






想要对大量图像进行简单处理,我们可以利用代码实现。
OpenCV作为开源的图像处理库,安装方便,容易上手,功能强大,受到了很多人的喜爱。
1.背景
-
笔者正在参加全国大学生智能汽车竞赛。由于放假在家,家中没有铺设赛道的条件,我找到了一款上位机,可以将智能车的图像导入到上位机中,上位机提供了在线调车功能,可以进行各种图像操作,将智能车的图像处理代码进行简单的修改,就可以在上位机中运行。
-
但是这款上位机对图片有尺寸和格式的要求:bmp格式图片,分辨率应该是在188*120以下。
-
在校调车期间,我购买了图传,将车辆运行时的图像实时传到电脑中,便于分析,所以电脑存有大量车辆运行中的图像。
-
但是传到电脑上的图为了便于观察,都自动进行了放大处理,放大了5倍。

-
所以我需要做三件事
-
1.将图片分辨率缩小5倍
-
2.将jpg格式图片转为bmp格式图片
-
3.将上述操作重复进行几万次
2.软件环境
使用win10+vs2017+OpenCV 4.1.1
vs2017与OpenCV安装配置过程略,csdn上有很多
(之前使用的是vs2020+OpenCV 4.6.0,出现了很多奇奇怪怪的bug,询问了一位大佬,修改到了上述版本)
3.代码
法一:利用glob函数读取文件夹内的所有图片
#include<iostream>
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/core/core.hpp>
#include<opencv2/opencv.hpp>
#include<math.h>
using namespace cv;
using namespace std;
int main()
{
Mat img_5min; //5倍缩放图
string InputPath = "D:\\Backup\\桌面\\原图\\*.jpg";//指定路径,精确到最后一个文件夹,图片带格式,名称用*
vector<String> InputFiles; //定义一个字符串数组作为输入文件
glob(InputPath, InputFiles);//用glob函数将输入路径与输入文件联系起来
