







安装geomesa-hbase
-
将geomesa-hbase_2.11-3.4.0-bin.tar.gz上传到xshell
-
解压geomesa-hbase_2.11-3.4.0-bin.tar.gz
tar -zxvf geomesa-hbase_2.11-3.4.0-bin.tar.gz
- 配置环境变量
vim .bashrc
添加如下内容:
#geomesa_hbase
export GEOMESA_HBASE_HOME=/home/ZQ/geomesa-hbase_2.11-3.4.0
export PATH=$PATH:$GEOMESA_HBASE_HOME/bin

使环境变量生效
source .bashrc

- 部署GeoMesa-HBase分布式运行jar
geomesa-hbase需要使用本地过滤器来加速查询,因此需要将GeoMesa的runtime JAR包,拷贝到
HBase的库目录下
cd geomesa-hbase_2.11-3.4.0/
cp ./dist/hbase/geomesa-hbase-distributed-runtime-hbase1_2.11-3.4.0.jar /home/ZQ/hbase-1.4.13/lib/

- 注册协处理器
GeoMesa利用服务器端处理来加速某些查询。具体实现:
在HBase的配置文件hbase-site.xml添加如下内容:
cd hbase-1.4.13/conf
vim hbase-site.xml
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.locationtech.geomesa.hbase.coprocessor.GeoMesaCoprocessor</value>
</property>


- 设置命令行工具
将HBase配置文件hbase-site.xml打包进geomesa-hbase-datastore_2.11-$VERSION.jar中:
cd geomesa-hbase_2.11-3.4.0/
zip -r lib/geomesa-hbase-datastore_2.11-hbase1_2.11-3.4.0.jar /home/ZQ/hbase-1.4.13/conf/hbase-site.xml

- 进入到${GEOMESA_HBASE_HOME},运行:
./bin/install-shapefile-support.sh

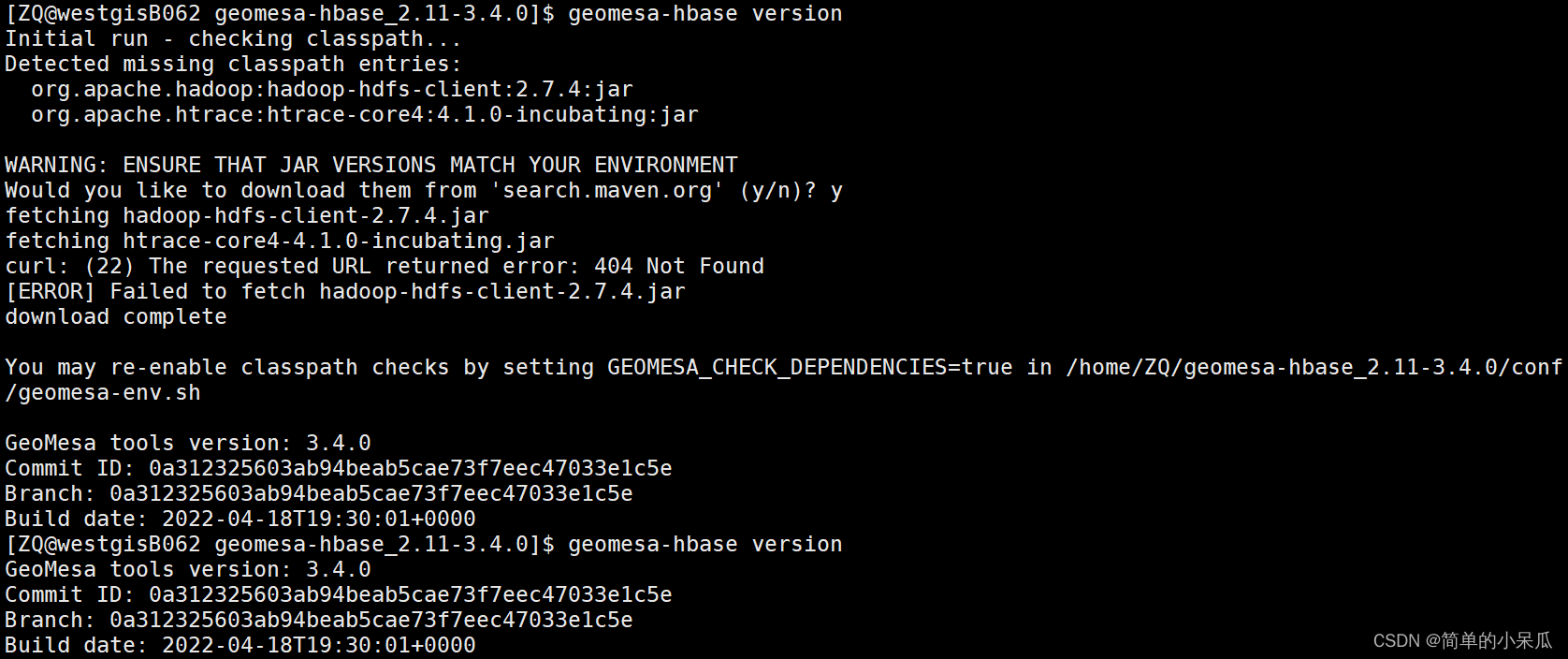
- 测试是否安装成功
geomesa-hbase version
时空索引
导入数据相关链接:GeoMesa命令行,索引概述_爱是与世界平行-程序员信息网
导入数据官方链接:8.3. Ingest Commands
定义特征类型官方链接:8.6. Defining Simple Feature Types
转换器官方链接:9. GeoMesa Convert
- 数据准备
在${GEOMESA_HBASE_HOME}下新建data目录,进入data目录创建data.csv
mkdir data
cd data
vim data.csv
在data.csv中增加如下内容:
AAA,red,113.918417,22.505892,2017-04-09T18:03:46
BBB,white,113.960719,22.556511,2017-04-24T07:38:47
CCC,blue,114.088333,22.637222,2017-04-23T15:07:54
DDD,yellow,114.195456,22.596103,2017-04-21T21:27:06
EEE,black,113.897614,22.551331,2017-04-09T09:34:48

