






一.设置好编辑环境
使用selenium时配置好浏览器插件确保在同一目录下并且与浏览器是同一版本,以谷歌为例子,下载好对应浏览器的版本。其次使用pycharm进行代码编辑。
安装驱动(windows系统)
写得挺详细就不写了。
二.上实例
1.对网站第一页进行观察
我爬取数据使用的地址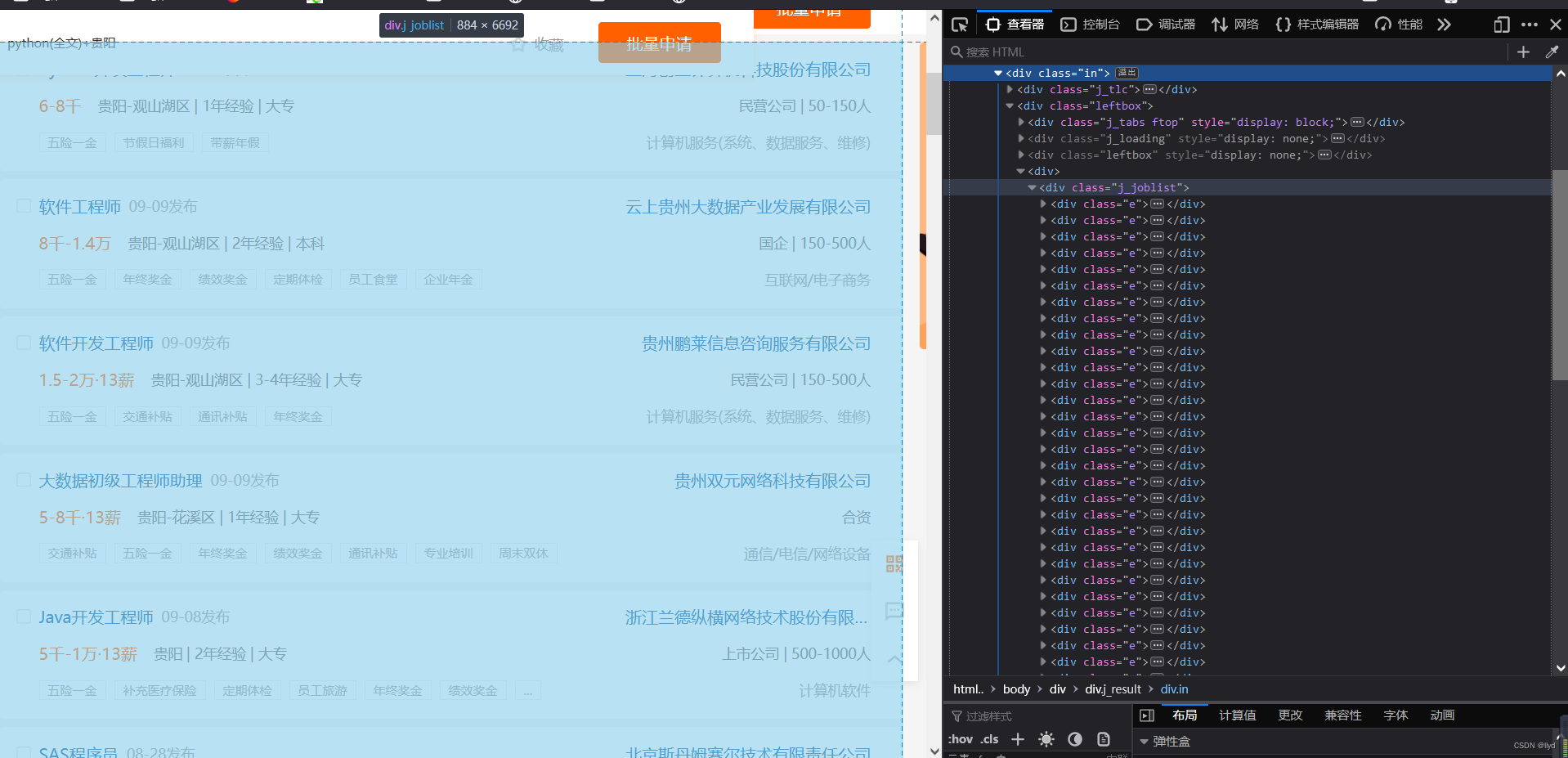
你会发现所有第一页的数据在同一class:j_joblist中,然后继续观察
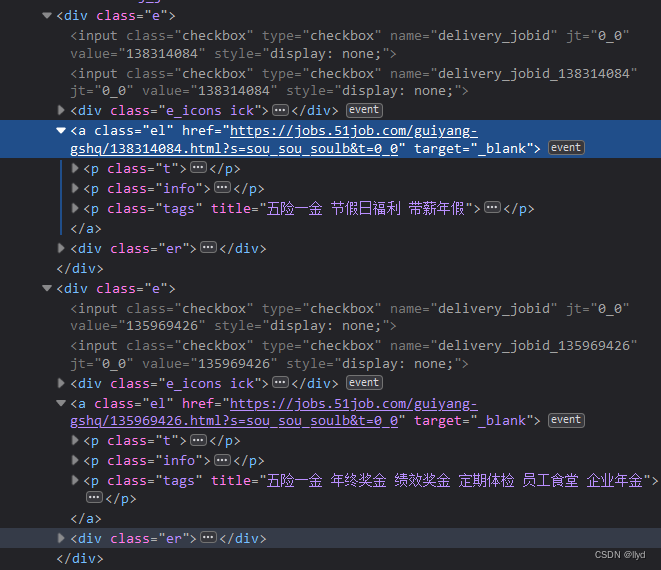
你会再次发现网页数据都在同一标签中,那么获取数据就相当容易了,也不用去抓包等等。
2.然后对第二页及n页进行观察