if (InputFiles.size() == 0) //检验是否有图片
{
cout << "No image files[jpg]" << endl;
return 0;
}
for (int i = 0; i < InputFiles.size(); i++)//image_file.size()代表文件中总共的图片个数
{
Mat img = imread(InputFiles[i]);//读取图片
resize(img, img_5min, Size(img.cols / 5, img.rows / 5), 0, 0, INTER_NEAREST);//缩放
string OutputPath = "D:\\Backup\\桌面\\修改图\\" + to_string(i) + ".bmp";//存储路径,文件名,文件格式
imwrite(OutputPath, img_5min);//存储
imshow("src", img_5min);//显示一下
waitKey(5);//5ms后正常运行下一次
}
waitKey(0);
return 0;
}这也是我在网上找到的比较多的办法,利用glob函数读取文件夹内所有图片,记录数量遍历。
由于我需要将图片缩放,在其中加了一句,将读取到的图片长宽除以5,另存。
resize(img, img_5min, Size(img.cols / 5, img.rows / 5), 0, 0, INTER_NEAREST);//缩放5倍效果很好,文件格式,图片大小都和预想的一样,完成了修改。

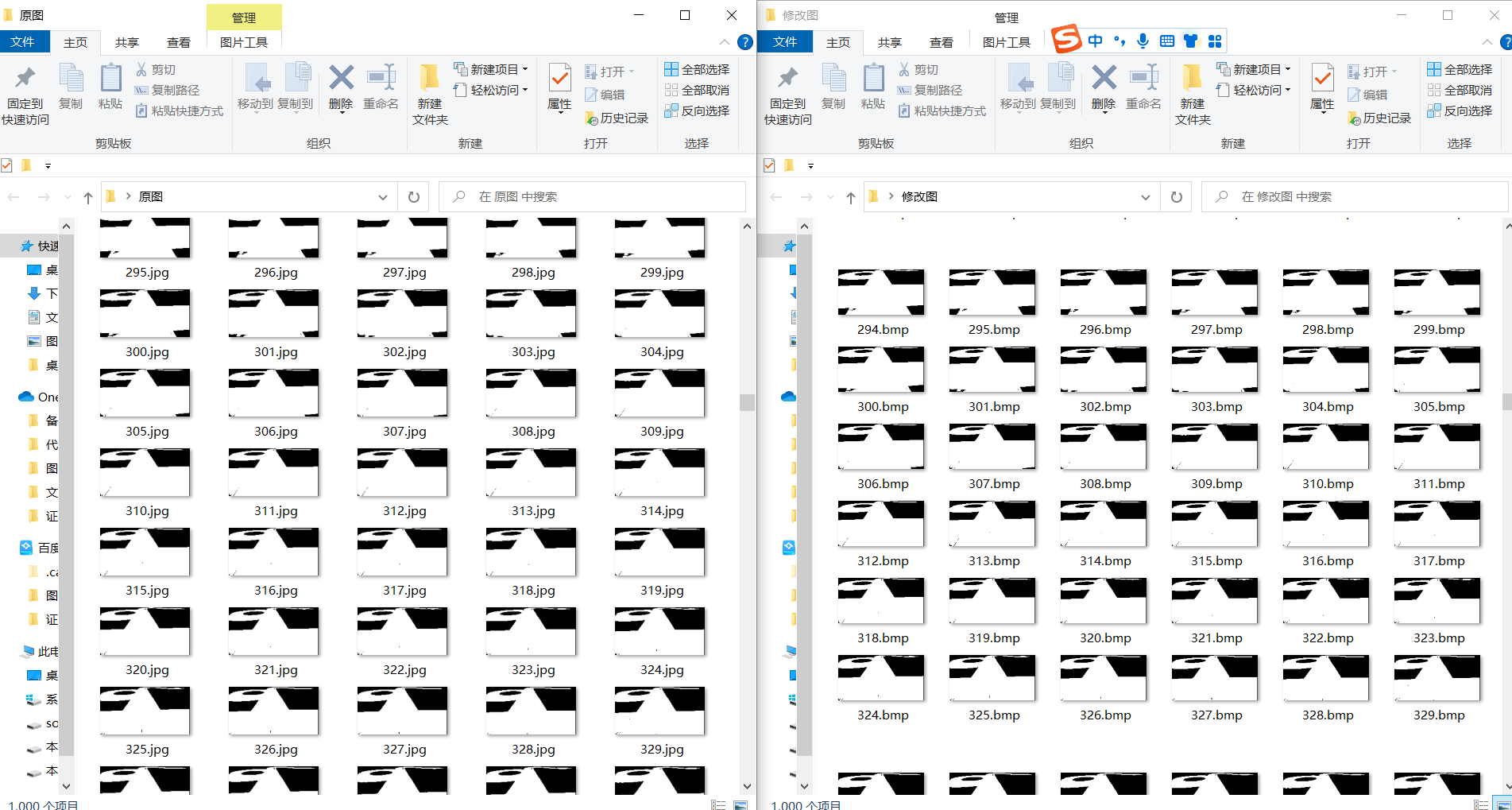
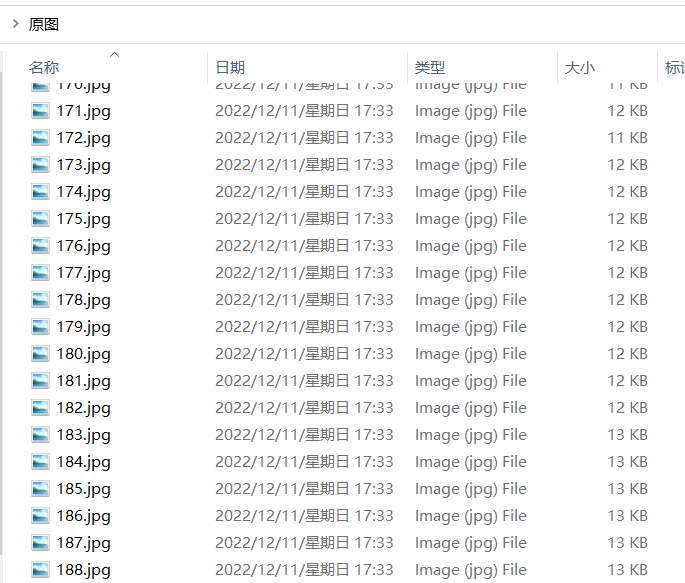
但是有个问题,看下面的图,这是我的原图集。

在修改过的图集中,顺序就改变了,相同的序号图片内容却不是一样的。貌似是有规律的变。

这组图对我来说就无法使用了,因为要想的是个动态过程,图片的顺序是有要求的。
于是我就观察了原始代码。
这套代码的核心就是读取目录中的图片,读取图片数量,然后遍历所有图,读一个,改一个,存一个,然后判断图像有没有访问完。
那么如果我知道图片数量,图片命名规律,我就知道每个图片的路径,是不是直接访问了呢?
