







ACM金牌带你零基础直达C语言精通-课程资料
本笔记属于船说系列课程之一,课程链接:ACM金牌带你零基础直达C语言精通
https://www.bilibili.com/cheese/play/ep159068?csource=private_space_class_null&spm_id_from=333.999.0.0
你也可以选择购买『船说系列课程-年度会员』产品『船票』,畅享一年内无限制学习已上线的所有船说系列课程:船票购买入口
做题网站OJ:HZOJ - Online Judge
Leetcode :力扣 (LeetCode) 全球极客挚爱的技术成长平台
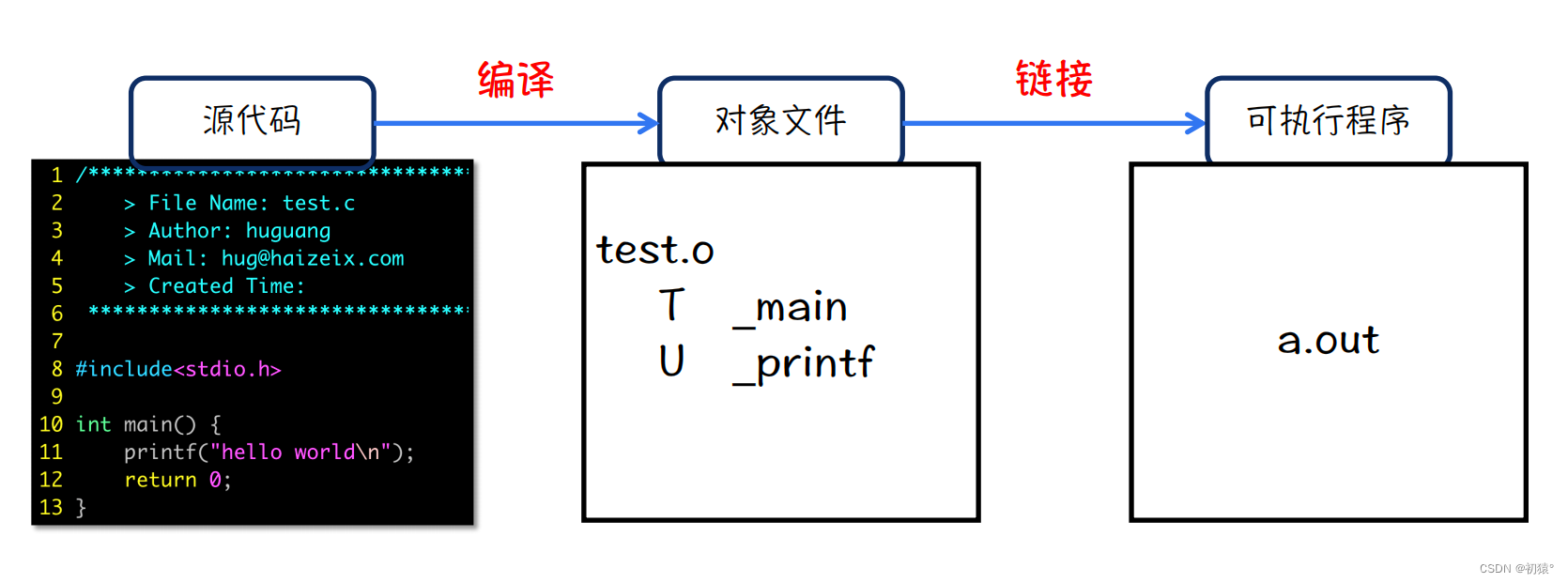
一.认识程序编译过程
第一步:源代码编译成为对象文件,在linux 下对象文件是以.o进行结尾的
在linux系统下命令行中执行
gcc -c 源代码文件名
就可以生成.o对象文件
第二步:如何执行链接阶段生成可执行程序
gcc 生成的.o文件名
执行后可以发现生成了a.out可以执行程序
执行程序:
对于编译和链接过程作用:
编译阶段:
语法错误:
1.语法格式错误:
没有分号:
少一个括号:
或者打错关键词等等;
2.未声明标识符:
b0写成了bo:
如何查看对象文件:
对于前面的大写字母理解:
T是表示函数的定义在当前对象文件中;U是需要在外部去查找定义的;
printf在系统库中,会自动去链接系统库;
链接阶段:
1.test1.c代码:
#include<stdio.h> int add(int, int); int main() { int a = 123, b = 456; printf("a + b = %d\n", a + b); printf("add(%d, %d) = %d\n", a, b, add(a, b)); return 0; }other.c:
#include<stdio.h> int add(int a, int b) { printf("[other.c] this is add function"); return a + b; }makefile文本:
test1: gcc -c 1.test1.c gcc -c other.c gcc other.o 1.test1.c利用make命令执行:
make 会执行 makefile里面的命令
这里发现1.test1.c中声明了add函数,在other.c中定义了add函数,这里就将1.test1.c链接了other.c,这样1.test1.c中调用了add函数,就不会发现链接阶段的错误,也就是定义缺失的错误。如果在1.test1.c中也实现了add函数,那么也会发生链接错误,也就是定义冲突。
总结:
记住这两句话就可以:
二.预处理命令家族
1.#include 头文件:
预处理命令都以#开头
对于在编译阶段之前还有一个阶段叫预处理阶段:
对于编译阶段检查的是待编译源码的错误
通过预处理阶段,待编译阶段会将#include中的内容和对应的功能作用会处理掉,变为待编译源码中的内容。
下面是代码演示:
5.pre_procesing.c
#include<stdio.h> int main() { printf("hello world"); return 0; }然后执行一个命令:
gcc -E 源代码文件名 > 定向文件
这句话的意思就是将5.pre_processing.c源代码,显示他的待编译源码,然后再将输出的内容重定向到output.c文件中
然后在output.c文件中可以看到许多在我们的源代码没有的内容,那就是#include <stdio.h>头文件替换的内容。
其实简单来说#include 做的就是复制和粘贴。
下面是对#include的作用展示:
#include <stdio.h> //这里包含了一个头文件def_a_b.c #include "def_a_b.c" int main() { printf("a + b = %d\n", a + b); return 0; }那么这里包含了def_a_b.c,就需要写源代码:
int a = 123, b = 456;然后进行查看他的待编译源码:
然后在待编译源码中可以看到:
第二行有int a, int b 的定义,以及赋值,也就是def_a_b.c中的那句代码,可以发现#include 做的就是粘贴和复制
编译后执行,发现是可以的;
对于#include <> 和 #Include "" 区别是,<>是在默认查找路径进行查找,""是在当前文件夹进行查找。
如何将自己的头文件添加到默认路径
需要执行的代码:
#include <stdio.h> #include <def_a_b.c> int main() { printf("a + b = %d\n", a + b); return 0; }
这局命令的意思就是将 ./(当前目录) 添加到默认路径,然后在对test.c进行编译。然后执行代码:
对于C语言有一个人文规定:
.c后缀为源文件
.h后缀为头文件
2.宏定义(#define)
程序展示宏定义的用法:
#include<stdio.h> #define PI 3.1415926 //这里为什么需要在(a) * (b),这里每个变量都要加上() //应为define的作用只是替换 //如果没有(), 对应下面的S(3 + 7, 4); 替换的结果就是3 + 7 * 4 //最终结果是31, 不是我们想要的(3 + 7) * 4的结果40 #define S(a, b) (a) * (b) #define s(a, b) a * b //定义多行宏时需要在每行末尾加上\进行续尾 #define P(a) {\ printf("define P : %d\n", a);\ } int main() { printf("PI = %lf\n", PI); printf("S(3, 4) = %d\n", S(3, 4)); printf("S(3 + 7, 4) = %d\n", S(3 + 7, 4)); //这里利用宏定义替换 //就相当于定义了一个int类型的指针p s(int, p); int a = 123; p = &a; P(*p); return 0; }待编译源码:
执行结果:
编译器中内置宏:
在程序中的使用方法:
#include<stdio.h> int main() { printf("__DATE__ = %s\n", __DATE__); printf("__TIME__ = %s\n", __TIME__); printf("__LINE__ = %d\n", __LINE__); printf("__FILE__ = %s\n", __FILE__); printf("__func__ = %s\n", __func__); printf("__PRETTY_FUNCTION__ = %s\n", __PRETTY_FUNCTION__); return 0; }执行结果:
宏定义中#和##的作用:
#的作用:将#后面的内容字符串化
##的作用: 将两个内容连接到一起,比如a##b,将a和b连接到一起
下面的代码演示:
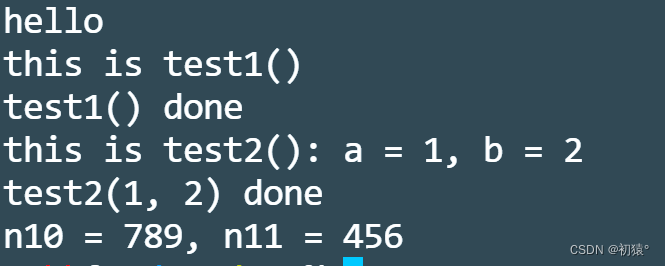
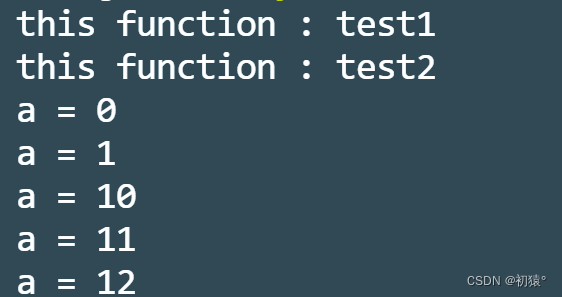
#include<stdio.h> #define STR(n) #n //这里的宏表示 执行func函数,并且打印func函数名以表func函数执行结束 #define RUN(func) {\ func;\ printf("%s done\n", #func);\ } //这个宏定义的作用是将a和b进行连接到一起 #define CAT(a, b) a##b void test1() { printf("this is test1()\n"); return ; } void test2(int a, int b) { printf("this is test2(): a = %d, b = %d\n", a, b); return ; } int main() { printf("%s\n", STR(hello)); RUN(test1()); RUN(test2(1, 2)); int n10 = 123, n11 = 456; CAT(n, 10) = 789; printf("n10 = %d, n11 = %d\n", n10, n11); return 0; }源代码截图:
待编译源码:
可以发现,之前用宏定义的代码全部被替换了。
执行结果:
3.条件编译(#if)
对于#ifdef的使用:
定义了DEBUG宏情况
#include<stdio.h> #define DEBUG #ifdef DEBUG int a = 1; #else int a = 2; #endif int main() { printf("a = %d\n", a); return 0; }待编译代码:
可以发现不满足的地方的代码被#ifdef裁掉了。
执行结果也显而易见了:
如果没有定义DEBUG宏,那么被裁掉的地方会是int a = 1;留下的是int a = 2;
如何在执行命令行阶段去定义宏:
gcc -D宏的名字 文件名
现在10.ifdef.c是没有定义DEBUG宏的。
通过句命令就可以在编译过程中定义DEBUG宏
