






 文章探讨了一种结合聚类感知和多关系图的网络嵌入方法,通过计算节点属性和结构相似度,实现跨关系的随机游走策略。文章还介绍了多种图学习模型,如BernNet、URAMN、DisentangledMultiplexGraphRepresentationLearning等,强调了公共信息提取、私有信息约束和对比学习在多模态网络表示学习中的作用。
文章探讨了一种结合聚类感知和多关系图的网络嵌入方法,通过计算节点属性和结构相似度,实现跨关系的随机游走策略。文章还介绍了多种图学习模型,如BernNet、URAMN、DisentangledMultiplexGraphRepresentationLearning等,强调了公共信息提取、私有信息约束和对比学习在多模态网络表示学习中的作用。
1. Attributed multiplex graph clustering: A heuristic clustering-aware network embedding approach
这篇文章讲述了一种跨关系随机游走的策略,其核心是跨多关系的聚类感知随机游走节点样本策略,以捕获连接节点和不同关系之间的聚类感知交互信息,并将skip-gram 从单层图网络扩展到属性复用图网络。其流程如下图:
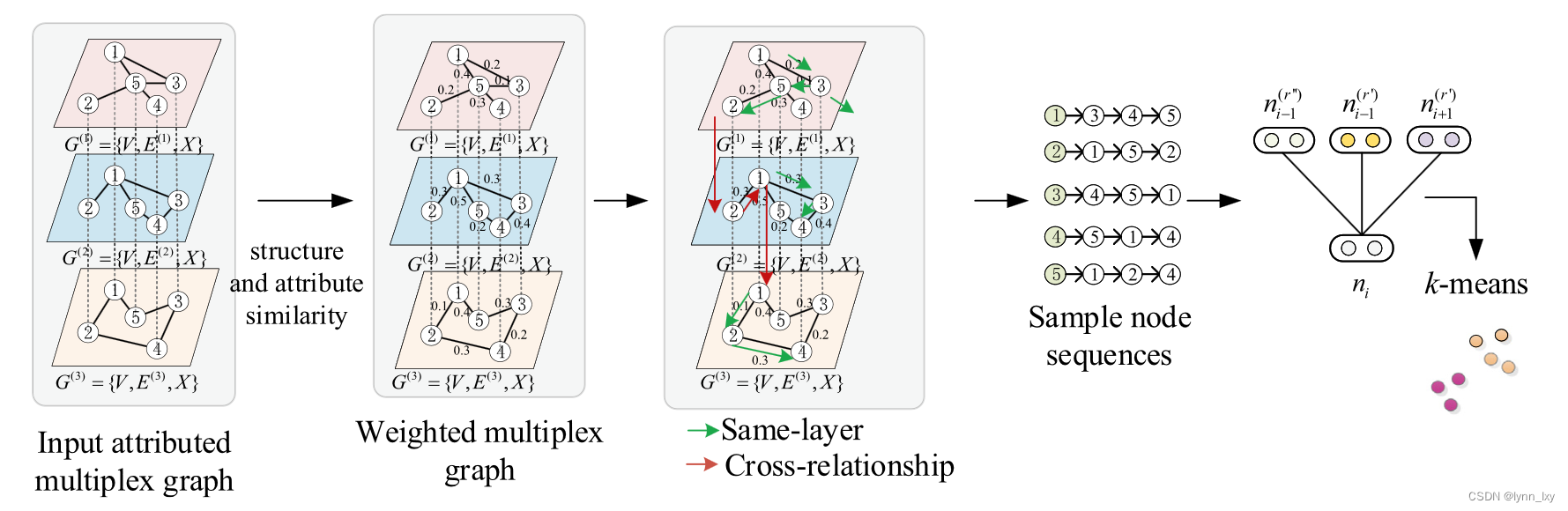
