







聚类模型
“物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。
聚类和分类的区别:分类是已知类别的,聚类未知。
目录
一. K-means聚类算法
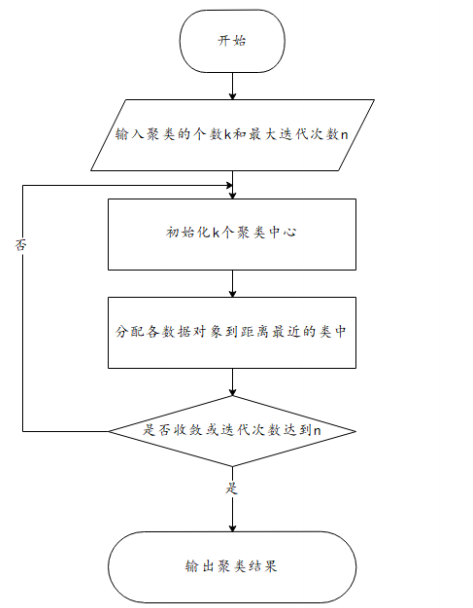
1.流程
- 指定需要划分的簇的个数K值(类的个数);
- 随机地选择K个数据对象作为初始的聚类中心(不一定要是我们的样本点);
- 计算其余的各个数据对象到这K个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中;
- 调整新类并且重新计算出新类的中心;
- 循环步骤三和四,看中心是否收敛(不变),如果收敛或达到迭代次数则停止循环;
- 结束。
2.图解 K-means

3.算法优缺点
优点:
- 算法简单、快速。
- 对处理大数据集,该算法是相对高效率的。
缺点:
- 要求用户必须事先给出要生成的簇的数目k
- 对初值敏感
- 对于孤立点数据敏感
K‐means++算法可解决2和3这两个缺点。
二.K-means++聚类算法
K-means++算法选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。
1.流程
- 随机选取一个样本作为第一个聚类中心;
- 计算每个样本与当前已有聚类中心的最短距离(即与最近一个聚类中心的距离),这个值越大(距离越大),表示被选取作为聚类中心的概率较大;最后,用轮盘法(依据概率大小来进行抽选)选出下一个聚类中心;
- 重复步骤二,直到选出 K 个聚类中心。选出初始点后,就继续使用标准的 K-means 算法了。
2.图解K-means++
假设平面内存在5个点,随机选取 A 为聚类中心作为第一个聚类中心,
计算其余 4 个样本与当前聚类中心的最短距离,这个值越大,表示被选取作为聚类中心的概率较大(如图1)。
利用轮盘法选择 D 作为第二个聚类中心(也可以选择E)。
选择 D 作为第二个聚类中心,求第一个聚类中心 A 与第二个聚类中心 D 的重心,并将其作为一个虚拟的聚类中心,求其他三个点B、C、E到 虚拟聚类中心 的距离,并计算相对的概率(如图2),
并用轮盘法选择下一个聚类中心… 直到选择出 K 个聚类中心然后进行 K-means 算法。

3.算法缺点
- K-means++算法虽解决了 K-means 算法的初值敏感、边界值敏感两种问题。但 K 还是需要手动选取,所以 K 应该取决于个人的经验与感觉,多尝试几组即可。
- 量纲不一致,也会出现问题,因此,需要用以下公式进行演算。zi=(xi-x平均)/x标准差,即减去均值再除以标准差。 即可消除量纲影响,当然也可以用 SPSS 进行操作。
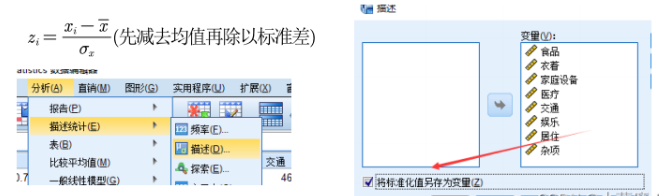
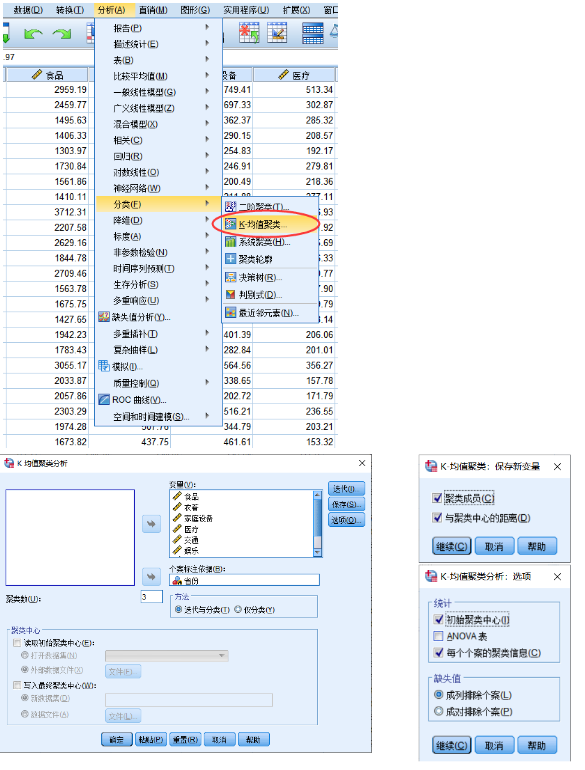
4.SPSS操作
分析 → 分类 → K-均值聚类,这里默认使用 K-means++算法。保存和选项的勾选项如下图:
三.系统(层次)聚类算法
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。此外,系统聚类可以解决簇数 K 的取值问题,后文会给出 SPSS 操作的流程。

