







15-Docker可视化管理工具
15.1-DockerUI
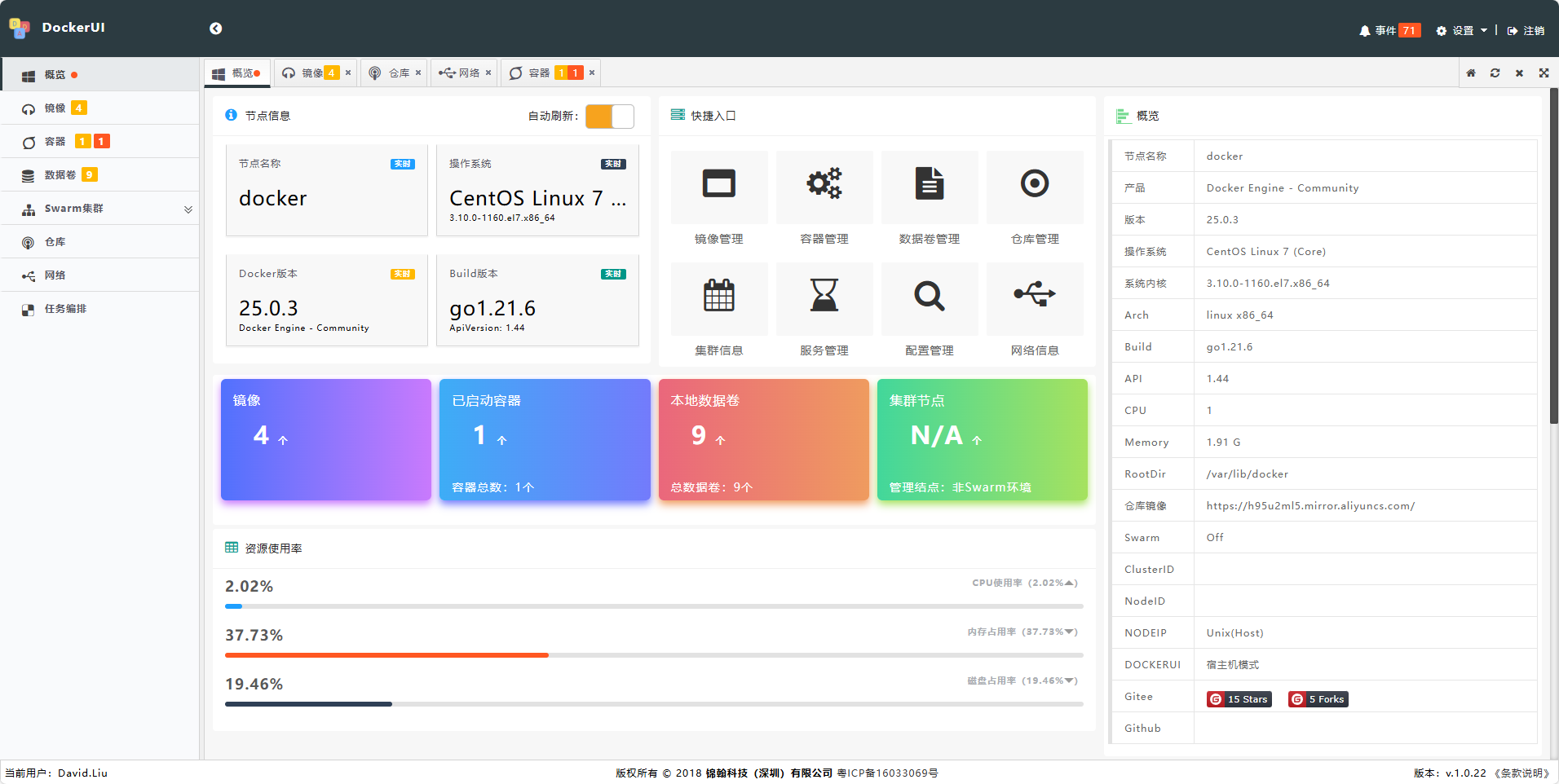
DockerUI-Docker的可视化管理工具
DockerUI 是由国内开发者打造的一款优秀的 Docker 可视化管理工具。该工具拥有简洁直观的UI界面,可以轻松进行Docker主机管理、集群管理,以及Docker任务的编排等操作。DockerUI不仅展示了资源利用率、系统信息和更新日志等内容,还提供了镜像管理的功能,能够有效清理中间镜像和残留的垃圾文件。
其UI设计和功能全面覆盖了Docker的核心操作,让用户无需通过命令行,即可方便地管理Docker环境。
GitHub开源地址
https://github.com/gohutool/docker.ui
主要功能
亮点:
Docker主机和集群的可视化管理
资源使用情况监控,实时查看CPU、内存和存储的使用情况
镜像管理,包括拉取、删除、导入导出镜像等操作
容器管理,支持启动、停止、重启和删除容器
网络管理,轻松配置Docker网络设置
缺点:
DockerUI开发者已经不再进行维护了,但对于小白来讲已经够用了
开发者的仓库地址:https://hub.docker.com/r/joinsunsoft/docker.ui
DockerUI直接启动
DockerUI可以通过以下命令直接启动:
docker run --restart always --name docker-ui -d -v /var/run/docker.sock:/var/run/docker.sock -p 18999:8999 joinsunsoft/docker.ui:latest
DockerUI国内镜像源启动
如果你需要使用国内镜像源,可以使用以下命令:
docker run --restart always --name docker-ui -d -v /var/run/docker.sock:/var/run/docker.sock -p 18999:8999 registry.cn-hangzhou.aliyuncs.com/jast-docker/docker.ui:latest
访问地址:http://localhost:18999/login.html,进入登录页面。localhost更改为宿主机ip
默认的用户名和密码为:ginghan / 123456
15.2-Portainer
Portainer轻量级图形化监控
Portainer是一款轻量级的应用,它提供了图形化界面,用于方便地管理Docker环境,包括单机环境和集群环境。
Portainer分为开源社区版(CE版)和商用版(BE版/EE版)。
Portainer官网
https://www.portainer.io/
Portainer下载
建议使用代理下载
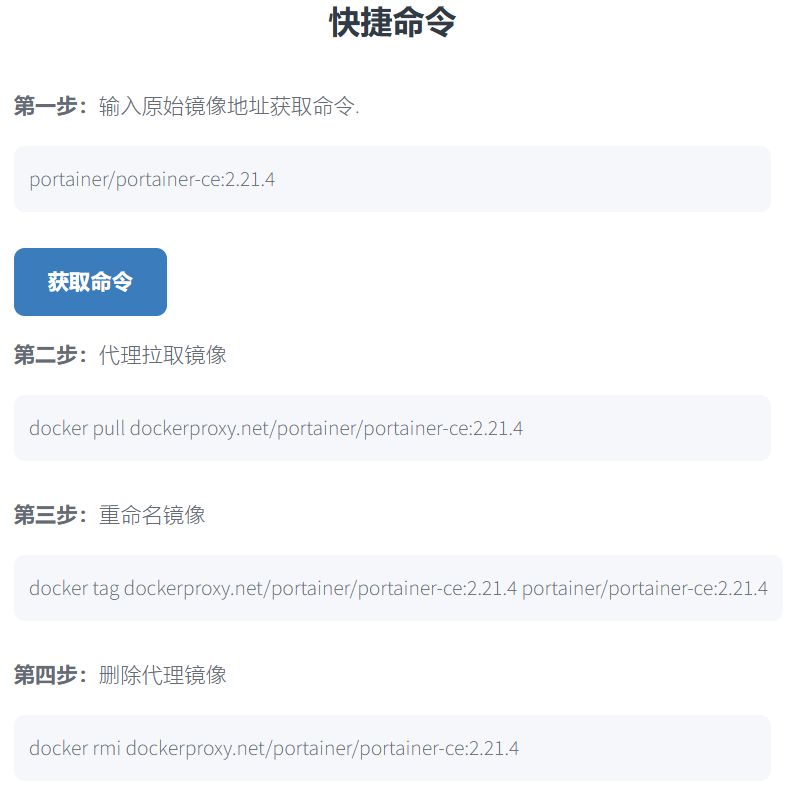
pull示例
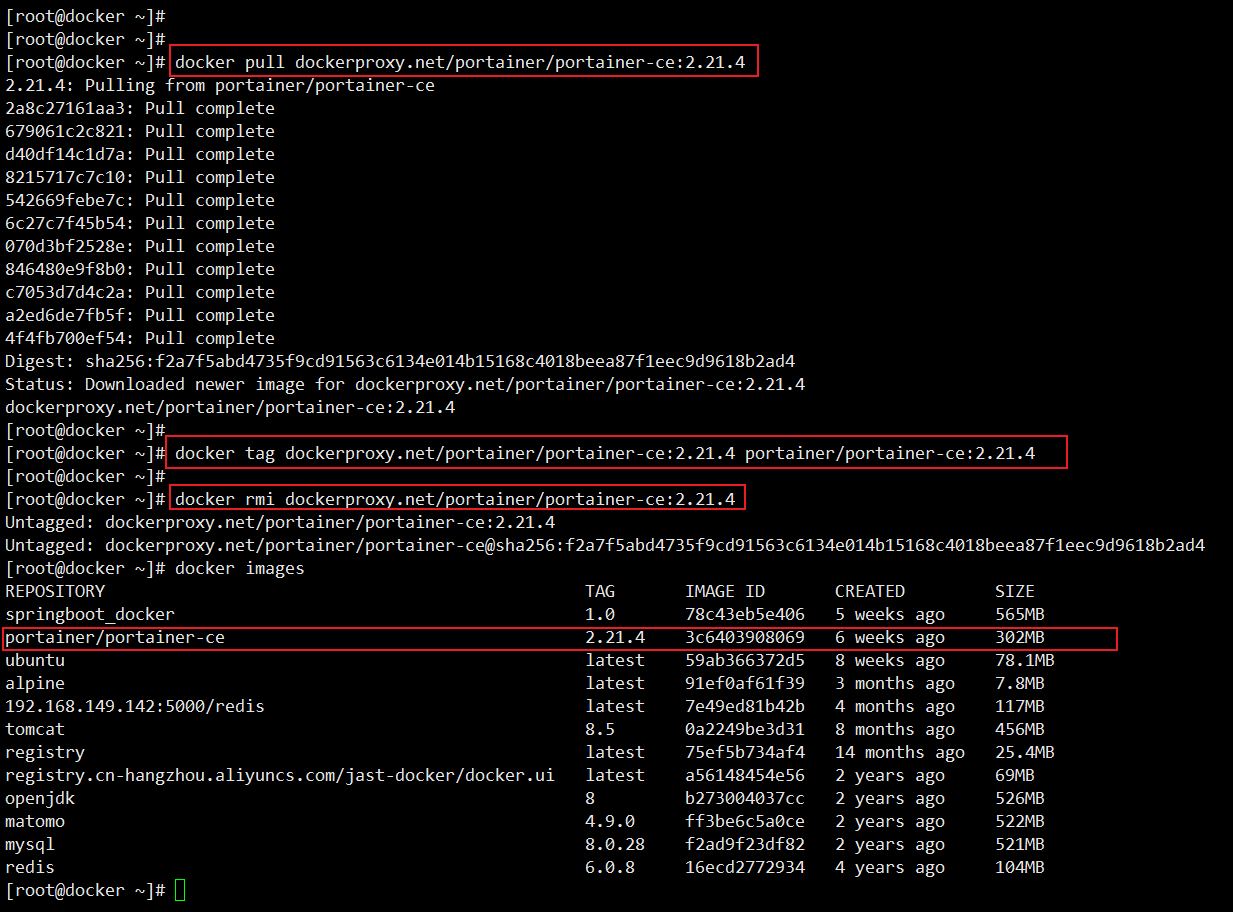
Portainer启动
官网步骤
https://docs.portainer.io/start/install-ce/server/docker/linux
Portainer也是一个Docker镜像,可以直接使用Docker运行。
首先,创建 Portainer Server 将用于存储其数据库的卷:
docker volume create portainer_data

然后,下载并安装 Portainer Server 容器(建议使用上述代理的方式pull,然后在进行部署):