如图,对于连接节点之间的聚类感知交互信息,本文首先计算每个关系的连接节点之间的节点属性相似度和局部图结构相似度。连接节点之间的权重是根据这两个相似度的加权线性组合来分配的。然后,根据多关系图网络中每个关系的信息级别,使用所提出的启发式聚类感知跨多关系随机游走采样策略来对所有节点的聚类感知交叉关系节点序列进行采样。随后,skip-gram 模型从单层图网络扩展到多重图网络,将获得的聚类感知信息转换为图网络每个节点的低维密集节点嵌入。节点嵌入包含连接节点之间的聚类感知结构和属性相似性,用于增强图聚类、不同关系之间的交互以及聚类感知信息图关系。
下面是本文在模型中应用的主要公式,首先是节点的属性相似度的计算:
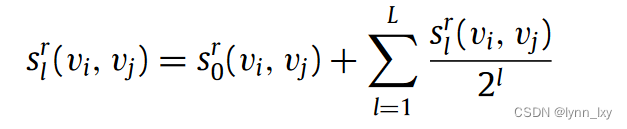
节点的局部结构相似性:
综合上述两个公式,得到The generation of a clustering-aware weighted multiplex graph
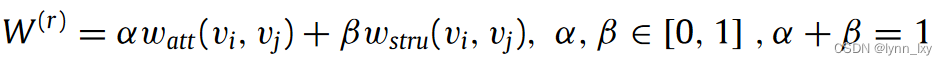
watt由第一个公式计算可得,wstru由第二个公式计算可得。
接下来是异构图中的随机游走器,

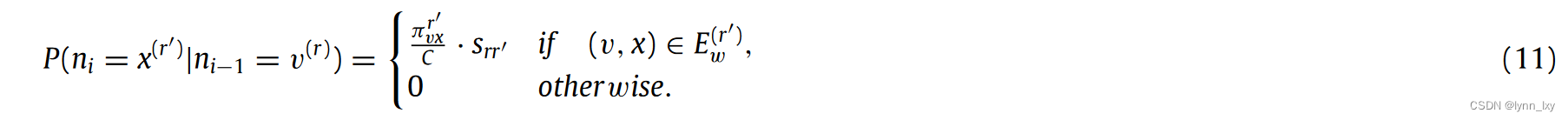
公式(9)是统一关系间的转移概率,(11)是不同关系间的转移概率
关于不同关系间专业概率的参数,计算方法如下:
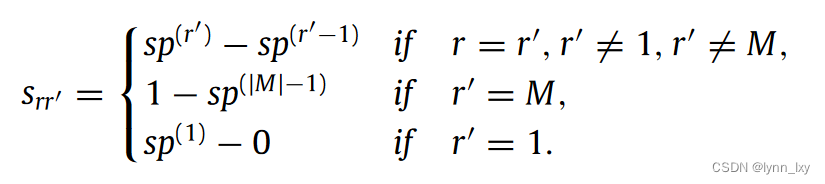
sp的值取决于图的模块化度,
