







Papaer Title: Recent Advances in Multi-modal 3D Scene Understanding: A Comprehensive Survey and Evaluation
1. 研究背景
多模态3D场景理解的重要性:
结合3D点云与其他模态(如2D图像、自然语言)可以提升场景理解的丰富性和精准性,多模态方法在复杂环境(例如天气变化、场景动态变化等)中尤为重要。3D点云数据主要应用在自动驾驶,机器人导航,人机交互等领域。
多模态3D场景理解的任务与挑战:
3D+2D:通过融合Lidar点云和相机图像,实现更全面的3D环境感知。
3D+语言:结合自然语言描述与3D点云,增强用户交互性(视觉定位、问答、场景生成等)。
遇到的困难:Lidar点云与相机的模态差异,自然语言与3D几何信息的对齐复杂度,室内外场景复杂度。

上图是3D+2D 和 3D+语言场景理解代表性方法的分类(论文原图)
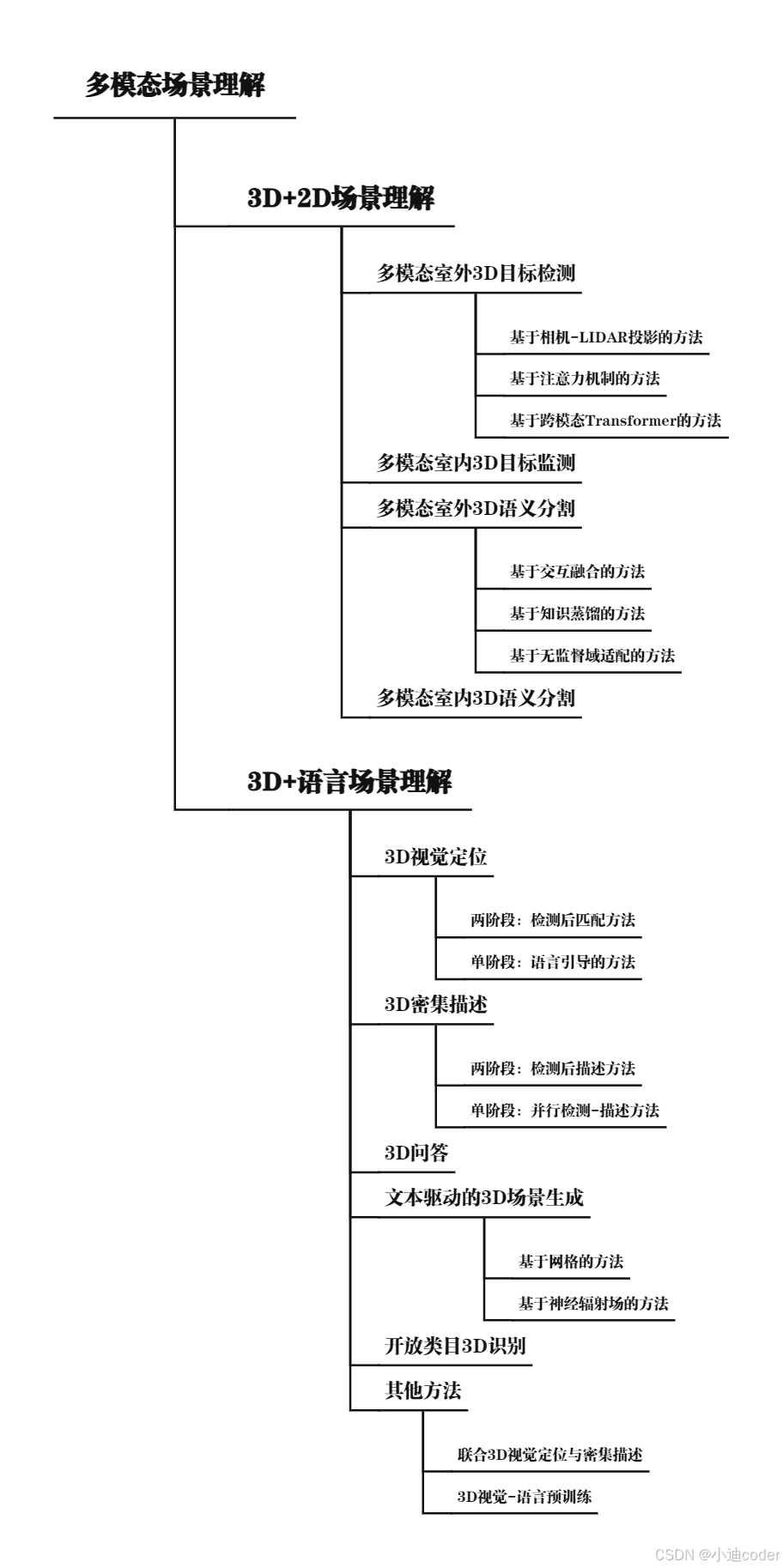
上图是3D+2D 和 3D+语言场景理解代表性方法的分类(手动绘制)
室内与室外场景使用领域区别:
从数据角度来看,室内场景理解方法的3D点云数据来自RGB-D扫描仪,而室外场景理解方法的3D点云数据则来自LiDAR传感器。
从应用角度来看,室内场景理解通常旨在帮助机器人了解场景中的内容以及物体在哪里。室外场景理解算法主要应用于自动驾驶,能够实时感知周围环境并判断每个物体的类型以规划交互。
2D+3D融合:可以提升3D点云数据下游任务性能。
语言+3D融合:文本可以引导生成复杂场景,通过提示词模型的泛化能力可以超出训练阶段标记的有限数量的基类。
2. 研究任务与挑战
(1)跨传感器校准
难点在于如何有效的将2D图像与3D点云数据融合,由于这两类数据是异构的,需要在聚合之间进行精准的对齐。点云转图像会失去几何信息,图像转点云会失去语义信息。
点云与图像融合的模型有:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









