







An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

本文 “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” 提出将标准Transformer直接应用于图像识别任务的Vision Transformer (ViT),通过将图像分割为块并输入Transformer编码器,在大规模数据预训练后于多个图像识别基准测试中取得优异成绩,探讨了其预训练数据需求、模型缩放等特性,分析了内部机制并对自监督学习进行初步探索。
摘要-Abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
虽然Transformer架构已成为自然语言处理任务的事实上的标准,但其在计算机视觉中的应用仍然有限。在视觉领域,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对CNN的依赖并非必要,直接应用于图像块序列的纯Transformer在图像分类任务中可以表现得非常出色。当在大量数据上进行预训练并转移到多个中等规模或小型图像识别基准(ImageNet、CIFAR - 100、VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)在训练时需要的计算资源显著减少的情况下仍能取得优异的结果。
引言-Introduction
- Transformer在NLP中的主导地位及发展趋势
- 基于自注意力的Transformer架构已成为自然语言处理(NLP)的首选模型,主导方法是在大文本语料库上预训练,然后在特定任务数据集上微调。
- 由于Transformer的计算效率和可扩展性,训练出的模型参数已超100B,且随着模型和数据集增大,性能仍未饱和。
- CNN在CV中的主导及自注意力结合尝试
- 在计算机视觉领域,卷积架构仍占主导地位,尽管受NLP成功启发,有许多工作尝试将类似CNN的架构与自注意力结合,部分工作尝试完全替换卷积,但后者因使用特殊注意力模式,在现代硬件加速器上尚未有效扩展,大规模图像识别中经典ResNet架构仍是当前最优。
- 本研究的动机与方法
- 受Transformer在NLP中成功的启发,作者尝试将标准Transformer直接应用于图像,将图像分割成块并将其线性嵌入后的序列作为Transformer输入,以监督方式训练模型进行图像分类。
- ViT在不同规模数据集上的表现预期
- 在中等规模数据集(如ImageNet)上训练时,若缺乏强正则化,ViT模型准确率比同等大小的ResNet低几个百分点,原因是Transformer缺乏CNN固有的归纳偏差,在数据量不足时泛化能力较差。
- 但在大规模数据集(14M - 300M图像)上训练时,情况发生变化,大规模训练可弥补归纳偏差不足,ViT在预训练充分并转移到数据点较少的任务时表现优异,在多个基准测试中接近或超越现有技术水平。
相关工作-Related Work
- Transformer在NLP中的发展
- 广泛应用与预训练微调模式:Transformers由Vaswani等人于2017年提出用于机器翻译,后成为众多NLP任务的主流方法。基于Transformer的大模型常先在大语料库上预训练,再针对具体任务微调,如BERT使用去噪自监督预训练任务,GPT系列使用语言建模作为预训练任务。
- 将自注意力应用于图像处理的尝试
- 局部自注意力近似方法:直接将自注意力应用于图像时,因像素间全局注意力计算成本高而无法扩展到实际输入大小。Parmar等人尝试仅在每个查询像素的局部邻域应用自注意力,后续工作如Hu等人、Ramachandran等人、Zhao等人进一步研究,用局部多头点积自注意力块完全替代卷积,但在硬件实现上存在效率问题。
- 稀疏Transformer与分块注意力:Sparse Transformers采用可扩展近似方法实现全局自注意力以应用于图像;Weissenborn等人及Ho等人、Wang等人尝试在不同大小块中应用注意力,极端情况下仅沿单个轴应用,但这些专门的注意力架构需复杂工程才能在硬件加速器上高效实现。