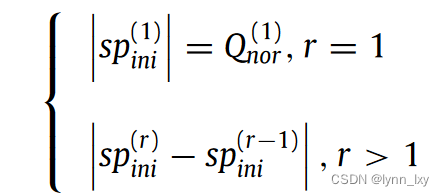
其中Q的计算方法为
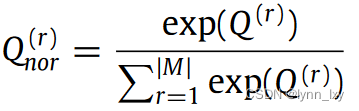
优化函数如下,使用了随机梯度下降(SGD)
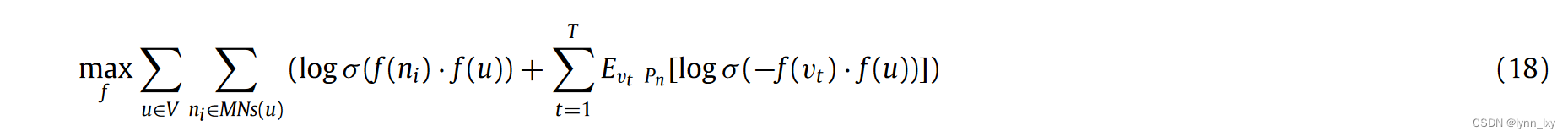
整体的算法的流程:

2. Unsupervised Representation Learning on Attributed Multiplex Network
这篇文章融合的点比较多,比如说图滤波器BernNet替代图卷积网络来进行编码,以及对图对比学习的改进,交替应用局部和全局对比学习来同时更新视图特定嵌入和共识嵌入,利用共识嵌入来融合不同关系的节点嵌入。本文所提出的模型名为URAMN。
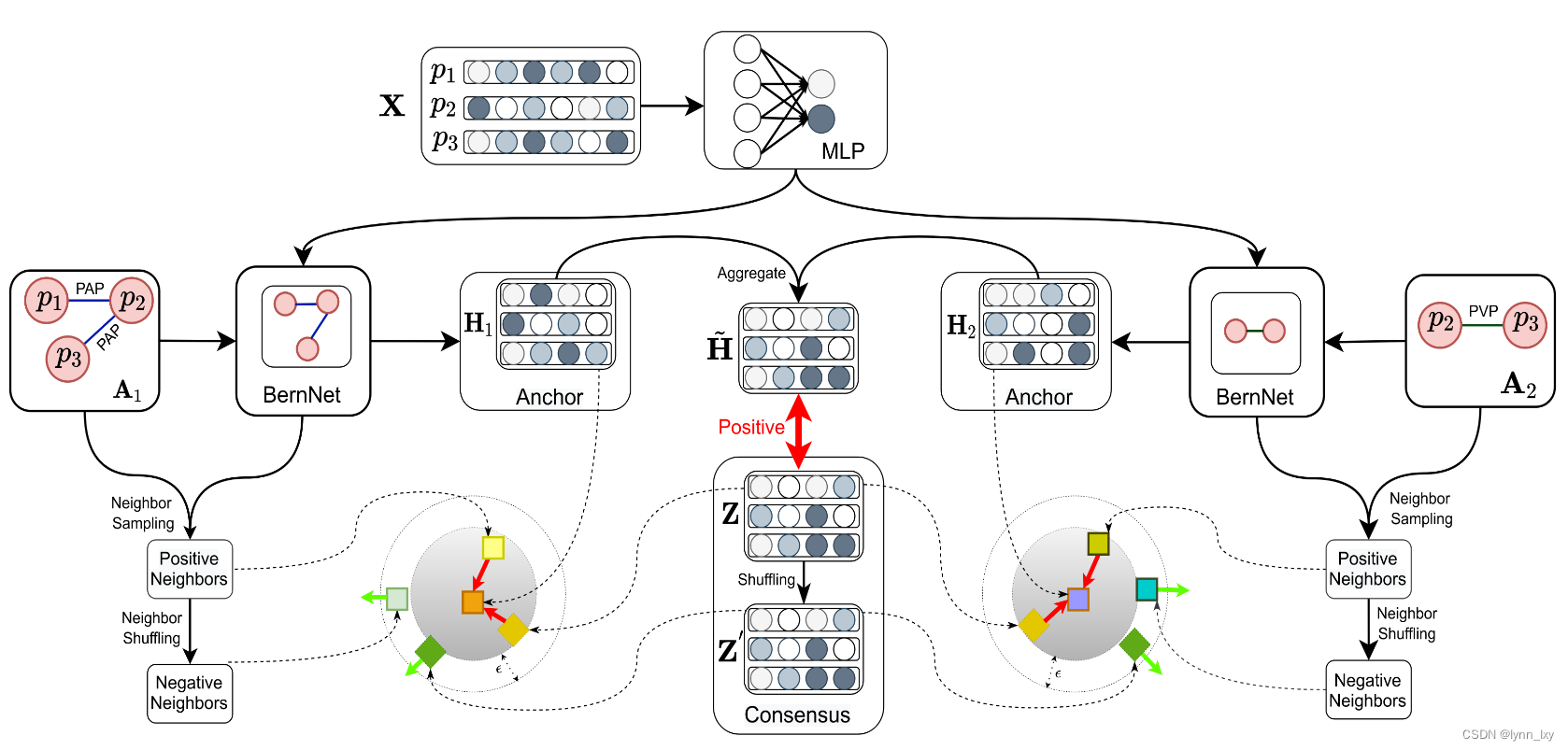
1)锚嵌入的生成
GCN 使用切比雪夫多项式的一阶近似,只是一个低通滤波器,在多层堆叠时可能会导致负光谱响应。为了避免GCN的负面影响,提出了BernNet。采用简化的低阶伯恩斯坦多项式作为基本编码器来为每个元路径视图生成锚嵌入。
原文经过对多项式的化简,得到如下公式:

其中都是可训练参数L是对称归一化图拉普拉斯,L^=Lx,x是节点特征矩阵,为了使得训练更高效,使用MLP对特征矩阵进行降维训练:
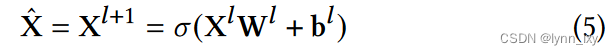