- 定义特征类型
vim conf/myschema.sft
在文件中增加如下内容
geomesa = {
sfts = {
example = {
type-name = "example"
attributes = [
{ name = "carid", type = "String", index = true }
{ name = "color", type = "String", index = false }
{ name = "double_0", type = "Double", index = false }
{ name = "double_1", type = "Double", index = false }
{ name = "time", type = "Date", index = false }
{ name = "geom", type = "Point", index = true,srid = 4326,default =
true }
]
}
}
}

- 定义转换器
vim conf/testconvertor.convert
在文件中增加如下内容
geomesa.converters.example = {
"fields" : [
{
"name" : "carid",
"transform" : "toString($1)"
},
{
"name" : "color",
"transform" : "toString($2)"
},
{
"name" : "double_0",
"transform" : "toDouble($3)"
},
{
"name" : "double_1",
"transform" : "toDouble($4)"
},
{
"name" : "time",
"transform" : "isoDateTime($5)"
},
{
"name" : "geom",
"transform" : "point($double_0,$double_1)"
}
],
"format" : "CSV",
"id-field" : "md5(string2bytes($0))",
"options" : {
"encoding" : "UTF-8",
"error-mode" : "skip-bad-records",
"parse-mode" : "incremental",
"validators" : [
"index"
]
},
"type" : "delimited-text"
}