- 与本文相关的模型研究
- 类似ViT的模型:Cordonnier等人的模型与ViT相似,从输入图像提取2×2大小的块并应用全局自注意力,但使用小补丁尺寸使其仅适用于小分辨率图像,而本文ViT能处理中等分辨率图像,且本文进一步证明大规模预训练使ViT优于现有CNN技术。
- 结合CNN与自注意力的模型:众多研究关注将卷积神经网络(CNNs)与自注意力形式结合,用于图像分类、对象检测、视频处理、无监督对象发现或统一文本 - 视觉任务等,如Bello等人通过自注意力增强特征图进行图像分类,Hu等人、Carion等人将自注意力应用于CNN输出以完成对象检测等任务。
- 图像GPT(iGPT)模型:iGPT先降低图像分辨率和颜色空间,再将Transformers应用于图像像素,以无监督方式训练为生成模型,其生成的表示经微调或线性探测可用于分类,在ImageNet上最高准确率达72%。
- 大规模图像识别相关研究:本文研究属于探索比标准ImageNet数据集更大规模图像识别的范畴,已有研究通过使用额外数据源在标准基准上取得先进成果,如Mahajan等人、Touvron等人、Xie等人的工作,本文聚焦于ImageNet - 21k和JFT - 300M数据集,训练Transformers而非先前工作中的ResNet模型。
方法-Method
- Vision Transformer (ViT)模型架构
- 图像到序列转换:为适应Transformer输入,将图像 x ∈ R H × W × C x\in\mathbb{R}^{H\times W\times C} x∈RH×W×C 重塑为展平的2D块序列 x p ∈ R N × ( P 2 ⋅ C ) x_{p}\in\mathbb{R}^{N\times(P^{2}\cdot C)} xp∈RN×(P2⋅C),其中 ( H , W ) (H, W) (H,W) 是原始图像分辨率, C C C 是通道数, ( P , P ) (P, P) (P,P) 是每个图像块的分辨率, N = H W / P 2 N = HW/P^{2} N=HW/P2 为块数量(即Transformer有效输入序列长度)。然后通过可训练线性投影将块映射到 D D D 维,得到块嵌入。
- 特殊标记与位置嵌入:类似BERT的
[class]token,在嵌入块序列前添加可学习的嵌入 z 0 0 = x c l a s s z_{0}^{0}=x_{class} z00=xclass,其在Transformer编码器输出时的状态 z L 0 z_{L}^{0} zL0 作为图像表示 y y y。位置嵌入采用标准可学习的1D位置嵌入,添加到块嵌入中以保留位置信息,实验发现更复杂的2D感知位置嵌入未显著提升性能。 - Transformer编码器结构:由交替的多头自注意力(MSA)层和MLP块组成,层归一化(LN)在每个块前应用,残差连接在每个块后应用。MLP包含两层,使用GELU非线性激活函数。
- 归纳偏差分析:ViT与CNN相比,图像特定归纳偏差较少。CNN每层都具有局部性、二维邻域结构和翻译等变性,而ViT中只有MLP层是局部和翻译等变的,自注意力层是全局的,二维邻域结构仅在图像切块和微调调整位置嵌入时使用,位置嵌入初始化时不包含块的2D位置信息,需从头学习空间关系。
- 混合架构:作为原始图像块输入的替代方案,输入序列可由CNN的特征图形成。将从CNN特征图提取的块应用块嵌入投影
E
E
E(特殊情况下,块空间大小可为
1×1,即通过展平特征图空间维度并投影到Transformer维度获得输入序列),再添加分类输入嵌入和位置嵌入。
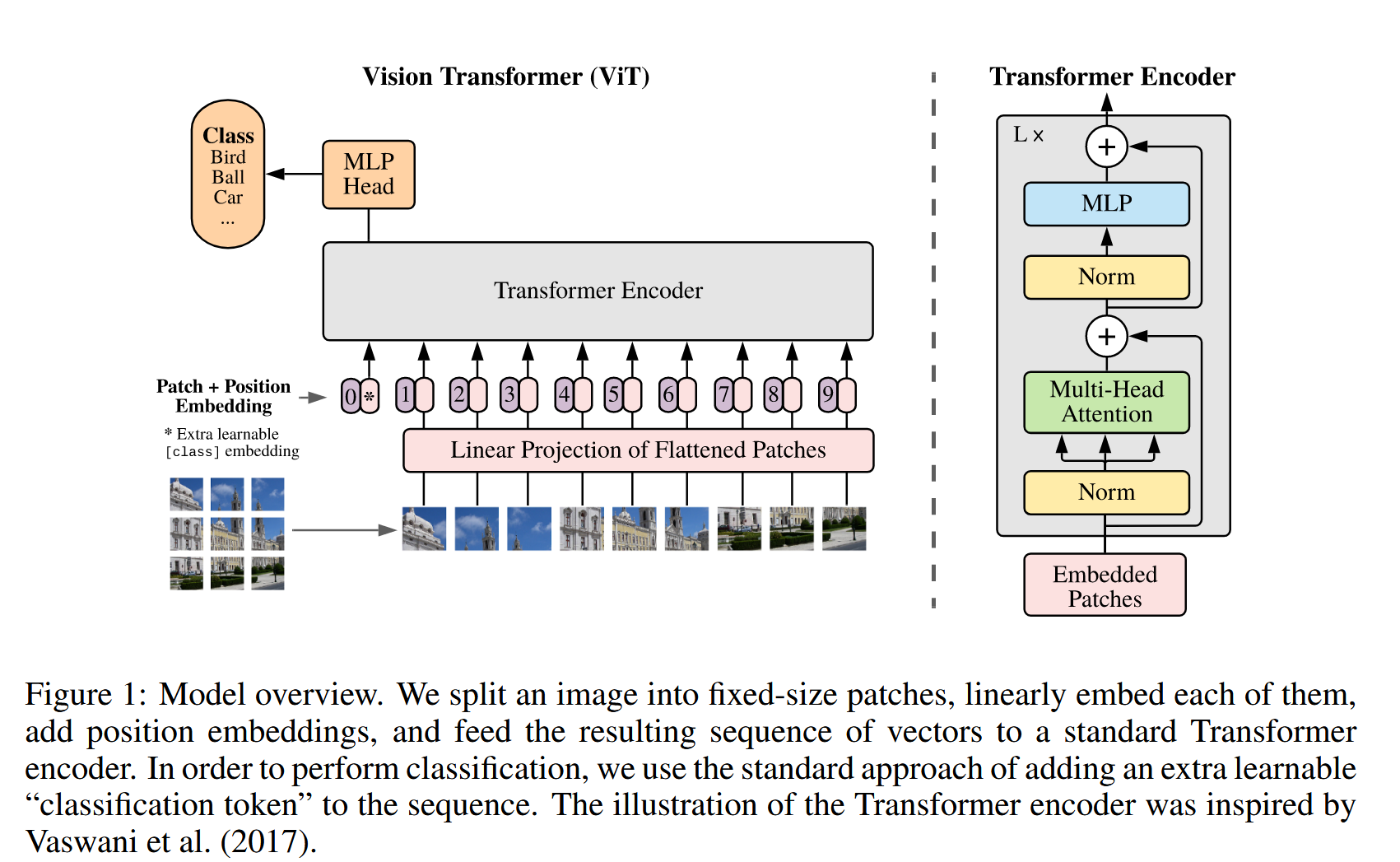
图1:模型概述。我们将一幅图像分割成固定大小的块,对每个块进行线性嵌入,添加位置嵌入,并将得到的向量序列输入到标准的Transformer编码器中。为了进行分类,我们使用向序列中添加一个额外可学习的“分类标记”的标准方法。Transformer编码器的图示灵感来自Vaswani等人(2017年)的研究.