综上所述,为了得到锚矩阵,使用如下公式:
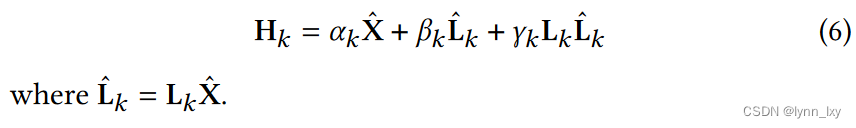
2)局部对比学习
传统的双线性判别器需要消耗大量的时间和内存,在这里作者采用了三元组边缘损失来进行邻域对比:
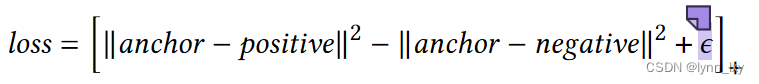
本文对二姐邻居进行对比,所得到正样本与负样本使用下面两个公式得到:
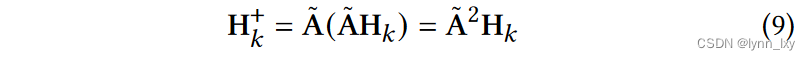
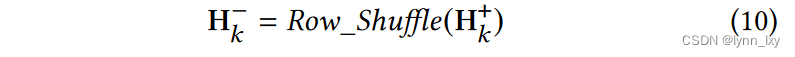
综合上述公式,可以得到局部对比损失计算公式如下
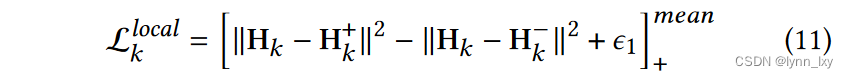
3)全局共识对比与正则化
全局对比也是采用三元组边缘随时,但是负样本发生了变化,是对公式嵌入进行处理得到的负样本:
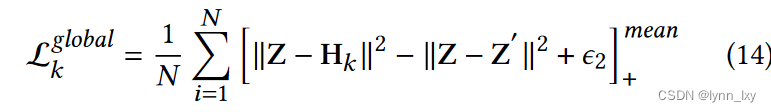
为了进一步减少泛化误差并提高特定于视图的嵌入与单一共识嵌入之间的近似度,在学习所有视图后引入了共识正则化:
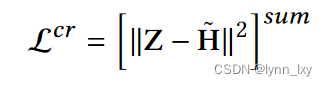
是所有视图中节点嵌入的聚合,有两种计算方法,一种是直接取平均,另一种是引入多头注意力机制,其计算方法如下:
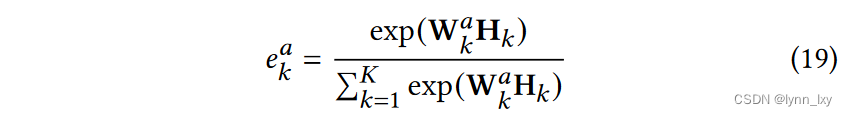
