







爬取前程无忧51job网上全国“python”关键字所对应的岗位招聘信息
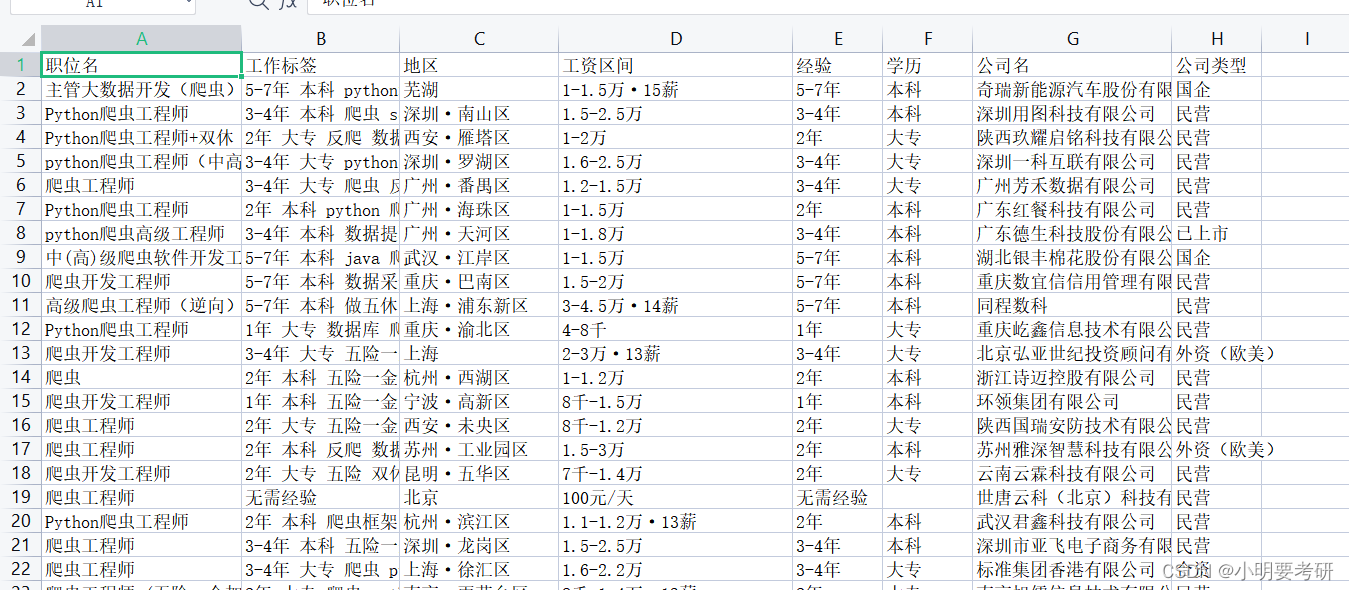
利用Requests和正则表达式方法,爬取前程无忧51job网站上全国“爬虫”关键字对应岗位的所有招聘信息,如下图所示,把爬取到的招聘数据存储在当前工程目录下的“51job.csv”文件中,需要爬取的信息有:职位名、公司名、工作地点、薪资和发布时间 。
标题思路分析:(1)导入第三方库;(2)指定url;(3)设置携带参数;(4)发起请求;(5)用正则表达式定位标签;(6)输出结果。
难点:翻页,抓包,以及解密的方法,其实没有涉及到正则表达式,用的json。
爬取的结果:
代码:
import csv
import json
import re
import requests
import pprint
import requests
import hmac
from hashlib import sha256
import time
f =open('前程无忧数据2.csv',mode='a',encoding&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2347
2347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