- 微调与高分辨率处理
- 微调策略:通常先在大数据集上预训练ViT,然后针对下游任务微调。微调时移除预训练的预测头,添加零初始化的(D\times K)前馈层((K)为下游类数量)。
- 分辨率调整:微调时使用比预训练更高的分辨率有益。输入更高分辨率图像时,保持块大小不变,会使有效序列长度增加。由于预训练位置嵌入在新分辨率下可能不再有意义,需根据原始图像位置对其进行2D插值。此分辨率调整和块提取是向ViT手动注入图像2D结构归纳偏差的唯一步骤。
实验-Experiments
设置-Setup
- 数据集
- 为探究模型可扩展性,使用多个数据集进行实验,包括ILSVRC - 2012 ImageNet数据集(1k类,1.3M图像)及其超集ImageNet - 21k(21k类,14M图像)、JFT(18k类,303M高分辨率图像)。对预训练数据集进行去重处理,使其与下游任务测试集无重叠。
- 模型训练后转移到多个基准任务进行评估,如ImageNet(原始验证标签和ReaL标签)、CIFAR - 10/100、Oxford - IIIT Pets、Oxford Flowers - 102以及19任务的VTAB分类套件(分为自然、专业、结构化任务组,每个任务使用1000个训练示例评估低数据转移能力)。对这些数据集的预处理遵循Kolesnikov等人的方法。
- 模型变体
- ViT配置基于BERT,包括“Base” “Large” “Huge”等模型,用如ViT - L/16表示“Large”变体且输入块大小为16×16的模型,模型的Transformer序列长度与块大小平方成反比,块越小计算成本越高。
- 基线CNN使用ResNet并进行修改,将Batch Normalization层替换为Group Normalization层,使用标准化卷积,记为“ResNet (BiT)”。
- 混合模型将CNN中间特征图输入ViT(块大小为1“像素”),通过改变取ResNet特征图的阶段来实验不同序列长度,如取常规ResNet50的第4阶段输出或调整第3阶段结构并取其输出(使序列长度变为4倍,对应更昂贵的ViT模型)。
- 训练与微调
- 所有模型(包括ResNets)使用Adam优化器训练, β 1 = 0.9 \beta_{1}=0.9 β1=0.9, β 2 = 0.999 \beta_{2}=0.999 β2=0.999,批量大小为4096,应用高权重衰减(0.1),发现这对所有模型的转移有益。使用线性学习率预热和衰减策略,附录B.1给出详细信息。