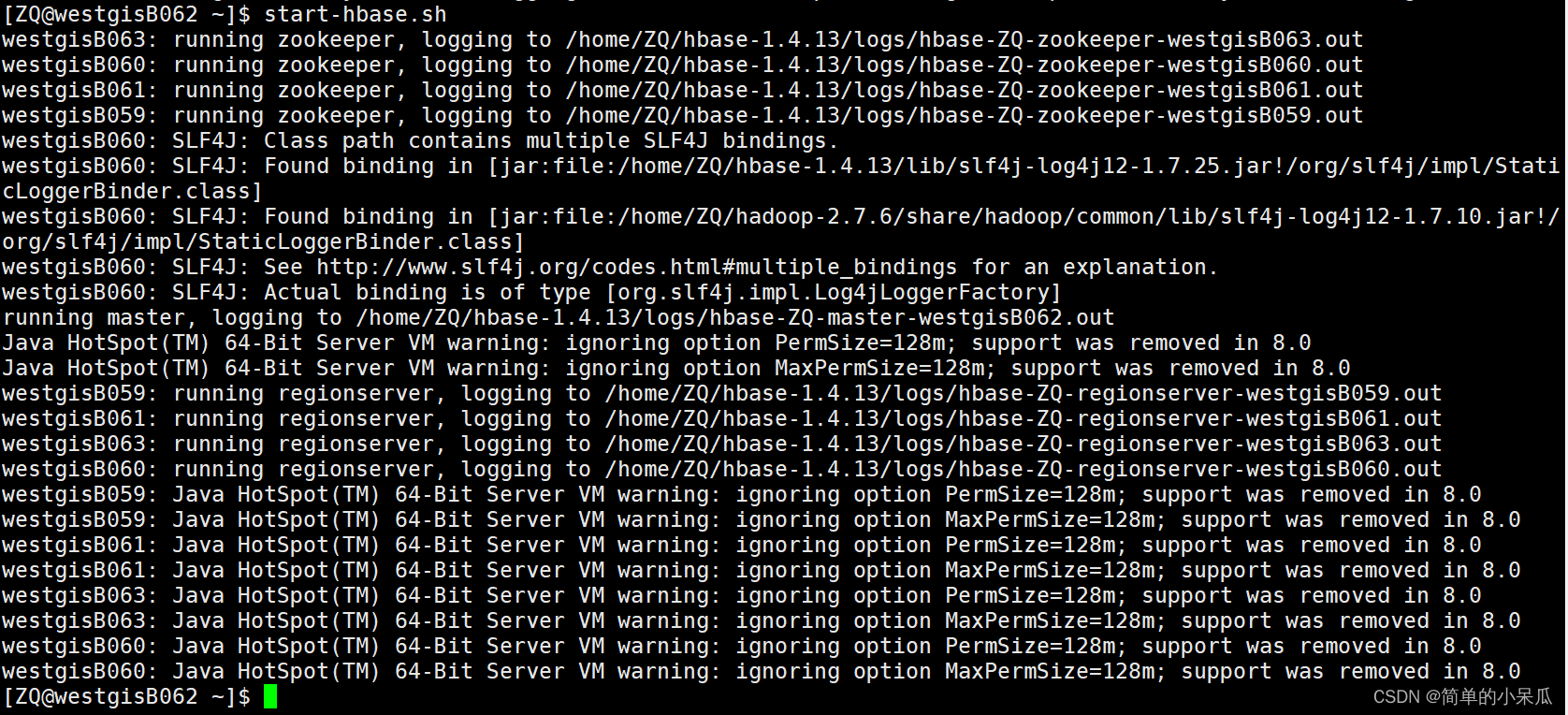
- 导入数据
启动HDFS和HBase
start-dfs.sh

start-hbase.sh
geomesa-hbase ingest --catalog geomesa01 --feature-name cars20 --input-format csv -C conf/testconvertor.convert -s conf/myschema.sft "data/data.csv"

