 循环可以直接从 0 开始遍历
三部曲直接ac:
class Solution {
public:
vector<string> letterCombinations(string digits) {
if (digits == "") return res;
backtracking(digits, 0);
return res;
}
private:
vector<string> res;
string temp;
void backtracking(const string& digits, int strIndex) {//strIndex是遍历到digits中的序号
if (temp.size() == digits.size()) {
res.push_back(temp);
return;
}
string foreachStr = num2string(digits[strIndex]);
for (int i = 0; i < foreachStr.size(); i++) {
temp += foreachStr[i];
backtracking(digits, strIndex + 1);
temp.pop_back();
}
}
//设置字典
string num2string(char c) {
switch(c) {
case '2':return "abc";
case '3':return "def";
case '4':return "ghi";
case '5':return "jkl";
case '6':return "mno";
case '7':return "pqrs";
case '8':return "tuv";
case '9':return "wxyz";
default: return NULL;
}
}
};
时间复杂度: O(3^m * 4^n),其中 m 是对应四个字母的数字个数,n 是对应三个字母的数字个数
空间复杂度: O(digits.size()),递归的深度取决于 digits.size(),所以递归栈空间是 o(digits.size()),局部变量如 res 和 path 也是和 digits.size() 相关的,其他的局部变量和递归参数与输入规模无关
组合总和
题目

题解
对于组合问题,如果是一个集合求组合,那么需要 startIndex 来表示下一次从哪开始循环遍历,如组合、组合Ⅲ以及本题
如果是多个集合求组合,各个集合之间相互不影响,那么就不用startIndex,如电话号码的字母组合
对于排列问题就不一样了
由于此题允许元素重复选择,因此 递归时 下一次的startIndex 是从 i 开始的
class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backtracking(candidates, target, 0);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
int sum = 0;
void backtracking(vector<int>& candidates, int target, int startIndex) {
if (sum > target) return;//只要超过就返回,防止一直递归
if (sum == target) {
res.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size(); i++) {
path.push_back(candidates[i]);
sum += candidates[i];
backtracking(candidates, target, i);//一个元素可以重复选择,所以不是 i+1,而是 i
path.pop_back();
sum -= candidates[i];
}
}
};
时间复杂度: O(n * 2^n)
空间复杂度: O(target)
剪枝操作:
在求和问题中,排序之后加剪枝是常见的套路
因此本题可以将 candidates 排序,这样只要 sum + candidates[i] > target 就不要再继续这个遍历循环了
比如 candidates = {1, 2, 5, 3},target = 5
candidates 排序后是{1, 2, 3, 5},当 path = {1, 2} 时,此时加上 candidates[i] = 3 就大于 target 了,因此后面的 5 不需要再遍历
因此:
sort(candidates.begin(), candidates.end());//剪枝操作,需要排序
...
