






目录
1.5.1 字段的辨识度要高-唯一性比较高(一般企业中辨识度达到75%左右比较考虑)
1.5.3 在order by group by后的字段可考虑加索引
一、索引原理
1.1 索引的分类
- 主键索引:mysql中表必须维护一个B+tree索引树,如果在表中没有指定主键列,数据库会通过一个隐藏列作为索引字段构建B+tree
- 普通索引:加速查找create index idx_ on 表(字段)
- 唯一索引:
- 主键索引:primary key :加速查找+约束(不为空且唯一)
- 唯一索引:unique:加速查找+约束 (唯一)
- 联合索引(组合索引): 联合主键索引,联合唯一索引,联合普通索引,create index a,b,c,最左匹配原则
- 全文索引:用于搜索很长一篇文章的时候,效果最好(一般不推荐使用大文本字段,比如text)。
1.2 索引的操作
了解即可,一般使用图形化界面进行操作
创建索引
-- create [UNIQUE|primary|fulltext] index 索引名称 ON 表名(字段(长度))
create index emp_name_index ON employee(NAME);查看索引
show index from 表名删除索引
-- drop index[索引名称] on 表名
DROP INDEX emp_name_index ON employee;更改索引
alter table tab_name add primary key(column_list)
-- 添加一个主键,索引必须是唯一索引,不能为NULL
alter table tab_name add unque index_name(column_list)
-- 创建的索引是唯一索引,可以为NULL
alter table tab_name add index index_name(column_list)
-- 普通索引,索引值可出现多次
alter table tab_name add fulltext index_name(column_list)
-- 全文索引1.3 联合索引(最左匹配原则)
如:一张员工表,我们经常会用 工号、名称、入职日期 作为条件查询
select * from 员工表 where 工号=10002 and 名称=Staff and 入职日期='2001-09-03'
那么我们可以考虑 将(工号、名称、入职日期)创建为一个组合索引
这时候就有小伙伴要问了,为什么不把三个字段都单独列一个索引呢?
因为如果对工号、名称、入职日期三列分别创建索引,MySQL只会选择辨识度高的一列作为索引。而对于组合索引而言如果将(工号、名称、入职日期)创建为一个组合索引,MySQL会先按工号排查、工号匹配完在按名称筛选、名称筛选完再按日期筛选,从而更精准的筛选到我们要查询的员工
最左原则:
(工号、名称、入职日期) 作为一个组合索引,将会生成下图的索引目录结构。
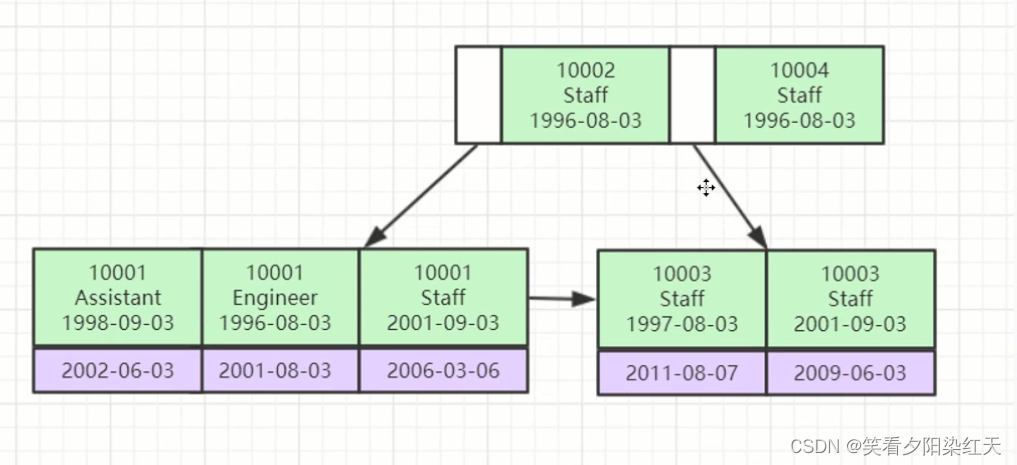
由接口可以看出, 工号是最先需要判断的字段,所以工号这个查询条件必须存在
工号判断完,才会判断名称
名称判断完才会判断入职日期
也就是说,组合索引查询条件必须得带有最左边的列,否则不生效!