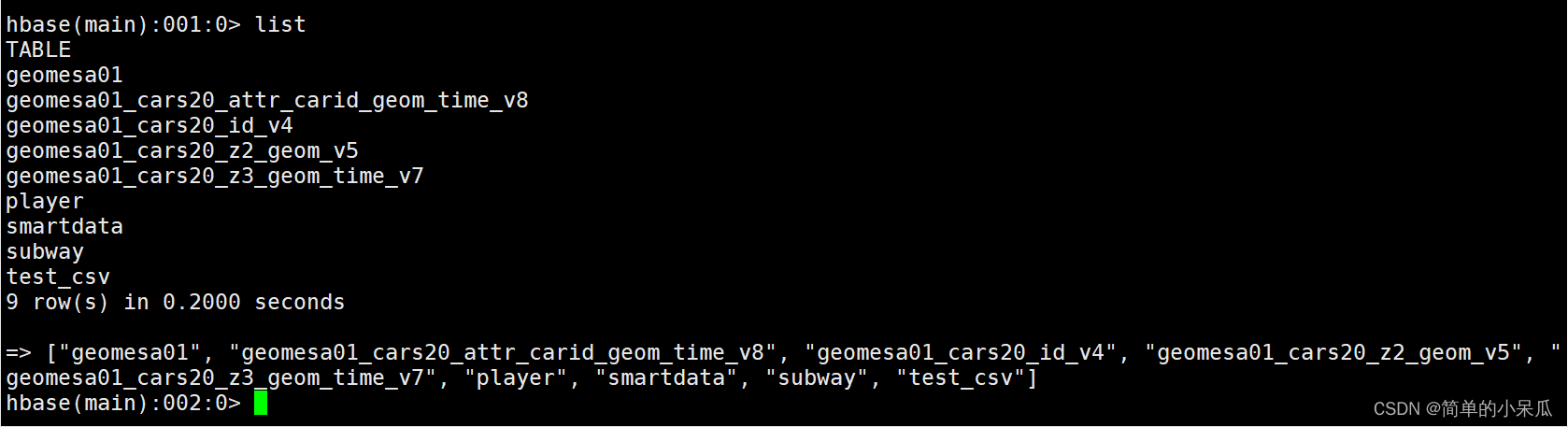
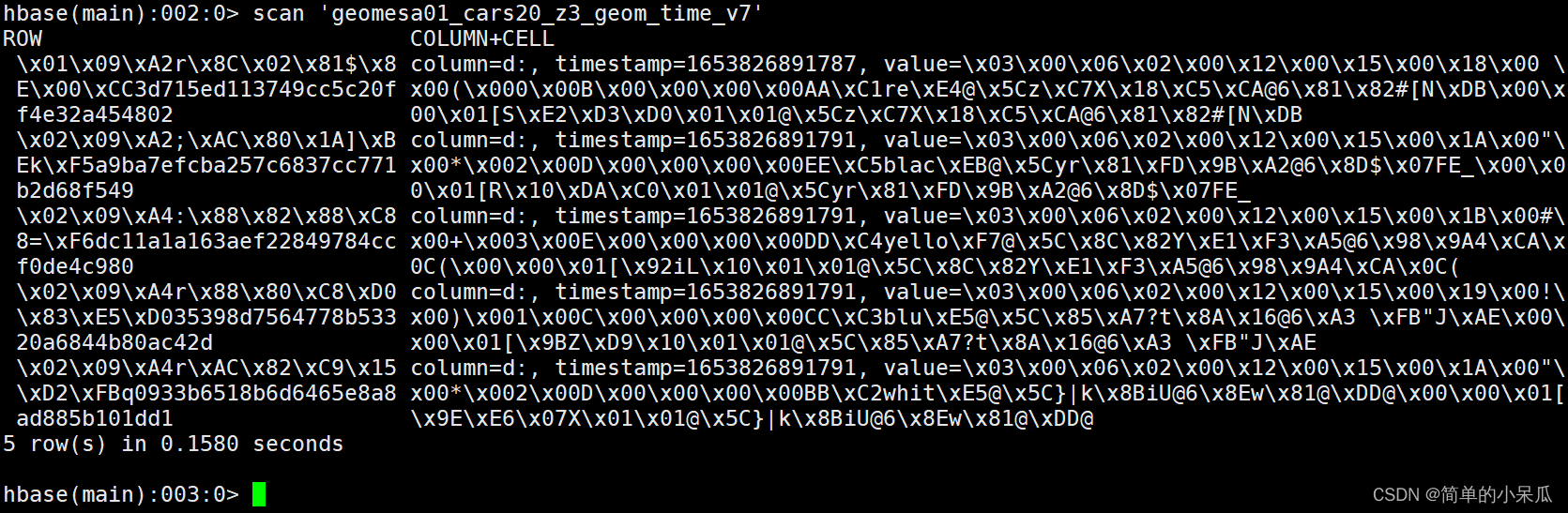
- 进入hbase shell查看导入的数据
Z2/Z3指示了Geomesa的索引方式(Z2:空间索引;Z3:时空索引)
hbase shell
list
scan 'geomesa01_cars20_z3_geom_time_v7'
KNN查询
- 将GeoSparkModified解压到指定目录
unzip GeoSparkModified-master.zip
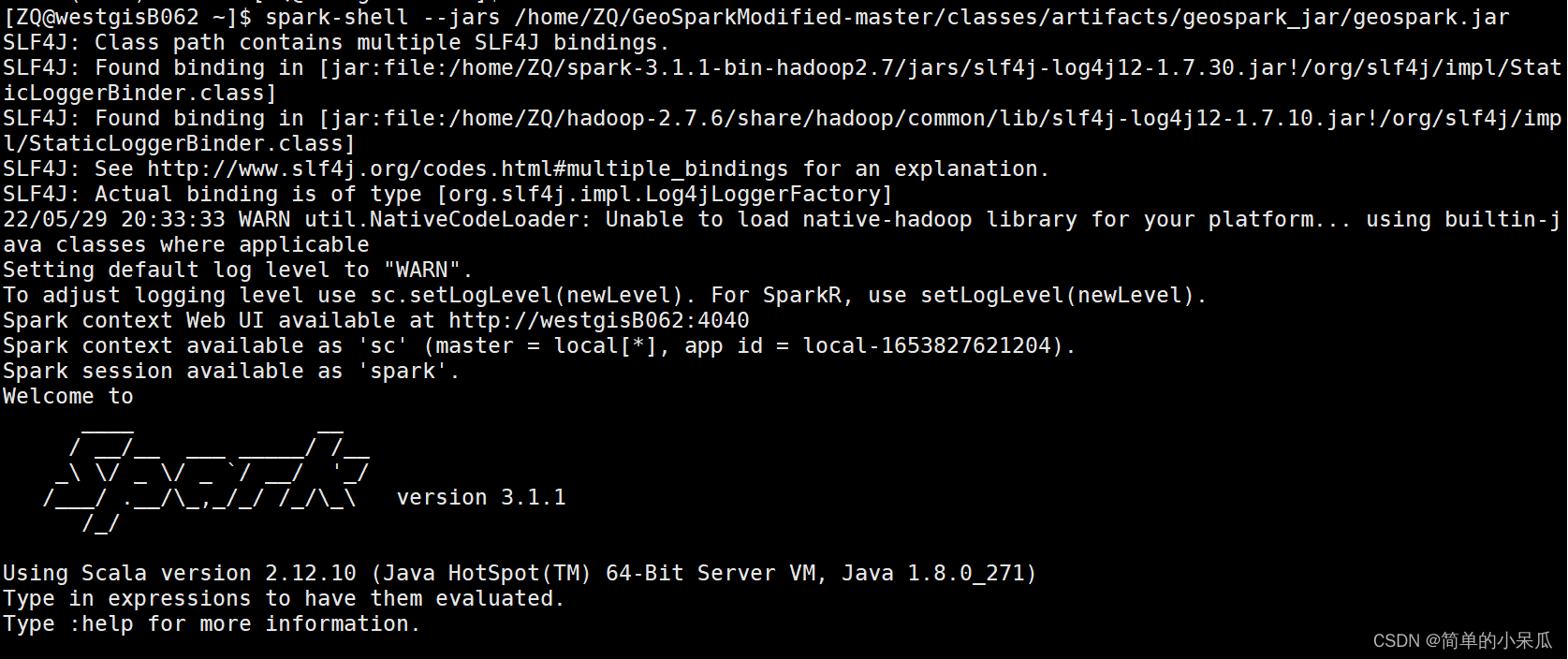
- 使用geospark.jar作为依赖项运行Spark shell
spark-shell --jars /home/ZQ/GeoSparkModified-master/classes/artifacts/geospark_jar/geospark.jar
