







ArkTS
ArkTs 是Harmonyos 优选的主力应用开发语言。arkTs 围绕应用开发在Typescript(简称 TS)生态基础上做了进一步扩展,继承了Ts的所有特性,是 TS 的超集。因此,在学习ArkTS语言之前,建议开发者具备S语言开发能力。
当前,ArkTS 在TS的基础上主要扩展了如下能力:
基本语法:ArkTS,定义了声明式U描述、自定义组件和动态扩展 UI 元素的能力,再配合AKUI开发框架中的系统组件及其相关的事件方法、属性方法等共同构成了UI 开发的主体。
状态管理:ArkTS 提供了多维度的状态管理机制。在UI开发框架中,与UI相关联的数据可以在组件内使用,也可以在不同组件层级间传递,比如父子组件之间、爷孙组件之间,还可以在应用全局范围内传递或跨设备传递。另外,从数据的传递形式来看,可分为只读的单向传递和可变更的双向传递。开发者可以灵活的利用这些能力来实现数据和UI的联动
渲染控制:ArkTS 提供了渲染控制的能力。条件渲染可根据应用的不同状态,渲染对应状态下的UI内容。循环渲染可从数据源中迭代获取数据,并在每次迭代过程中创建相应的组件。数据懒加载从数据源中按需迭代数据,并在每次迭代过程中创建相应的组件。
ArkTS基本语法
基本语法概述
在初步了解了 AEkTS 语言之后,我们以一个具体的示例来说明rkTs 的基不组成。该案例中当开发者点击按钮时,文本内容从“Helloworld”变为“Hello ArkUI工创建步骤如下
首先我们新创建一个项目MyApp02
在index.js文件当中
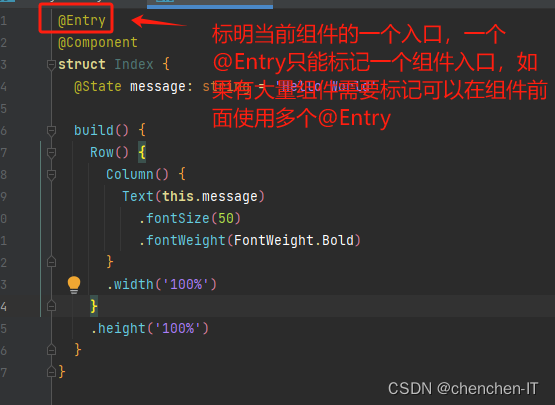

入口就是一打开App所看见的页面
@Entry
@Component
struct Index {
@State message: string = 'Hello World'
build() {
Row() {
Column() {
Text(this.message)
.fontSize(50)
.fontWeight(FontWeight.Bold)
}
.width('100%')
}
.height('100%')
}
}
// 所有带@符号的都属于装饰器
//
// Index是我们自定义的组件名称
//
// message: string 是定义的一个变量
//
// @State 装饰器 表示他是一个状态变量 (好处可以当变量的值发生变化的时候,变量所对应的组件页面会自动进行刷新)对应的Index组件
//
// build() 以声明式的的方式来描述UI结构
//
// Row()内置组件 代表一行
//
// Column()内置组件 表示一列
//
// Text(this.message):所要展示的值
//
// .fontSize(50) 显示的字体大小 单位是像素
//
// fontWeight 表示显示的字体
//
// width('100%') 表示Column() 这一列的宽占页面的100%
//
// height('100%') 表示build() 这一行的高 占页面100%实现一个简单点击按钮切换切换内容:
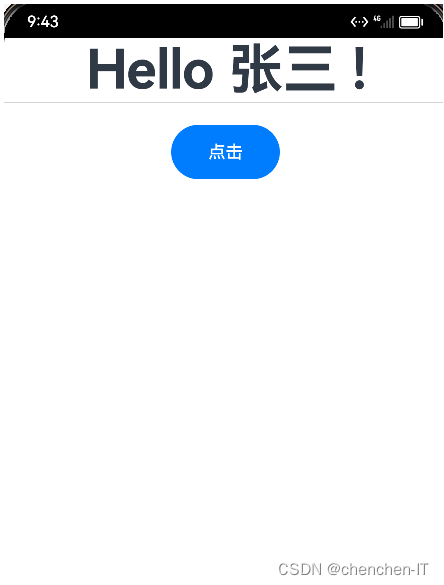
@Entry
@Component
struct Hello {
@State pweaon_name: string = '张三'
build() {
Row() {
Column() {
Text(`Hello ${this.pweaon_name} !`)
.fontSize(50)
.fontWeight(FontWeight.Bold)
Divider() //Divider() 提供分隔器的组件(系统组件)
Button('点击')
.onClick(() => { //点击箭头函数
this.pweaon_name = "李四" //点击一下给他重新赋值 然后因为@State监听pweaon_name所以会自动进行刷新
})
.height(50) //高
.width(100) //宽
.margin({ top: 20 }) //
}
}
}
}
使用模拟器进行运行之后:
基本内容
-
装饰器: 用于装饰类、结构、方法以及变量,并赋予其特殊的含义。如上述示例中@Entry、@Component和@state 都是装饰器,@Component 表示自定义组件,@Entry 表示该自定义组件为入口组件,@state表示组件中的状态变量,状态变量变化会触发 UI刷新。
-
UI 描述:以声明式的方式来描述 UI的结构,例如 build()方法中的代码块。←自定义组件:可复用的UI单元,可组合其他组件,如上述被@Component装饰的struct Hello。
-
系统组件:ArkUI框架中默认内置的基础和容器组件,可直接被开发者调用,比如示例中的Column、Text、Divider、Button。
-
属性方法:组件可以通过链式调用配置多项属性,如ontsize()、width()、height()、backgroundColor()等。
-
事件方法:组件可以通过链式调用设置多个事件的响应逻辑,如跟随在Button后面的 onclick()
-
系统组件、属性方法、事件方法具体使用可参考基于ArkTs的声明式开发范式。除此之外,ArkTS扩展了多种语法范式来使开发更加便捷:
-
@Builder/@BuilderParam:特殊的封装UI描述的方法,细粒度的封装和复用UI描述。
-
@Extend/@style:扩展内置组件和封装属性样式,更灵活地组合内置组件。
-
“statestyles:多态样式,可以依据组件的内部状态的不同,设置不同样式。
声明式UI概述
ArkTS以声明方式组合和扩展组件来描述应用程序的UI,同时还提供了基本的属性、事件和子组件配置方法,帮助开发者实现应用交互逻辑
如果组件的接口定义没有包含必选构造参数,则组件后面的“()”不需要配置任何内容。例如,Divider组件不包含构造参数:
Column() //无参数代码块
Text('item') //文本框的组件
Divider()//分割线的组件
@Entry //装饰器
@Component //自定义一个组件
struct UIText1{ //写组件内容
build(){//相当于一个组件小集合
Column(){
Text("Hello text1") //文本组件
Divider() //分割线组件
Text("Hello text2")
}
}
}编写完成之后
可以在右边查看效果

