







文章目录
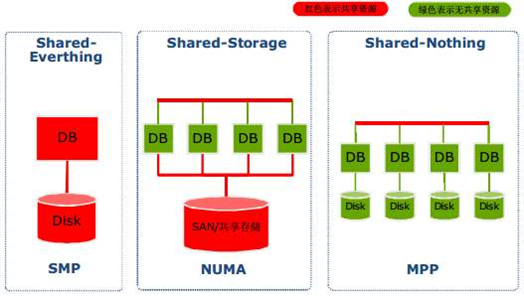
1、MPP数据库架构介绍
MPP(Massively Parallel Processing)就是大规模并行处理.
1、MPP的基本介绍
MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
2、MPP数据库架构模型介绍
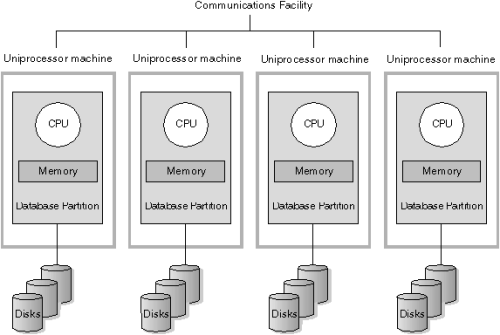
3、 MPP架构特征
任务并行执行;
● 数据分布式存储(本地化);
● 分布式计算;
● 私有资源;
● 横向扩展;
● Shared Nothing架构。
4、常见的MPP架构的数据库介绍
常见的MPP架构的数据库也有很多,例如像Greenplum,Elasticsearch,Presto,clickhouse等
5、MPP与hadoop的区别
https://blog.csdn.net/yimenglin/article/details/90510134
2、ClickHouse概述
1、ClickHouse基本简介
ClickHouse是俄罗斯的Yandex于2016年开源的列式存储数据库管理系统(DBMS:Database Management System),简称CK。
主要用于在线分析处理查询(OLAP:Online Analytical Processing)
能够使用SQL查询实时生成分析数据报表
ClickHouse官方文档:https://clickhouse.tech/docs/en/
2、ClickHouse的特性
真正的面向列的DBMS
数据压缩
磁盘存储的数据
多核并行处理
多个服务器上分布式处理
SQL支持
向量化引擎
实时数据更新
索引
支持在线查询
支持近似计算
数据复制和对数据完整性的支持
ClickHouse的不完美
没有完整的事务支持
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量修改或删除数据
稀疏索引使得clickhouse不适合通过其键检索单行的点查询
3、clickhouse的应用场景
OLAP场景关键特征:
大多数是读请求
数据总是以相当大的批(> 1000 rows)进行写入
不修改已添加的数据
每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
宽表,即每个表包含着大量的列
较少的查询(通常每台服务器每秒数百个查询或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小: 数字和短字符串(例如,每个UR60个字节)
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
事务不是必须的
对数据一致性要求低
每一个查询除了一个大表外都很小
查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
应用场景:
用于结构良好清晰且不可变的事件或日志流分析。
不适合的场景:
事务性工作(OLTP),高请求率的键值访问,低延迟的修改或删除已存在数据,Blob或文档存储,超标准化数据。
3、ClickHouse的安装部署
clickhouse官网并没有提供二进制或rpm安装包,但是Altinity公司提供了对应的rpm安装包,可以通过rpm方式去安装。
第一步:下载rpm包
下载地址:https://packagecloud.io/Altinity/clickhouse

第二步:上传rpm包
上传rpm包到服务器node01、node02、node03服务器上的/kkb/soft路径下
第三步:安装rpm包
每台节点安装下面的2个依赖
sudo yum install -y libtool
sudo yum install -y *unixODBC*
每台节点安装ck服务
cd /kkb/soft/
sudo rpm -ivh clickhouse*rpm

第四步:修改配置文件
修改config.xml
三台机器都修改配置文件
node01执行以下命令修改config.xml
sudo vim /etc/clickhouse-server/config.xml
将这一行注释文件给打开
<listen_host>::</listen_host>
将配置文件拷贝到其他机器上面去
sudo scp /etc/clickhouse-server/config.xml node02:/etc/clickhouse-server/
sudo scp /etc/clickhouse-server/config.xml node03:/etc/clickhouse-server/
创建metrika.xml
node01服务器创建metrika.xml
node01服务器的/etc 目录下新建metrika.xml文件
sudo vim /etc/metrika.xml
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<bip_ck_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node03</host>
<port>9000</port>
</replica>
</shard>
</bip_ck_cluster>
</clickhouse_remote_servers>
<!-- 本节点副本,不同的机器配置不同 -->
<macros>
<replica>node01</replica>
</macros>
<!-- ZK -->
<zookeeper-servers>
<node index="1">
<host>node01</host>
<port>2181</port>
</node>
<node index="2">
<host>node02</host>
<port>2181</port>
</node>
<node index="3">
<host>node03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 监听网络 -->
<networks>
<ip>::/0</ip>
</networks>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
node02服务器创建metrika.xml
node02服务器的/etc 目录下新建metrika.xml文件
sudo vim /etc/metrika.xml
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<bip_ck_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node03</host>
<port>9000</port>
</replica>
</shard>
</bip_ck_cluster>
</clickhouse_remote_servers>
<!-- 本节点副本,不同的机器配置不同 -->
<macros>
<replica>node02</replica>
</macros>
<!-- ZK -->
<zookeeper-servers>
<node index="1">
<host>node01</host>
<port>2181</port>
</node>
<node index="2">
<host>node02</host>
<port>2181</port>
</node>
<node index="3">
<host>node03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 监听网络 -->
<networks>
<ip>::/0</ip>
</networks>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
node03服务器创建metrika.xml
node03服务器的/etc 目录下新建metrika.xml文件
sudo vim /etc/metrika.xml
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<bip_ck_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node03</host>
<port>9000</port>
</replica>
</shard>
</bip_ck_cluster>
</clickhouse_remote_servers>
<!-- 本节点副本,不同的机器配置不同 -->
<macros>
<replica>node03</replica>
</macros>
<!-- ZK -->
<zookeeper-servers>
<node index="1">
<host>node01</host>
<port>2181</port>
</node>
<node index="2">
<host>node02</host>
<port>2181</port>
</node>
<node index="3">
<host>node03</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 监听网络 -->
<networks>
<ip>::/0</ip>
</networks>
<!-- 数据压缩算法 -->
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
给予权限
§ 说明:以下两个目录在安装完ck,且没有开始使用时,是不存在的
§ 如果后边在使用的过程中,出现权限问题,再给每台机器的目录授权(避免后面操作异常)
sudo chmod -R 777 /var/lib/clickhouse/data
sudo chmod -R 777 /var/lib/clickhouse/metadata
§ 搭建clickhouse过程中会生成对应的目录
配置文件路径:/etc/clickhouse-server/config.xml
日志文件路径:/var/log/clickhouse-server/
建表信息路径:/var/lib/clickhouse/metadata
分区数据路径:/var/lib/clickhouse/data
clickHouse默认是数据单副本的存在,这种情况下如果其中一台服务器宕机,那么就会造成数据丢失的问题,clickHouse也可以数据多副本的方式来实现对外提供高可用
https://www.cnblogs.com/grapelet520/p/11642273.html
3.2 ClickHouse的单机版安装部署
1.新建一个节点,上传四个rpm包。
2.安装
#安装依赖
sudo yum install -y libtool
sudo yum install -y *unixODBC*
#如果报错的话,安装以下依赖
sudo yum install libicu.x86_64
#安装ck服务
cd /kkb/soft/
sudo rpm -ivh clickhouse*rpm
4、clickHouse的启动与停止
ClickHouse的启动
先启动zookeeper集群
再在三台机器上面运行以下命令来启动clickHouse服务
sudo service clickhouse-server start
可以通过 ps -ef | grep clickhouse 命令查看ck是否启动成功
ps -ef | grep clickhouse
连接客户端
[hadoop@node01 bin]$ clickhouse-client
node01.kaikeba.com :) show databases;
SHOW DATABASES
┌─name────┐
│ default │
│ system │
└─────────┘
2 rows in set. Elapsed: 0.006 sec.