docker run -d -p 8000:8000 -p 9443:9443 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:2.21.4
–restart=always 如果Docker引擎重启了,那么这个容器实例也会在Docker引擎重启后重启,类似开机自启

访问地址:https://localhost:9443,进入登录页面。localhost更改为宿主机ip
首次进来时,需要创建 admin 的用户名(默认admin)、密码(必须满足校验规则,例如portainer.io123)。
选择 local管理本地docker,即可看到本地Docker的详细信息,包括其中的镜像(images)、容器(containers)、网络(networks)、容器卷(volumes)、compose编排(stacks)等等。
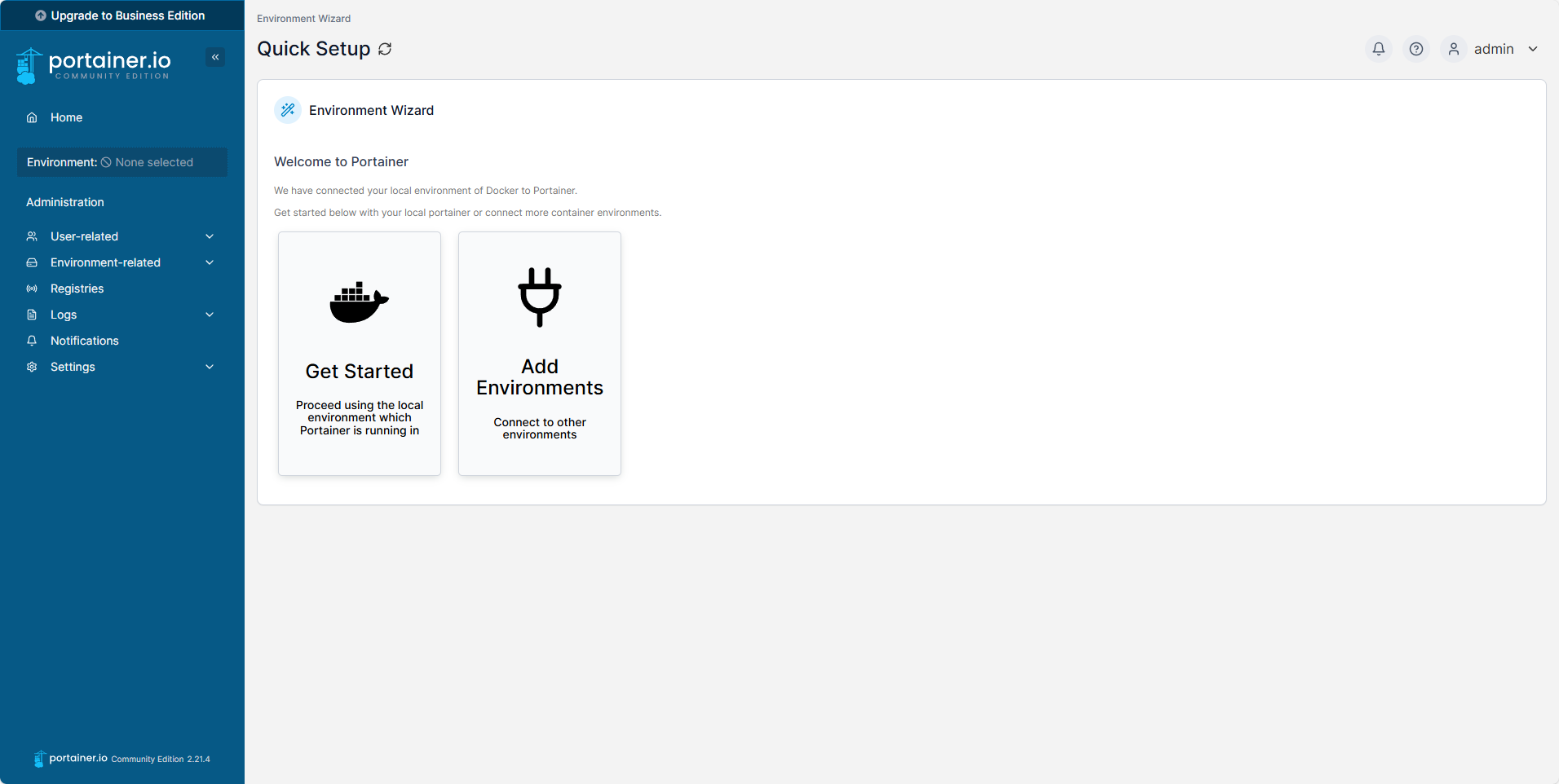
Portainer的汉化后续我会单独出一个教程
15.3-CIG
CIG重量级监控
通过docker stats 命令可以很方便的查看当前宿主机上所有容器的CPU、内存、网络流量等数据,可以满足一些小型应用。
但是 docker stats 统计结果只能是当前宿主机的全部容器,数据资料是实时的,没有地方存储、没有健康指标过线预警等功能。
CAdvisor(监控收集) + InfluxDB(存储数据) + Granfana(展示图表),合称 CIG。
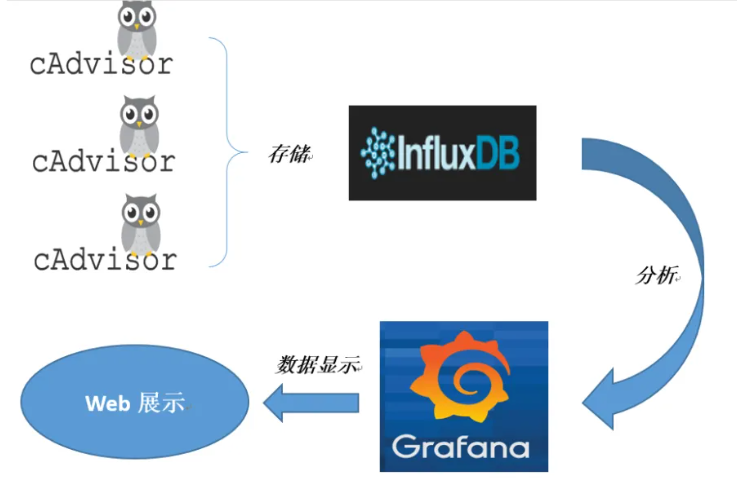
CAdvisor
CAdvisor是一个容器资源监控工具,包括容器的内存、CPU、网络IO、磁盘IO等监控,同时提供了一个Web页面用于查看容器的实时运行状态。