执行结果:就是
三. 结构体
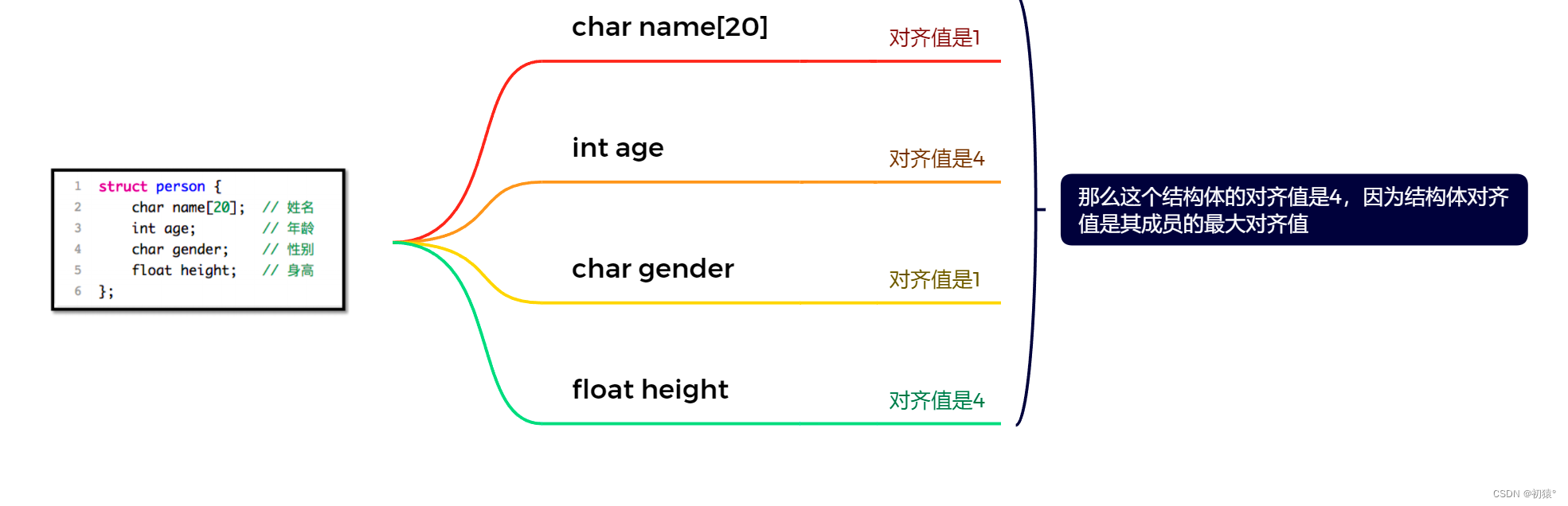
结构体(Struct)是一种在编程语言中用于组织和存储多个相关数据项的复合数据类型。它允许开发者将不同类型的数据项组合在一起,以便于在程序中一起操作和管理。
结构体通常由多个成员变量(也称为字段或属性)组成,每个成员变量可以是不同的数据类型,例如整数、浮点数、字符、数组、指针等。
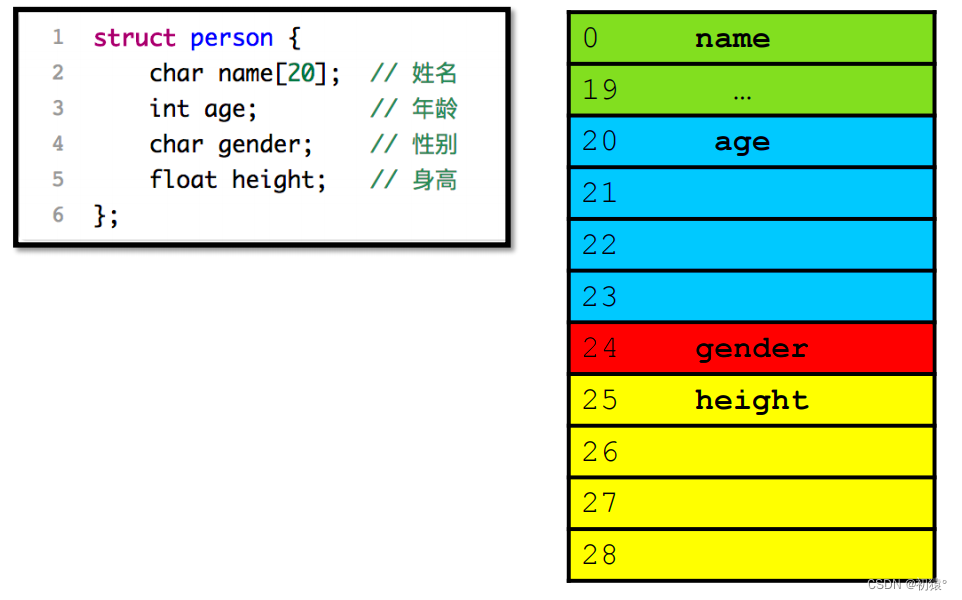
图中左边是结构体的定义,右边是结构体的内存图。
对于结构体定义和使用:
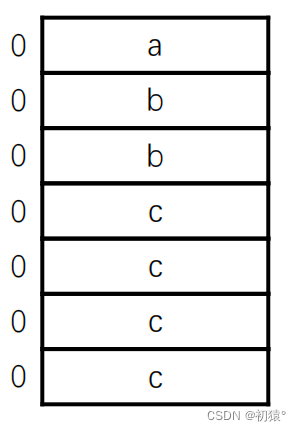
#include <stdio.h> #include <string.h> //定义结构体需要用struct关键字 typedef struct person { char name[20]; int age; char gender; float height; } person;//在前面加上typedef,就可以在最后定义别名,在下方定义结构体变量时,就可以用别名来定义 void output(struct person *p) { printf("use pointer p (%s, %d, %c, %f)\n", p->name, p->age, p->gender, p->height); return ; } //这个函数的作用是将结构体变量所占空间,转换为buff字符串来可见 //第一个参数用来转换的buff字符串 //第二个参数是结构体起始变量地址 //第三个参数是那个结构体变量的起始地址 //第四个参数是这个结构体变量的结束地址 //第五个参数替换的字符 void set_buff(char *buff, void *head, void *begin, void *end, char ch) { //循环判断条件, 当起始位置等于结束位置时结束 while (begin != end) { //这里变量的起始位置减去结构体起始的位置可以得到索引下标 buff[begin - head] = ch; begin += 1; } return ; } void output_person() { //开person结构体个大小的字符串 int n = sizeof(struct person), len = 0; char buf[n]; //初始化字符串内容为. for (int i = 0; i < n; i++) buf[i] = '.'; //打印对应位置索引 for (int i = 0; i < n; i++) { len += printf("%3d", i); } printf("\n"); //间隔符 for (int i = 0; i < len; i++) printf("-"); printf("\n"); //定义一个结构体变量 struct person hug; //name有20个字节大小所以从起始位置到结尾有20,并用'n'表示所占位置 