ClickHouse的服务停止
三台节点上执行命令
sudo service clickhouse-server stop
5、 命令行客户端连接ClickHouse
通过命令行来访问 ClickHouse,您可以使用 clickhouse-client
语法格式示例
clickhouse-client -m -u [username] -h [ip] --password [password] --port [port]
--user ``或者`` -u
用户名。 默认值: default。
--password
密码。 默认值:空字符串。
--host ``或者`` -h
服务端的 host 名称, 默认是 ‘localhost’
--port
连接的端口,默认值: 9000。
--multiline ``或者`` -m
如果指定,允许多行语句查询(Enter 仅代表换行,不代表查询语句完结)。
演示:开启多行查询
clickhouse-client -m 或者 clickhouse-client -multiline
6、数据类型
官网文档 https://clickhouse.tech/docs/en/sql-reference/data-types/
1 整型
固定长度的整型,包括有符号整型或无符号整型
· 整型范围
Int8 :[-128 : 127]
Int16:[-32768 : 32767]
Int32:[-2147483648 : 2147483647]
Int64:[-9223372036854775808 : 9223372036854775807]
Int256
· 无符号整型范围
UInt8 : [0 : 255]
UInt16: [0 : 65535]
UInt32: [0 : 4294967295]
UInt64: [0 : 18446744073709551615]
UInt256
2 浮点型
· Float32: float
· Float64: double
建议尽可能以整数形式存储数据。
例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
node01 :) select 1-0.9;
SELECT 1 - 0.9
┌───────minus(1, 0.9)─┐
│ 0.09999999999999998 │
└─────────────────────┘
· 与标准SQL相比,ClickHouse 支持以下类别的浮点数:
o inf 正无穷
node01 :) select 1/0;
SELECT 1 / 0
┌─divide(1, 0)─┐
│ inf │
└──────────────┘
o -inf 负无穷
node01 :) select -1/0;
SELECT -1 / 0
┌─divide(-1, 0)─┐
│ -inf │
└───────────────┘
o NaN 非数字
node01 :) select 0/0;
SELECT 0 / 0
┌─divide(0, 0)─┐
│ nan │
└──────────────┘
3 布尔型
· 没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
4 字符串
· String
o 字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
· FixedString(N)
o 固定长度 N 的字符串,N 必须是严格的正自然数。
o 当向ClickHouse中插入数据时
§ 如果字符串包含的字节数少于N, 将对字符串末尾进行空字节填充。
§ 如果字符串包含的字节数大于N, 将抛出Too large value for FixedString(N)异常。
o 与String相比,极少会使用FixedString,因为使用起来不是很方便。
5 枚举类型
· 包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系。
o Enum8 用 ‘String’= Int8 对描述。
o Enum16 用 ‘String’= Int16 对描述。
· 用法演示
o 创建一个带有一个枚举 Enum8('hello' = 1, 'world' = 2) 类型的列:
§ 客户端连接server端命令(–multiline表示开启多行查询)
§ clickhouse-client --multiline
CREATE TABLE enum_table(
x Enum8('hello' = 1, 'world' = 2)
)ENGINE = TinyLog;
o 这个 x 列只能存储类型定义中列出的值:'hello'或'world'。如果您尝试保存任何其他值,ClickHouse 抛出异常。
--插入数据
node01 :) INSERT INTO enum_table VALUES ('hello'), ('world'), ('hello');
--插入非'hello'或者'world'的数据
node01 :) INSERT INTO enum_table VALUES ('a');
INSERT INTO enum_table VALUES
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)
o 从表中查询数据时,ClickHouse 从 Enum 中输出字符串值
node01 :) select * from enum_table;
SELECT *
FROM enum_table
┌─────x─┐
│ hello │
│ world │
│ hello │
└───────┘
o 如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型。
node01 :) SELECT CAST(x, 'Int8') FROM enum_table ;
SELECT CAST(x AS Int8)
FROM enum_table
┌─CAST(x, \'Int8\')─┐
│ 1 │
│ 2 │
│ 1 │
└───────────────────┘
6 数组
Array(T)
由 `T` 类型元素组成的数组。
`T` 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能存储在 `MergeTree` 表中存储多维数组。
创建数组
可以使用array函数来创建数组
array[T]
也可以使用方括号
案例
node01 :) SELECT array(1, 2) AS x, toTypeName(x) ;
SELECT
[1, 2] AS x,
toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
node01 :) SELECT [1.1, 2.2] AS x, toTypeName(x);
SELECT
[1.1, 2.2] AS x,
toTypeName(x)
┌─x─────────┬─toTypeName([1.1, 2.2])─┐
│ [1.1,2.2] │ Array(Float64) │
└───────────┴────────────────────────┘
7 元组
· Tuple(T1, T2, …):元组,其中每个元素都有单独的类型。
· 创建元组
o 可以使用函数来创建元组
tuple(T1, T2, ...)