答案是可以的
法二:修改访问路径批量操作图片
#include<iostream>
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/core/core.hpp>
#include<opencv2/opencv.hpp>
#include<math.h>
using namespace cv;
using namespace std;
int main()
{
Mat image; //原图
Mat image_5_min; //5倍缩放图
int i = 0;
for (i = 0; i < 1100; i++)
{
string InputPath = "D:\\Backup\\桌面\\原图\\" + to_string(i) + ".jpg";
image = imread(InputPath, 0);
if (image.data == nullptr)//nullptr是c++11新出现的空指针常量
{
cout << "名称应该为" << i << "的图片文件不存在" << endl;
break;
}
resize(image, image_5_min, Size(image.cols / 5, image.rows / 5), 0, 0, INTER_NEAREST);//五倍缩
string OutputPath = "D:\\Backup\\桌面\\修改图\\" + to_string(i) + ".bmp";
imwrite(OutputPath, image_5_min);
waitKey(5);
}
waitKey(0);
return 0;
}在运行之后效果很好。
相同的序号图片内容是一样的。
我的原图集的命名是连续的,0.jpg~999.jpg,修改访问路径可以很好遍历,只要命名是连续的,想要访问更多图片也只需要更改程序中for循环的条件而已,十分的方便。
对于图片命名是不是连续的情况,比如我让我的队友找了一下他电脑里的一些跑车时候存下来的图片,他发来的文件是这样的。、
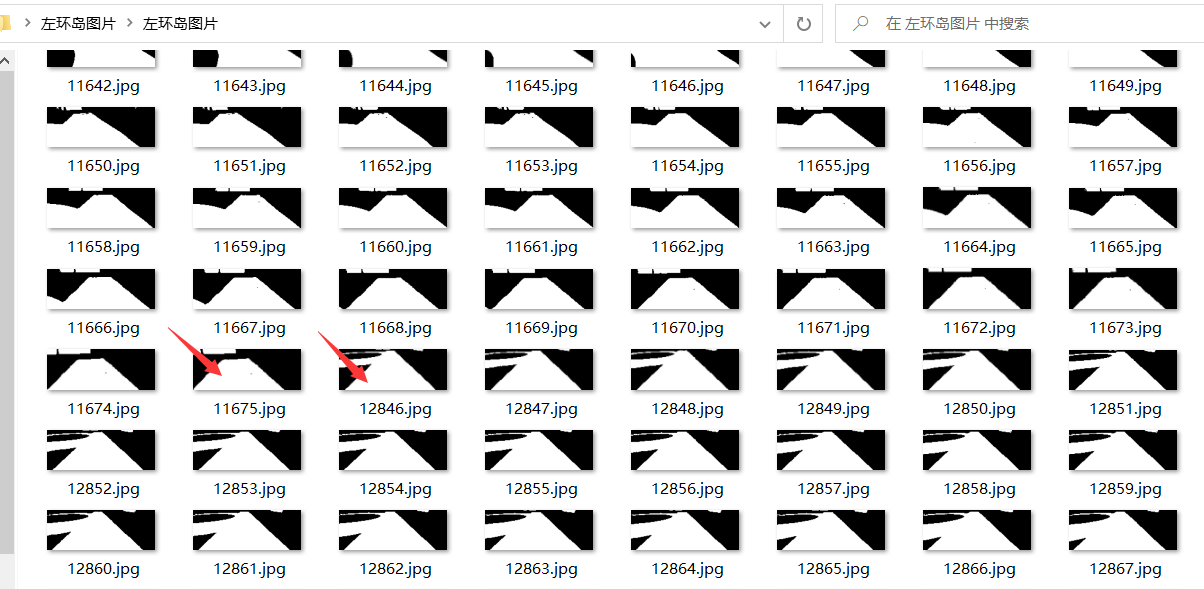
我第一次运行时候看着原图有800多张图片,用上面的程序跑完一遍只生成了300多张图片,提示我没有找到11676.jpg。感觉有点问题,不应该呀。我就看了一下文件,的确没有11676.jpg。
文件名从11675.jpg跳跃到了12846.jpg,显然我的队友只将一些片段截取了出来,他发给我的文件夹内有3段,文件名跳跃了2次,我又懒得找到每个跳跃的地方,记录跳跃起始点,结束点。
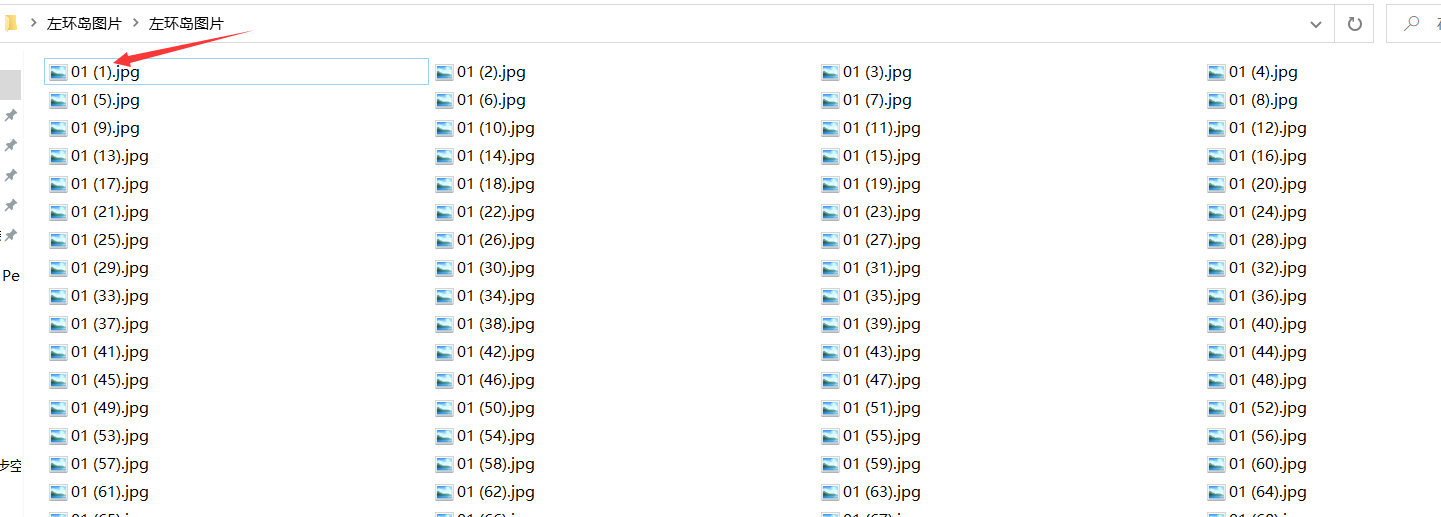
于是我灵机一动,选中第一张图片,再ctrl+a全选图片,将第一张图片重命名为01,按下enter。
结果如下,833个项目按照Windows的系统命名规则进行了重命名了。
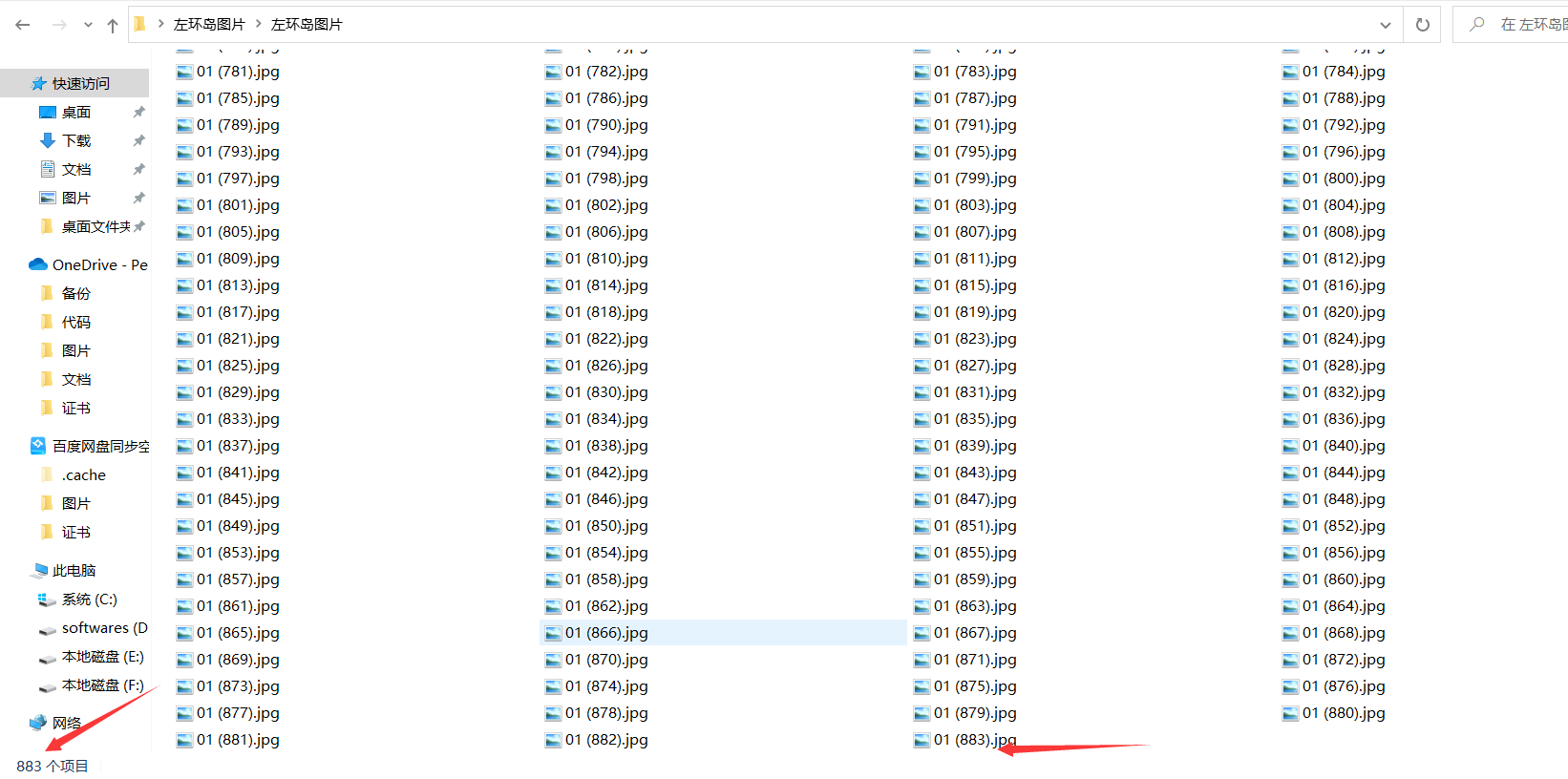
理论上无论多少图片,系统都会从01顺下去命名,这样我只需要将代码略加修改,就可以一次性修改所有的图片。
我只需要将代码中的路径按照上面的命名规则:01(i).jpg 进行改变路径即可,代码如下
#include<iostream>
#include<opencv2/highgui/highgui.hpp>