CAdvisor默认存储2分钟的数据,而且只是针对单物理机。不过CAdvisor提供了很多数据集成接口,支持 InfluxDB、Redis、Kafka、Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
CAdvisor主要功能:
-
展示Host和容器两个层次的监控数据
-
展示历史变化数据
InfluxDB
InfluxDB是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
CAdvisor默认只在本机保存2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储 CAdvisor 的数据。而且 CAdvisor本身已经提供了InfluxDB的集成方法,在启动容器时指定配置即可。
InfluxDB主要功能:
-
基于时间序列,支持与时间有关的相关函数(如最大、最小、求和等)
-
可度量性,可以实时对大量数据进行计算
-
基于事件,支持任意的事件数据
Granfana
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB、MySQL、Elasticsearch、OpenTSDB、Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
Granfana主要功能:
-
灵活丰富的图形化选项
-
可以混合多种风格
-
支持白天和夜间模式
-
多个数据源
安装部署CIG
新建目录
[root@docker ~]# cd /app
[root@docker app]# mkdir cig
[root@docker app]# cd cig
[root@docker cig]# pwd
/app/cig
新建docker-compose.yml文件
[root@docker cig]# vim docker-compose.yml
tutum/influxdb相比influxdb多了web可视化视图。但是该镜像已被标记为已过时
- “8083:8083” # 数据库web可视化页面端口
- “8086:8086” # 数据库端口
- 编写
docker-compose.yml服务编排文件
version: "3.1"
volumes:
grafana_data: {}
services:
influxdb:
image: tutum/influxdb:latest
restart: always
environment:
- PRE_CREATE_DB=cadvisor
ports:
- "8083:8083"
- "8086:8086"
volumes:
- ./data/influxdb:/data
cadvisor:
image: google/cadvisor:v0.32.0
links:
- influxdb:influxsrv
command:
- -storage_driver=influxdb
- -storage_driver_db=cadvisor
- -storage_driver_host=influxsrv:8086
restart: always
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
grafana:
image: grafana/grafana:8.5.2
user: '104'
restart: always
links:
- influxdb:influxsrv