· 案例
node01 :) SELECT tuple(1,'a') AS x, toTypeName(x);
SELECT
(1, 'a') AS x,
toTypeName(x)
┌─x───────┬─toTypeName(tuple(1, \'a\'))─┐
│ (1,'a') │ Tuple(UInt8, String) │
└─────────┴─────────────────────────────┘
8 Date日期
· 日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值
CREATE TABLE dt
(
`timestamp` Date,
`event_id` UInt8
)
ENGINE = TinyLog;
INSERT INTO dt Values (1546300800, 1), ('2019-01-01', 2);
SELECT * FROM dt;
9 DateTime时间戳
· 时间戳类型。用四个字节(无符号的)存储 Unix 时间戳)。
· 允许存储与日期类型相同的范围内的值。最小值为 0000-00-00 00:00:00。时间戳类型值精确到秒
CREATE TABLE dtt
(
`timestamp` DateTime('Europe/Moscow'),
`event_id` UInt8
)
ENGINE = TinyLog;
INSERT INTO dtt Values (1546300800, 1), ('2019-01-01 00:00:00', 2);
SELECT * FROM dtt;
还有很多数据结构,可以参考官方文档:https://clickhouse.yandex/docs/zh/data_types/
7、表引擎
· 官网参考文档:https://clickhouse.tech/docs/en/engines/table-engines/
· 表引擎(即表的类型)决定了:
o 数据的存储方式和位置,写到哪里以及从哪里读取数据
o 支持哪些查询以及如何支持。
o 并发数据访问。
o 索引的使用(如果存在)。
o 是否可以执行多线程请求。
o 数据复制参数。
ClickHouse的表引擎有很多,下面介绍其中几种,对其他引擎有兴趣的可以去查阅官方文档:https://clickhouse.yandex/docs/zh/operations/table_engines/
1 TinyLog
· 最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
· 该引擎没有并发控制
o 如果同时从表中读取和写入数据,则读取操作将抛出异常;
o 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(建议最多1,000,000行)。如果有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,不支持索引。
· 案例
o 创建一个TinyLog引擎的表并插入一条数据
create table f1 (a UInt16, b String) ENGINE=TinyLog;
insert into f1 (a, b) values (1, 'abc');
o 此时我们到保存数据的目录/var/lib/clickhouse/data/default/f1中可以看到如下目录结构:
[root@node01 f1]# ll
-rw-rw-rw- 1 clickhouse clickhouse 28 Feb 18 21:58 a.bin
-rw-rw-rw- 1 clickhouse clickhouse 30 Feb 18 21:58 b.bin
-rw-rw-rw- 1 clickhouse clickhouse 60 Feb 18 21:58 sizes.json
其中a.bin 和 b.bin 是压缩过的对应的列的数据,
sizes.json 中记录了每个 *.bin 文件的大小
[root@node01 f1]# cat sizes.json
{"yandex":{"a%2Ebin":{"size":"28"},"b%2Ebin":{"size":"30"}}}
2 Memory
· 内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过10G/s)。
· 一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概 1 亿行)的场景。
3 Merge
· Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据。 读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用。
· Merge 引擎的参数:一个数据库名和一个用于匹配表名的正则表达式。
· 案例
o 先建t1,t2,t3三个表,然后用 Merge 引擎的 tt 表再把它们链接起来
–创建表
create table t1 (id UInt16, name String) ENGINE=TinyLog;
create table t2 (id UInt16, name String) ENGINE=TinyLog;
create table t3 (id UInt16, name String) ENGINE=TinyLog;
–向表中插入数据
insert into t1(id, name) values (1, ‘first’);
insert into t2(id, name) values (2, ‘second’);
insert into t3(id, name) values (3, ‘three’);
–创建t表 ,把defalut数据库中所有以t开头的表连接起来
create table t(id UInt16, name String) ENGINE=Merge(currentDatabase(), ‘^t’);
node01 😃 select * from t;
SELECT *
FROM t
┌─id─┬─name──┐
│ 1 │ first │
└────┴───────┘
┌─id─┬─name───┐
│ 2 │ second │
└────┴────────┘
┌─id─┬─name──┐
│ 3 │ three │
└────┴───────┘
4 MergeTree
· Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(MergeTree)中的其他引擎。
· MergeTree 引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。
· 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE [=] MergeTree(date-column [, sampling_expression], (primary, key), index_granularity)
l date-column:类型为 Date 的列名。ClickHouse 会自动依据这个列创建分区。
l sampling_expression :采样表达式。
l (primary, key) :主键。类型为Tuple(),主键可以是任意表达式构成的元组(通常是列名称的元组).
l index_granularity :索引粒度。即索引中相邻”标记”间的数据行数。设为 8192 可以适用大部分场景。
案例:
--创建基于MergeTree的引擎表
create table mt_table (date Date, id UInt8, name String) ENGINE=MergeTree(date, (id, name), 8192);
--插入数据
insert into mt_table values ('2019-05-01', 1, 'zhangsan');
insert into mt_table values ('2019-06-01', 2, 'lisi');
insert into mt_table values ('2019-05-03', 3, 'wangwu');
--查询表
node01 :) select * from mt_table;
SELECT *
FROM mt_table
┌───────date─┬─id─┬─name───┐
│ 2019-05-03 │ 3 │ wangwu │
└────────────┴────┴────────┘
┌───────date─┬─id─┬─name─────┐
│ 2019-05-01 │ 1 │ zhangsan │
└────────────┴────┴──────────┘
┌───────date─┬─id─┬─name─┐
│ 2019-06-01 │ 2 │ lisi │
└────────────┴────┴──────┘
o 在/var/lib/clickhouse/data/default/mt_table目录下可以看到信息
[root@node01 mt_table]# ll
drwxrwxrwx 2 clickhouse clickhouse 157 Feb 19 12:51 20190501_20190501_2_2_0
drwxrwxrwx 2 clickhouse clickhouse 157 Feb 19 12:51 20190503_20190503_6_6_0
drwxrwxrwx 2 clickhouse clickhouse 157 Feb 19 12:51 20190601_20190601_4_4_0
drwxrwxrwx 2 clickhouse clickhouse 6 Feb 19 12:51 detached
o 进入到20190501_20190501_2_2_0目录中
[root@node01 20190501_20190501_2_2_0]# ll
-rw-rw-rw- 1 clickhouse clickhouse 255 Feb 19 12:51 checksums.txt
-rw-rw-rw- 1 clickhouse clickhouse 74 Feb 19 12:51 columns.txt
-rw-rw-rw- 1 clickhouse clickhouse 28 Feb 19 12:51 date.bin
-rw-rw-rw- 1 clickhouse clickhouse 16 Feb 19 12:51 date.mrk
-rw-rw-rw- 1 clickhouse clickhouse 27 Feb 19 12:51 id.bin
-rw-rw-rw- 1 clickhouse clickhouse 16 Feb 19 12:51 id.mrk
-rw-rw-rw- 1 clickhouse clickhouse 35 Feb 19 12:51 name.bin
-rw-rw-rw- 1 clickhouse clickhouse 16 Feb 19 12:51 name.mrk
-rw-rw-rw- 1 clickhouse clickhouse 10 Feb 19 12:51 primary.idx
##其中
*.bin是按列保存数据的文件
*.mrk保存块偏移量
primary.idx保存主键索引
5 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
n 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE [=] ReplacingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [ver])
--可以看出他比MergeTree只多了一个ver
--这个ver指代版本列,它和时间一起配置用来区分哪条数据是最新的。
--如果指定了ver,则保留ver值最大的版本;若没指定,则保留最后一条
· 案例
--创建一个基于ReplacingMergeTree引擎的表