1.样本与样本的距离
例:下表是30个学生的六门课的成绩。根据这30个人的成绩,对这30个学生进行分类。

样本与样本之间的常用距离(样本 i与样本 j):

例:


2.指标与指标之间的距离
例:根据这30个人的成绩,将六门课程分为两类。
指标与指标之间的常用距离(指标 i 与指标 j )

用的比较少,了解即可。
3.类与类之间的距离
类与类之间的距离就是集合与集合之间的距离。
类与类之间的距离有如下两个属性:
- 由一个样品组成的类是最基本的类;如果每一类都由一个样品组成,那么样品间的距离就是类间距离。
- 如果某一类包含不止一个样品,那么就要确定类间距离,类间距离是基于样品间距离定义的。

- 最短距离法:

- 最长距离法:
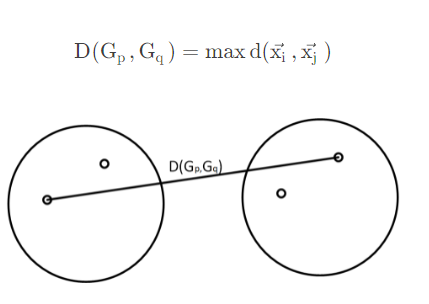
- 最长距离法:
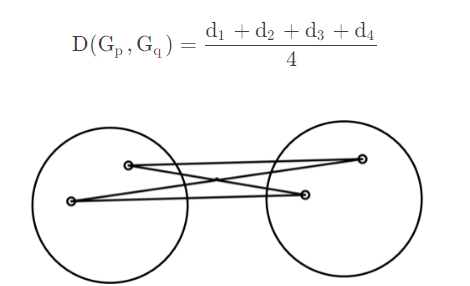
- 组内平均连接法:

重心法:
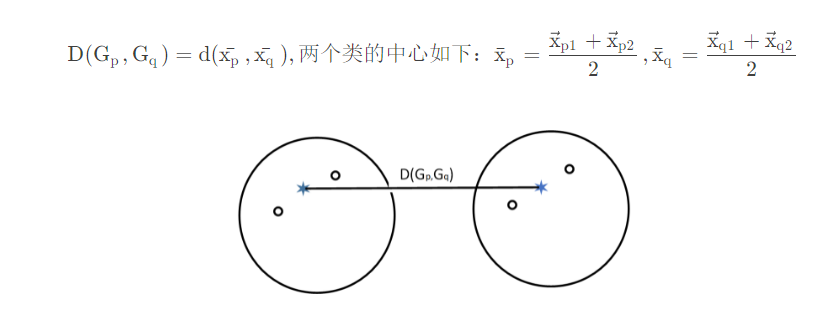
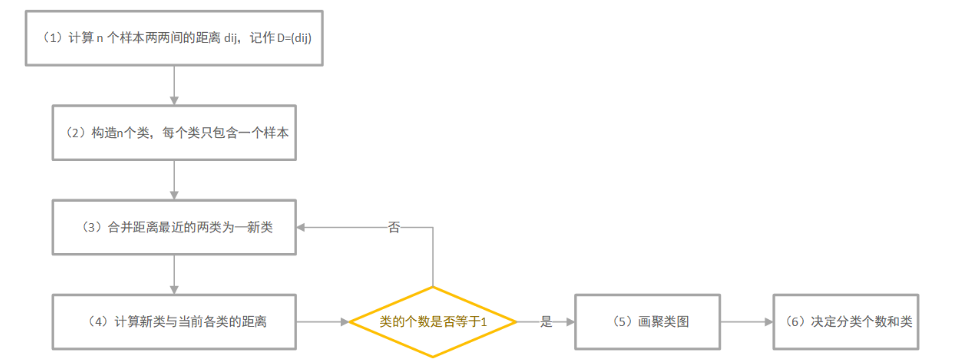
4.系统聚类法流程
流程图如下:
5.案例分析
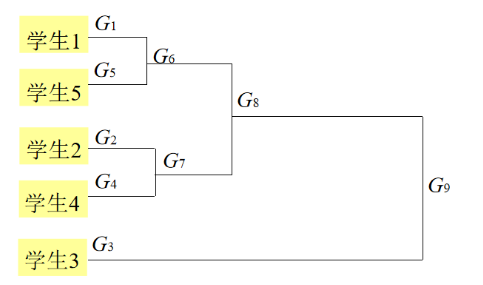
根据五个学生的六门课的成绩,对这五个学生进行分类。
1.写出样品间的距离矩阵(以欧氏距离为例)

