






图像分割
图像语义分割: 对图像中每个像素赋予一个指定的标签
图像分割:泛指将图片划分为不同的区域,对每个区域的语义信息并没有要求。
一致性正则化😀
正则化:在模型的损失函数中增加惩罚项来增强模型的泛化能力,从而避免模型过拟合
一致性:相似的数据点具有相似的输出,即如果对于一个未标记数据在实际应用中发生扰动,其预测结果不应该发生显著变化,扰动前的预测结果与扰动后的预测结果没有太大差异,也就是输出结果具有一致性。
举例:那么一致性是什么意思呢?让我们回想一下聚类假设:假设这两个点在同一类(或者距离十分的接近),他们的输出也会接近。一致性就是为了使得训练的函数fθ有如下性质:任意给定两个输入和 ,假设他们的欧式距离足够近,那么他们的输出和能够相近。所以组合起来,一致性正则化,就是为了让函数能有这样的性质。
1、要解决什么问题?😁
- 模型容易过拟合.
- 模型在受到微小扰动(噪声)后, 预测结果会受相当程度的影响.
2、如何解决?😊
使构造的模型对这种扰动具有鲁棒性,通常最小化原始输入的预测与输入的扰动版本的预测之间的差异来实现。
方法可以是均方误差或KL散度或任何其它距离度量 。
3、最后要达到的效果?😃
能够防止过拟合,对于一个输入,即使受到微小干扰,其预测都应该是一致的。
给模型加入先验知识😎
1、要解决什么问题?🎉
在模型自动学习特征的时候,会拟合一些不重要特征而陷入局部非重要特征。
2、如何解决?🎇
可在模型中加入一些人为先验知识,让模型学习到这些关键特征。
主要方法:
1、在预训练模型中加入先验知识,让先验知识成为物体本身属性的一部分,例如颜色、文理、边缘信息等。
2、在模型输入端加入先验知识,与模型原来的输入融合成新的输入,即通过扩充输入的方法丰富训练数据。
3、直接给所加入的先验知识增加一个训练支路,这可以减轻后面回归任务的工作量。
4、通过加入外部环境信息作为物体的额外补充信息。
聚类🥇
概述:聚类属于无监督学习,聚类使用算法将样本分为N个群落,群落内部相似度较高,群落之间相似度低。通常采用距离来度量样本间的相似度,距离越小相似度越高,距离越大相似度越低。
常用相似度度量方法:
1、欧式距离