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- HTTP_USER=admin
- HTTP_PASS=admin
- INFLUXDB_HOST=influxsrv
- INFLUXDB_PORT=8086
- 检查语法
docker-compose config -q
检查语法出现了以下报错
[root@docker cig]# docker compose config -q
WARN[0000] /app/cig/docker-compose.yml: `version` is obsolete
那是因为我使用的docker compose的版本比较新,但是新版本会兼容旧版本,暂时不用管
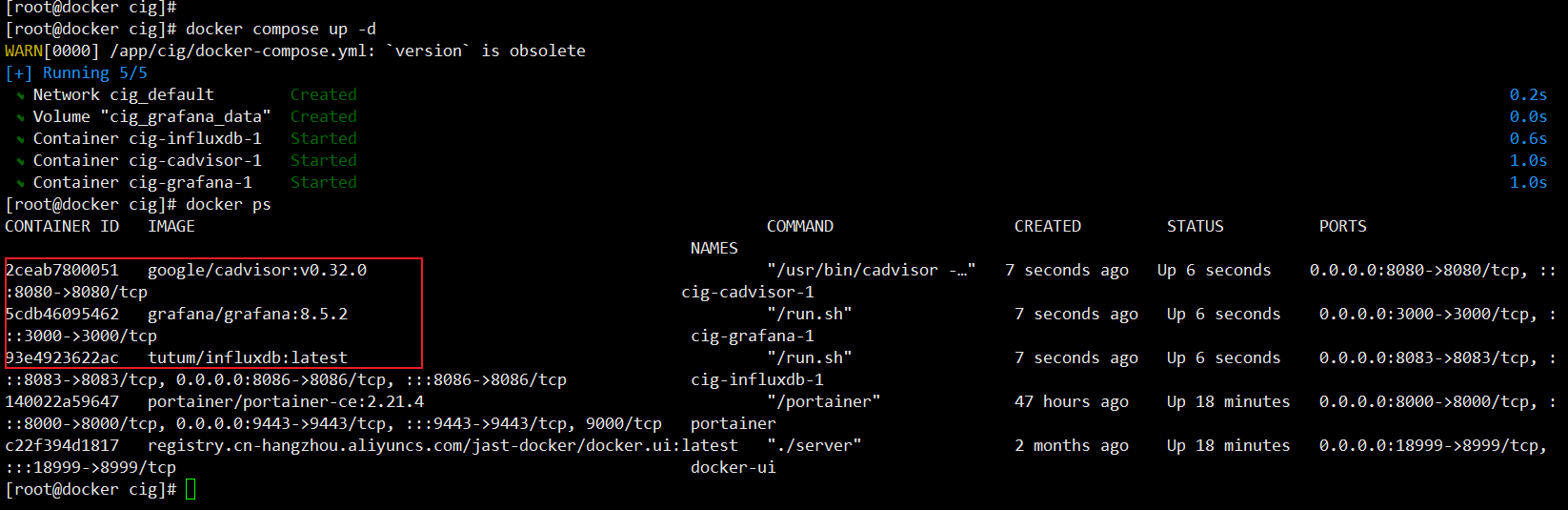
- 创建并启动容器(建议先把镜像拉取下来再进行启动)
docker-compose up -d
容器启动成功示例
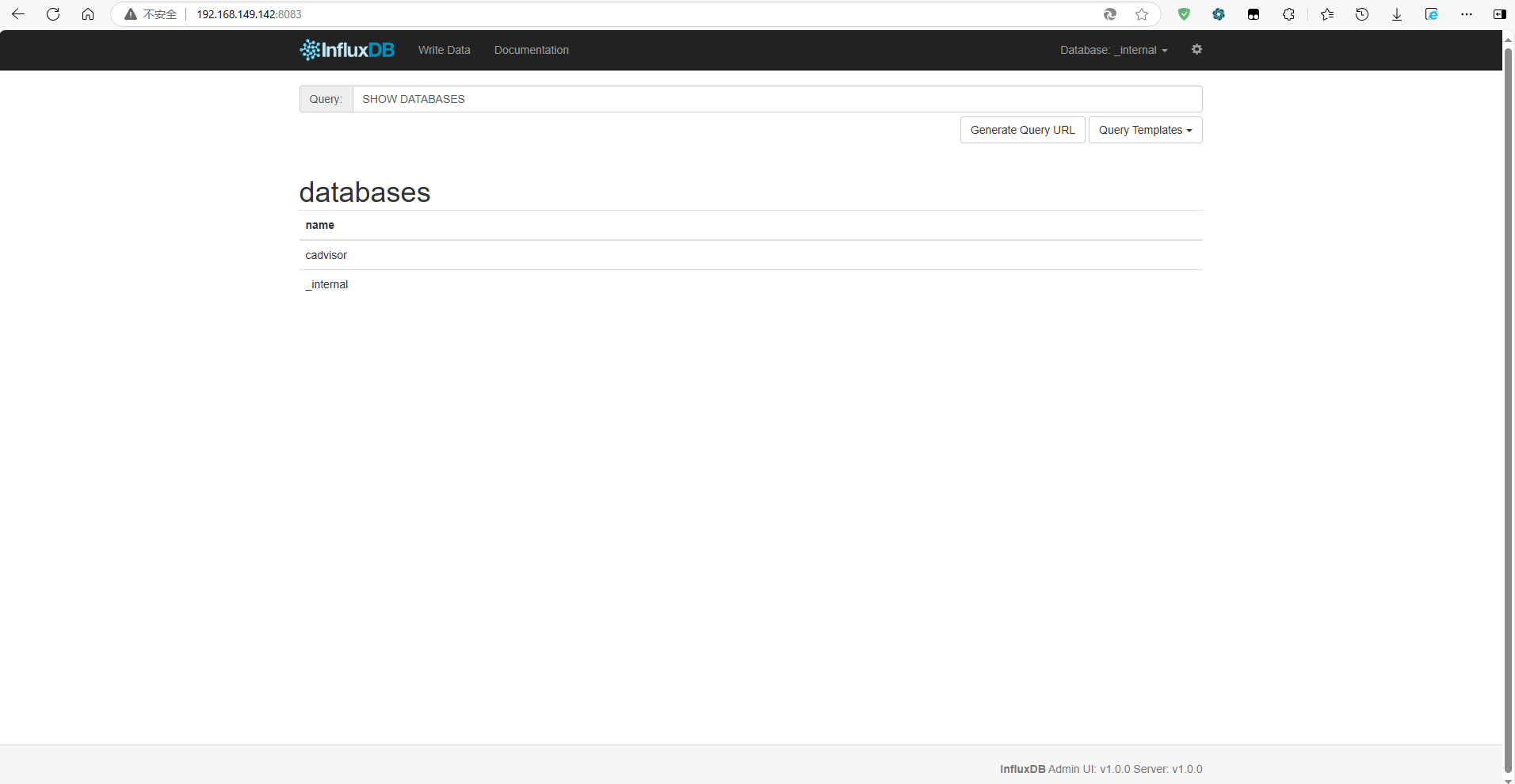
- 在浏览器打开InfluxDB数据库的页面:http://xxx.xxx.xxx.xxx:8083,使用命令查看当前数据库中的数据库实例:
SHOW DATABASES
查看其中是否自动创建了我们在配置文件中配置的 cadvisor 数据库实例
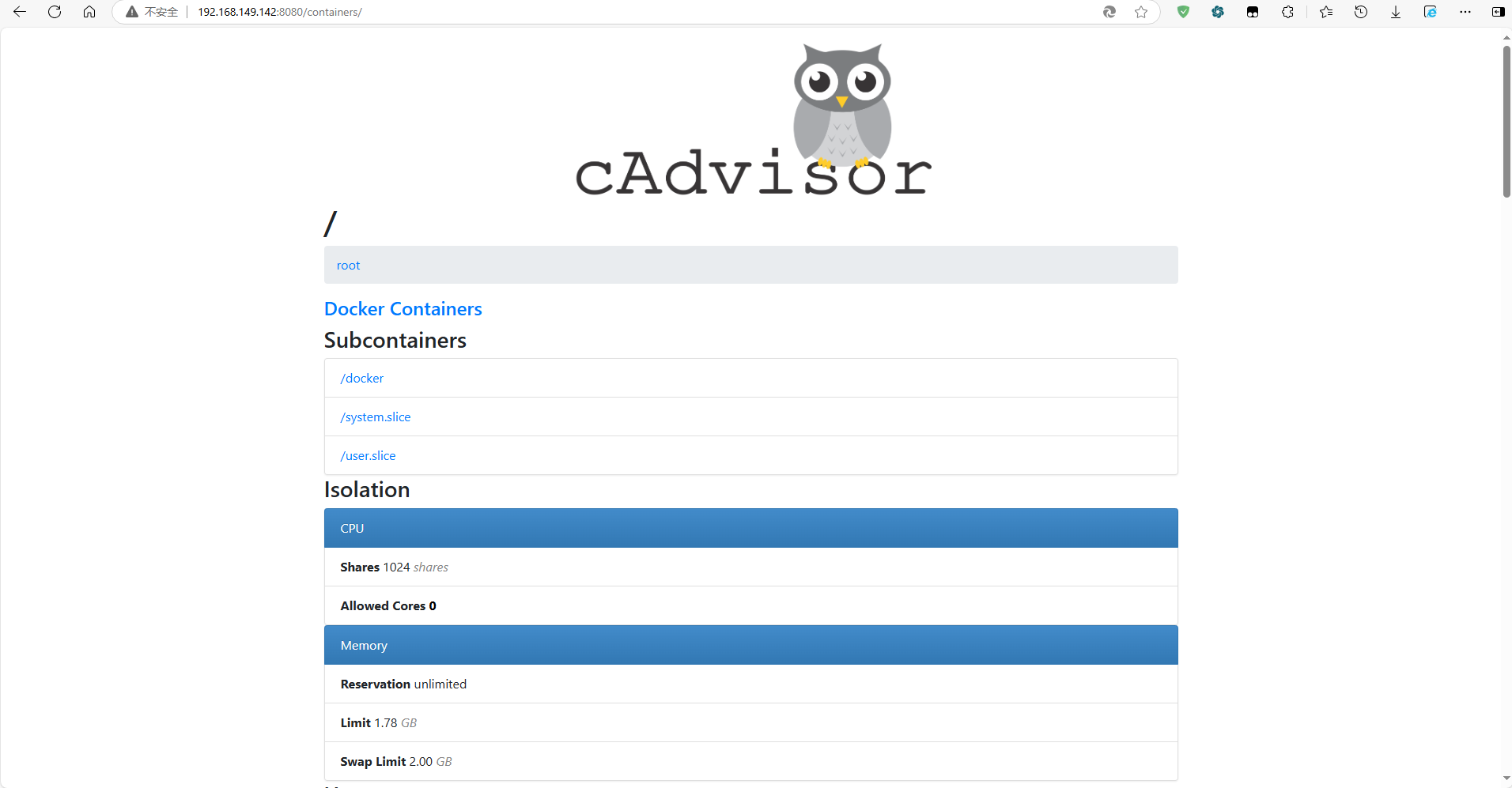
- 在浏览器打开CAdvisor页面:http://xxx.xxx.xxx.xxx8080/,查看当前docker中的cpu、内存、网络IO等统计信息。
- 在浏览器打开Grafana页面:http://xxx.xxx.xxx.xxx:3000/,默认用户名密码是:
admin/admin。
Grafana配置