- 微调时所有模型使用SGD和动量,批量大小为512,ImageNet结果中,ViT - L/16和ViT - H/14分别在512和518分辨率下微调,并使用Polyak平均(因子为0.9999)。
- 评估指标
- 通过少样本或微调准确率报告下游数据集结果。微调准确率反映模型在特定数据集上微调后的性能,少样本准确率通过解决正则化最小二乘回归问题获得,该问题将训练图像子集(冻结)的表示映射到 { − 1 , 1 } K \{-1,1\}^K {−1,1}K 目标向量,虽主要关注微调性能,但少样本准确率用于快速评估(微调成本过高时)。
与现有SOTA技术的比较-Comparison to State of The Art
- 对比对象与指标
- 此节主要将ViT的最大模型(ViT - H/14和ViT - L/16)与文献中的最先进CNN(如Big Transfer (BiT)和Noisy Student)进行比较,比较指标为在多个流行图像分类基准上的准确率(报告均值和标准差,取三次微调运行的平均值)以及预训练所需的计算资源(TPUv3 - core - days,即TPU v3核心数乘以训练天数)。
- 与BiT对比结果
- ViT - L/16模型在JFT - 300M数据集上预训练后,在所有任务上的性能均优于在相同数据集上预训练的BiT - L,且所需计算资源显著减少。
- ViT - H/14模型进一步提升性能,尤其在更具挑战性的数据集(如ImageNet、CIFAR - 100和VTAB套件)上表现出色。
- 预训练于ImageNet - 21k数据集的ViT - L/16模型在多数数据集上也有良好表现,且预训练资源需求较少(在标准云TPUv3上用8个核心约30天可训练完成)。
- 在VTAB基准上的对比
- 在VTAB基准测试中,将其任务分解为自然、专业、结构化任务组进行评估。
- ViT - H/14在自然和结构化任务上超越BiT - R152x4及其他方法(如VIVI、S4L),在专业化任务上,与顶级模型性能相似。
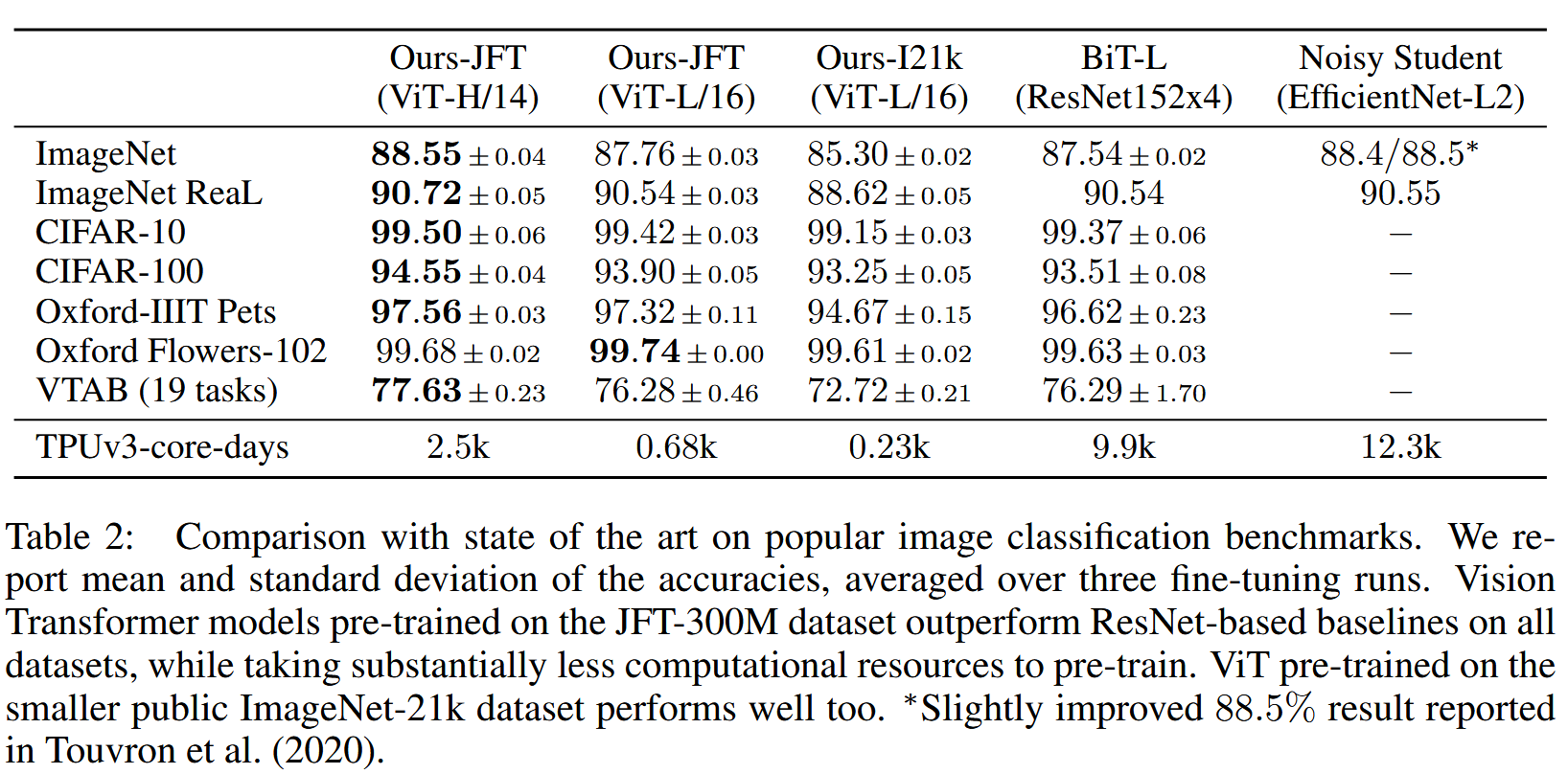
表2:与流行图像分类基准上的现有技术对比。我们报告准确率的平均值和标准差,取三次微调运行的平均值。在JFT - 300M数据集上预训练的Vision Transformer模型在所有数据集上均优于基于ResNet的基线模型,同时预训练所需计算资源显著减少。在较小的公共ImageNet - 21k数据集上预训练的ViT表现也不错。 ∗ ^* ∗Touvron等人(2020年)报告的88.5%的结果略有改进。