for (int i = startIndex; i < candidates.size() && candidates[i] + sum <= target; i++) {//剪枝操作
总体代码:
class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());//剪枝操作,需要排序
backtracking(candidates, target, 0);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
int sum = 0;
void backtracking(vector<int>& candidates, int target, int startIndex) {
if (sum > target) return;//只要超过就返回,防止一直递归
if (sum == target) {
res.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && candidates[i] + sum <= target; i++) {//剪枝操作
path.push_back(candidates[i]);
sum += candidates[i];
backtracking(candidates, target, i);//一个元素可以重复选择,所以不是 i+1,而是 i
path.pop_back();
sum -= candidates[i];
}
}
};
虽然此时时间复杂度:仍是 O(n * 2^n),但是这只是复杂度的上界,因为剪枝的存在,真实的时间复杂度远小于此
组合总和 II
题目
题解
这道题有点难,比如第一个示例,两个1,可以出现在同一个组合比如[1, 1, 6](树枝可以重复),但是不能出现到不同组合比如[1, 2, 5] 和 [2, 1, 5](树层不能重复)
这点没考虑清楚就出错了:

所以需要去重:去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重:
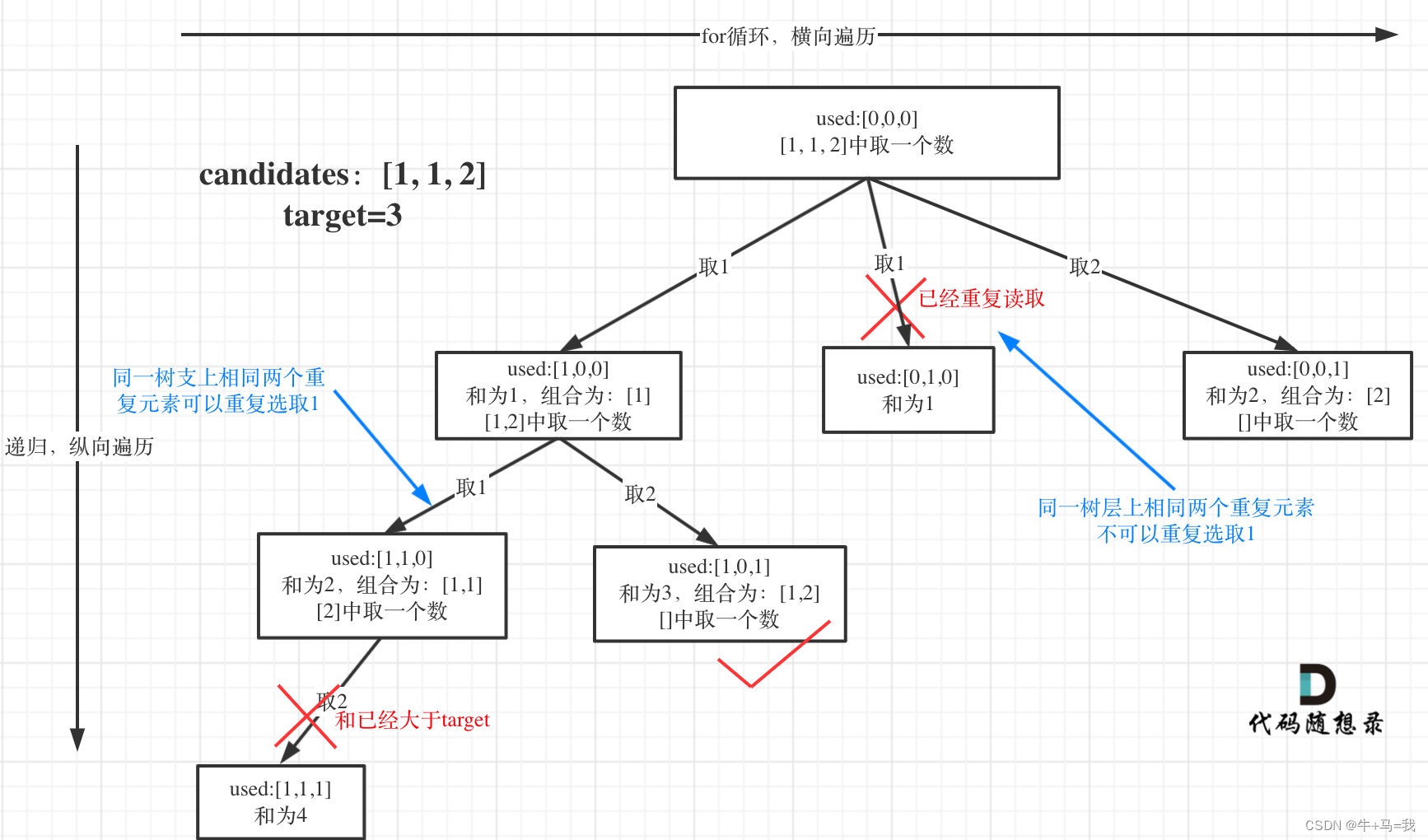
因此使用 used 数组,used 数组是记录 candidates 选择的哪几个数,选中为 true,未选中为 false
去重首先得先将数组排序,这样相同的数字就挨在了一起
- 如果
candidates[i] == candidates[i - 1]并且used[i - 1] == false,那么就是树层重复,因为candidates[i] == candidates[i - 1]表示了这一个数 和 上一个数相等,used[i - 1] == false指的是前面的数已经被回溯了,所以是 false,只有不同的层才会回溯,所以这个代表的是树层重复 - 如果
candidates[i] == candidates[i - 1]并且used[i - 1] == true,那么就是树枝重复,因为树枝没有回溯,所以之前的数是 true
如图:
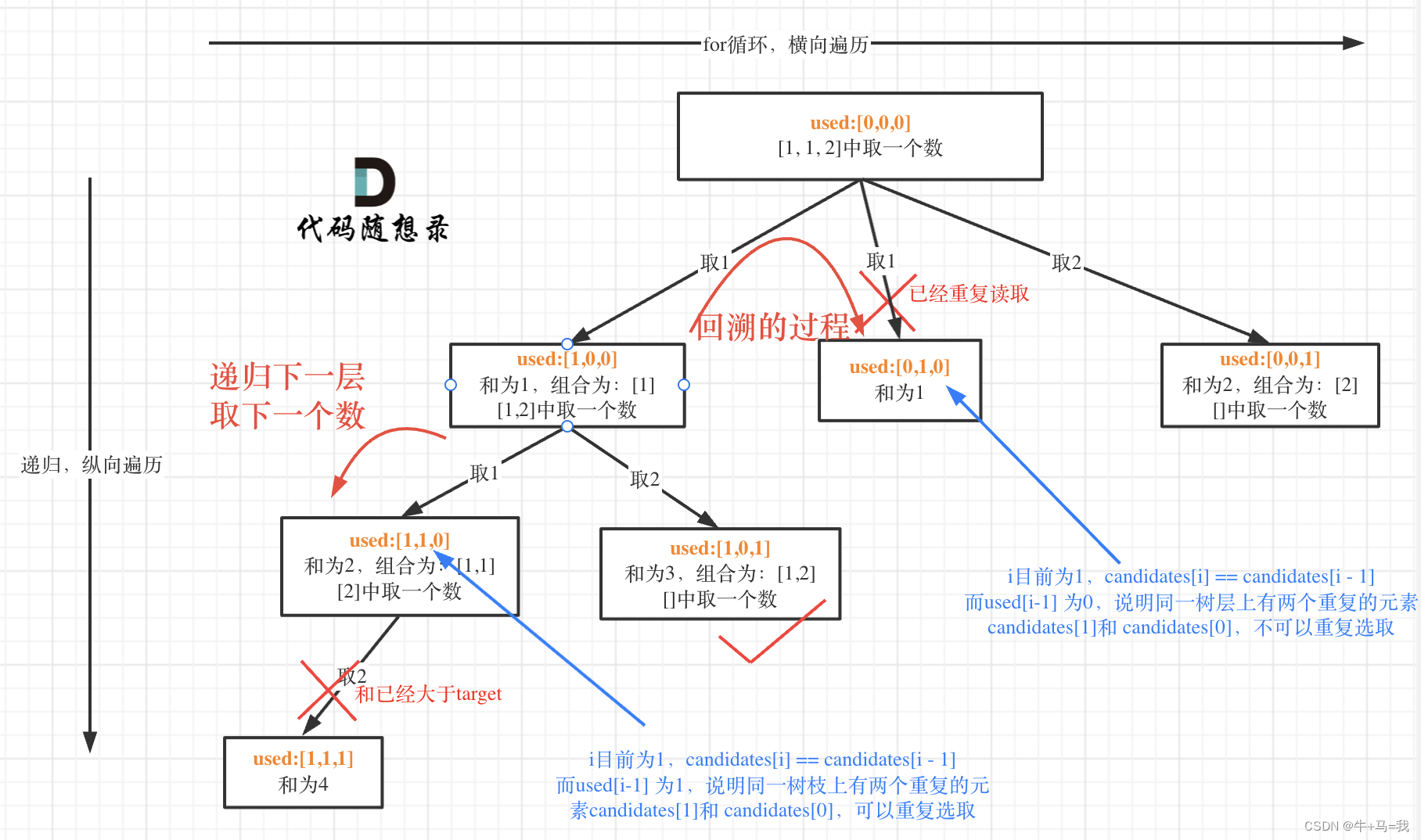
class Solution {
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end()); //1.先排序才能去重 2.排序方便剪枝
vector<bool> used(candidates.size(), false);
backtracking(candidates, target, 0, used);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
int sum = 0;
void backtracking(vector<int>& candidates, int target, int startIndex, vector<bool>& used) {
if (sum > target) return;
if (sum == target) {
res.push_back(path);
return;
}
for (int i = startIndex; i < candidates.size() && candidates[i] + sum <= target; i++) { //包含了剪枝操作
if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) continue; //如果树层重复,则跳过
path.push_back(candidates[i]);
sum += candidates[i];
used[i] = true;