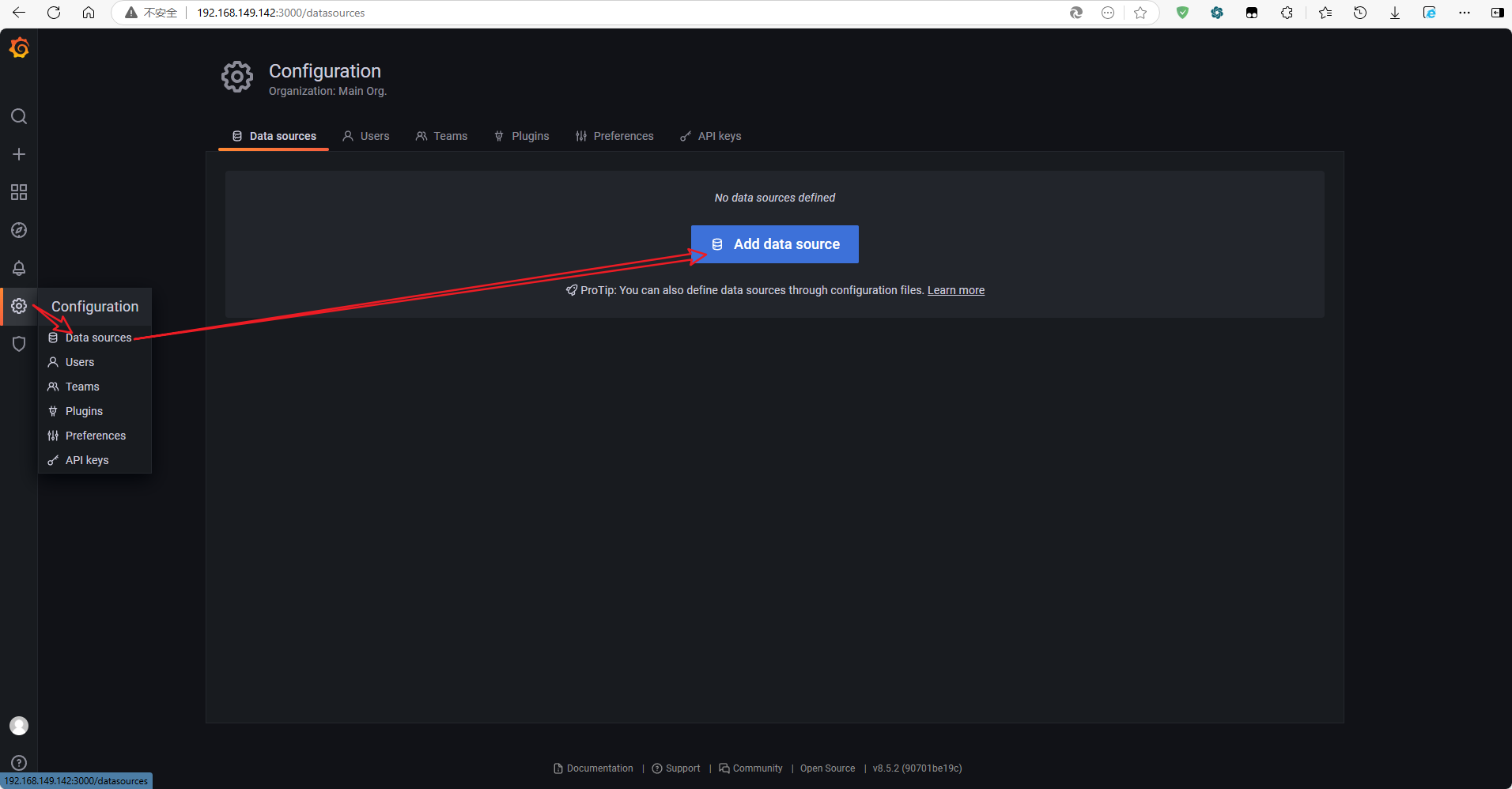
添加数据源
在Configuration(小齿轮)选项卡中,选择Data Sources,添加一个InfluxDB数据源:
-
name:自定义一个数据源名称,例如
InfluxDB -
Query Language:查询语言,默认
InfluxQL即可 -
URL:根据compose中的容器服务名连接,
http://influxdb:8086 -
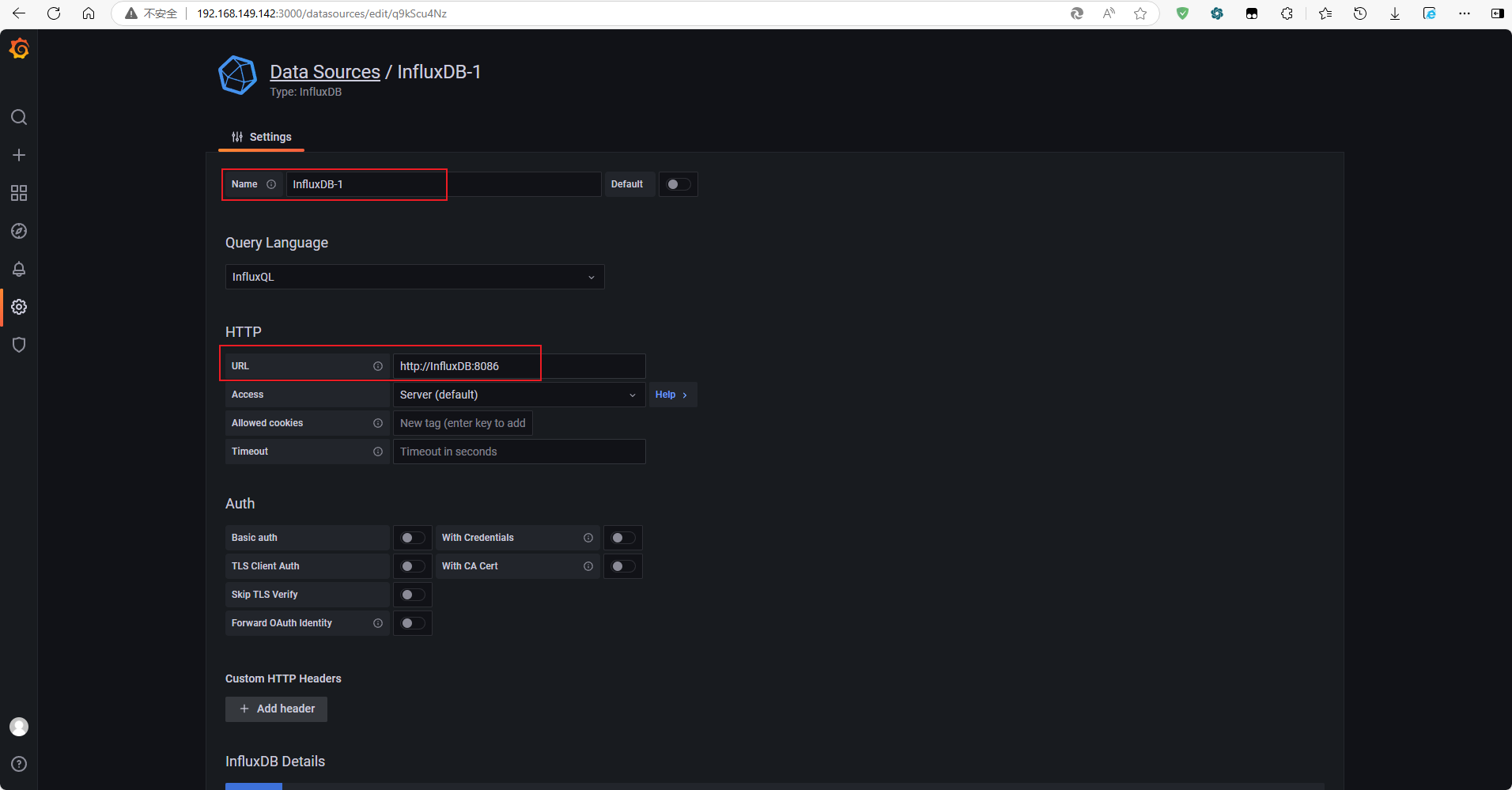
database:我们在InfluxDB中创建的数据库实例,
cadvisor -
User:InfluxDB的默认用户,
root -
Password:
root
示例
添加一个InfluxDB数据源
name:自定义一个数据源名称,例如InfluxDB
Query Language:查询语言,默认InfluxQL即可
URL:根据compose中的容器服务名连接,http://influxdb:8086
database:我们在InfluxDB中创建的数据库实例,cadvisor
User:InfluxDB的默认用户,root
Password:root
点击测试并保存
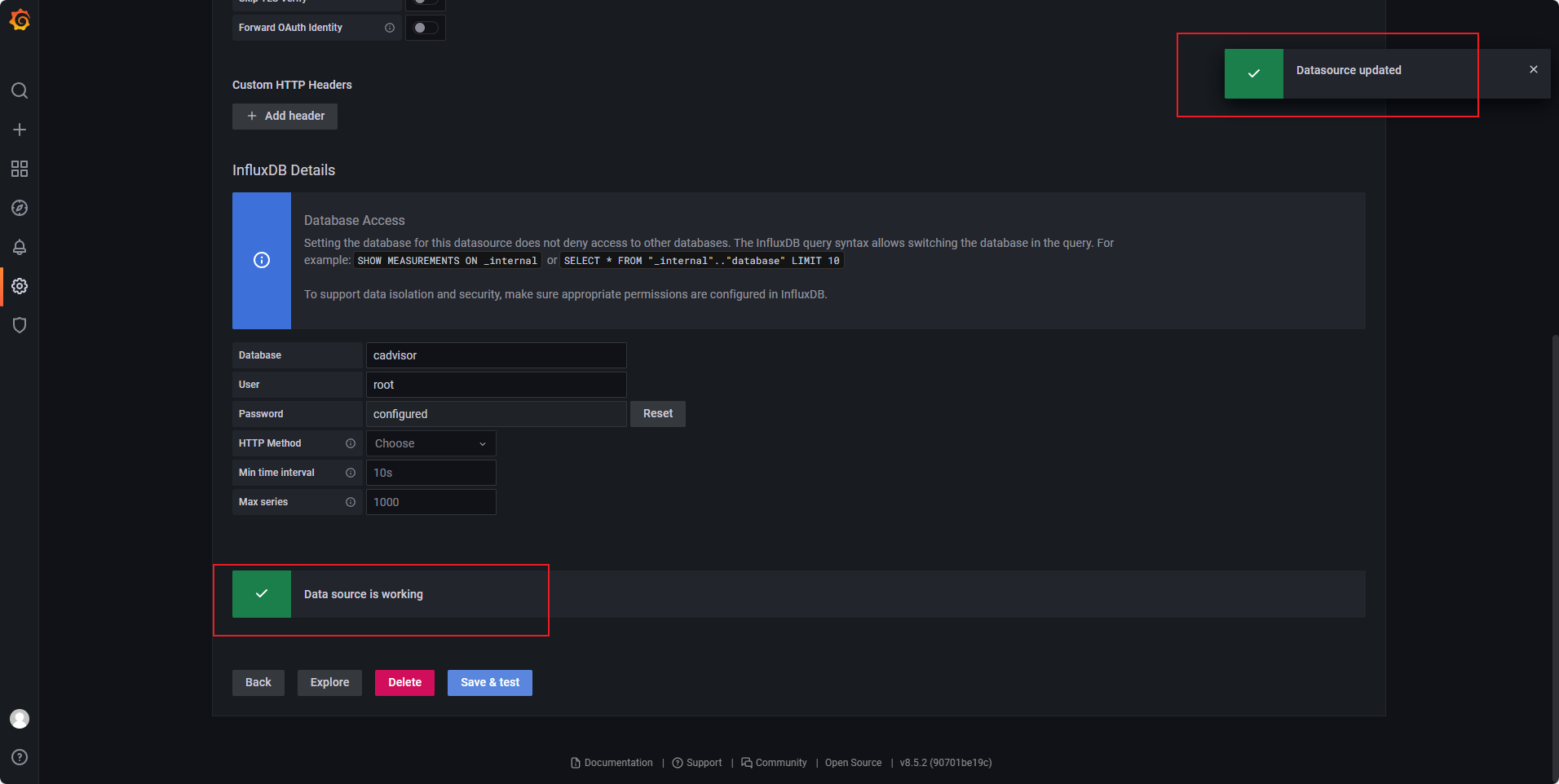
添加工作台
-
在
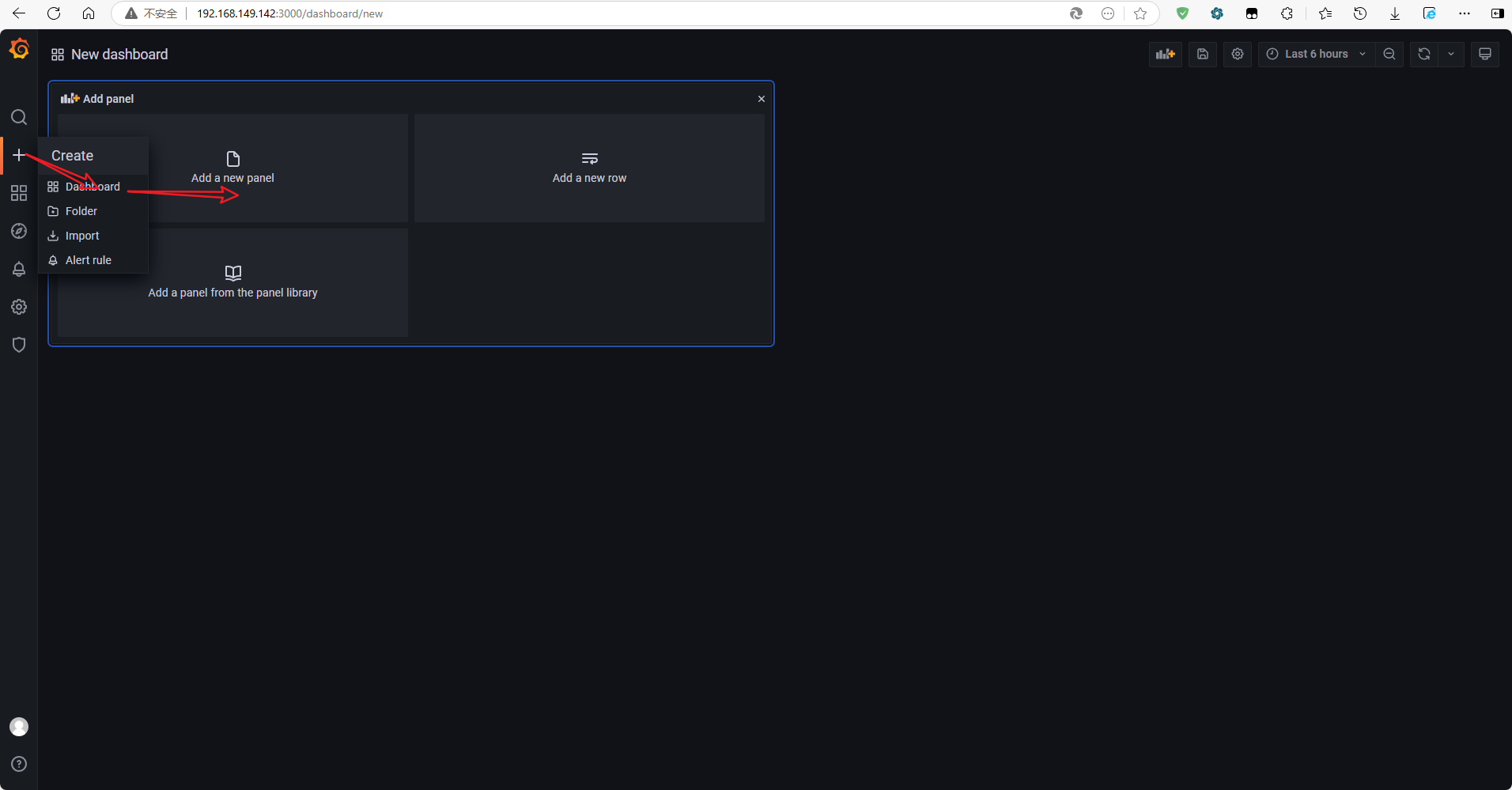
Create(加号)选项卡中,选择创建Dash Board工作台。右上角配置中可以配置创建出来的工作台的标题、文件夹等信息。 -
在创建出来的工作台中,选择
Add panel中的Add a new panel添加一个新的面板。
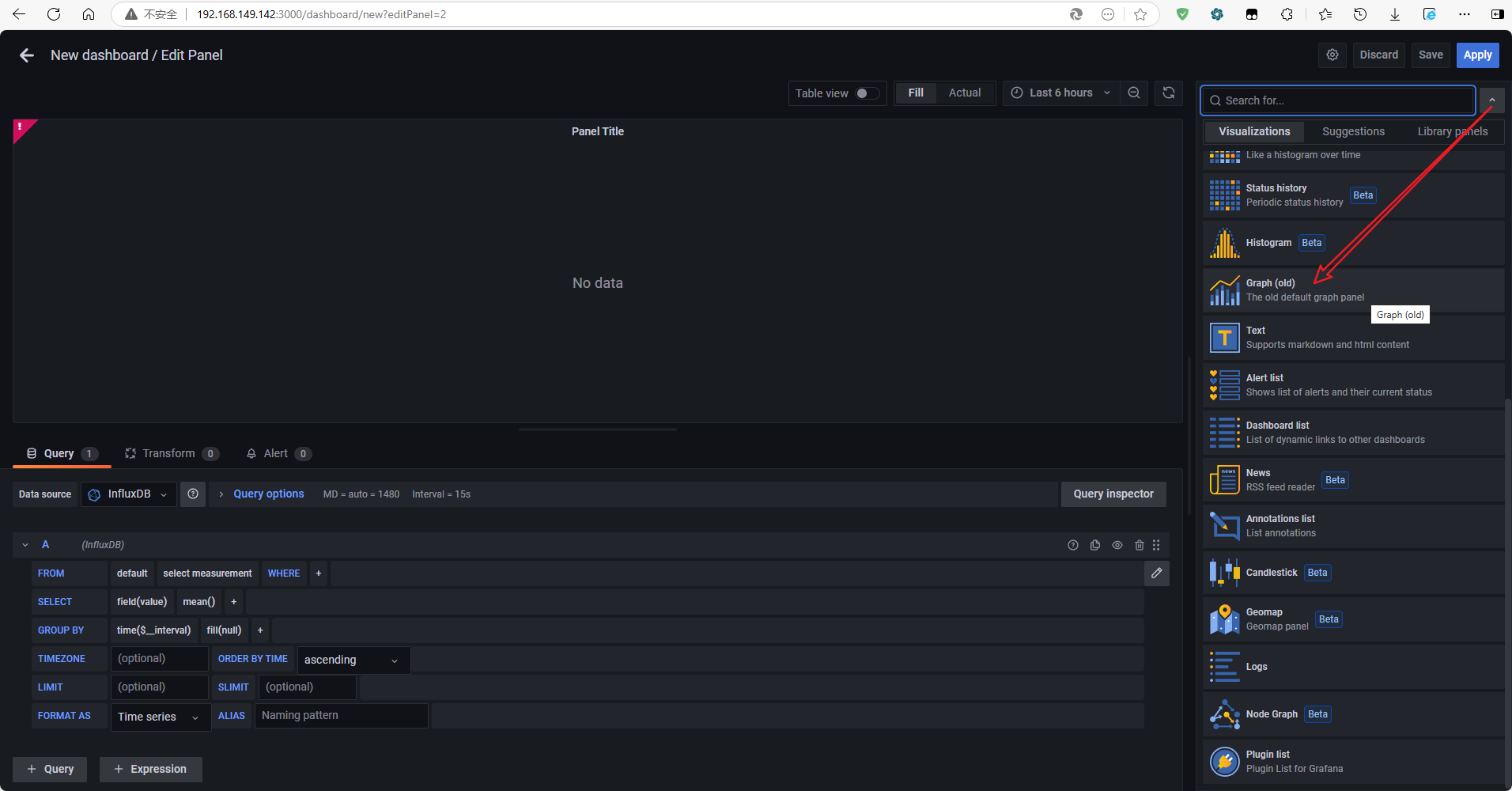