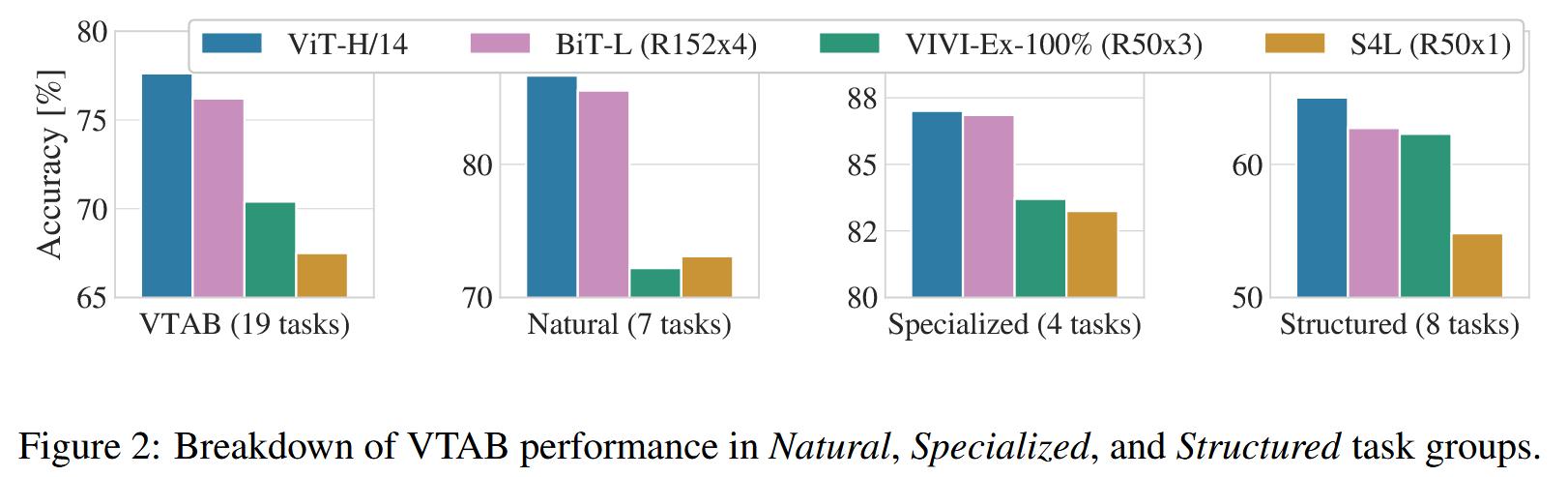
图2:VTAB在自然、专业和结构化任务组中的性能细分。
预训练数据需求-Pre-Training Data Requirements
- 研究目的
- 探究Vision Transformer在预训练数据量方面的需求,由于ViT相比ResNets在视觉上的归纳偏差较少,因此研究数据集大小对其性能的影响至关重要。
- 实验系列一
- 实验设置:预训练ViT模型于不同大小的数据集(ImageNet、ImageNet - 21k、JFT - 300M),为提高小数据集上的性能,优化三个基本正则化参数(权重衰减、Dropout、标签平滑)。
- 实验结果:在最小数据集ImageNet上预训练时,尽管进行了(适度)正则化,ViT - Large模型性能仍不如ViT - Base模型;在ImageNet - 21k数据集上预训练时,两者性能相似;只有在JFT - 300M数据集上预训练时,大模型的优势才充分体现。同时,与不同大小的BiT模型对比,在ImageNet上BiT CNNs性能优于ViT,但随着数据集增大,ViT性能超越BiT。
- 实验系列二
- 实验设置:在JFT数据集的随机子集(9M、30M、90M及完整的300M)上训练模型,不对小数据集子集进行额外正则化,所有设置使用相同超参数,但使用早停法并报告训练期间达到的最佳验证准确率。为节省计算资源,报告少样本线性准确率而非完整微调准确率。
- 实验结果:在较小数据集上,与计算成本相当的ResNets相比,Vision Transformers过拟合更严重。例如,ViT - B/32比ResNet50稍快,但在9M子集上表现差很多,在90M + 子集上表现更好;ResNet152x2和ViT - L/16也有类似情况。这进一步证实了卷积归纳偏差对小数据集有用,而对于大数据集,直接从数据中学习相关模式就足够,甚至更有益的直觉。
- 总结与展望
- 少样本结果(如图4在ImageNet上的结果)以及VTAB上的低数据结果表明,ViT在极低数据转移方面具有潜力,对ViT少样本特性的进一步分析是未来工作的一个有前景的方向。
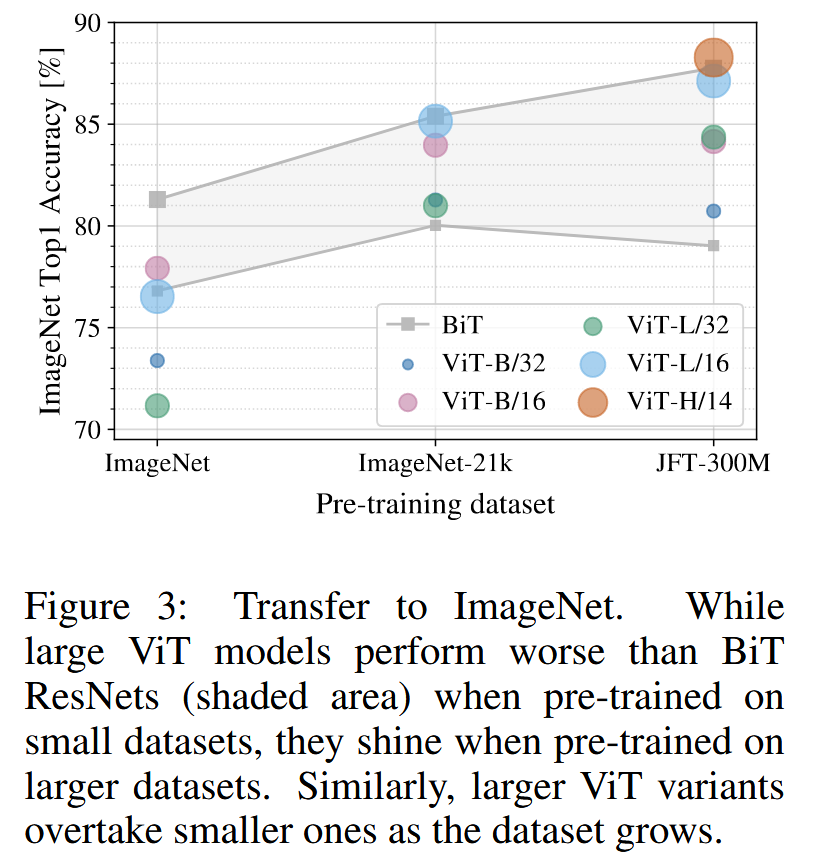
图3:迁移至ImageNet。在小数据集上预训练时,大型ViT模型的性能比BiT ResNets(阴影区域)差,但在大数据集上预训练时,它们表现出色。同样,随着数据集的增长,较大的ViT变体超过较小的变体.