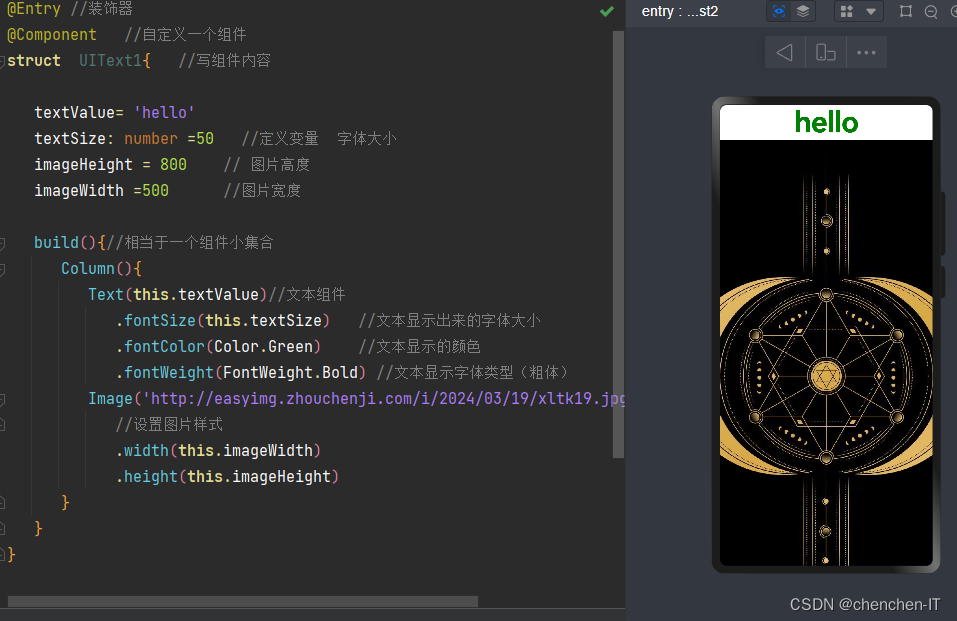
接下来我们练习一下有图片的样式
//有图片和文本的样式
@Entry //装饰器
@Component //自定义一个组件
struct UIText1{ //写组件内容
textValue= 'hello'
textSize: number =50 //定义变量 字体大小
imageHeight = 800 // 图片高度
imageWidth =500 //图片宽度
build(){//相当于一个组件小集合
Column(){
Text(this.textValue)//文本组件
.fontSize(this.textSize) //文本显示出来的字体大小
.fontColor(Color.Green) //文本显示的颜色
.fontWeight(FontWeight.Bold) //文本显示字体类型(粗体)
Image('http://easyimg.zhouchenji.com/i/2024/03/19/xltk19.jpg') //图片组件
//设置图片样式
.width(this.imageWidth)
.height(this.imageHeight)
}
}
}















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