set_buff(buf, hug.name, hug.name, 20 + (void *)hug.name, 'n'); set_buff(buf, hug.name, &hug.age, 4 + (void *)&hug.age, 'a'); set_buff(buf, hug.name, &hug.gender, 1 + (void *)&hug.gender, 'g'); set_buff(buf, hug.name, &hug.height, 4 + (void *)&hug.height, 'h'); for (int i = 0; i < n; i++) { printf("%3c", buf[i]); } printf("\n"); return ; } int main() { //定义结构体变量, 必须在前面加上struct关键字 //并初始化结构体中的变量 struct person hug = {"zhang san", 18, 'm', 2.1}; //利用结构体别名来定义结构体变量 person su = {"Su", 25, 'm', 1.6}; //hug.name这种以.的方式进行访问结构体中的变量叫做直接访问 printf("(%s, %d, %c, %f)\n", hug.name, hug.age, hug.gender, hug.height); //通过结构体指针访问结构体变量的方式叫做间接访问 output(&hug); output(&su); //查看person结构体占用的字节数 printf("sizeof(struct person) =%lu\n", sizeof(struct person)); //执行一个方法,标记每个结构体变量的在这32个字节中的位置 output_person(); return 0; }执行结果:
可以发现,结构体对应的内存大小不是所有变量对应字节大小进行相加来得到的,在下面的结构体内存对齐规则会讲到,为什么是这样。
结构体内存对齐规则:
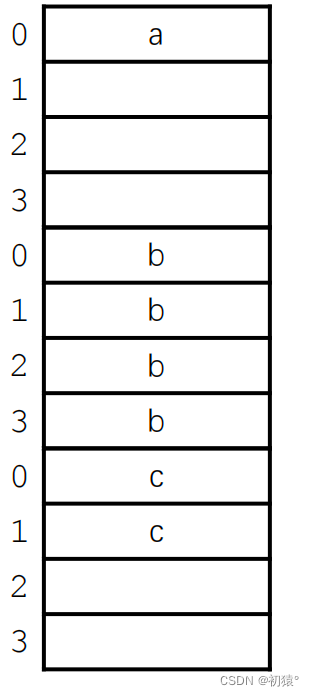
对于刚才代码的结构体进行分析:
这张图说明了1和2两点
然后第3点:
可以发现每个变量的起始位置分别是:
0,20,24,28是可以整除最大对齐值4的因为25-27是无法整除最大对齐值4的所以,25-27是空的。
对于这个图只是方便理解,计算机底层并不是这样去申请空间。
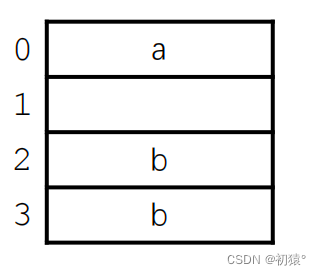
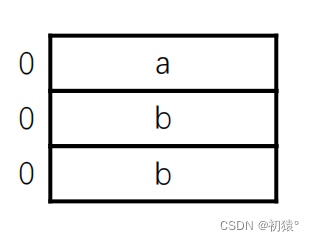
下面的3个结构体分别对应的大小是:
struct A : 12字节struct B:8字节
struct C:7字节
第一个很好理解;
第二个最大对齐值是4,先存char然后还有3个字节空间,然后short是两个字节可以存储,斌且要存储在能整除他的位置上,然后没有空间无法存int类型,需要重新申请一个空间,然后来存储int类型,最终是8字节。
第三个有一句代码#pragma pack(1),那么最大对齐值就被限制为1,所以就一个字节空间的开辟来进行存储,最后结果为7字节。