backtracking(candidates, target, i + 1, used); //每个元素只能选一次,因此是 i+1
path.pop_back();
sum -= candidates[i];
used[i] = false;
}
}
};
时间复杂度: O(n * 2^n)
空间复杂度: O(n)
分割回文串
题目
题解
其实切割问题类似组合问题
class Solution {
public:
vector<vector<string>> partition(string s) {
backtracking(s, 0);
return res;
}
private:
vector<vector<string>> res;
vector<string> path;
void backtracking(const string& s, int startIndex) {
if (startIndex == s.size()) { //startIndex 到了最后的位置,说明找到了一种方案
res.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
string temp = s.substr(startIndex, i - startIndex + 1);
if (isHuiWen(temp) == false) continue;//如果不是回文,跳过,看看加上后面的字符是不是回文
path.push_back(temp);
backtracking(s, i + 1);
path.pop_back();
}
}
bool isHuiWen(const string& temp) {
for (int i = 0; i < temp.size() / 2; i++) {
if (temp[i] != temp[temp.size() - 1 - i]) return false;
}
return true;
}
};
时间复杂度: O(n * 2^n) 到 O(n^2 * 2^n) 之间:回溯是 O(2^n),for 循环是 O(n),substr 的时间复杂度是 和 判断回文的 isHuiWen 都是 O(temp.size())
空间复杂度: O(n)
优化:
由于在 for 循环中执行查找回文,使得原来 for 循环只是 o(n) 的复杂度,变成了 o(n^2) 的复杂度
为此,可以先通过动态规划算出字符串 s 的每个起始位置 到 终止位置是否是回文串,记录在一个二维数组中
之后可以在 for 循环中直接查找这个二维数组即可,不用再 判断回文了
class Solution {
public:
vector<vector<string>> partition(string s) {
vector<vector<bool>> huiWenVec(s.size(), vector<bool>(s.size(), false));
isHuiWen(huiWenVec, s);
backtracking(s, 0, huiWenVec);
return res;
}
private:
vector<vector<string>> res;
vector<string> path;
void backtracking(const string& s, int startIndex, vector<vector<bool>>& huiWenVec) {
if (startIndex == s.size()) { //startIndex 到了最后的位置,说明找到了一种方案
res.push_back(path);
return;
}
for (int i = startIndex; i < s.size(); i++) {
if (huiWenVec[startIndex][i] == false) continue;//如果不是回文,跳过,看看加上后面的字符是不是回文
string temp = s.substr(startIndex, i - startIndex + 1);
path.push_back(temp);
backtracking(s, i + 1, huiWenVec);
path.pop_back();
}
}
//动态规划,算出s中从i到j的子串是否是回文串
void isHuiWen(vector<vector<bool>>& huiWenVec, const string& s) {
for (int i = huiWenVec.size() - 1; i >= 0; i--) {
for (int j = i; j < huiWenVec.size(); j++) {
