







Paper Title:Magma: A Foundation Model for Multimodal AI Agents
Project Website: https://microsoft.github.io/Magma
该论文发布于2025年2月18日。
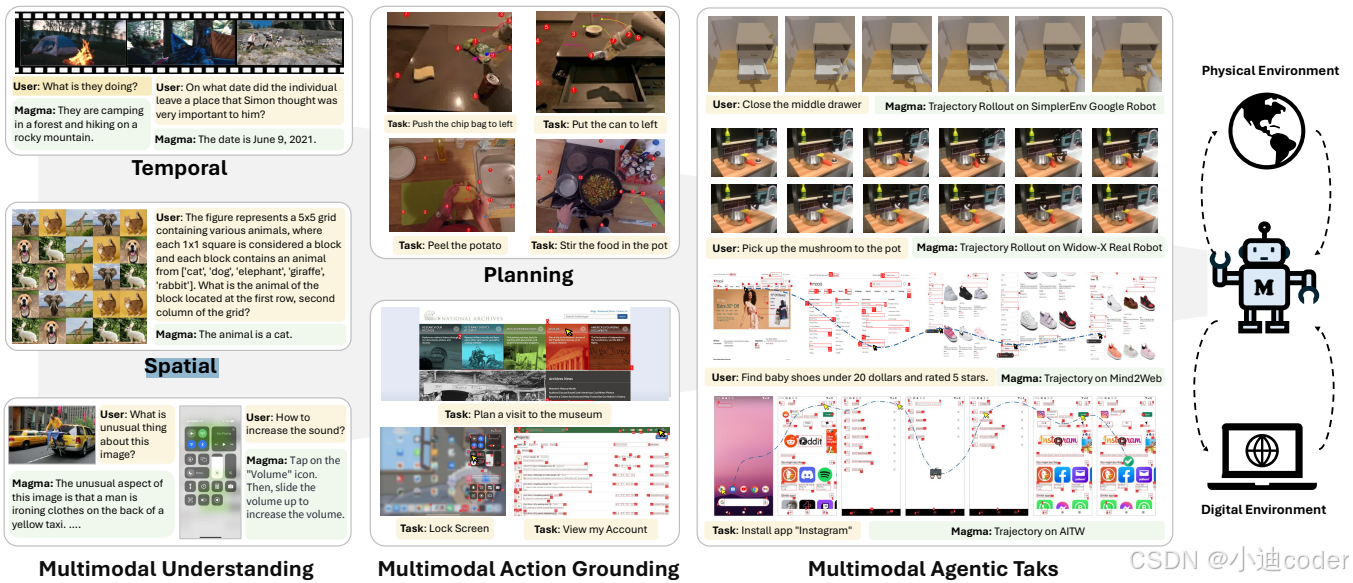
1. 多模态理解(Multimodal Understanding):给定一个场景,Magma可以回答图像描述的问题或从语言中理解问题。
2. 动作定位(Action Grounding):Magma能够通过Set-of-Mark(SoM)技术对可操作对象进行定位。
3. 动作规划(Action Planning):一旦理解了任务并定位了可操作的对象,Magma就能够通过Trace-of-Mark (ToM) 技术进行动作规划,预测任务执行的步骤和未来的动作。
VLA模型通常被分别训练,以简化问题,然后在不同任务中使用。
由于不同环境之间的固有差异(例如,2D数字世界与3D物理世界)
1. 在数字世界中的典型模型包括Pix2ACT、WebGUM和Ferret-UI用于UI导航。
2. 在3D物理世界中的VLA模型包括RT-2和Open-VLA用于机器人操作。
在本论文研究中,开发了一个基础模型,以便在数字和物理环境中执行多模态AI任务。
该模型需具备以下能力:
- 多模态理解:理解来自各个领域的多模态输入(包括数字和物理环境),不仅在语义上理解,而且在空间和时间上理解。
- 多模态动作预测:将长远的任务分解为一组准确的动作序列,这些动作可以被AI代理系统有效地执行。
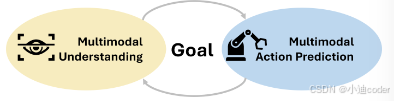
一个多模态AI智能体应该能够对给定目标进行多模态理解和行动预测。
为了赋予广泛的能力,利用了大量异构的视觉-语言和动作数据集:
- UI数据集(例如SeekClick)、
- 机器人操作数据集(例如OXE)、
- 人类教学视频数据集(例如Ego-4d)
- 用于LMM(大型多模态模型)的图像-文本配对数据
因为多模态理解(主要是语言的)与执行任务的动作(主要是空间的)之间存在显著差距。为了弥合这一差距,本论文提出了两种替代任务来进行模型训练:动作定位和动作规划。
问题定义:
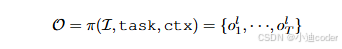
π表示多模态AI代理模型,是一个函数,I是视觉观察输入,task是任务描述,ctx是上下文信息。
输出O中的元素可能是语言符号,可能是空间符号。
此公式可以适用于不同的任务类型:
1. UI导航任务
2. 机器人操作任务
3. 多模态理解任务
在构建一个强大的多模态AI代理基础模型时,面临两个关键挑战:
-
预训练目标:如何构建一个统一的预训练接口以促进联合训练?
一个直接的方法是预测UI导航的2D坐标、机器人末端执行器的3D位置,以及视觉-语言任务的常规文本输出。然而,在我们的实验中&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