2、曼哈顿距离
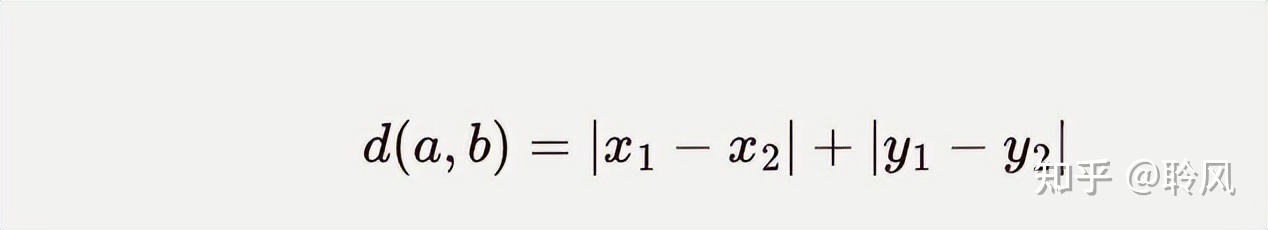
3、闵可夫斯基距离
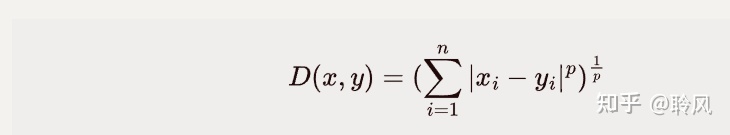
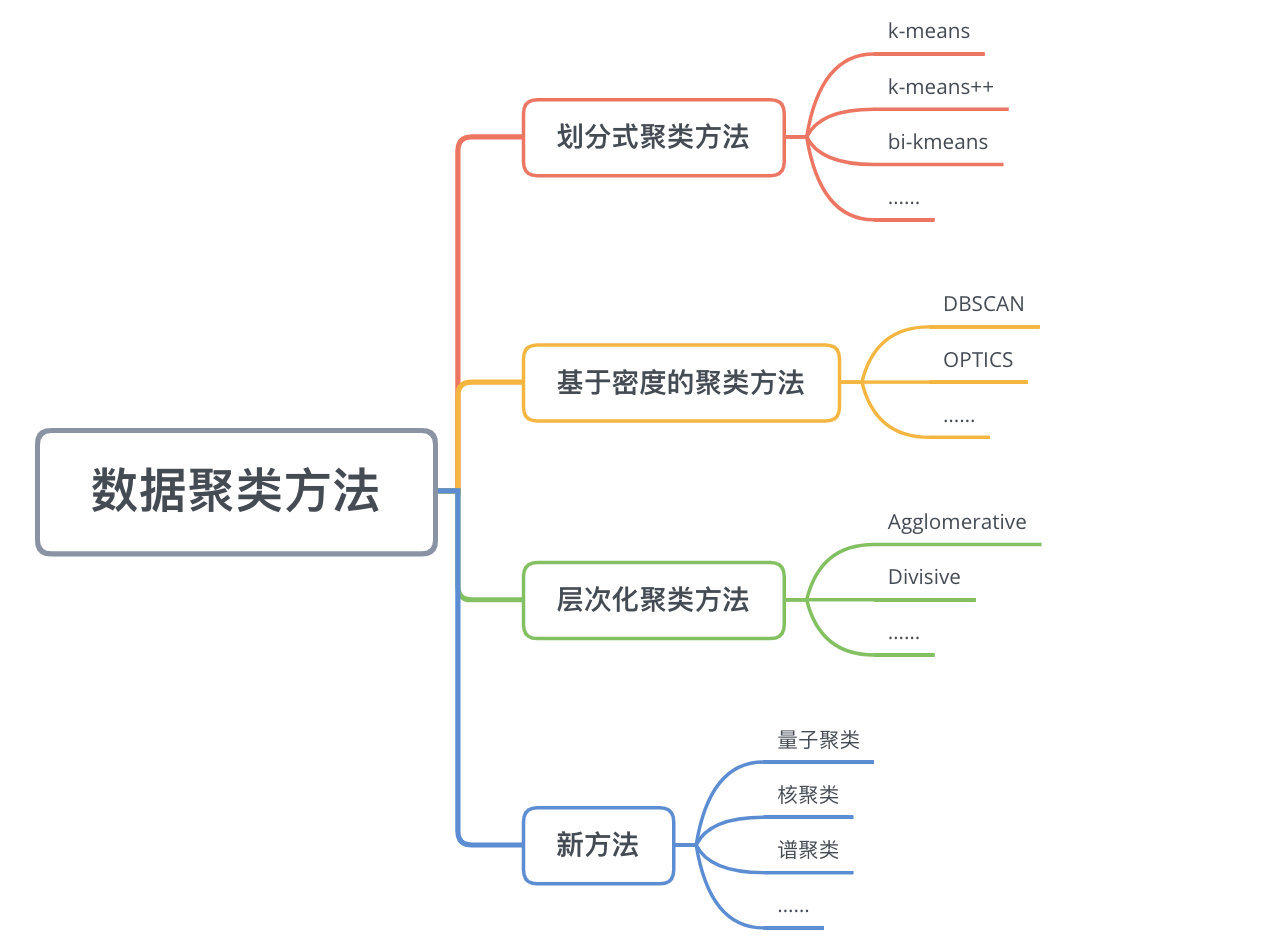
聚类算法分类🎈
原型聚类、层次聚类、密度聚类
常用聚类算法🎉
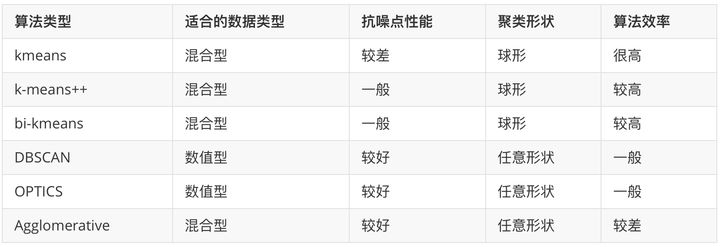
聚类模型的评价指标:
理想的聚类模型为内疏外密,内部紧密相连,类别之间距离足够疏远,常用轮廓系数S(i)来衡量。
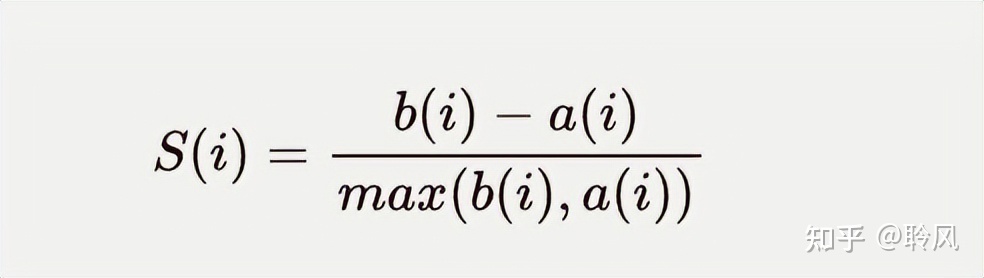
当S(i)趋近于1时,聚类效果最好;
当S(i)趋近于-1时,聚类效果最差;
当S(i)趋近于0时,说明出现重叠。
计算机视觉领域顶级会议与顶级期刊总结😁

















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