if (s[i] == s[j]) {
if (i == j || j - i == 1) huiWenVec[i][j] = true;
else huiWenVec[i][j] = huiWenVec[i + 1][j - 1];
}
}
}
}
};
时间复杂度: O(n * 2^n):回溯是2^n,for 循环是 n,去掉了判断回文的 isHuiWen 函数,并且 substr 执行的次数也少了,不是每次都执行,只有满足条件才执行
空间复杂度: O(n^2)
复原 IP 地址
题目

题解
这个题目和分割回文串差不多
class Solution {
public:
vector<string> restoreIpAddresses(string s) {
backtracking(s, 0);
return res;
}
private:
vector<string> res;
vector<string> path;//用vector<string>更方便
void backtracking(const string& s, int stratIndex) {
if (path.size() > 4) return;
//将vector换成string并加入res
if (stratIndex == s.size() && path.size() == 4) {
string temp;
for (string ele : path) {
temp += ele;
temp += ".";
}
temp.pop_back();
res.push_back(temp);
return;
}
for (int i = stratIndex; i < s.size(); i++) {
string temp = s.substr(stratIndex, i - stratIndex + 1);
if(isIP(temp) == false) continue;
path.push_back(temp);
backtracking(s, i + 1);
path.pop_back();
}
}
//检查分割的子串是否合格
bool isIP(const string& temp) {
if (temp.size() > 1 && temp[0] == '0') return false;
if (temp.size() > 3) return false;
int tempInt = stoi(temp);
if (tempInt < 0 || tempInt > 255) return false;
return true;
}
};
时间复杂度:O(n * 2^n) 到 O(n^2 * 2^n) 之间:因为有一个取 substr,时间复杂度是 O(temp.size())
子集
题目

题解
组合问题和分割问题都是收集树的叶子节点,而子集问题是找树的所有节点
并且子集{1,2} 和 子集{2,1}是一样的
所以 for 循环需要从 startIndex 开始,而不是从0开始。一般是排列问题是从0开始的
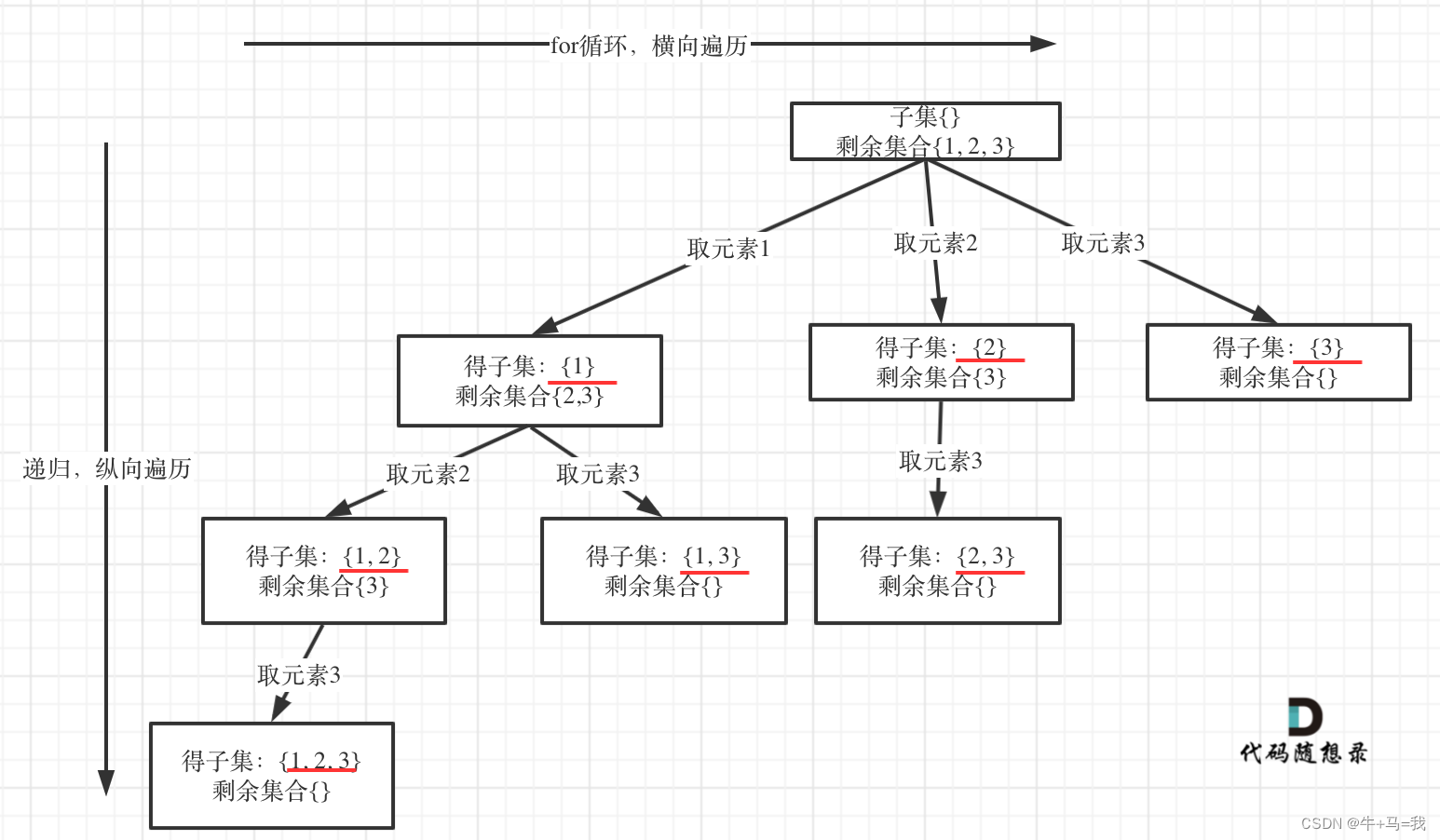
遍历这个树的时候,把所有节点都记录下来,就是要求的子集集合
所以 求取子集问题,不需要任何剪枝!因为子集就是要遍历整棵树
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
backtracking(nums, 0);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
res.push_back(path);//不用return,因为所有的情况(所有节点)都符合,需要遍历到所有的子节点
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
};
时间复杂度: O(n * 2^n)
空间复杂度: O(n)
子集 II
题目
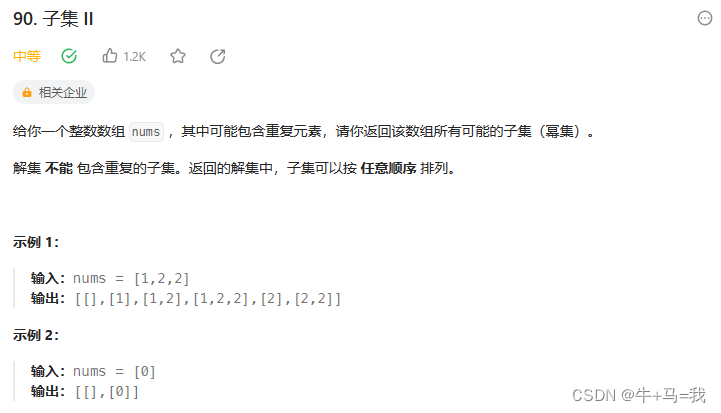
题解
这个题其实就是在上个题的基础上加上了 树层不重复,树枝可重复
所以加上 used 数组即可
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);//需要used数组进行树层去重
backtracking(nums, 0, used);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex, vector<bool> used) {
res.push_back(path);