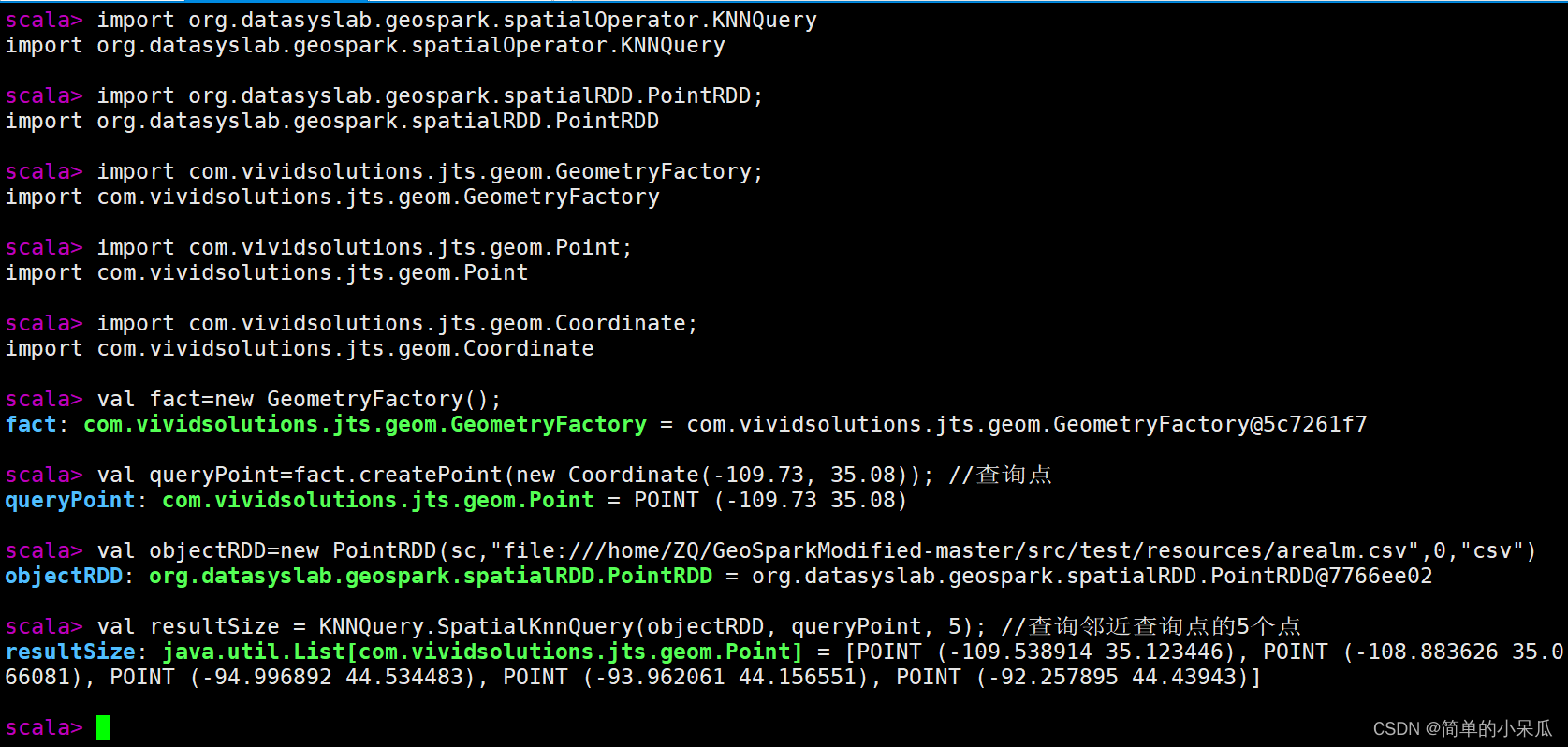
- 导包运行KNN查询代码
/home/ZQ/GeoSparkModified-master/src/test/resources/arealm.csv文件中含
有121960条经纬度
import org.datasyslab.geospark.spatialOperator.KNNQuery
import org.datasyslab.geospark.spatialRDD.PointRDD;
import com.vividsolutions.jts.geom.GeometryFactory;
import com.vividsolutions.jts.geom.Point;
import com.vividsolutions.jts.geom.Coordinate;
val fact=new GeometryFactory();
val queryPoint=fact.createPoint(new Coordinate(-109.73, 35.08)); //查询点
val objectRDD=new PointRDD(sc,"file:///home/ZQ/GeoSparkModified-master/src/test/resources/arealm.csv",0,"csv")
val resultSize = KNNQuery.SpatialKnnQuery(objectRDD, queryPoint, 5); //查询邻近查询点的5个点
关闭HBase和HDFS
stop-hbase.sh
stop-dfs.sh
















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