四.联合体
对于下面联合体所占空间只有4个字节大小:
对于上面的联合体代码是实现:
#include<stdio.h> #define P(a, format) {\ printf("%s = " format "\n", #a, a);\ } union A { struct { unsigned char byte1; unsigned char byte2; unsigned char byte3; unsigned char byte4; } bytes; unsigned int number; }; int main() { union A a; a.number = 0x61626364; P(a.number, "%x"); P(a.bytes.byte1, "%x"); P(a.bytes.byte2, "%x"); P(a.bytes.byte3, "%x"); P(a.bytes.byte4, "%x"); P(sizeof(union A), "%lu"); P(&a.number, "%p"); P(&a.bytes.byte1, "%p"); P(&a.bytes.byte2, "%p"); P(&a.bytes.byte3, "%p"); P(&a.bytes.byte4, "%p"); return 0; }执行结果:
可以发现,对number进行赋值后,对应结构体中的byte1~4的值也是对应的值;说明他们是公用的一块内存区域。对于为什么是倒过来存的是因为是小端系统,数字的地位存储在内存的低位。
不仅number可以对对应区域进行赋值和取值,bytes也可以。
五.枚举类型
如何运用枚举类型:
#include<stdio.h> #define P(a, format) {\ printf("%s = " format "\n", #a, a);\ } //从上往下进行自增+1 enum Number { zero, one, two = 10, three, four }; enum FUNC_DATA { #ifdef TEST1 FUNC_test1, #endif #ifdef TEST2 FUNC_test2, #endif #ifdef TEST3 FUNC_test3, #endif #ifdef TEST4 FUNC_test4, #endif //如果上面存在一个函数,那么FUNC_MAX 就会+1 //说明有存在几个函数 FUNC_MAX }; //利用宏定义,定义函数 #define DEFINE_FUNC(name)\ void name() {\ printf("this function : %s\n", #name);\ } DEFINE_FUNC(test1); DEFINE_FUNC(test2); DEFINE_FUNC(test3); DEFINE_FUNC(test4); //函数指针数组 //利用#ifdef来进行对函数指针数组进行存储 void (*func_arr[FUNC_MAX])() = { #ifdef TEST1 