for (int i = startIndex; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, i + 1, used);
path.pop_back();
used[i] = false;
}
}
};
时间复杂度: O(n * 2^n)
空间复杂度: O(n)
当然也可以 unordered_set 去重
这个 uset 只负责这一层,因此遇到这一层的元素就插入,后续就可以对 uset 进行 find 查找看看元素是否在 uset 中,如果在,那么说明树层重复,则跳过
需要注意的是 uset 不参与回溯,因为 uset 就是记录树层的元素,如果回溯,则记录就没了
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
backtracking(nums, 0);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
res.push_back(path);
unordered_set<int> uset;//树层去重用的
for (int i = startIndex; i < nums.size(); i++) {
if (uset.find(nums[i]) != uset.end()) continue;//如果uset中找到了nums[i],说明上个树层用过了nums[i]
path.push_back(nums[i]);
uset.insert(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
//uset不用回溯,因为uset就是记录之前用的nums[i]的,回溯了就没记录了
}
}
};
递增子序列
题目

题解
首先这个题,不允许树层重复
其次这个题,不允许排序,因此不能使用 used 数组来进行去重
所以只能用 unordered_set 来去重:
这个 unordered_set\<int> uset 只负责这一层,因此遇到这一层的元素就插入,后续就可以对 uset 进行 find 查找看看元素是否在 uset 中,如果在,那么说明树层重复,则跳过
需要注意的是 uset 不参与回溯,因为 uset 就是记录树层的元素,如果回溯,则记录就没了
class Solution {
public:
//树枝可重复,树层不可重复
vector<vector<int>> findSubsequences(vector<int>& nums) {
backtracking(nums, 0);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, int startIndex) {
if (path.size() >= 2) res.push_back(path);
unordered_set<int> uset;
for (int i = startIndex; i < nums.size(); i++) {
if (uset.find(nums[i]) != uset.end()) continue;//同树层不重复
if (path.size() >= 1 && nums[i] < path[path.size() - 1]) continue;//小于前一个元素的不加进去
path.push_back(nums[i]);
uset.insert(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
//注意uset不能回溯
}
}
};
时间复杂度: O(n * 2^n)
空间复杂度: O(n^2):系统栈是O(n),uset是O(n)
优化:题目中说明了 -100 <= nums[i] <= 100,因此可以直接使用 int hash[201] = {0};来代替 uset
防止 uset 频繁的 insert 和 hash映射 浪费时间,因为 insert 时底层有时候也会扩充,做 hash 映射时需要根据 key 算 hash function 的映射值,这都需要时间
所以直接用数组做哈希会更快
全排列
题目

题解
这是排列问题,是有序的,也就是说 [1,2] 和 [2,1] 是两个集合
元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了,每次都从0开始
但是需要一个 used 数组记录之前遍历的元素,防止 path 中加入重复的元素,比如不能出现[1, 1],因为1已经加过了,第二位就不能加1了
class Solution {
public:
vector<vector<int>> permute(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used) {