#include<opencv2/core/core.hpp>
#include<opencv2/opencv.hpp>
#include<math.h>
using namespace cv;
using namespace std;
int main()
{
Mat image; //原图
Mat image_5_min; //5倍缩放图
int i = 1;
for (i = 1; i < 1100; i++)
{
string InputPath = "D:\\Backup\\桌面\\左环岛图片\\左环岛图片\\01 (" + to_string(i) + ").jpg";
image = imread(InputPath, 0);
if (image.data == nullptr)//nullptr是c++11新出现的空指针常量
{
cout << "名称应该为" << i << "的图片文件不存在" << endl;
break;
}
resize(image, image_5_min, Size(image.cols / 5, image.rows / 3.5), 0, 0, INTER_NEAREST);//队友和我的图像不一样,缩放比例可以调整
string OutputPath = "D:\\Backup\\桌面\\修改图\\" + to_string(i) + ".bmp";
imwrite(OutputPath, image_5_min);
waitKey(5);
}
waitKey(0);
return 0;
}对比上面,改变其实只有一点,根据我文件夹的位置、命名规则,我改变了输入文件路径,让他变成了一个动态的输入路径。
string InputPath = "D:\\Backup\\桌面\\左环岛图片\\左环岛图片\\01 (" + to_string(i) + ").jpg";这样就可以非常优雅的批量修改图片。
4.总结
对于图像批量修改我们可以使用glob函数读取文件夹内所有图片,记录数量遍历。但是可能会造成文件乱序,对于顺序要求不高的可以使用。
也可以根据命名顺序,修改访问路径,进行批量修改。优点是不会乱序,但是需要文件名有规律。
最终也是实现了上位机读取图片,代码对图片进行分析,进行相关操作,从而仿真调车
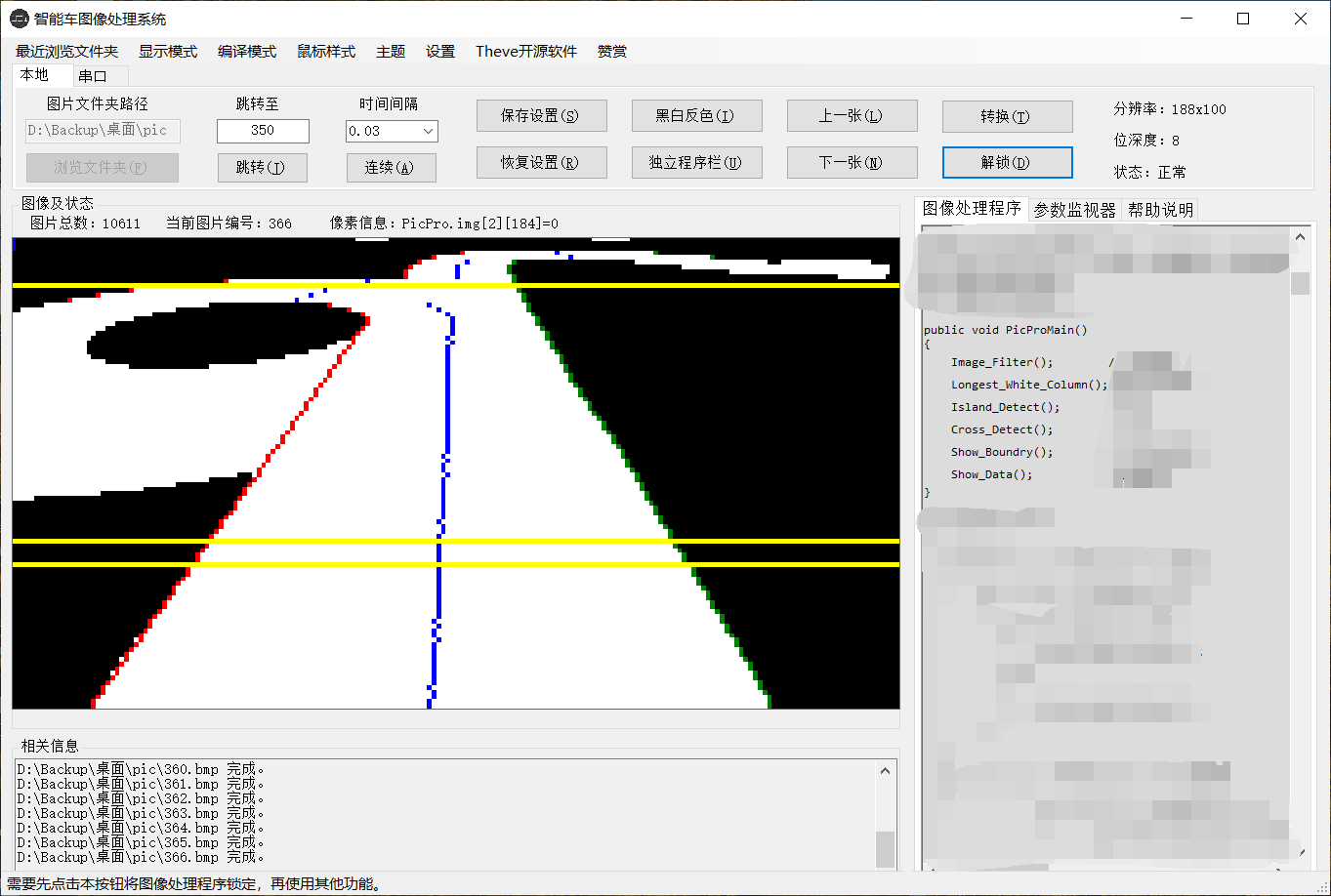
5.一些猜想和注意事项
5.1猜想
glob函数有可能根据文件大小,根据地址访问。原图中大小不一样,有可能造成访问某张个图片时发生了错误,序号标错了。
5.2注意事项
1.在vs2017运行,很容易出现正在加载符号,程序就会等着符号加载完在运行,很烦人,我也找了很多解决办法,效果不好,意外的发现有个很简单的好办法。
不要点击vs中间的本地Windows调试器,要使用ctrl+f5,就可以避免乱七八糟的符号加载。
原理貌似是按下本地Windows调试器是进行程序的调试,需要一些组件之类的东西支持,而ctrl+f5是运行而不调试,可以省略很多东西的加载。
2.文件夹路径都是双杠\\,因为单杠会被认为转义符,双杠才是\
希望对你有所帮助。
本人菜鸡一只,各位大佬发现问题欢迎留言指出。
qq:2296449414















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