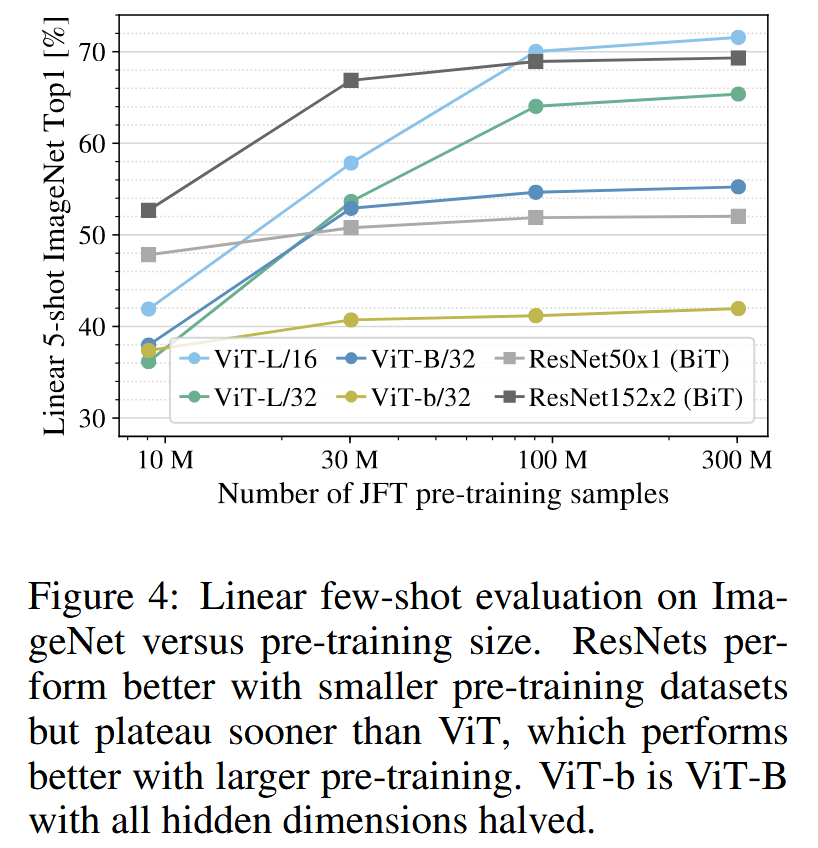
图4:ImageNet上的线性少样本评估与预训练数据量的关系。ResNets在较小的预训练数据集上表现更好,但比ViT更快达到性能瓶颈,而ViT在较大的预训练数据集上表现更好。ViT - b是所有隐藏维度减半的ViT - B.
缩放研究-Scaling Study
- 研究目的
- 通过评估从JFT - 300M数据集的转移性能,对不同模型进行控制变量的缩放研究,以评估各模型在数据量不成为性能瓶颈时的性能与预训练成本之间的关系。
- 模型设置
- 模型集包括7种ResNets(R50x1、R50x2、R101x1、R152x1、R152x2,其中R152x2和R200x3预训练14个轮次,其余预训练7个轮次)、6种Vision Transformers(ViT - B/32、B/16、L/32、L/16,其中L/16和H/14预训练14个轮次,其余预训练7个轮次)以及5种混合模型(R50 + ViT - B/32、B/16、L/32、L/16预训练7个轮次,R50 + ViT - L/16预训练14个轮次,混合模型名称中的数字表示ResNet骨干网络中的总下采样率)。
- 实验结果与分析
- 性能与计算量权衡:Vision Transformers在性能/计算权衡上优于ResNets,平均在5个数据集上,ViT使用约2 - 4倍更少计算资源可达到与ResNets相同的性能。
- 混合架构表现:混合架构在小计算预算下略优于ViT,但随着模型增大,这种优势消失。这一结果令人意外,原以为卷积局部特征处理在任何尺寸下都能辅助ViT。
- ViT的缩放潜力:Vision Transformers在尝试的范围内未显示出性能饱和迹象,这为未来进一步缩放努力提供了动力。
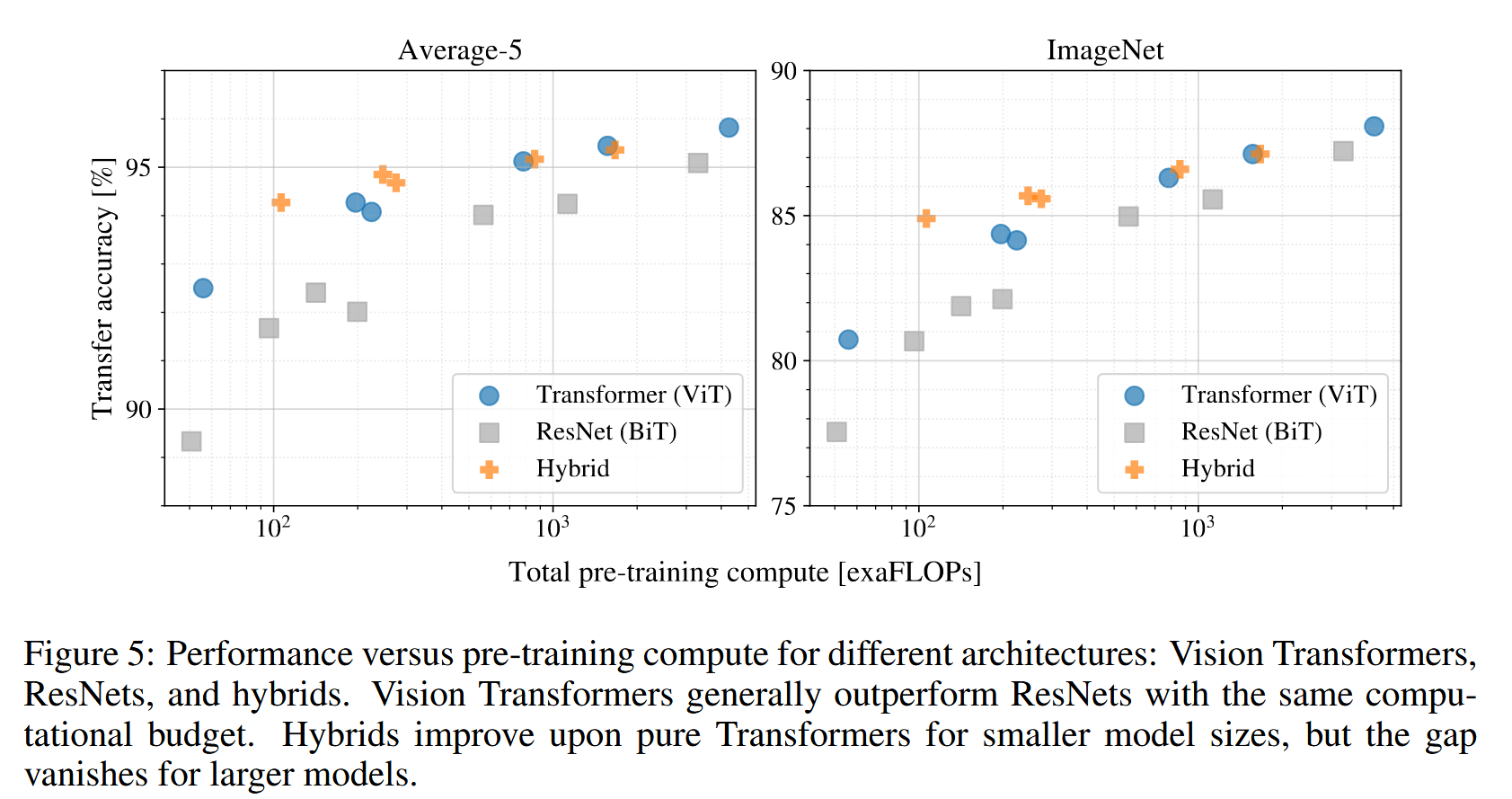
图5:不同架构(Vision Transformers、ResNets和混合架构)的性能与预训练计算量的关系。在相同计算预算下,Vision Transformers通常优于ResNets。对于较小模型尺寸,混合架构比纯Transformer有所改进,但对于较大模型,差距消失.
审视Vision Transformer-Inspecting Vision Transformer
- 研究目的
- 为深入理解Vision Transformer如何处理图像数据,对其内部表示进行分析,包括模型各层对图像信息的处理方式以及注意力机制在图像空间中的作用。
- 第一层嵌入层分析