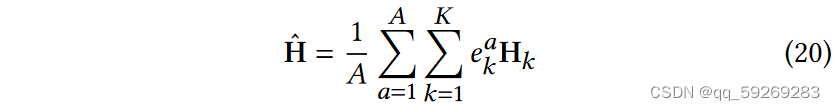
最后,总的损失函数如下:
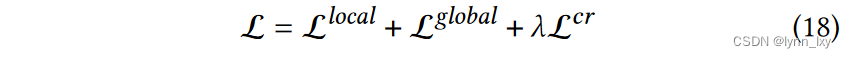
3. Disentangled Multiplex Graph Representation Learning
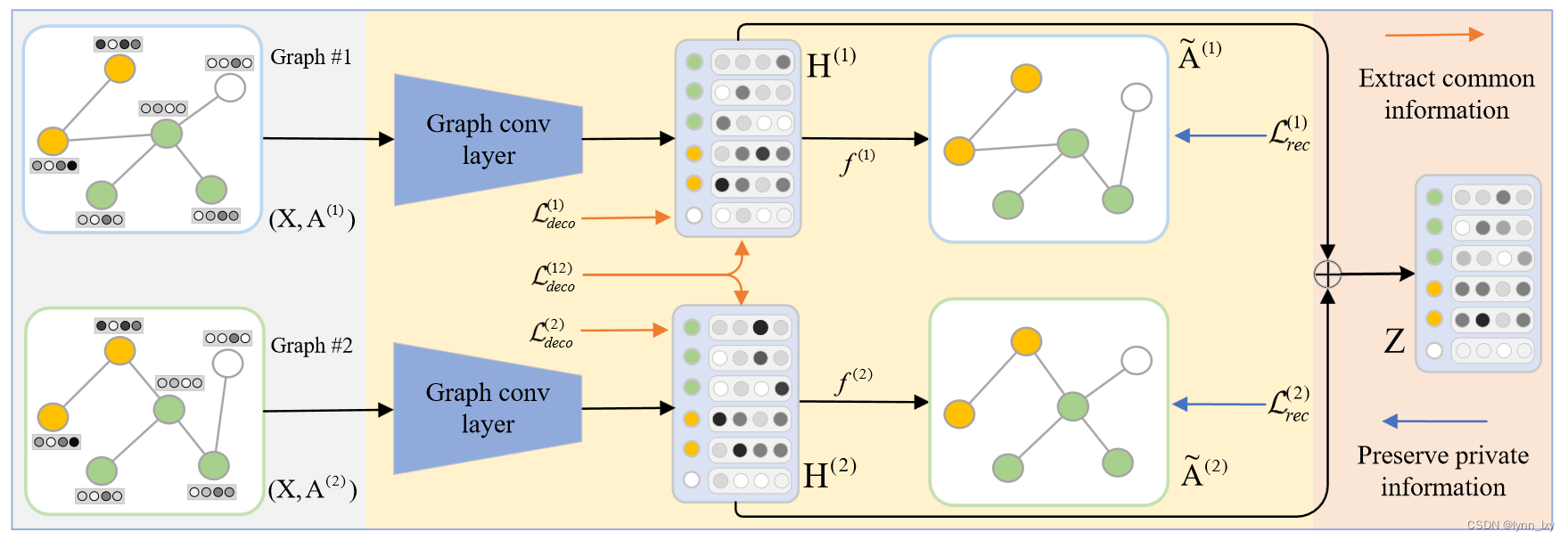
这篇文章主要的亮点是抛弃对比学习的思路,选择Disentangled Representation Learning的方法学习到完整干净的公共信息与没有杂音的私有信息,最后再将其融合得到最终的表示,其流程图如下:
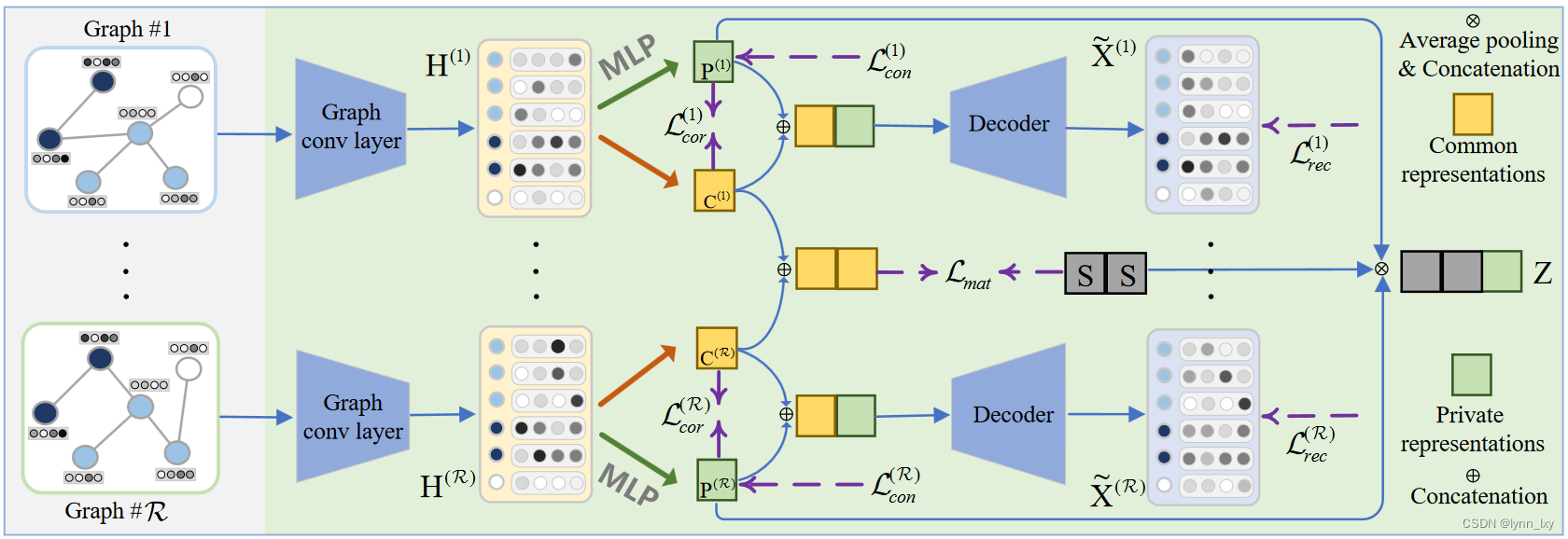
首先使用图卷积层获得基础的节点嵌入,然后分别通过MLP获得公有与私有表示,之后DMG分别研究匹配损失和相关孙志获得干净的共同信息,并研究重建损失以促进编码器的可逆性探究平凡解的问题。同时通过研究对比损失以保持互补性并消除私人信息中的噪声,最后不同图的私有便表示通过平均池化进行融合,然后与公共变量链接得到最终表示Z。
本文主要解答了两个问题,即:How to obtain complete and clean common information?与How to preserve complementarity and remove noise in private information?