create table rmt_table (date Date, id UInt8, name String,point UInt8) ENGINE= ReplacingMergeTree(date, (id, name), 8192,point);
--插入数据
insert into rmt_table values ('2019-07-10', 1, 'a', 20);
insert into rmt_table values ('2019-07-10', 1, 'a', 30);
insert into rmt_table values ('2019-07-11', 1, 'a', 20);
insert into rmt_table values ('2019-07-11', 1, 'a', 30);
insert into rmt_table values ('2019-07-11', 1, 'a', 10);
--等待一段时间或者使用 optimize table rmt_table 命令手动触发merge
--查询数据(返回去重之后最新的数据)
node01 :) select * from rmt_table;
SELECT *
FROM rmt_table
┌───────date─┬─id─┬─name─┬─point─┐
│ 2019-07-11 │ 1 │ a │ 30 │
└────────────┴────┴──────┴───────┘
6 SummingMergeTree
l 该引擎继承自 MergeTree。
l 区别在于: 当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。
l 在 merge 时,主键相同的行,被指定列的值会相加,没有被指定的列会取最先出现的值
语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE [=] SummingMergeTree(date-column [, sampling_expression], (primary, key), index_granularity, [columns])
o columns :包含将要被汇总的列的列名的元组;所选的列必须是数值类型,并且不可位于主键中
· 案例
----创建一个基于SummingMergeTree引擎的表
create table smt_table (date Date, name String, a UInt16, b UInt16) ENGINE=SummingMergeTree(date, (date, name), 8192, (a));
--插入数据
insert into smt_table (date, name, a, b) values ('2019-07-10', 'a', 1, 2);
insert into smt_table (date, name, a, b) values ('2019-07-10', 'b', 2, 1);
insert into smt_table (date, name, a, b) values ('2019-07-11', 'b', 3, 7);
insert into smt_table (date, name, a, b) values ('2019-07-11', 'b', 3, 8);
insert into smt_table (date, name, a, b) values ('2019-07-11', 'a', 3, 1);
insert into smt_table (date, name, a, b) values ('2019-07-12', 'c', 1, 3);
----等待一段时间或者使用 optimize table smt_table 命令手动触发merge
--查询数据
node01 :) select * from smt_table;
SELECT *
FROM smt_table
┌───────date─┬─name─┬─a─┬─b─┐
│ 2019-07-10 │ a │ 1 │ 2 │
│ 2019-07-10 │ b │ 2 │ 1 │
│ 2019-07-11 │ a │ 3 │ 1 │
│ 2019-07-11 │ b │ 6 │ 7│
│ 2019-07-12 │ c │ 1 │ 3 │
└────────────┴──────┴───┴───┘
--发现2019-07-11,b的a列合并相加了,b列取了7(因为b列为7的数据最先插入)
7 Distributed
· 分布式引擎,本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用。
· 语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE [=] Distributed(cluster_name, database, table [, sharding_key])
o 参数解析:
§ cluster_name :服务器配置文件中的集群名,在/etc/metrika.xml中配置的
§ database :数据库名
§ table :表名
§ sharding_key :数据分片键
· 案例:
(1)在node01,node02,node03上分别创建一个表 kaikeba
create table kaikeba(id UInt16, name String) ENGINE=TinyLog;
(2)在三台机器的 kaikeba 表中插入一些数据
insert into kaikeba (id, name) values (1, 'zhangsan');
insert into kaikeba (id, name) values (2, 'lisi');
(3)在 node01上创建分布式表
node01 :) create table distributed_table(id UInt16, name String) ENGINE=Distributed(bip_ck_cluster, default, kaikeba, id);
(4)查询 distributed_table 表的数据
node01 :) select * from distributed_table;
SELECT *
FROM distributed_table
┌─id─┬─name─────┐
│ 2 │ lisi │
│ 1 │ zhangsan │
└────┴──────────┘
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
└────┴──────────┘
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
└────┴──────────┘
(5)向distributed_table插入数据
insert into distributed_table select * from kaikeba;
node01 :) select * from distributed_table;
SELECT *
FROM distributed_table
┌─id─┬─name─────┐
│ 2 │ lisi │
│ 1 │ zhangsan │
└────┴──────────┘
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
│ 2 │ lisi │
└────┴──────────┘
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
│ 1 │ zhangsan │
└────┴──────────┘
--可以看到每个节点分布的数据差不多
· 总结
分布式表实际上是Clickhouse集群本地表的一种“视图”。对分布式表的SELECT查询,会利用集群所有分片资源进行执行。你可以配置多个集群,并创建多个分布式表,给不同的集群提供视图
8、SQL语法
1 create
1.1 create database
· 用于创建指定名称的数据库,语法如下:
CREATE DATABASE [IF NOT EXISTS] db_name
· 演示
create database if not exists test;
1.2 create table
· 对于创建表,语法如下
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
--DEFAULT expr : 默认值,用法与SQL类似。
--MATERIALIZED expr :物化表达式,被该表达式指定的列不能被INSERT,因为它总是被计算出来的。 对于INSERT而言,不需要考虑这些列。 另外,在SELECT查询中如果包含星号,此列不会被查询。
--ALIAS expr :别名。
· 创建表的三种方式
(1)直接创建
node01 :) create table t_demo1(id UInt16,name String) engine=TinyLog;
(2)创建一个与其他表具有相同结构的表
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
演示
node01 :) create table t_demo2 as t_demo1 engine=Memory;
node01 :) desc t_demo2;
DESCRIBE TABLE t_demo2
┌─name─┬─type───┬─default_type─┬─default_expression─┐
│ id │ UInt16 │ │ │
│ name │ String │ │ │
└──────┴────────┴──────────────┴────────────────────┘
(3)使用指定的引擎创建一个与SELECT子句的结果具有相同结构的表,并使用SELECT子句的结果填充它。
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ..
演示
--向t_demo1表中添加数据
insert into t_demo1 values(1,'zhangsan'),(2,'lisi'),(3,'wangwu');
create table t_demo3 engine=TinyLog as select * from t_demo1;
--查询表数据
node01 :) select * from t_demo3;
SELECT *
FROM t_demo3
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
│ 3 │ wangwu │
└────┴──────────┘
2 insert into
insert主要用于向系统中添加数据.
语法:
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
演示
create table t_demo4(id UInt16,name String) engine=TinyLog;
insert into t_demo4 values(1,'zhangsan'),(2,'lisi');
--查询
node01 :) select * from t_demo4;
SELECT *
FROM t_demo4
┌─id─┬─name─────┐
│ 1 │ zhangsan │
│ 2 │ lisi │
└────┴──────────┘
注意
clickhouse不支持的其他用于修改数据的查询:UPDATE, DELETE, REPLACE, MERGE, UPSERT, INSERT UPDATE。 但是可以使用 ALTER TABLE ... DROP PARTITION查询来删除一些旧的数据。
3 alter
ALTER只支持MergeTree系列,Merge和Distributed引擎的表
语法
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|MODIFY COLUMN ...