if (path.size() == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue;//说明这个元素已经选过了,不能再选了
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
};
时间复杂度: O(n!),排列一般就是阶乘的复杂度
空间复杂度: O(n)
全排列 II
题目

题解
这道题就是在 全排列 的基础上添加了重复的元素
因此需要树层去重
class Solution {
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return res;
}
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used) {
if (path.size() == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;//树层重复,不添加
if (used[i]) continue;//这个元素在上一层已经添加过了,不能再加了
path.push_back(nums[i]);
used[i] = true;
backtracking(nums, used);
path.pop_back();
used[i] = false;
}
}
};
时间复杂度: O(n!),排列一般就是阶乘的复杂度
空间复杂度: O(n)
重新安排行程
题目
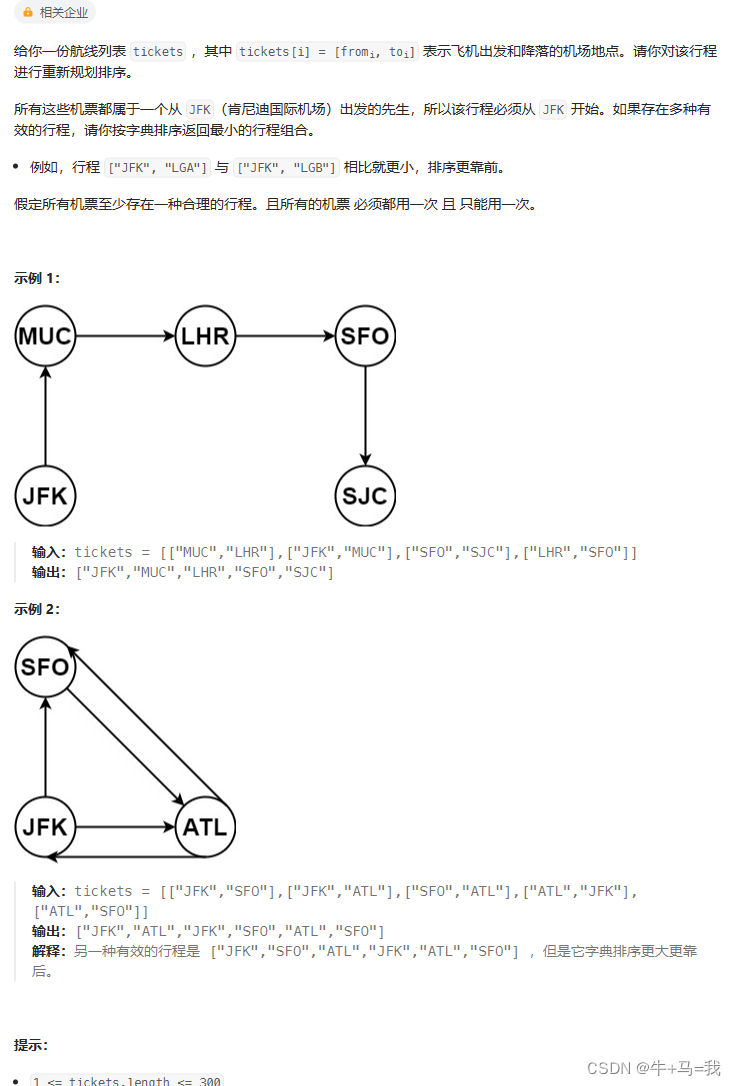
题解
首先为了方便遍历,可以将 tickets 放入到 unordered_map<string, map<string, int>> 这个容器中,表示 <from, <to, num>> 即 <起始位置, <终止位置, 数字>>,这个数字如果是1表示没有加入到 path,如果是0表示加入到了 path
这样的话后续每次就不用遍历整个 vector<vector<string>>& tickets 了,直接遍历对应索引的 value 即可,比如 path 最后一个元素是 “JKF”,表示下一次只需要遍历以 “JKF” 开头的小组即可,即 “JKF” 这个 key 对应的 value:map<string, int>
并且 unordered_map 中用的是 map,因为需要对 string 进行排序,这样如果能找到一条轨迹,那么就是最小轨迹了,后面的不用再找了
取的时候,可以通过 for (pair<const string, int>& ele : fromToNum[path.back()]) 来取
这里面有很多要点:
- 用pair来接收 map,因为后面需要将 pai r的 first 加入到 path 中
path.push_back(ele.first),如果是 map 的话,很难取出 key - 必须是引用拷贝,因为后面 ele.second 需要进行 + +和 - - 操作,操作完之后fromToNum中也得更改
- 必须加 const,因为是引用拷贝,编译器为了防止 map 中的 key 被修改,因此需要加上 const,表示 key 不能修改
- 这种取出 unordered_map 中 key 对应的所有 value 的方法需要记住
- 可以直接用 auto 来代替 pair<const string, int>,比如:
for (auto& ele : fromToNum[path.back()])
这道题还有其他的一些要点:
这道题 path 就是 res,因为只需要找到一条轨迹,不用收集
对于只找一条轨迹,返回值是bool,方便找到后快速放回,防止一直遍历没用的结果
class Solution {
public:
vector<string> findItinerary(vector<vector<string>>& tickets) {
//将tickets放入到unordered_map<string, map<string, int>>
for (vector<string> ele : tickets) {
fromToNum[ele[0]][ele[1]]++;
}
path.push_back("JFK");
int num = tickets.size();
backtracking(num);
return path;
}
private:
vector<string> path;//这道题path就是res,因为只需要找到一条轨迹,不用收集