下面分别回答
1)Common Information Extraction
首先通过GCN和MLP层得到公共表示:
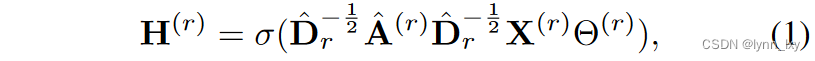
H(r)投入到MLP层里得到公有表示C(r)和私有表示P(r),通过奇异值分解得到公共变量S,为了对齐公有表示和公共变量,计算他们之间的匹配损失:
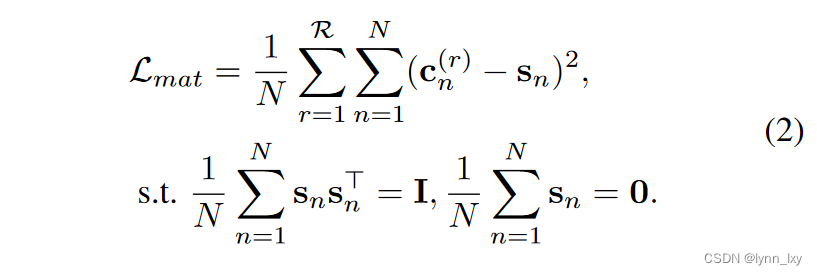
然后,为了保证公有和私有信息的独立性,计算二者的相关性损失,这里使用的是pearson相关系数,论文中给出的公式是这样的:
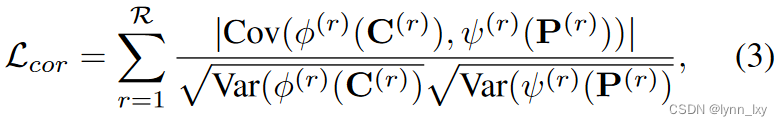
but代码里的计算公式是这样的
为了防止平凡的解决方案,作者采用可以重构损失自动编码器,本文中采用的方法同时重构节点特征和拓扑特征
损失公式如下
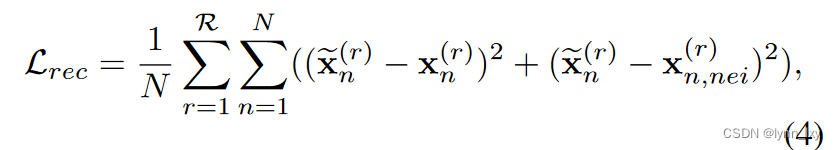
第一部分是特征重构,第二部分是节点重构
2)Private Information Constraint
为了尽可能的保留每个图结构的互补边并去除噪声边,作者对边的余弦相似度进行排序,相似度高的是互补边,相似度低的是噪声边,得到互补边集合和噪声边集合之后,可以计算二者的对比损失:
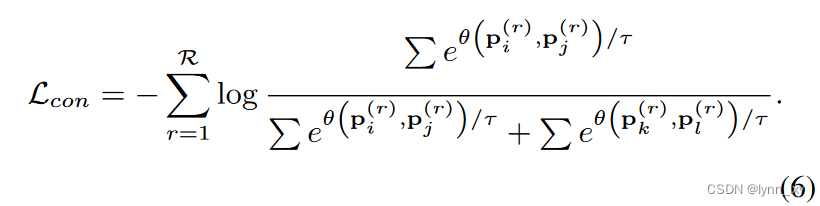