test1, #endif #ifdef TEST2 test2, #endif #ifdef TEST3 test3, #endif #ifdef TEST4 test4, #endif }; int main() { for (int i = 0; i < FUNC_MAX; i++) { func_arr[i](); } enum Number a; a = zero; P(a, "%d"); a = one; P(a, "%d"); a = two; P(a, "%d"); a = three; P(a, "%d"); a = four; P(a, "%d"); return 0; }如何进行对宏TEST进行添加
这个在#if中讲过,执行命令:
gcc后面可以跟多个参数添加宏
执行结果:
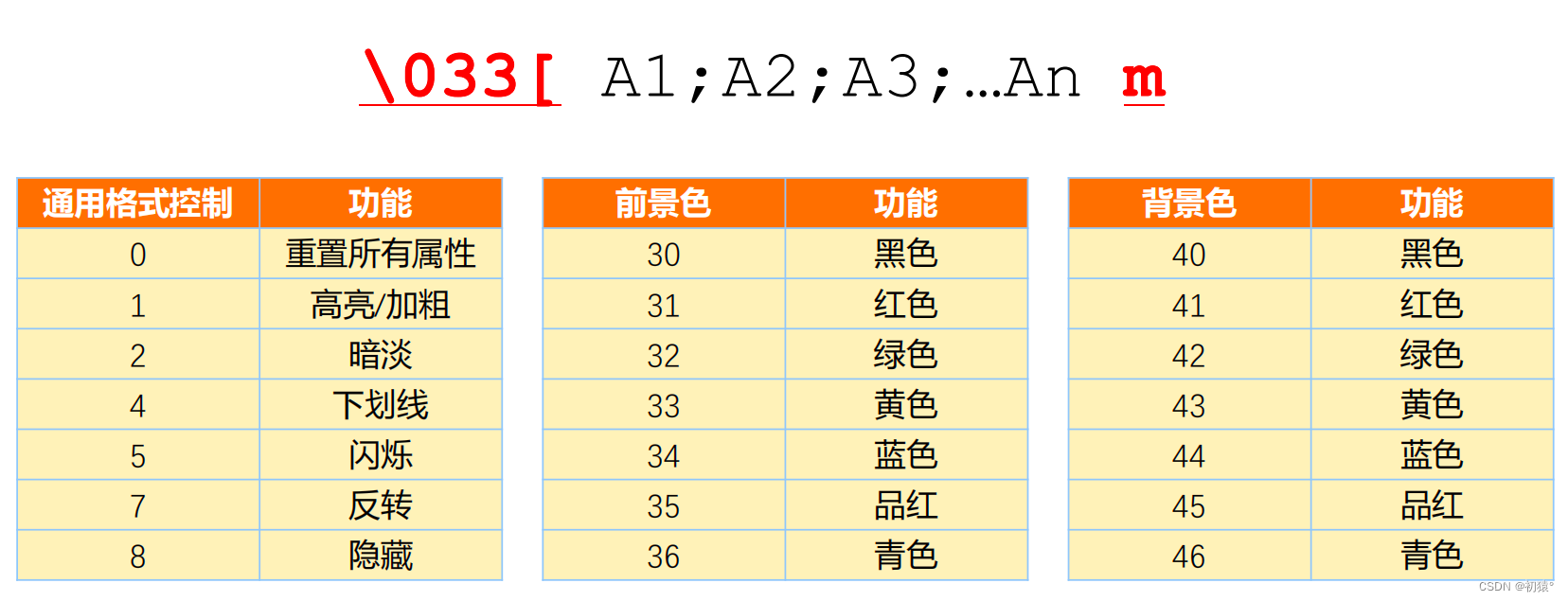
如何使用printf打印有颜色的字体
程序中如何运用:
#include<stdio.h> //对于这份代码,主要的是宏定义和枚举类型的运用 //大部分都是宏定义的内容,所以对于代码不懂,可以再回看关于宏定义的内容 #ifdef plana //利用宏定义进行封装collor工具 #define COLLOR(msg, code) "\033[1;" #code "m" msg "\033[0m" #define RED(msg) COLLOR(msg, 31) #define GREEN(msg) COLLOR(msg, 32) #define YELLOW(msg) COLLOR(msg, 33) #define BLUE(msg) COLLOR(msg, 34) int main() { //格式为\033[格式控制然后用;进行分隔跟上一个m,然后m后跟上需要打印的内容 //最后\033[0m表示讲字体格式和颜色进行初始化 //不然后面的字体都会变为你改变的颜色和格式 printf("\033[1;32;43mhello world\n\033[0m"); //使用宏定义进行输出带有演示的字体 printf(RED("hello world\n")); printf(GREEN("hello world\n")); printf(YELLOW("hello world\n")); printf(BLUE("hello world\n")); return 0; } #else //利用枚举类型进行封装color工具 enum COLOR_CODE { RED =31, GREEN, YELLOW, BLUE }; //利用宏定义封装输出信息 #define COLOR_SET "\033[1;%dm" #define COLOR_END "\033[0m" int main() { printf(COLOR_SET "hello color plan b\n" COLOR_END, RED); printf(COLOR_SET "hello color plan b\n" COLOR_END, GREEN); printf(COLOR_SET "hello color plan