- 模型第一层将展平的图像块线性投影到低维空间,学习到的嵌入滤波器主成分类似于表示每个块内精细结构的低维基函数,表明该层开始对图像块内信息进行有效编码。
- 位置嵌入分析
- 位置嵌入学习到编码图像内距离信息,表现为位置嵌入相似性与图像中块的距离相关,即更近的块倾向于有更相似的位置嵌入,且同行/列的块嵌入相似,在大网格中有时呈现正弦结构。这解释了为何手工设计的2D感知嵌入变体未带来性能提升,因为模型自身能有效学习到位置信息。
- 自注意力机制分析
- 注意力距离与信息整合:通过计算注意力权重的平均距离(类比CNN中的感受野大小),发现部分注意力头在最低层就能够关注到大部分图像,表明模型具备全局信息整合能力,且注意力距离随网络深度增加。不同头部在低层注意力距离差异大,部分关注全局,部分关注局部区域,在混合模型中应用ResNet前的局部注意力不太明显,可能起到与CNN早期卷积层相似的功能。
- 注意力关注区域与语义相关性:模型在分类时关注的图像区域与语义相关,表明自注意力机制能够根据分类任务需求有效聚焦于图像中重要区域,从而提取有意义的特征用于分类决策。通过Attention Rollout方法计算注意力映射,可视化了输出标记到输入空间的注意力分布,进一步证实了模型对图像语义相关区域的关注。

图6: 从输出标记到输入空间的注意力的代表性示例。详见附录D.7
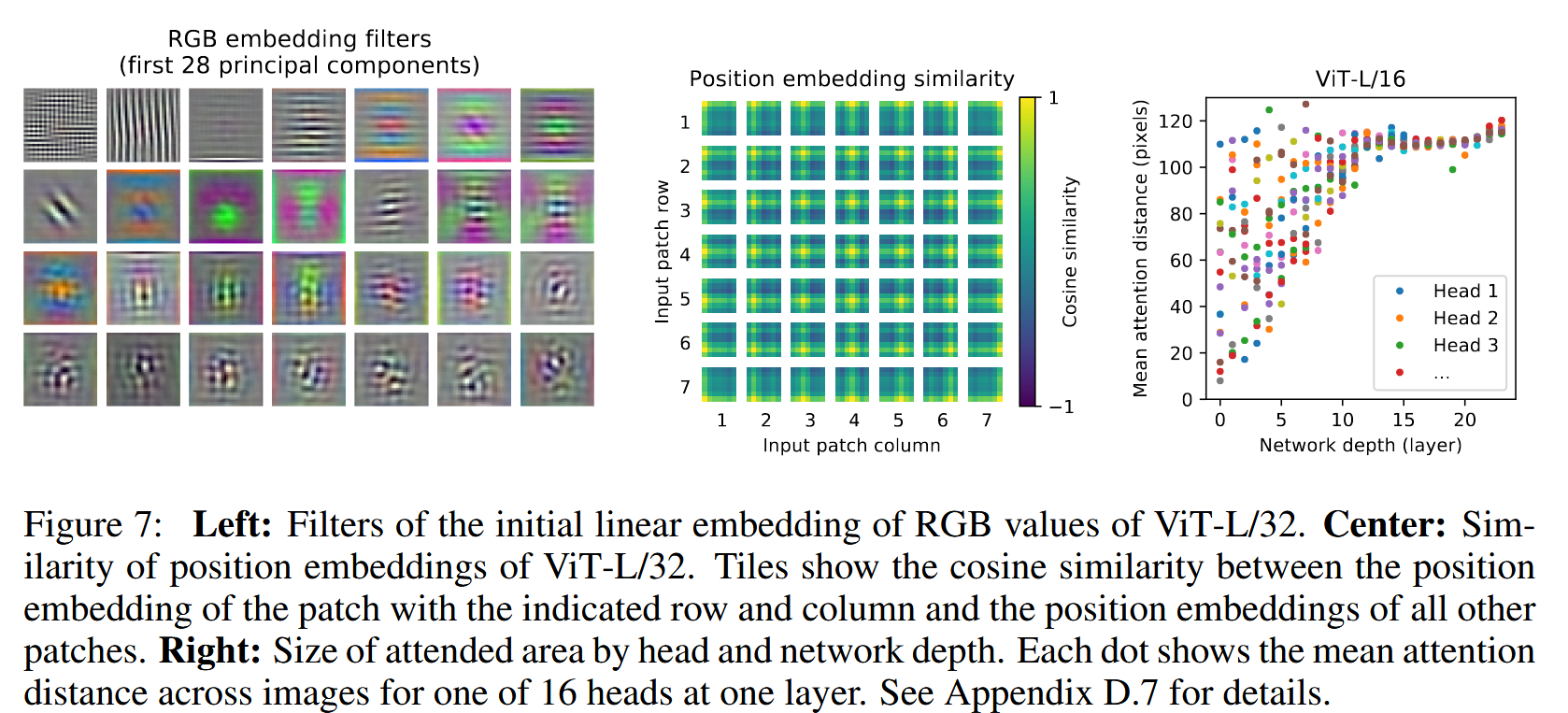
图7:左:ViT - L/32对RGB值进行初始线性嵌入的滤波器。中:ViT - L/32位置嵌入的相似性。方格展示了指定行和列的图像块位置嵌入与所有其他图像块位置嵌入之间的余弦相似度。右:按注意力头和网络深度划分的关注区域大小。每个点表示某一层中16个注意力头之一跨图像的平均注意力距离。详见附录D.7.
自监督-Self Supervision
- 实验设置
- 任务模仿:模仿BERT中的掩码语言建模任务,对Vision Transformer进行掩码块预测的自监督预训练实验。
- 数据处理:随机将50%的块嵌入进行破坏,具体方式为80%的概率将其替换为可学习的
[mask]嵌入,10%的概率替换为随机其他块嵌入,10%的概率保持不变。预测每个被破坏块的3位平均颜色(共512种颜色)。 - 训练参数:在JFT数据集上使用Adam优化器训练100万步(约14个epoch),批量大小为4096,学习率为 2 ⋅ 1 0 − 4 2 \cdot 10^{-4} 2⋅10−4,热身步数为10000,采用余弦退火学习率衰减。
- 实验结果
- 较小的ViT - B/16模型通过自监督预训练在ImageNet上达到了79.9%的准确率,相比从零开始训练提高了2%,但仍比监督预训练低4%。