2)Objective Function
综合上述叙述,总的损失函数为:
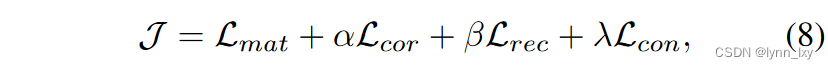
训练收敛后得到私有表示经过平均池化后与公共变量连接起来得到最终表示为Z。
总的算法流程如下:

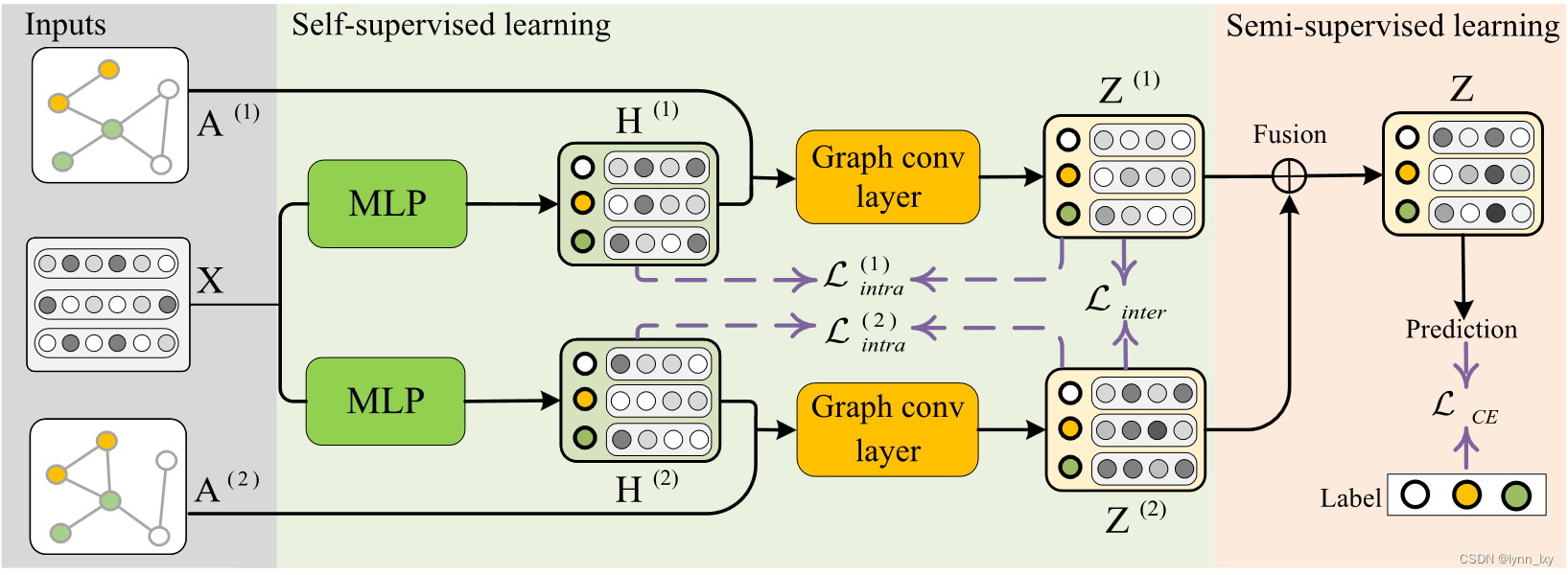
4. Multiplex Graph Representation Learning Via Dual Correlation Reduction && Multiplex Graph Representation Learning via Common and Private Information Mining
这两篇和上一篇是同一个作者,文章思路很相似,都是最小化层内信息损失与层间信息损失,流程图分别如下,没什么好讲的思路差别都不大
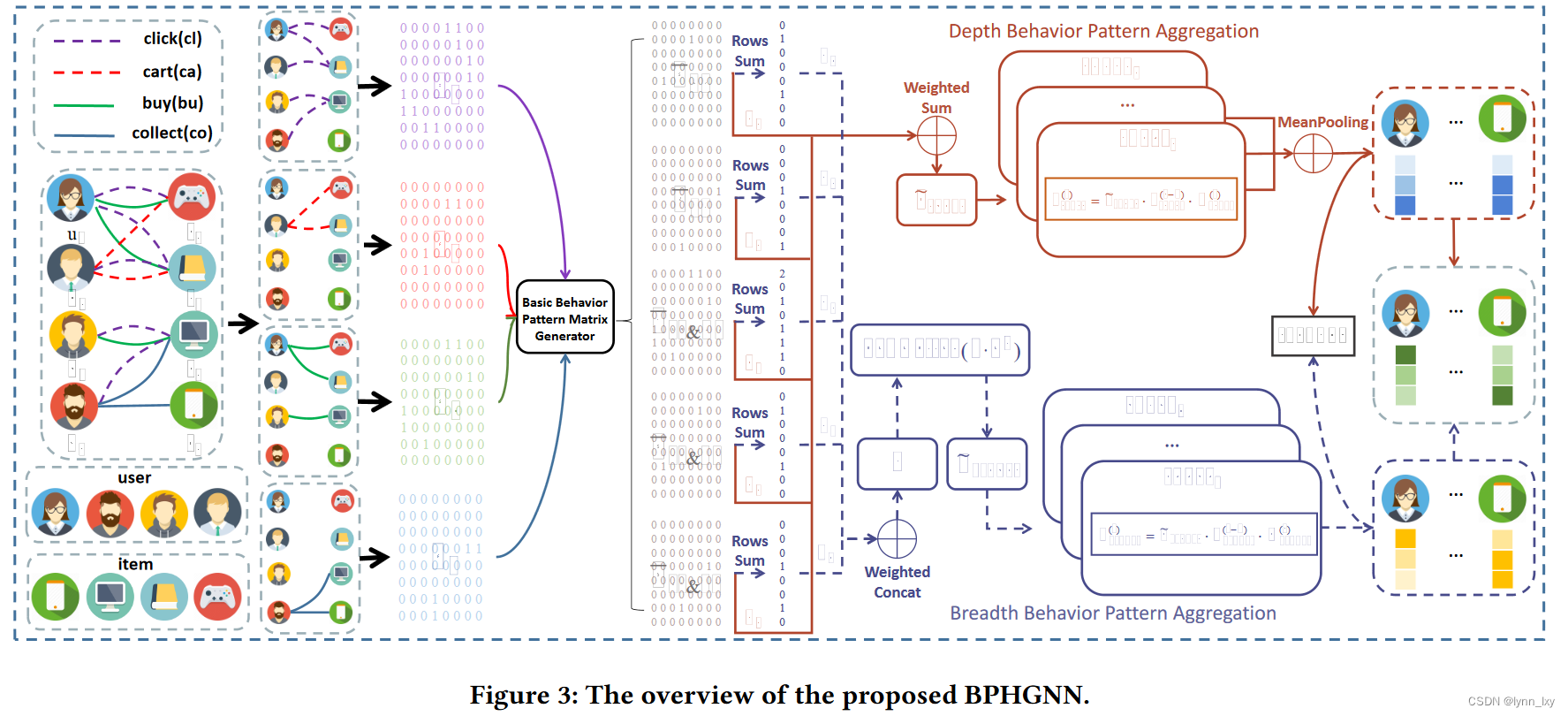
5.Multiplex Heterogeneous Graph Neural Network with Behavior Pattern Modeling
本文的思路是分别对广度行为模式进行聚合以及对深度行为模式进行聚合,然后计算全局和局部集合的对比损失,最后再模型学习时对无监督网络计算使用负样本进行对比学习,对半监督样本计算标签与预测值的交叉熵损失函数,全局的框架如下