unordered_map<string, map<string, int>> fromToNum;
bool backtracking(int num) { //对于只找一条轨迹,返回值是bool,方便找到后快速放回
if (path.size() == num + 1) return true;//终止条件
for (pair<const string, int>& ele : fromToNum[path.back()]) {
if (ele.second == 0) continue;//说明访问过了,需要跳过
path.push_back(ele.first);
ele.second--;
if (backtracking(num)) return true;
path.pop_back();
ele.second++;
}
return false;
}
};
以下是我之前写的代码,以前可以通过,现在再运行就超时了,所以还是推荐用上面的代码
class Solution {
public:
vector<string> findItinerary(vector<vector<string>>& tickets) {
sort(tickets.begin(), tickets.end(), letterSort);//先排序,这样找到的第一条轨迹就是最小轨迹
path.push_back("JFK");
vector<bool> used(tickets.size(), false);
backtracking(tickets, used);
return path;
}
private:
vector<string> path;
bool backtracking(vector<vector<string>>& tickets, vector<bool>& used) {
if (path.size() == tickets.size() + 1) return true;
for (int i = 0; i < tickets.size(); i++) {
if (path.back() != tickets[i][0]) continue;//起点和重点不衔接,直接跳过
if (used[i] == true) continue;//这个组已经用过了,跳过
path.push_back(tickets[i][1]);
used[i] = true;
if (backtracking(tickets, used)) return true;;
path.pop_back();
used[i] = false;
}
return false;
}
static bool letterSort(vector<string>& a, vector<string>& b) {
if (a[0] == b[0]) return a[1] < b[1];
return a[0] < b[0];
}
};
N 皇后
题目

题解
继组合、切割、子集、排列问题之后,现在这道题包括下到题都是棋盘问题
行数决定了递归的深度,列数决定了 for 循环遍历的多少
这道题的约束条件是:
不能同行
不能同列
不能同斜线
所以需要一个函数去判断添加的 ‘Q‘ 是否符合约束

因为是递归是一行一行的,for 循环是一列一列的,所以只有检验 左方、上方、左上方、右上方 是否有 ’Q’即可
class Solution {
public:
vector<vector<string>> solveNQueens(int n) {
vector<string> path(n, string(n, '.'));//这个初始化没写出来,可以看看
backtracking(path, n, 0);
return res;
}
private:
vector<vector<string>> res;
//x是行数,y是列数
void backtracking(vector<string>& path, int n, int x) {
if (x == n) { //行数到n,说明递归到最后了,收集结果并终止
res.push_back(path);
return;
}
for (int y = 0; y < n; y++) {//递归是行数,for循环是列数
if (isValid(path, n, x, y) == false) continue;
path[x][y] = 'Q';
backtracking(path, n, x + 1);
path[x][y] = '.';
}
}
bool isValid(vector<string>& path, int n, int x, int y) {
//找左方同行的
for (int j = y; j >= 0; j--) {
