







Paper Title: From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
发布于:2025年3月2日发布在arXiv

基于身份引导的行人生成模型在三个数据集上展示了8种代表性姿势的可视化效果。
人物重识别(ReID)旨在提取准确的身份表示特征。
方法的核心思想是通过“特征集中化”来减少噪声和提高身份特征的稳定性,进而提高重识别的准确性。
具体来说,Pose2ID方法提出了两种创新机制:
-
身份引导的人物生成(IPG):利用人物的身份特征生成多种不同姿势的图像,从而增加训练样本的多样性,同时保持人物的身份一致性,即使在背景复杂、遮挡严重或使用不同模态(如红外图像)时,依然能确保生成图像的身份特征稳定。
-
邻域特征集中化(NFC):通过分析样本间的邻近关系,进一步增强样本的特征表示,使得相似样本的特征向量更紧密地聚集,从而提高模型对相同身份的区分能力。
行人重识别(ReID)是视频监控和安全领域中的一项关键任务,旨在匹配不同摄像头捕捉到的行人图像。本文提出了一种免训练的ReID框架,通过减轻特征噪声来增强身份表示。在训练过程中,具有相同身份的特征通过损失函数进行约束,自然地在特征空间中聚集在“身份中心”周围。
特别地,根据中心极限定理,当样本数量足够大时,这些特征将遵循以身份中心为均值的正态分布。
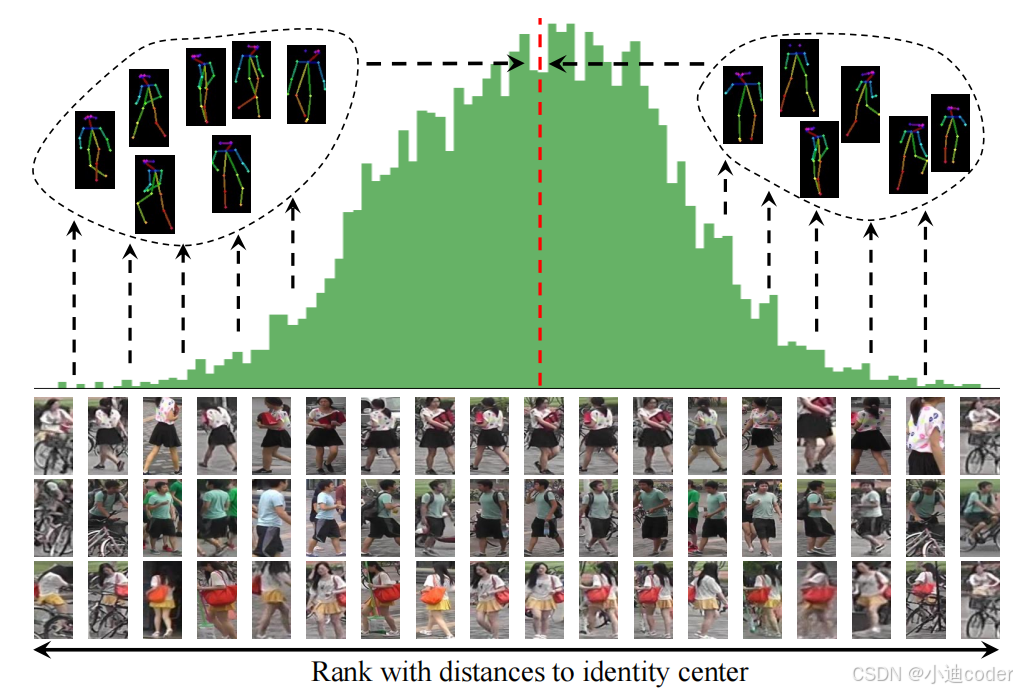
上图所示,我们可视化了一个身份的特征分布,并根据距离身份中心的远近对同一身份的样本进行排序。为了使每个样本的特征更能代表其身份,通过聚集相同身份的特征,我们可以减少个体样本中的噪声,加强身份特征,并使每个特征维度更接近其中心值。
- 背景和挑战:
- **人物重识别(ReID)**是计算机视觉中的一个关键任务,特别是在视频监控和安全领域。它的目标是能够准确地识别并匹配不同摄像头下拍摄的相同人物的图像。然而,由于噪声(如背景干扰、遮挡、图像质量差)和模型的局限性,传统的ReID方法面临着很大的挑战。
- 提出的解决方案(Pose2ID):
- 论文提出了一种无训练的ReID框架(Pose2ID),通过利用特征的自然聚集特性来增强身份表示,避免了需要大量训练的过程。具体来说,通过聚合相同身份的特征,减少噪声并增强特征的稳定性。这一方法依赖于特征集中化的思想,即将相同身份的样本特征靠近中心,从而增强模型对身份的识别能力。
- 创新点:
- 为了解决样本多样性不足的问题,文章提出了身份引导的人物生成(IPG),该方法通过生成具有不同姿势的图像来增加样本多样性,确保身份的一致性,尤其是在复杂场景中(如红外图像或图像遮挡)。
- 另外,论文提出了**邻域特征集中化(NFC)**方法,通过探索样本的邻域关系,进一步提高特征的表示质量,使模型能够更好地识别身份,即使在没有标签的情况下,也能发现潜在的正样
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3197
3197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