参数解析
ADD COLUMN 向表中添加新列
DROP COLUMN 在表中删除列
MODIFY COLUMN 更改列的类型
· 演示
(1)创建一个MergerTree引擎的表
create table mt_table_demo1 (date Date, id UInt8, name String) ENGINE=MergeTree(date, (id, name), 8192);
(2)向表中插入数据
insert into mt_table_demo1 values ('2019-05-01', 1, 'zhangsan');
insert into mt_table_demo1 values ('2019-06-01', 2, 'lisi');
insert into mt_table_demo1 values ('2019-05-03', 3, 'wangwu');
(3)新增age列
--添加age列
node01 :) alter table mt_table_demo1 add column age UInt8;
--查看表结构
node01 :) desc mt_table_demo1;
DESCRIBE TABLE mt_table_demo1
┌─name─┬─type───┬─default_type─┬─default_expression─┐
│ date │ Date │ │ │
│ id │ UInt8 │ │ │
│ name │ String │ │ │
│ age │ UInt8 │ │ │
└──────┴────────┴──────────────┴────────────────────┘
--查询表数据
node01 :) select * from mt_table_demo1;
SELECT *
FROM mt_table_demo1
┌───────date─┬─id─┬─name───┬─age─┐
│ 2019-05-03 │ 3 │ wangwu │ 0 │
└────────────┴────┴────────┴─────┘
┌───────date─┬─id─┬─name─────┬─age─┐
│ 2019-05-01 │ 1 │ zhangsan │ 0 │
└────────────┴────┴──────────┴─────┘
┌───────date─┬─id─┬─name─┬─age─┐
│ 2019-06-01 │ 2 │ lisi │ 0 │
└────────────┴────┴──────┴─────┘
(4)更改age列的类型
--更改age列的类型为UInt16
node01 :) alter table mt_table_demo1 modify column age UInt16
--查看表结构
node01 :) desc mt_table_demo1;
DESCRIBE TABLE mt_table_demo1
┌─name─┬─type───┬─default_type─┬─default_expression─┐
│ date │ Date │ │ │
│ id │ UInt8 │ │ │
│ name │ String │ │ │
│ age │ UInt16 │ │ │
└──────┴────────┴──────────────┴────────────────────┘
(5)删除age列
--删除age列
node01 :) alter table mt_table_demo1 drop column age;
--查看表结构
node01 :) desc mt_table_demo1;
DESCRIBE TABLE mt_table_demo1
┌─name─┬─type───┬─default_type─┬─default_expression─┐
│ date │ Date │ │ │
│ id │ UInt8 │ │ │
│ name │ String │ │ │
└──────┴────────┴──────────────┴────────────────────┘
4 check table
检查表中的数据是否损坏,它会返回两种结果:
0:表数据已损坏
1:表数据完整
该命令只支持Log、TinyLog和StripeLog引擎
演示
node01 :) check TABLE mt_table_demo1;
CHECK TABLE t1
┌─result─┐
│ 1 │
└────────┘
9、clickhouse集成外部存储系统
1 kafka
把消息从kafka集群中实时写入到clickhouse中
1.1 创建一个topic
cd /kkb/install/kafka_2.11-1.1.0
kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic ck --zookeeper node01:2181,node02:2181,node03:2181
1.2 创建表
在node01上启动 clickhouse-client -m 客户端,执行sql语句
CREATE TABLE queue (
timestamp UInt64,
level String,
message String
) ENGINE = Kafka SETTINGS kafka_broker_list ='node01:9092,node02:9092,node03:9092',
kafka_topic_list = 'ck',
kafka_group_name = 'consumer_ck',
kafka_format = 'JSONEachRow',
kafka_num_consumers = 3;
l kafka_broker_list:指定kafka集群地址
l kafka_topic_list:topic 列表
l kafka_group_name:Kafka 消费组名称
l kafka_format:消息体格式,使用与 SQL 部分的 FORMAT 函数相同表示方法,例如 JSONEachRow
l kafka_num_consumers:消费者线程数
1.3 向topic写入数据
利用脚本写数据到ck主题中
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic ck
##发送一条数据
{"timestamp":153000000,"level":"1","message":"hello ck"}
1.4 查询数据
node01 :) select * from queue;
SELECT *
FROM queue
┌─timestamp─┬─level─┬─message──┐
│ 153000000 │ 1 │ hello ck │
└───────────┴───────┴──────────┘
注意
--这里使用select查询每条数据数据只能够读取一次。可以使用物化视图创建实时线程更实用。
--实现步骤:
--(1)使用引擎创建一个 Kafka 消费者并作为一条数据流。
--(2)创建一个结构表。
--(3)创建物化视图,改视图会在后台转换引擎中的数据并将其放入之前创建的表中。
--当 MATERIALIZED VIEW 添加至引擎,它将会在后台收集数据。可以持续不断地从 Kafka 收集数据并通过 SELECT 将数据转换为所需要的格式。
CREATE TABLE daily (
day Date,
level String,
total UInt64
) ENGINE = SummingMergeTree(day, (day, level), 8192);
CREATE MATERIALIZED VIEW consumer TO daily
AS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as total
FROM queue GROUP BY day, level;
SELECT level, sum(total) FROM daily GROUP BY level;
2 HDFS
该引擎允许通过ClickHouse 管理HDFS上的数据,从而与Apache Hadoop生态系统集成。
2.1 创建一张表
格式:
ENGINE = HDFS(URI, format)
--URI:指定hdfs文件目录
--format:指定数据的格式
演示:
CREATE TABLE hdfs_engine_table (id Int32, name String, age Int32) ENGINE=HDFS('hdfs://node01:8020/other_storage/*', 'CSV');
--数据来自于hdfs上other_storage目录下的所有文件
--文件的格式是CSV(字段之前的分隔符是逗号)
支持的数据格式 :
https://clickhouse.tech/docs/zh/interfaces/formats/#formats
2.2 准备数据
node01执行以下命令创建文件,然后上传到hdfs对应文件夹
cd /kkb/install
vim file1.txt
1,zhangsan,20
2,lisi,29
3,wangwu,25
4,zhaoliu,35
5,tianqi,35
6,kobe,40
上传文件到hdfs上对应的目录
hdfs dfs -mkdir -p /other_storage
hdfs dfs -put file1.txt /other_storage
2.3 查看表数据
node01 :) select * from hdfs_engine_table;
SELECT *
FROM hdfs_engine_table
┌─id─┬─name─────┬─age─┐
│ 1 │ zhangsan │ 20 │
│ 2 │ lisi │ 29 │
│ 3 │ wangwu │ 25 │
│ 4 │ zhaoliu │ 35 │
│ 5 │ tianqi │ 35 │
│ 6 │ kobe │ 40 │
└────┴──────────┴─────┘
10、 实战
需求:基于clickhouse对航班飞行数据进行分析处理
1 准备数据
node01服务器执行以下命令,创建shell脚本
sudo yum -y install wget
cd /kkb/install/
vim down_data.sh
#!/bin/bash*
for s in `seq 1987 2018`
do
for m in `seq 1 12`
do
wget https://transtats.bts.gov/PREZIP/On_Time_Reporting_Carrier_On_Time_Performance_1987_present_${s}
_${m}.zip
done
done
该脚本主要是为了下载从1987年到 2018年航班飞行数据,由于数据量比较大,这里只使用1988年和1989年的飞行数据

2 创建表
node01服务器进入clickhouse的客户端,然后准备创建表
进入客户端,然后创建表
clickhouse-client -m
CREATE TABLE `ontime` (
`Year` UInt16,
`Quarter` UInt8,
`Month` UInt8,
`DayofMonth` UInt8,
`DayOfWeek` UInt8,
`FlightDate` Date,
`UniqueCarrier` FixedString(7),
`AirlineID` Int32,
`Carrier` FixedString(2),