2.将每一个样品看做是一个类,即 G1,G2,G3,G4,G5。观察 D(G1,G5)=15.8最小,故将 G1 与 G5 聚为一类,记为G6。计算新类与其余各类之间的距离,得到新的距离矩阵D1。
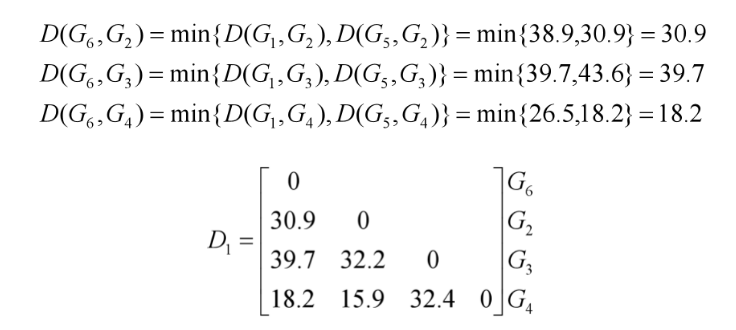
3.观察 D(G2,G4)=15.9 最小,故将G2与G4聚为一类,记为G7。计算新类与其余各类之间的距离,得到新的距离矩阵D2。
4.观察 D(G6,G7) =18.2最小,故将G6与G7聚为一类,记为G8。 计算新类与其余各类之间的距离,得到新的距离矩阵 D3。