- 在右上角
Time series(时序图)位置可以切换展示的图表样式(柱状图、仪表盘、表格、饼图等等) - 右侧边栏为该图表配置相关信息:标题、描述
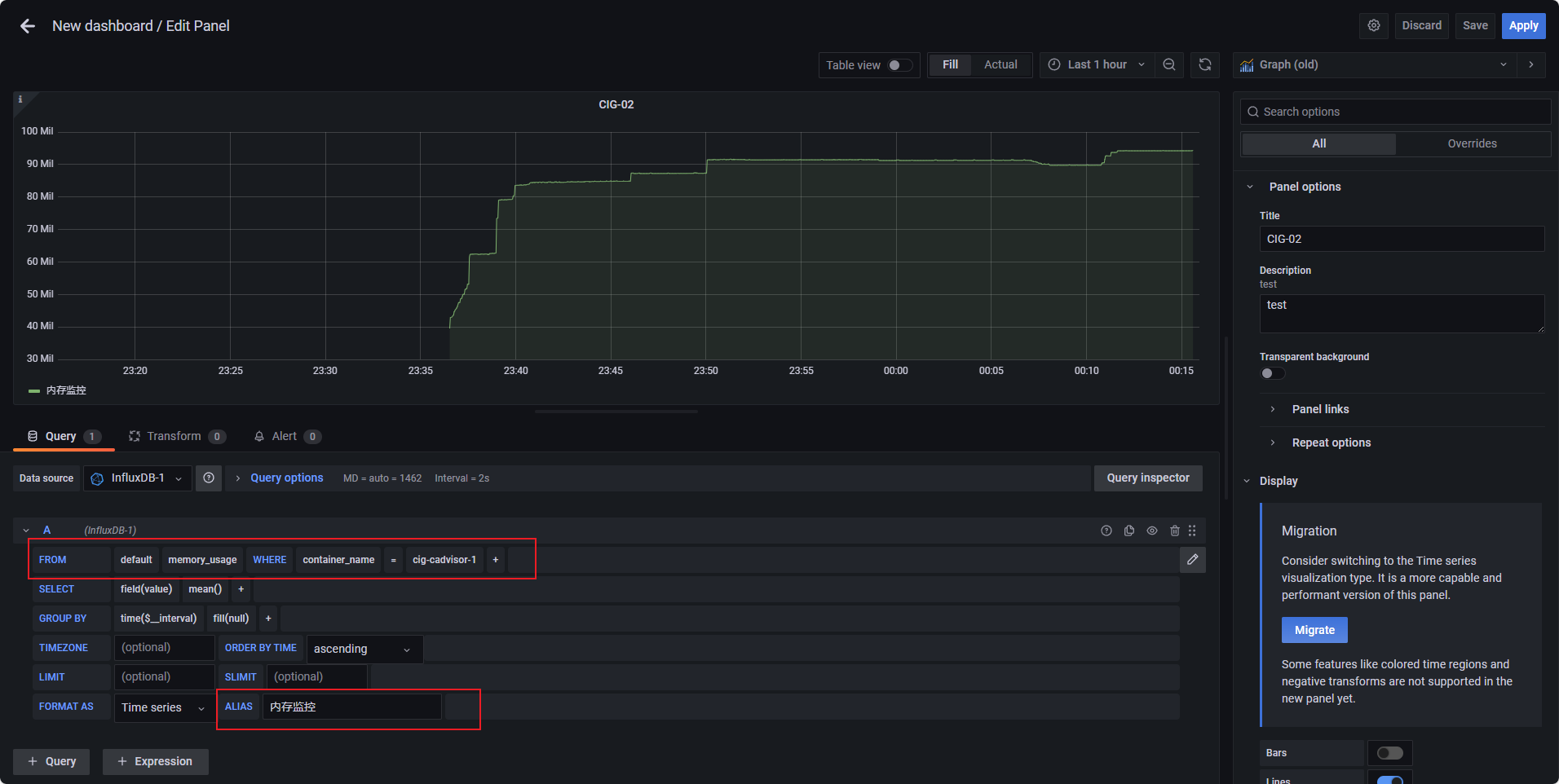
- 图表下方可以配置该图表展示的数据的查询语句,例如:
-
FROM:
cpu_usage_total(Grafana会自动获取InfluxDB数据库中的元数据,可以直接选择对应表名) -
WHERE:添加一个条件,
container_name=cig-cadvisor-1 -
ALIAS:配置一个别名,
CPU使用情况汇总
示例
在创建出来的工作台中,选择Add panel中的Add a new panel添加一个新的面板
在右上角Time series(时序图)位置可以切换展示的图表样式(柱状图、仪表盘、表格、饼图等等)
右侧边栏为该图表配置相关信息:标题、描述
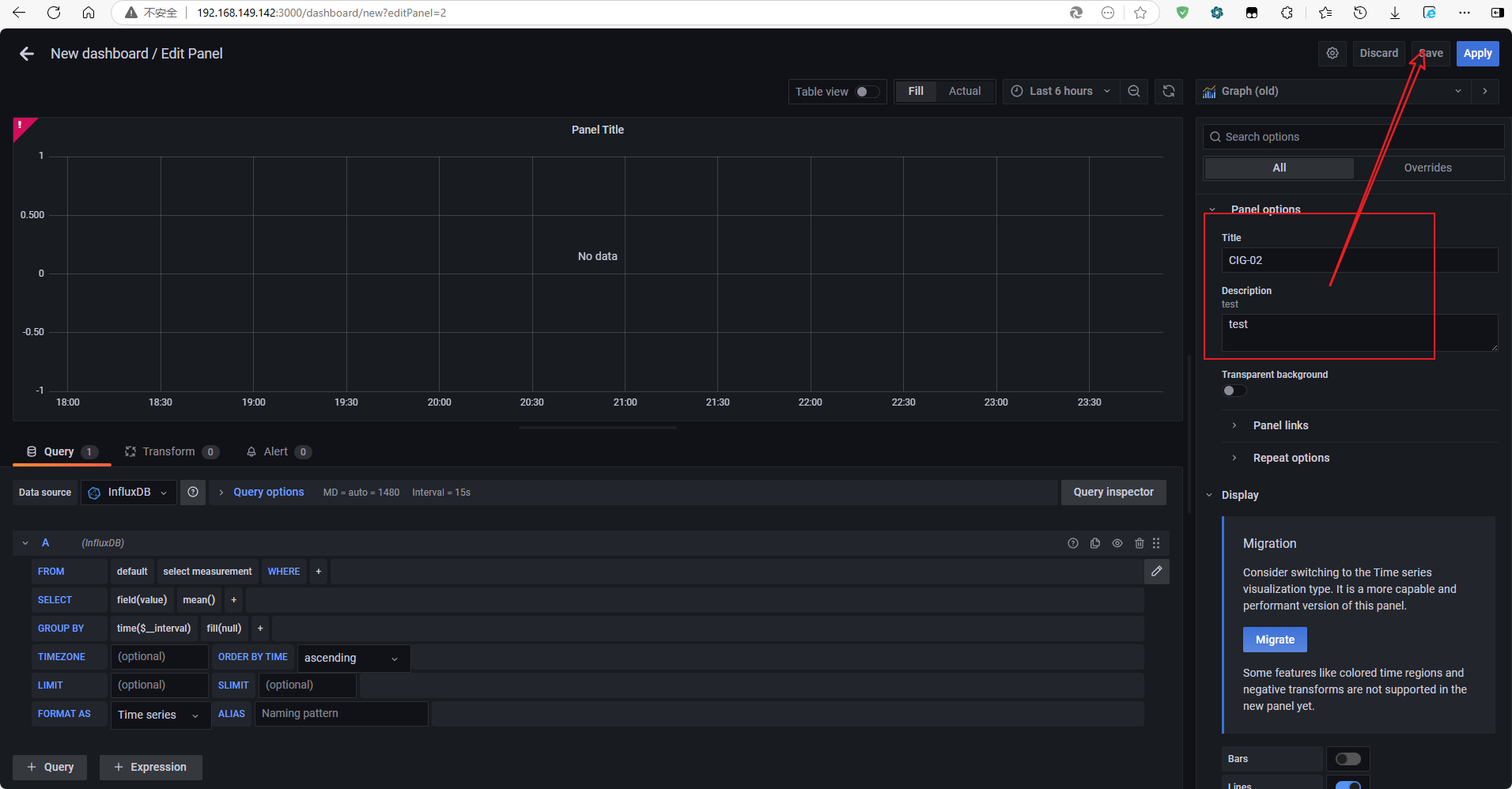
保存后重新选择编辑
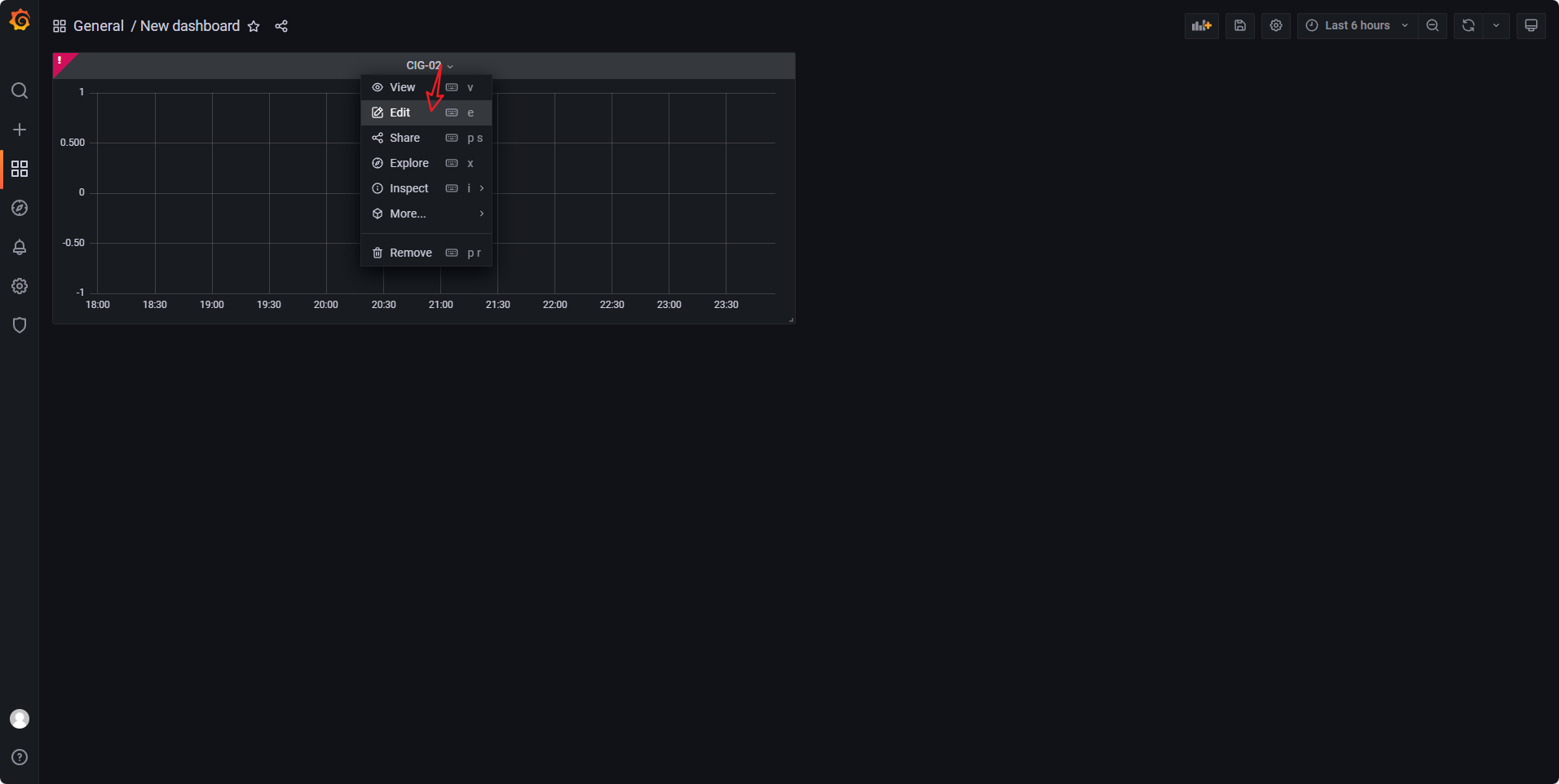
-
FROM:
cpu_usage_total(Grafana会自动获取InfluxDB数据库中的元数据,可以直接选择对应表名) -
WHERE:添加一个条件,
container_name=cig-cadvisor-1 -
ALIAS:配置一个别名,
CPU使用情况汇总
图示是以内存举例
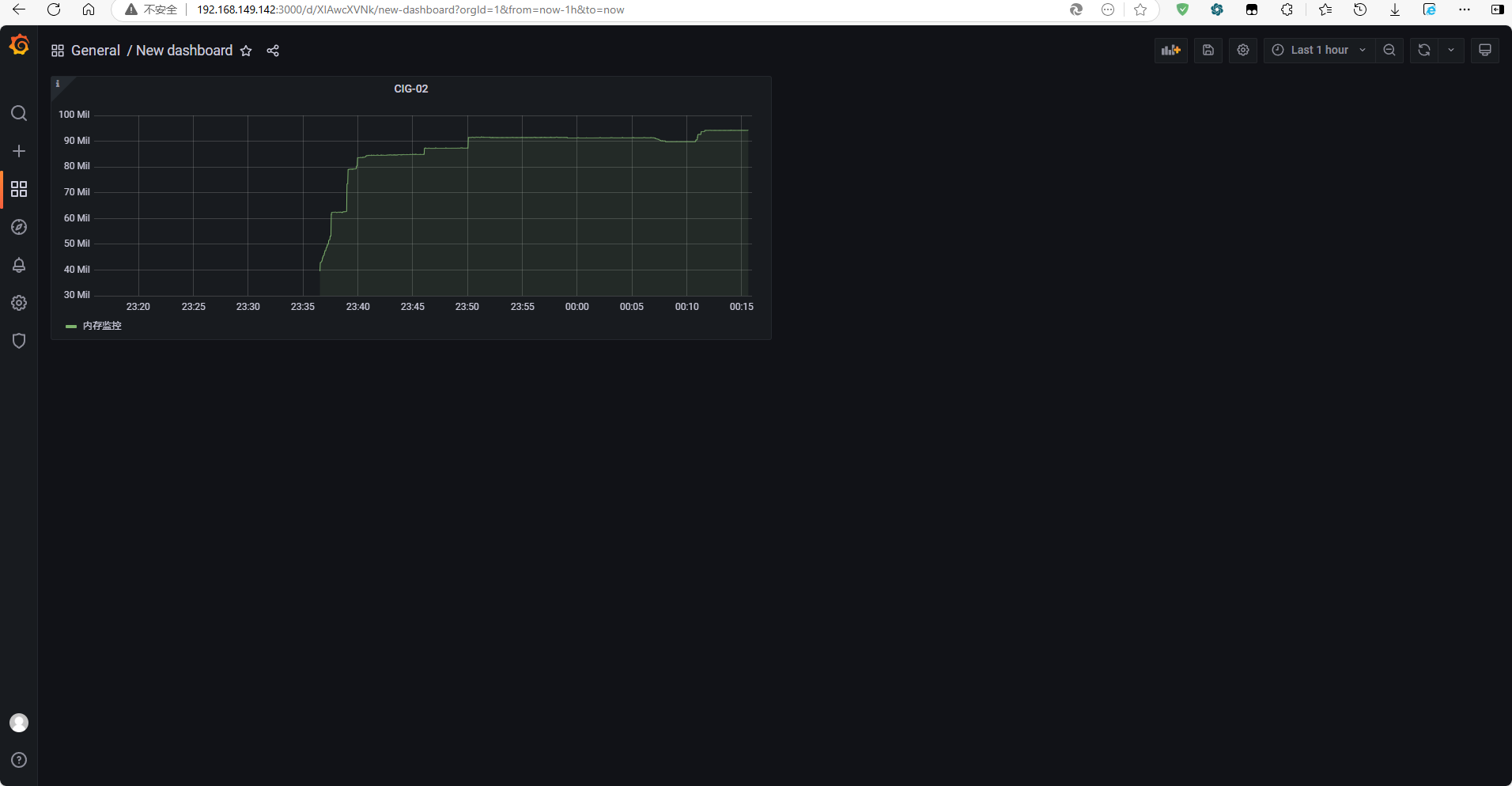
最终效果


















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