会发现
每一页只有一个的div数字不一样,使用遍历,想要多少页就获取多少页
2.进行代码编写
def parse_data():
divs=driver.find_elements_by_xpath('.//div[@class="j_joblist"]/div')
for div in divs:
for i in range(1,51):
title = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[1]/span[1]').text # 标题`
price = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[2]/span[1]').text # 价格
business = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/div[2]/a').text # 店名
location = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[2]/span[2]').text # 地名
detail_url=div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/div[2]/a').get_attribute('href')#网址
print(title,price,business,location,detail_url)
dit = {
'标题': title,
'价格':price,
'店名': business,
'地名': location,
'网址': detail_url,
}
csv_writer.writerow(dit)
print(title,price,business,location,detail_url)
执行就可以获取到固定的数据

当然前面的导入包等等没去载图出来,还要模拟人工操作浏览器滑动,不然容易报错
for x in range(1, 30, 4): # 1 3 5 7 9 在你不断的下拉过程中, 页面高度也会变的
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)
最后进行数据的收集保存到表格中
f = open(f'qc.csv', mode='a', encoding='utf-8', newline='')
# 快速替换小技巧 选择要替换内容 按住ctrl + R 输入 正则表达式匹配规则 替换
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'价格',
'店名',
'地名',
'网址',
])
最后进行数据的收集保存到表格中写入表头
3.最后综合代码进行运行
from selenium import webdriver
import time
import csv
f = open(f'qc.csv', mode='a', encoding='utf-8', newline='')
# 快速替换小技巧 选择要替换内容 按住ctrl + R 输入 正则表达式匹配规则 替换
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'价格',
'店名',
'地名',
'网址',
])
csv_writer.writeheader()
def drop_down():
"""执行页面滚动的操作""" # javascript
for x in range(1, 30, 4): # 1 3 5 7 9 在你不断的下拉过程中, 页面高度也会变的
time.sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f' % j
driver.execute_script(js)
driver=webdriver.Chrome()
driver.get('https://search.51job.com/list/260200,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=')
drop_down()
time.sleep(3) # 延时三秒钟
def parse_data():
divs=driver.find_elements_by_xpath('.//div[@class="j_joblist"]/div')
for div in divs:
for i in range(1,51):
title = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[1]/span[1]').text # 标题`
price = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[2]/span[1]').text # 价格
business = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/div[2]/a').text # 店名
location = div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/a/p[2]/span[2]').text # 地名
detail_url=div.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div['+str(i)+']/div[2]/a').get_attribute('href')#网址
print(title,price,business,location,detail_url)
dit = {
'标题': title,
'价格':price,
'店名': business,
'地名': location,
'网址': detail_url,
}
csv_writer.writerow(dit)
print(title,price,business,location,detail_url)
for page in range(0,20):
print(f'------正在爬第{page+1}页-----')
parse_data()
time.sleep(2)
driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[2]/div/div/div/ul/li[8]/a').click()
运行成功你会发现同文件目录下多了一个qc.csv的文档,点开你就可以看到获取到的数据。

然后就成功了 这个网站比较容易没有那么复杂。
总结:
第一次写,后面还会继续更新,希望对正在学的小伙伴有所帮助。
















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