5.最后将G8与G3聚为一类,记为G9
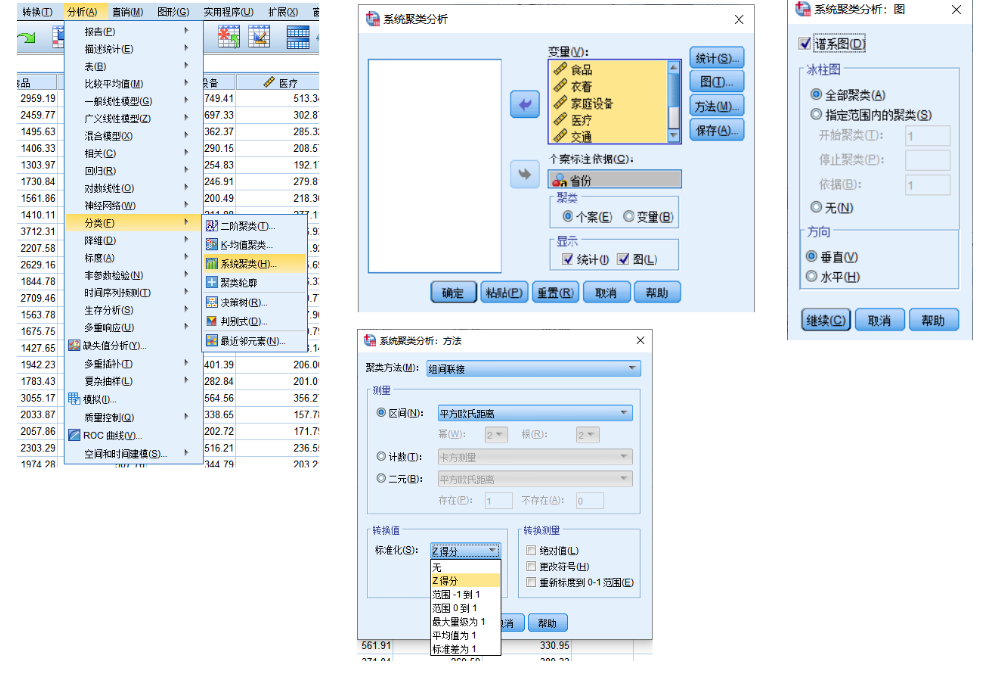
SPSS操作
分析 → 分类 → 系统聚类,将变量与标注依据分别加入到对应的组中。 保存图示如下,方法中的标准化,如果量纲不同,则选择 Z 得分。
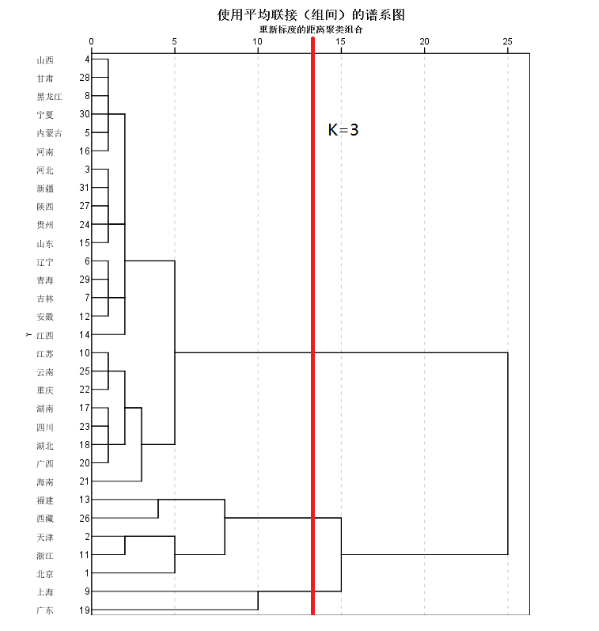
结果分析:
SPSS运行出的谱系图,可根据自己的需求划分出要聚类的个数,方法是画竖线,如下图,将样本化分为 3 类。第一类是广东、上海,第二类是北京、浙江、天津、西藏、福建,第三类是其余的省份。(这道例题选取:1999年全国31个省份城镇居民家庭平均每人全年消费性支出数据 )
四.肘部法则
肘部法则是通过图形大致的估计出最优的聚类数量。应用了SPSS输出文档中的集中计划中的系数,需要将系数进行排序之后,应用 excel 生成图像,如下图:

从上图可以看出 K 取1到5时,畸变程度变化最大。超过5以后,畸变程度变化显著降低。因此 K可以取 5,当然 3 也可以,只要给出理由。
确定 K 之后,即可重新聚类,注意保存中选取单个解为 K 的值。如 K=3: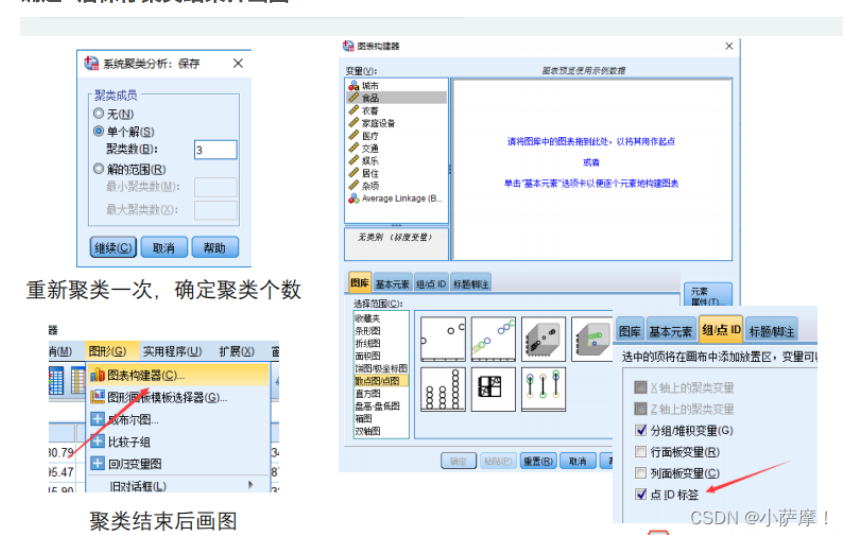
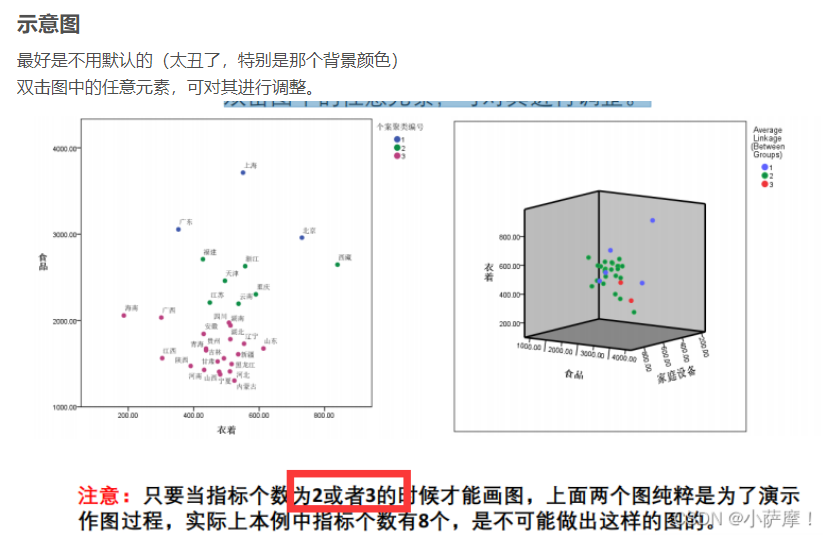
五.DBSCAN聚类算法
DBSCAN(Density-based spatial clustering of applications with noise)是Martin Ester, Hans-PeterKriegel等人于1996年提出的一种基于密度的聚类方法,聚类前不需要预先指定聚类的
个数,生成的簇的个数不定(和数据有关)。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。
该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据。

1.基本分类
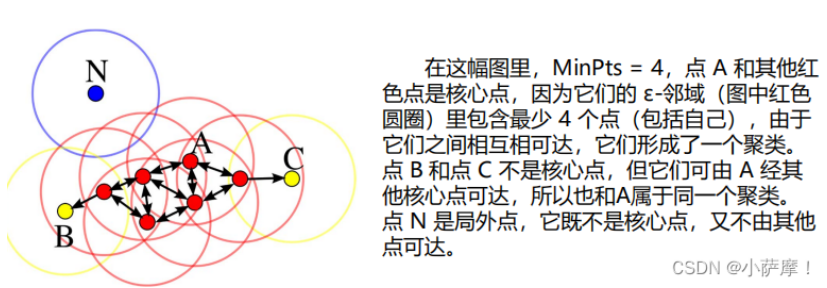
DBSCAN算法将数据点分为三类:
- • 核心点:在半径Eps内含有不少于MinPts数目的点
- • 边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
- • 噪音点:既不是核心点也不是边界点的点
2.优缺点
优点:
- 基于密度定义,能处理任意形状和大小的簇;
- 可在聚类的同时发现异常点;
- 与K-means比较起来,不需要输入要划分的聚类个数。
缺点:
- 对输入参数ε和Minpts敏感,确定参数困难;
- 由于DBSCAN算法中,变量ε和Minpts是全局唯一的,当聚类的密度不均匀时,聚类距离相差很大时,聚类质量差;
- 当数据量大时,计算密度单元的计算复杂度大。
六.总结
- K-means 算法对分类问题的处理简单、快速,而且对处理大数据集,该算法是相对高效率的。
- K-means++算法对K-means算法初始化K个聚类中心这一步进行了优化,但是确定 K 值还需要进一步讨论。实际上对 K 值的选取,应用层次聚类可以解决。
- 只有两个指标,且你做出散点图后发现数据表现得很“DBSCAN”,这时候你再用DBSCAN进行聚类。其他情况下,全部使用系统聚类吧。
- 聚类方法的不同,聚类结果一般也不同(尤其是样品特别多的时候)。最好能通过各种方法找出其中的共性。
- 要注意指标的量纲,量纲差别太大会导致聚类结果不合理。
- 聚类分析的结果可能不令人满意,因为我们所做的是一个数学的处理,对于结果我们要找到一个合理的解释。















 1297
1297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