if (path[x][j] == 'Q') return false;
}
//找上方同列的
for (int i = x; i >= 0; i--) {
if (path[i][y] == 'Q') return false;
}
//找左上方斜线的
for (int k = 1; x - k >= 0 && y - k >= 0; k++) {
if (path[x - k][y - k] == 'Q') return false;
}
//找右上方斜线的
for (int k = 1; x - k >= 0 && y + k < n; k++) {
if (path[x - k][y + k] == 'Q') return false;
}
return true;
}
};
时间复杂度: O(n!)
空间复杂度: O(n)
时间复杂度解释:

这是递归过程,选完 n 之后,还有 n - 1 种选择,选完 n - 1 之后,还有 n - 2 种选择…
所以是 O(n!)
解数独
题目

题解
说个题外话,这道题面试肯定不会让手搓,笔试更不会考,最大面试让说一下解题思路。因为这道题的输入示例只有一个,如果受挫,直接按照结果写一个 board 即可
这道题是三维递归,和 N皇后 不一样
N皇后 是每一行每一列只放一个皇后,只需要一层 for 循环遍历一列,递归来遍历行,然后一行一列确定皇后的唯一位置
本题每个位置都要放数字,所以需要二维,而且每一个位置是 1 - 9 进行尝试,这有又一个循环,所以是三维递归,因此其实 递归函数中有三个 for 循环
首先需要清楚,递归函数返回值是 bool , 因为找到一个叶子节点就返回
不需要终止条件,因为要遍历整个树形结构寻找可能的叶子节点就立刻返回,什么时候到叶子节点呢?肯定是三层 for 循环遍历结束,那么整个棋盘就遍历完了,就找到了一个结果,从而结束
class Solution {
public:
// 三维递归
void solveSudoku(vector<vector<char>>& board) {
backtracking(board);
}
private:
bool backtracking(vector<vector<char>>& board) {
for (int row = 0; row < board.size(); row++) { // 遍历行
for (int col = 0; col < board.size(); col++) { // 遍历列
if (board[row][col] != '.') continue;
for (char num = '1'; num <= '9'; num++) {
if (isValid(board, i, j, num) == false) continue; //不满足条件,跳过
board[i][j] = num;
if (backtracking(board)) return true;
board[i][j] = '.';
}
return false;//9个数都试完了,仍找不到合适num填这个位置,需要return false进行回溯
}
}
return true;//运行到这说明找到了
}
bool isValid(vector<vector<char>>& board, int row, int col, char num) {
//检验同行是否有相同的数组
for (int i = 0; i < board.size(); i++) {
if (board[row][i] == num) return false;
}
//检验同列是否有相同的数组
for (int i = 0; i < board.size(); i++) {
if (board[i][col] == num) return false;
}
//检验同个小方块是否有相同的数组
int cubeX = (row / 3) * 3;//row/3代表是第几个小方块,再*3代表小方块开始的坐标。比如row=5,row/3=2代表是第二行的小方块,2*3=6代表这个小方块的起始坐标是6
int cubeY = (col / 3) * 3;
for (int i = cubeX; i < cubeX + 3; i++) {
for (int j = cubeY; j < cubeY + 3; j++) {
if (board[i][j] == num) return false;
}
}
return true;
}
};















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