1.4 索引的优劣势
1.4.1优势
- 可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性.
- 建立索引可以大大提高检索的数据,以及减少表的检索行数
- 在表连接的连接条件 可以加速表与表直接的相连
- 在分组和排序字句进行数据检索,可以减少查询时间中 分组 和 排序时所消耗的时间(数据库的记录会重新排序)
- 建立索引,在查询中使用索引 可以提高性能
1.4.2 劣势
- 索引文件会占用物理空间,除了数据表需要占用物理空间之外,每一个索引还会占用一定的物理空间
- 在创建索引和维护索引 会耗费时间,随着数据量的增加而增加
- 当对表的数据进行INSERT,UPDATE,DELETE 的时候,索引也要动态的维护,这样就会降低数据的维护速度
1.5 索引字段的选择
1.5.1 字段的辨识度要高-唯一性比较高(一般企业中辨识度达到75%左右比较考虑)
-- 去重后数量 / 总数量 越趋近1,越好,体现唯一性
select count(distinct name)/count(name) from testemployee;适合: 主键自动建立唯一索引
不适合:数据重复的表字段-辨识度低,比如性别
1.5.2 条件字段优先考虑加索引
创建索引,只有查询用到了,才有效!
where on
尤其多表关联查询时,关联的字段添加索引,可加快联查的速度;
适合:频繁作为查询条件的字段
不适合:where on 条件里用不到的字段
1.5.3 在order by group by后的字段可考虑加索引
order by :本质是排序,而索引树是将字段已经排好序了,这样如果走索引,则减少CPU计算开销!
group by:分组,索引树的叶子节点排好序了,相同的原则都连着在一块了!!
适合:查询中排序的字段,查询中统计或分组的字段
不适合:字段特别大不适合
1.5.4 对于回表查询
如果联合字段唯一性强,则可构建联合索引,避免频繁回表查询(随机I/O)导致查询过慢问题;
1.5.5 对于索引优化
如果查询中存在热点数据,则数据不经常变化,则考虑缓存(本地缓存|远程缓存)
1.6 索引失效的原因?
- .查询条件没有用索引
- 只要对索引字段进行处理,都会导致索引失效
- 对索引字段进行数学运算
eg:select * from testemployee where id(+|-|*|/|%) 10=100; - 对索引字段进行函数处理
eg:select * from testemployee where trim(name)='zhangsan'; - 对索引字段类型转换
eg: select * from user where phone=18812122334;(phone是varchar类型,条件值是long类型)
- 对索引字段进行数学运算
- 左侧模糊匹配查询 like '%三'
- 数据频繁的增删:频繁的增删数据,导致叶子节点分裂与合并,重新构建的过程,索引会失效
- or关键字可能导致索引失效
select * from user where name like 'zhang%' or id_card='xxxx'; - 联合索引不遵循最左匹配原则
- 查询的列为空;为空的列对应的行不参与索引的构建!