- 发现不同的预测目标设置(如仅预测平均颜色、预测缩小版本的颜色、对整个块进行L2回归)效果都不错,但L2回归稍差,最终报告仅预测平均颜色的结果,因为其在少样本性能上表现最佳。
- 实验表明掩码块预测任务不需要大量的预训练步数或像JFT这样的大型数据集就能在ImageNet分类上取得类似的性能提升,预训练10万步后下游性能的提升就开始递减,且在ImageNet上预训练也能看到类似的增益。
- 未来方向:作者认为对比预训练(如MoCo、SimCLR等方法)是未来探索的一个方向。
结论-Conclusion
- 核心成果回顾
- 文中展示了将标准Transformer架构直接应用于图像分类任务的可行性,提出的Vision Transformer(ViT)模型在大规模图像识别方面表现出色,能达到或超越当前先进的卷积神经网络(CNN)的性能水平。
- 通过在不同规模的数据集(如ImageNet、ImageNet - 21k、JFT - 300M等)上进行预训练和微调实验,揭示了ViT在不同数据量下的性能特点,证实大数据集预训练对其发挥优势至关重要。
- 模型特性探讨
- 分析了ViT相较于CNN不同的归纳偏差特点,ViT缺乏CNN固有的如局部性、二维邻域结构和翻译等变性等归纳偏差,但在大规模数据训练下能弥补这些不足,进而展现出强大的图像分类能力。
- 研究了ViT内部的一些机制,比如其第一层嵌入层对图像块信息的编码方式、位置嵌入对图像距离信息的有效编码,以及自注意力机制在整合图像全局信息、关注语义相关区域等方面的作用。
- 与其他模型对比及优势体现
- 在与先进的CNN模型(如BiT ResNets等)对比中,在相同计算预算下,ViT通常能展现出更好的性能表现,且在预训练所需计算资源方面也有优势,尤其在大规模数据集上预训练后,在多个基准测试任务上能取得优异成绩。
- 对于混合架构(结合CNN和Transformer的模型),在小模型尺寸时其比纯Transformer有一定优势,但随着模型增大,这种优势逐渐消失,进一步凸显了ViT自身在大规模场景下的潜力。
- 研究意义与展望
- 这项研究为计算机视觉领域引入了Transformer架构的新思路,证明了其在图像分类任务上的巨大潜力,拓展了后续相关研究的方向。
- 指出未来可进一步探索ViT在少样本学习等方面的特性,以及继续深入挖掘Transformer架构在计算机视觉中更多的应用和优化空间,推动计算机视觉领域不断向前发展。


















 2784
2784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











