






在读论文的时候感觉自己过于偏重论文里面的方法和模型框架,但是对于相关的实验如何设计以及如何评估并没有太多关注,写一下这个就当入门一下怎么进行实验吧
1.F1
在介绍F1之前明确一下精确率和召回率的概念,精确率就是在所有实际为a的猜测中猜测正确的概率,召回率就是在所有猜测为a的猜测中猜测正确的概率,F1的值就是2*精确率*召回率/(精确率+召回率)
2.Macro-F1与Micro-F1
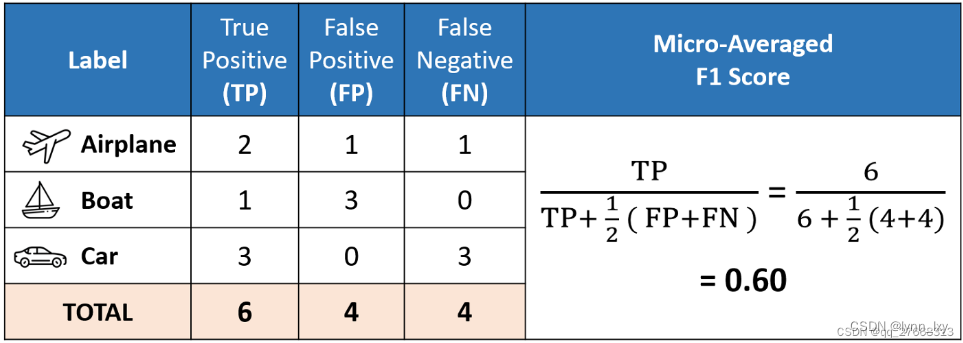
Macro-f1 是对每类F1分数计算算术平均值,该方法平等地对待所有类,而不考虑不同类别的重要性。Micro-f1通过计算全局的TP、FN和FP来计算F1分数(有点像acc?),比如下图中的例子
3.MI
两个随机变量的互信息(Mutual Information,简称MI)或转移信息(transinformation)是变量间相互依赖性的量度,计算公式为:
其中 p(x,y) 是 X 和 Y 的联合概率分布函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率分布函数
4.NMI
NMI是Normalized Mutual Information的缩写,中文为标准化互信息。在聚类任务中,NMI用于评估聚类结果与真实标签之间的相似度,它的取值范围是0到1,值越大表示聚类结果与真实标签的一致性越高。
NMI的计算公式为:
其中H(x)和H(y)分别为预测分布和实际分布的交叉熵,其计算公式如下:
5.ARI
调整兰德指数,用于度量聚类结果与真实类别之间的相似度。它考虑了随机分配的影响,值越大表示聚类结果与真实类别越相似。ARI的取值范围为-1到1,值越大表示聚类结果越好。
其中C(i,j)表示从i中随机挑选j个元素的组合数,其中,表示聚类结果中第
i 类与真实类别中第 j 类共同包含的样本数量, 表示聚类结果中第
i 类的样本数量,表示真实类别中第
j 类的样本数量,n 表示总样本数。这个公式看起来比较复杂,所以引用一个例子来说明:

首先是,就是要找到两个点,她们不仅实际分类相同,预测分类也相同,在上图中就是(u2,v2)以及(u3,v3)的两个数值,也就是说我们需要C(4,2)和C(2,2)的和来表示
,这个数的值为7.
可以想成是实际上的分类,在图中就是2,4,4,那么C(4,2)+C(4,2)+C(2,2)为13,
可以想成是计算而得的分类,在图中就是2,3,5,那么C(3,2)+C(5,2)+C(2,2)为14,n=10,C(10,2)=45那么可以得到这个列表所计算而得的ARI=
6.ROC-ARU与PR-AUC
ROC-AUC(arear-under-curve)是ROC曲线与横轴构成的面积,和Accuracy、Precision、recall、F1 score这些指标不同,AUC的值并不依赖于threshold的选择。ROC曲线的横轴为TPR(true positive rate),也称为真正例率,表示真实样本的Positive samples中有多少被预测为Positive。TPR的计算方法和Recall的计算方法完全一样。它的纵坐标为FPR(false positive rate),也称为假正例率,表示真实样本的Negative samples中有多少被预测为Positive。ROC-AUC越大,曲线下的面积越大,曲线越向左上角凸起,模型效果越好。由于ROC一般位于直线y=x的上方,因此ROC-AUC的值在[0.5, 1]之间(如果ROC-AUC小于0.5,我们就把模型预测的正负例标签调换一下)。
可以证明,ROC AUC分数等同于计算预测值与目标值之间的排名相关性。它也可以解释为:从样本中随机找出来一个Positive样本和一个Negative样本,这个Positive样本获得比Negative样本更高分数的概率。
例如,一个模型的ROC-AUC是0.8,那么随机给定一个正样本和负样本,有80%的概率模型给正样本的打分比对于负样本的打分高。此时,我们关心的是两类样本的相对排序,而不是每一个样本预测的概率是否准确。
和ROC-AUC一样,我们可以计算PR曲线下方的面积,以此来描述模型的表现。我们可以将PR-AUC看作是为每个Recall阈值计算的Precision的平均值。
PR曲线的名字就是图像的横纵坐标:的纵轴为Precision,横轴为Recall。
通过改变判区分Positive和Negative的threshold,我们可以得到一系列的Precision和Recall的值,将这些点画在坐标系上,我们就得到了PR曲线。
对于同一个模型,Recall越大,Precision越小。因此,PR曲线越向右上角凸越好。
我们可以通过PR曲线来观察在recall多大的时候,precision开始加速下降。这样我们可以利用PR曲线来选择最佳的threshold。

















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