二、性能分析
2.1 慢查询日志
MYSQL的慢查询日志是mysql提供的一种日志记录,它用来记录在mysql中响应时间超过阀值的语句,mysql 的日志是跟踪mysql性能瓶颈的最快和最直接的方式了,系统性能出现瓶颈的时候,首先要打开慢查询日志,进行跟踪,尽快的分析和排查出执行效率较慢的SQL ,及时解决避免造成不好的影响。
作用: 记录具体执行效率较低的SQL语句的日志信息。注意:
在默认情况下mysql的慢查询日志记录是关闭的。
同时慢查询日志默认不记录管理语句和不使用索引进行查询的语句
2.2 常用命令
2.2.1 开启慢查询日志
set global slow_query_log=1;
-- 只对当前数据库生效,如果重启后,则会失效
-- 如果想永久生效,必须修改配置文件
slow_query_log = 1
slow_query_log_file = 地址2.2.2查询是否开启慢查询日志
show variables like '%slow_query_log%'2.2.3 设置慢查询的阀值
-- 表示将查询执行时间超过 0.01 秒的查询记录为慢查询。
set long_query_time = 0.01;2.2.4 查询慢查询的阀值
show variables like 'long_query_time'2.2.5 设置慢日志文件位置
set global slow_query_log_file='E:\slowdata\\mysql.log';注: 加 global 关键字为全局
2.3 慢查询日志分析
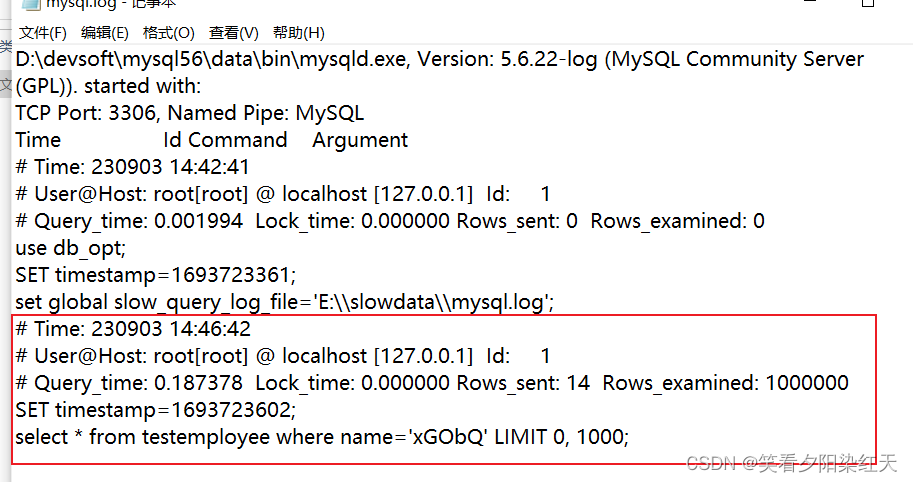
主要功能是, 统计不同慢sql的
出现次数(Count),
执行最长时间(Time),
累计总耗费时间(Time),
等待锁的时间(Lock),
发送给客户端的行总数(Rows),
扫描的行总数(Rows),
用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).
第三方可视化日志分析工具:mysqlsla,myprofi,pt-query-diges等等
三、 Explain (执行计划)
3.1概念及作用
使用explain关键字,可以模拟优化器执行的SQL语句
从而知道MYSQL是如何处理sql语句的
通过Explain可以分析查询语句或表结构的性能瓶颈
具体作用:
- 查看表的读取顺序
- 数据读取操作的操作类型
- 查看哪些索引可以使用
- 查看哪些索引被实际使用
- 查看表之间的引用
- 查看每张表有多少行被优化器执行
3.2 使用方法
-- 使用Explain关键字 放到sql语句前
explain select cus_id from testemployee where cus_id > 103.3 参数详解
主要记一下比较重要的参数 type、key、rows、Extra
3.3.1 type
要求:
一般来说,保证查询至少达到range级别
最好能达到ref

3.3.2 key
概念
实际使用的索引,如果为NULL,则没有使用索引,查询中若使用了覆盖索引 ,则该索引仅出现在key列表
possible_keys与key关系?
possible_keys是理论应该用到哪些索引 ,key是实际用到了哪些索引
什么是覆盖索引?
查询的字段和建立的字段刚好吻合,这种我们称为覆盖索引
3.3.3 rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,每长表有多少行被优化器查询过
3.3.4 Extra
注意:
语句中出现了Using Filesort 和 Using Temporary说明没有使用到索引,出现 impossible where说明条件永远不成立
Using Filesort:排序没有走索引直接获取,而是先经过条件查询,然后再对查询的结果进行排序
产生的值:
- Using filesort (需要优化):说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行,Mysql中无法利用索引完成排序操作称为"文件排序"。
- Using temporary (需要优化):使用了临时表保存中间结果,Mysql在对查询结果排序时, 使用了临时表,常见于排序orderby 和分组查询group by
- impossible where (需要优化):where 子句的值总是false 不能用来获取任何元组
- using where:表明使用了where过滤
- using join buffer:使用了连接缓存
















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