`TailNum` String,
`FlightNum` String,
`OriginAirportID` Int32,
`OriginAirportSeqID` Int32,
`OriginCityMarketID` Int32,
`Origin` FixedString(5),
`OriginCityName` String,
`OriginState` FixedString(2),
`OriginStateFips` String,
`OriginStateName` String,
`OriginWac` Int32,
`DestAirportID` Int32,
`DestAirportSeqID` Int32,
`DestCityMarketID` Int32,
`Dest` FixedString(5),
`DestCityName` String,
`DestState` FixedString(2),
`DestStateFips` String,
`DestStateName` String,
`DestWac` Int32,
`CRSDepTime` Int32,
`DepTime` Int32,
`DepDelay` Int32,
`DepDelayMinutes` Int32,
`DepDel15` Int32,
`DepartureDelayGroups` String,
`DepTimeBlk` String,
`TaxiOut` Int32,
`WheelsOff` Int32,
`WheelsOn` Int32,
`TaxiIn` Int32,
`CRSArrTime` Int32,
`ArrTime` Int32,
`ArrDelay` Int32,
`ArrDelayMinutes` Int32,
`ArrDel15` Int32,
`ArrivalDelayGroups` Int32,
`ArrTimeBlk` String,
`Cancelled` UInt8,
`CancellationCode` FixedString(1),
`Diverted` UInt8,
`CRSElapsedTime` Int32,
`ActualElapsedTime` Int32,
`AirTime` Int32,
`Flights` Int32,
`Distance` Int32,
`DistanceGroup` UInt8,
`CarrierDelay` Int32,
`WeatherDelay` Int32,
`NASDelay` Int32,
`SecurityDelay` Int32,
`LateAircraftDelay` Int32,
`FirstDepTime` String,
`TotalAddGTime` String,
`LongestAddGTime` String,
`DivAirportLandings` String,
`DivReachedDest` String,
`DivActualElapsedTime` String,
`DivArrDelay` String,
`DivDistance` String,
`Div1Airport` String,
`Div1AirportID` Int32,
`Div1AirportSeqID` Int32,
`Div1WheelsOn` String,
`Div1TotalGTime` String,
`Div1LongestGTime` String,
`Div1WheelsOff` String,
`Div1TailNum` String,
`Div2Airport` String,
`Div2AirportID` Int32,
`Div2AirportSeqID` Int32,
`Div2WheelsOn` String,
`Div2TotalGTime` String,
`Div2LongestGTime` String,
`Div2WheelsOff` String,
`Div2TailNum` String,
`Div3Airport` String,
`Div3AirportID` Int32,
`Div3AirportSeqID` Int32,
`Div3WheelsOn` String,
`Div3TotalGTime` String,
`Div3LongestGTime` String,
`Div3WheelsOff` String,
`Div3TailNum` String,
`Div4Airport` String,
`Div4AirportID` Int32,
`Div4AirportSeqID` Int32,
`Div4WheelsOn` String,
`Div4TotalGTime` String,
`Div4LongestGTime` String,
`Div4WheelsOff` String,
`Div4TailNum` String,
`Div5Airport` String,
`Div5AirportID` Int32,
`Div5AirportSeqID` Int32,
`Div5WheelsOn` String,
`Div5TotalGTime` String,
`Div5LongestGTime` String,
`Div5WheelsOff` String,
`Div5TailNum` String
) ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
3 加载数据到表中
· 在数据所在的目录执行下面命令
将所有的数据上传到node01服务器的/kkb/soft/flydatas路径下
然后执行以下命令加载数据
sudo yum -y install unzip
for i in *.zip; do echo $i; unzip -cq $i '*.csv' | sed 's/\.00//g' | clickhouse-client --query="INSERT INTO ontime FORMAT CSVWithNames"; done
· 加载成功后,查看表数据
node01 :) select count(*) from ontime;
SELECT count(*)
FROM ontime
┌──count()─┐
│ 10243296 │
└──────────┘
1 rows in set. Elapsed: 0.005 sec. Processed 10.24 million rows, 10.24 MB (2.26 billion rows/s., 2.26 GB/s.)
4 需求指标分析
4.1 查询所有月份中航班数的最大值、最小值、平均值
SELECT max(c1),min(c1),avg(c1)
FROM
(
SELECT Year, Month, count(*) AS c1
FROM ontime
GROUP BY Year, Month
);
┌─max(c1)─┬─min(c1)─┬─avg(c1)─┐
│ 446769 │ 395176 │ 426804 │
└─────────┴─────────┴─────────┘
4.2 查询从1988年到1989年中周内的航班数
SELECT DayOfWeek, count(*) AS c
FROM ontime
WHERE Year>=1988 AND Year<=1989
GROUP BY DayOfWeek
ORDER BY c desc;
┌─DayOfWeek─┬───────c─┐
│ 5 │ 1497912 │
│ 3 │ 1493143 │
│ 2 │ 1492544 │
│ 1 │ 1489357 │
│ 4 │ 1484423 │
│ 7 │ 1420042 │
│ 6 │ 1365875 │
└───────────┴─────────┘
4.3 查询从1988年到1989年中周内延误超过10分钟的航班数。
SELECT DayOfWeek, count(*) AS c
FROM ontime
WHERE DepDelay>10 AND Year>=1988 AND Year<=1989
GROUP BY DayOfWeek
ORDER BY c DESC;
┌─DayOfWeek─┬──────c─┐
│ 4 │ 307762 │
│ 5 │ 304375 │
│ 3 │ 290879 │
│ 2 │ 270656 │
│ 1 │ 243052 │
│ 7 │ 234229 │
│ 6 │ 219208 │
└───────────┴────────┘
4.4 查询1988年到1989年每个机场延误超过10分钟以上的次数
SELECT Origin, count(*) AS c
FROM ontime
WHERE DepDelay>10 AND Year>=1988 AND Year<=1989
GROUP BY Origin
ORDER BY c DESC
LIMIT 10;
┌─Origin──┬──────c─┐
│ ORD\0\0 │ 138100 │
│ DFW\0\0 │ 80991 │
│ ATL\0\0 │ 80184 │
│ CLT\0\0 │ 68363 │
│ PIT\0\0 │ 67484 │
│ LAX\0\0 │ 63626 │
│ DEN\0\0 │ 60269 │
│ SFO\0\0 │ 58458 │
│ EWR\0\0 │ 55438 │
│ STL\0\0 │ 53238 │
└─────────┴────────┘
4.5 查询1988年各航空公司延误超过10分钟以上的次数
SELECT Carrier, count(*) as num
FROM ontime
WHERE DepDelay>10 AND Year=1988
GROUP BY Carrier
ORDER BY num DESC;
┌─Carrier─┬────num─┐
│ UA │ 113208 │
│ AA │ 96946 │
│ DL │ 96443 │
│ PI │ 94642 │
│ CO │ 80925 │
│ AL │ 78368 │
│ EA │ 66918 │
│ NW │ 64962 │
│ TW │ 51121 │
│ WN │ 44572 │
│ US │ 26604 │
│ HP │ 21175 │
│ AS │ 13352 │
│ PA │ 10181 │
│ PS │ 5020 │
└─────────┴────────┘
4.6 查询1988年各航空公司延误超过10分钟以上的百分比
SELECT Carrier, c, c2, c*100/c2 as c3
FROM
(
SELECT
Carrier,
count(*) AS c
FROM ontime
WHERE DepDelay>10
AND Year=1988
GROUP BY Carrier
)
ANY INNER JOIN
(
SELECT
Carrier,
count(*) AS c2
FROM ontime
WHERE Year=1988
GROUP BY Carrier
) USING Carrier
ORDER BY c3 DESC;
---更好的查询版本
SELECT Carrier, avg(DepDelay>10)*100 AS c3
FROM ontime
WHERE Year=1988
GROUP BY Carrier
ORDER BY Carrier;
┌─Carrier─┬──────c─┬─────c2─┬─────────────────c3─┐
│ AL │ 78368 │ 361059 │ 21.705039896526607 │