6. Fast Attributed Multiplex Heterogeneous Network Embedding
本文使用了Fast Random Projection的方法,将谱图变化和节点特征合并到随机投影的框架中,以有效地学习节点表示,与GCN层相比,它能够更好地应用在节点类型多,特征空间巨大的大规模异构网络中。本文所提出的模型为FAME,模型框架如下:
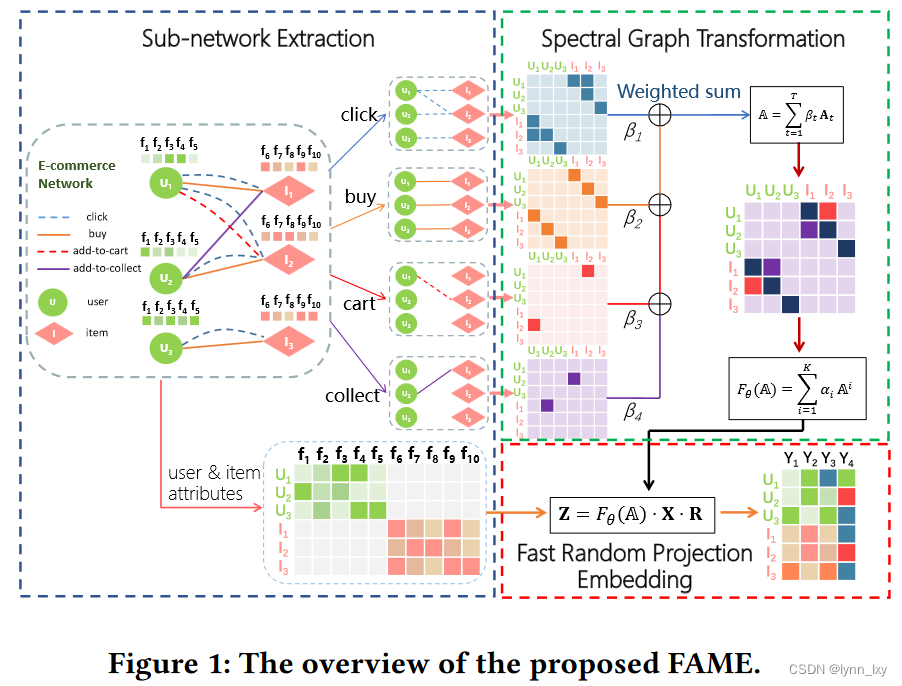
1)谱图变换
首先将多路异构图解耦为多个同构图和二份子网络,如上图所示,然后对单个图的邻接矩阵 A 的幂的加权和作为谱图变换函数进行计算,然后再融合不同关系子图的谱图,最后再对融合的A做归一化,所用到的公式分别如下:
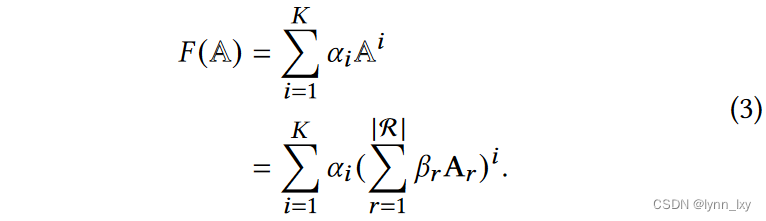
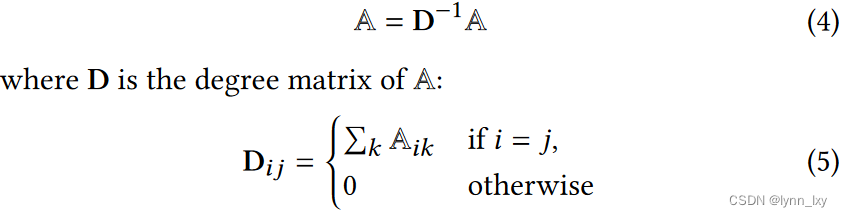
2)快速随机投影
关于这个方法的详细讲解,在这个链接中 快速随机投影 - 嬴图算法与分析 - Ultipa Graph
根据叙述初始化投影矩阵为

最终得到的节点表示可以写做:
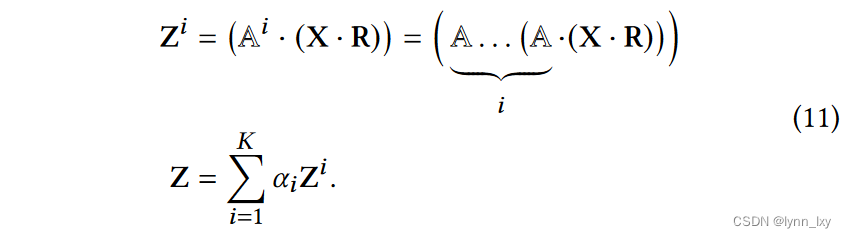
最后整个算法的流程如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