b\n" COLOR_END, YELLOW); printf(COLOR_SET "hello color plan b\n" COLOR_END, BLUE); //如果不懂下面的代码,可以再回看关于宏定义的内容 printf( COLOR_SET "hello " COLOR_SET "color " COLOR_SET "plan " COLOR_SET "b" "\n" COLOR_END, RED, GREEN, YELLOW, BLUE ); return 0; } #endif实现plana的方法:
执行结果:
实现planb的方法:
六.位域相关概念
直接程序理解:
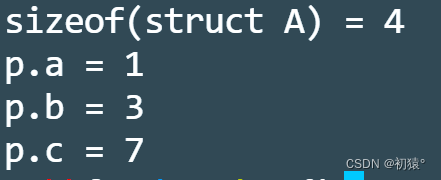
include<stdio.h> #define P(a, format) {\ printf("%s = " format "\n", #a, a);\ } struct A { //这里用到了无符号整形,有可能输出的结果都为-1,所以需要用到无符号 unsigned int a:1;//这里的代码说明a变量只用二进制的一位 unsigned int b:2;//同理 unsigned int c:3; //一共用了6位二进制 }; int main() { //由于struct A最大对齐值的4 //所以struct A占4字节 P(sizeof(struct A), "%lu");//4 struct A p; p.a = 15; p.b = 15; p.c = 15; //如果超出了占位的取值范围,那么只取后面几位,也就是低位 P(p.a, "%d");//因为只占用一位,所以对应二进制是1,输出结果结果为1 P(p.b, "%d");//因为只占用两位,所以对应二进制是11,输出结果结果为3 P(p.c, "%d");//因为只占用三位,所以对应二进制是111,输出结果结果为7 return 0; }在编译过程中有waring,只是警告的意思,但是依旧可以运行程序
执行结果:
章节小结:
理解程序的编译过程,在那些阶段会发现什么错误,以及每个阶段的作用是什么;
对于预处理,理解头文件是如何进行工作的,在后续的项目阶段会用上;对于宏定义一定要学会如何去使用,这样在以后编码的过程中可减少很多代码量。
结构体在后续数据结构中,是经常会用到的内容,基本每个结构都会用到结构体进行去封装,对于结构体内存的对齐规则一定要去理解其中是如何进行对齐的,这个内容在考试会考到。
联合体明白如何使用,知道这个东西,并且知道内存是如何进行公用就可以。
枚举类型学会后,在以后的编码过程中,学会去运用它,然编码的可读性和灵活性变得更高。
最后加油,看到这里你已经超过百分之95的人了。



















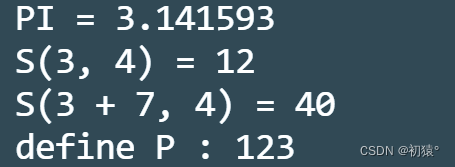








































 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