│ PI │ 94642 │ 470957 │ 20.095677524699706 │
│ US │ 26604 │ 133324 │ 19.954396807776543 │
│ UA │ 113208 │ 587144 │ 19.281130353030942 │
│ TW │ 51121 │ 275819 │ 18.534256160743094 │
│ CO │ 80925 │ 457031 │ 17.70667635236997 │
│ EA │ 66918 │ 389292 │ 17.18966739619617 │
│ WN │ 44572 │ 262422 │ 16.984856452584005 │
│ NW │ 64962 │ 431440 │ 15.057018357129612 │
│ AS │ 13352 │ 89822 │ 14.864955133486228 │
│ PA │ 10181 │ 72264 │ 14.088619506254844 │
│ AA │ 96946 │ 694757 │ 13.953943609060435 │
│ DL │ 96443 │ 753983 │ 12.791137200706117 │
│ PS │ 5020 │ 41911 │ 11.9777624012789 │
│ HP │ 21175 │ 180871 │ 11.707238860845575 │
└─────────┴────────┴────────┴────────────────────┘
4.7 同上一个查询一致,只是查询范围扩大到1988年到1989年
SELECT Carrier, avg(DepDelay>10)*100 AS c3
FROM ontime
WHERE Year>=1988 AND Year<=1989
GROUP BY Carrier
ORDER BY Carrier;
┌─Carrier─┬─────────────────c3─┐
│ AA │ 14.973459265773348 │
│ AL │ 21.705039896526607 │
│ AS │ 14.402829935622318 │
│ CO │ 16.96160617418744 │
│ DL │ 14.788366379301934 │
│ EA │ 16.675253490185977 │
│ HP │ 13.738282256500709 │
│ NW │ 14.799160318481144 │
│ PA │ 15.59199720311088 │
│ PI │ 24.084359219776232 │
│ PS │ 11.9777624012789 │
│ TW │ 18.715348820366113 │
│ UA │ 22.14408797247073 │
│ US │ 25.955873831985677 │
│ WN │ 20.385723408269595 │
└─────────┴────────────────────┘
4.8 每年航班延误超过10分钟的百分比
SELECT Year, c1/c2
FROM
(
select
Year,
count(*)*100 as c1
from ontime
WHERE DepDelay>10
GROUP BY Year
)
ANY INNER JOIN
(
select
Year,
count(*) as c2
from ontime
GROUP BY Year
) USING (Year)
ORDER BY Year;
---更好的查询版本
SELECT Year, avg(DepDelay>10)
FROM ontime
GROUP BY Year
ORDER BY Year;
┌─Year─┬─────divide(c1, c2)─┐
│ 1988 │ 16.61709049583091 │
│ 1989 │ 19.950091248115527 │
└──────┴────────────────────┘
4.9 每年更受人们喜爱的目的地
SELECT DestCityName, uniqExact(OriginCityName) AS u
FROM ontime
WHERE Year >= 1988 and Year <= 1989
GROUP BY DestCityName
ORDER BY u DESC LIMIT 10;
--uniqExact去重
┌─DestCityName──────────┬───u─┐
│ Chicago, IL │ 111 │
│ Atlanta, GA │ 92 │
│ Dallas/Fort Worth, TX │ 89 │
│ Denver, CO │ 86 │
│ Pittsburgh, PA │ 79 │
│ St. Louis, MO │ 78 │
│ Minneapolis, MN │ 75 │
│ Charlotte, NC │ 69 │
│ Detroit, MI │ 69 │
│ Phoenix, AZ │ 67 │
└───────────────────────┴─────┘
11、clickhouse为什么辣么快
在巨大的单表测试运行当中,ck有着无与伦比的性能,那么ck究竟是如何实现的,才能够实现惊人的速度呢?
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础
clickhouse的存储存优势
1、列式存储
就像hbase等一些nosql的数据库一样,clickhouse也采用了列式存储的方式。相比于行式存储,列式存储在分析场景下有着许多优良的特性。
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
2、数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
3、主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
4、稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。其中被索引的value可以是任意的合法SQL Expression,并不仅仅局限于对column value本身进行索引。之所以叫稀疏索引,是因为它本质上是对一个完整index granularity(默认8192行)的统计信息,并不会具体记录每一行在文件中的位置。目前支持的稀疏索引类型包括:
Ø minmax: 以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
Ø set(max_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
Ø ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
Ø tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与ngrambf_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
Ø bloom_filter([false_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
5、数据sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3)column value分片:按照某一列的值进行hash分片。
4)自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join; 支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
6、数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
Ø 在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
Ø 对partition进行TTL管理,淘汰过期的分区数据。
7、数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
8、高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
9、有限支持delete、update
在分析场景中,删除、更新操作并不是核心需求。ClickHouse没有直接支持delete、update操作,而是变相支持了mutation操作,语法为alter table delete where filter_expr,alter table update col=val where filter_expr。
目前主要限制为删除、更新操作为异步操作,需要后台compation之后才能生效。
10、主备同步
ClickHouse通过主备复制提供了高可用能力,主备架构下支持无缝升级等运维操作。而且相比于其他系统它的实现有着自己的特色:
1)默认配置下,任何副本都处于active模式,可以对外提供查询服务;
2)可以任意配置副本个数,副本数量可以从0个到任意多个;
3)不同shard可以配置不提供副本个数,用于解决单个shard的查询热点问题;
ClickHouse计算层优势
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
1、多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
2、分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
Ø 随机下发:在多个replica中随机选择一个;
Ø 最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
Ø in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
Ø first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
3、向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
4、动态代码生成Runtime Codegen
在经典的数据库实现中,通常对表达式计算采用火山模型,也即将查询转换成一个个operator,比如HashJoin、Scan、IndexScan、Aggregation等。为了连接不同算子,operator之间采用统一的接口,比如open/next/close。在每个算子内部都实现了父类的这些虚函数,在分析场景中单条SQL要处理数据通常高达数亿行,虚函数的调用开销不再可以忽略不计。另外,在每个算子内部都要考虑多种变量,比如列类型、列的size、列的个数等,存在着大量的if-else分支判断导致CPU分支预测失效。
ClickHouse实现了Expression级别的runtime codegen,动态地根据当前SQL直接生成代码,然后编译执行。如下图例子所示,对于Expression直接生成代码,不仅消除了大量的虚函数调用(即图中多个function pointer的调用),而且由于在运行时表达式的参数类型、个数等都是已知的,也消除了不必要的if-else分支判断。
5、近似计算
近似计算以损失一定结果精度为代价,极大地提升查询性能。在海量数据处理中,近似计算价值更加明显。
ClickHouse实现了多种近似计算功能:
Ø 近似估算distinct values、中位数,分位数等多种聚合函数;
Ø 建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理;
6、复杂数据类型支持
ClickHouse还提供了array、json、tuple、set等复合数据类型,支持业务schema的灵活变更。
12、hive表迁移到clickHouse
由于历史原因,很多公司的历史数仓都是基于hive构建,数据表都是存储在hive当中,如何实现hive表数据迁移到clickHouse就至关重要了,接下来我们来一起看看如何将hive表数据全部平滑的迁移到clickHouse里面来
由于我们hive的数据全部都是存储在hdfs上面的,所以我们直接将hdfs的数据加载到clickhouse里面创建的表里面来即可,我们可以通过第三方插件例如datax或者waterdrop等数据传输工具,将hdfs的数据全部采集到clickhouse里面来即可
需求:将hive数据仓库当中的game_center这个库的ods_user_login表数据迁移到clickHouse表里面来
这里涉及到数据的迁移,将hive当中的表数据迁移到clickHouse里面来,数据迁移的工具很多,例如sqoop,datax,waterdrop等,其中有一个比较优秀的插件叫做waterdrop的,可以非常方便的实现我们各种数据的迁移,官网链接如下:
https://interestinglab.github.io/waterdrop/#/
通过简单的配置即可,我们就可以通过waterdrop将各个地方的数据进行抽取到各个目的地去
1、waterdrop的基本介绍
官网链接如下:
https://interestinglab.github.io/waterdrop/#/
通过简单的配置即可,我们就可以通过waterdrop将各个地方的数据进行抽取到各个目的地去
2、waterdrop的安装与使用
waterdrop使用spark的引擎来实现数据的抽取和传输到目的地,所以使用waterdrop之前需要我们先安装好spark的环境,
运行环境要求:
l java运行环境,java >= 8
l 如果您要在集群环境中运行Waterdrop,那么需要以下Spark集群环境的任意一种:
l Spark on Yarn
l Spark Standalone
l Spark on Mesos
l 如果您的数据量较小或者只是做功能验证,也可以仅使用local模式启动,无需集群环境,Waterdrop支持单机运行。
waterdrop不支持spark1.x的各种版本,最低需要安装spark2.x的版本,如果使用spark2.3.x的版本,那么waterdrop需要1.4.x及以上的版本
第一步:安装spark集群
我们这里已经安装成功,不用再进行安装,并且我们使用的spark集群版本是2.3.x版本(需要让spark、hadoop支持lzo压缩)
第二步:集成spark与hive
由于我们需要将hive表当中的数据,导入到clickhouse当中去,而waterdrop又是借助于spark来进行数据抽取的,所以我们需要整合spark与hive
node03执行以下命令,拷贝hive-site.xml
先将hive-site.xml中的tez引擎注释掉
cd /kkb/install/apache-hive-3.1.2/conf/
scp hive-site.xml node01:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf/
scp hive-site.xml node02:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf/
scp hive-site.xml node03:/kkb/install/spark-2.3.3-bin-hadoop2.7/conf/
第三步:启动hive的metastore以及hiveserver2服务
使用spark作为引擎,读取hive表数据,我们需要启动hive的metastore服务,node03执行以下命令启动hivedemetastore服务即可
cd /kkb/install/apache-hive-3.1.2
bin/hive --service metastore
bin/hive --service hiveserver2
第四步:下载安装waterdrop
我们这里使用waterdrop1.4.2的这个版本,waterdrop的下载地址如下:
https://github.com/InterestingLab/waterdrop/releases/download/v1.4.2/waterdrop-1.4.2.zip
node02执行以下命令下载waterdrop
cd /kkb/soft/
sudo yum -y install wget
wget https://github.com/InterestingLab/waterdrop/releases/download/v1.4.2/waterdrop-1.4.2.zip
node02执行以下命令进行解压
sudo yum -y install unzip
unzip waterdrop-1.4.2.zip -d /kkb/install/
第五步:修改waterdrop的配置文件
node02服务器执行以下命令,修改配置文件
cd /kkb/install/waterdrop-1.4.2/config
vim waterdrop-env.sh
SPARK_HOME= /kkb/install/spark-2.3.3-bin-hadoop2.7
第六步:上传数据及创建clickhouse数据库以及数据库表
一键执行所有的ods层的数据库表
开发shell脚本,一键执行ods层所有的表
将ods层的所有sh脚本,上传到/home/hadoop/bin目录
node03开发以下shell脚本
cd /home/hadoop/bin
vim execute_ods.sh
#!/bin/bash
odsshell=`ls ods*`
#echo "$odsshell"
for m in $odsshell
do
echo $m
/usr/bin/sh $m
done
执行脚本
sh execute_ods.sh
node02服务器进入到clickHouse客户端,然后创建数据库以及数据库表
clickhouse-client -m
node02.kaikeba.com :) create database game_center;
node02.kaikeba.com :) use game_center;
创建clickHouse表
CREATE TABLE game_center.ods_role_recharge(
plat_id String,
server_id Int32,
channel_id String,
user_id String,
role_id String,
role_name String,
event_time Int32,
order_id String,
acer_count Int32,
recharge_amount Float64,
order_status Int32,
recharge_purpose Int32,
part_date date
)ENGINE = MergeTree PARTITION BY part_date ORDER BY (part_date) SETTINGS index_granularity = 16384;
第七步:开发clickHouse数据处理配置文件
node02执行以下命令开发waterdrop的配置文件
cd /kkb/install/waterdrop-1.4.2/config
vim batch.conf
#配置文件内容如下
spark {
spark.app.name = "Waterdrop"
spark.executor.instances = 2
spark.executor.cores = 1
spark.executor.memory = "1g"
spark.sql.catalogImplementation = "hive"
}
input {
hive {
pre_sql = "select * from game_center.ods_role_recharge"
result_table_name = "ods_role_recharge2"
table_name = "ods_role_recharge2"
}
}
filter {
# split data by specific delimiter
}
output {
clickhouse {
host = "node02:8123"
database = "game_center"
table = "ods_role_recharge"
fields = ["plat_id","server_id","channel_id","user_id","role_id","role_name","event_time","order_id","acer_count","recharge_amount","order_status","recharge_purpose"]
username = ""
password = ""
}
}
第八步:启动waterdrop导入数据到clickhouse表当中去
node02执行以下命令,启动waterdrop开始导入数据
使用spark的local模式进行运行
cd /kkb/install/waterdrop-1.4.2/
bin/start-waterdrop.sh --config config/batch.conf -e client -m 'local[2]'
如果想要使用spark的standAlone模式进行运行,通过以下方式进行提交
# client 模式
./bin/start-waterdrop.sh --master spark://node01:7077 --deploy-mode client --config ./config/batch.conf
# cluster 模式
./bin/start-waterdrop.sh --master spark://node01:7077 --deploy-mode cluster --config ./config/*batch.conf
如果想要使用spark on yarn模式进行提交,那么通过以下方式进行提交
# client 模式
./bin/start-waterdrop.sh --master yarn --deploy-mode client --config ./config/batch.conf
# cluster 模式
./bin/start-waterdrop.sh --master yarn --deploy-mode cluster --config ./config/batch.conf
第九步:查询clickhouse数据,验证数据进入clickhouse
node02执行以下命令,查询clickhouse当中的数据
clickhouse-client -m
node02.kaikeba.com :) use game_center;
node02.kaikeba.com :) select count(1) from ods_role_recharge;
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











