







Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
本文 “Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation” 提出反向对抗扰动(RAP)方法,通过构建极小极大双层优化问题,寻找位于平坦区域的对抗样本,有效缓解代理模型过拟合问题,显著提升对抗样本的迁移性,在多种攻击场景和模型上表现优异。
摘要-Abstract
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples, which can produce erroneous predictions by injecting imperceptible perturbations. In this work, we study the transferability of adversarial examples, which is significant due to its threat to real-world applications where model architecture or parameters are usually unknown. Many existing works reveal that the adversarial examples are likely to overfit the surrogate model that they are generated from, limiting its transfer attack performance against different target models. To mitigate the overfitting of the surrogate model, we propose a novel attack method, dubbed reverse adversarial perturbation (RAP). Specifically, instead of minimizing the loss of a single adversarial point, we advocate seeking adversarial example located at a region with unified low loss value, by injecting the worst-case perturbation (i.e., the reverse adversarial perturbation) for each step of the optimization procedure. The adversarial attack with RAP is formulated as a min-max bi-level optimization problem. By integrating RAP into the iterative process for attacks, our method can find more stable adversarial examples which are less sensitive to the changes of decision boundary, mitigating the overfitting of the surrogate model. Comprehensive experimental comparisons demonstrate that RAP can significantly boost adversarial transferability. Furthermore, RAP can be naturally combined with many existing black-box attack techniques, to further boost the transferability. When attacking a real-world image recognition system, i.e., Google Cloud Vision API, we obtain 22% performance improvement of targeted attacks over the compared method.
深度神经网络(DNNs)已被证明易受对抗样本的攻击,这些对抗样本通过注入难以察觉的扰动就能使模型产生错误的预测。在这项研究中,我们探讨了对抗样本的迁移性,这一点意义重大,因为在现实应用中,模型架构或参数通常是未知的,而对抗样本的迁移性对这些应用构成了威胁。许多现有研究表明,对抗样本很可能会过拟合其生成所基于的代理模型,这限制了它对不同目标模型的迁移攻击性能。为了减轻代理模型的过拟合问题,我们提出了一种新颖的攻击方法,称为反向对抗扰动(RAP)。具体而言,我们不追求最小化单个对抗点的损失,而是主张寻找位于具有统一低损失值区域的对抗样本,在优化过程的每一步中注入最坏情况的扰动(即反向对抗扰动)。采用RAP的对抗攻击被表述为一个极小极大双层优化问题。通过将RAP集成到攻击的迭代过程中,我们的方法能够找到更稳定的对抗样本,这些样本对决策边界的变化不太敏感,从而减轻了代理模型的过拟合现象。全面的实验对比表明,RAP能够显著提升对抗样本的迁移性。此外,RAP可以自然地与许多现有的黑盒攻击技术相结合,进一步提高迁移性。在攻击现实世界中的图像识别系统(即谷歌云视觉API)时,与对比方法相比,我们的目标攻击性能提高了22%.
引言-Introduction
该部分主要介绍研究背景、问题和创新点,旨在说明研究对抗样本迁移性的重要性,以及提出的RAP方法对解决现有问题的意义。具体内容如下:
- 研究背景:深度神经网络(DNNs)在自动驾驶、人脸识别等安全关键任务中应用广泛。然而,其易受对抗样本攻击,这些样本与自然样本难以区分,但会使模型产生错误预测。在实际应用中,DNN模型常对用户隐藏,攻击者需在黑盒设置下生成对抗样本,因此对抗样本的迁移性至关重要,这一特性也受到了更多研究关注。
- 现有问题:在白盒设置下,基于梯度的攻击(如PGD)虽攻击性能良好,但迁移性较差。这是因为对抗样本容易过拟合代理模型,当代理模型参数稍有变化时,攻击损失会大幅增加,导致对抗样本无法攻击目标模型。尽管已有多种技术尝试缓解过拟合、提高迁移性,但迁移设置与理想白盒设置下的攻击性能仍存在较大差距,尤其是在目标攻击方面。
- 研究创新点:提出反向对抗扰动(RAP)方法,该方法从对抗样本损失景观的平坦性这一新颖视角出发,鼓励对抗样本及其邻域区域都具有低损失值。通过将其构建为一个极小极大双层优化问题,帮助逃离尖锐的局部最小值,寻找相对平坦的局部最小值,从而找到更稳定、对决策边界变化更不敏感的对抗样本,减轻代理模型的过拟合问题。此外,还设计了RAP的晚启动变体(RAP-LS),并指出RAP可与现有黑盒攻击技术自然结合,进一步提升迁移性。
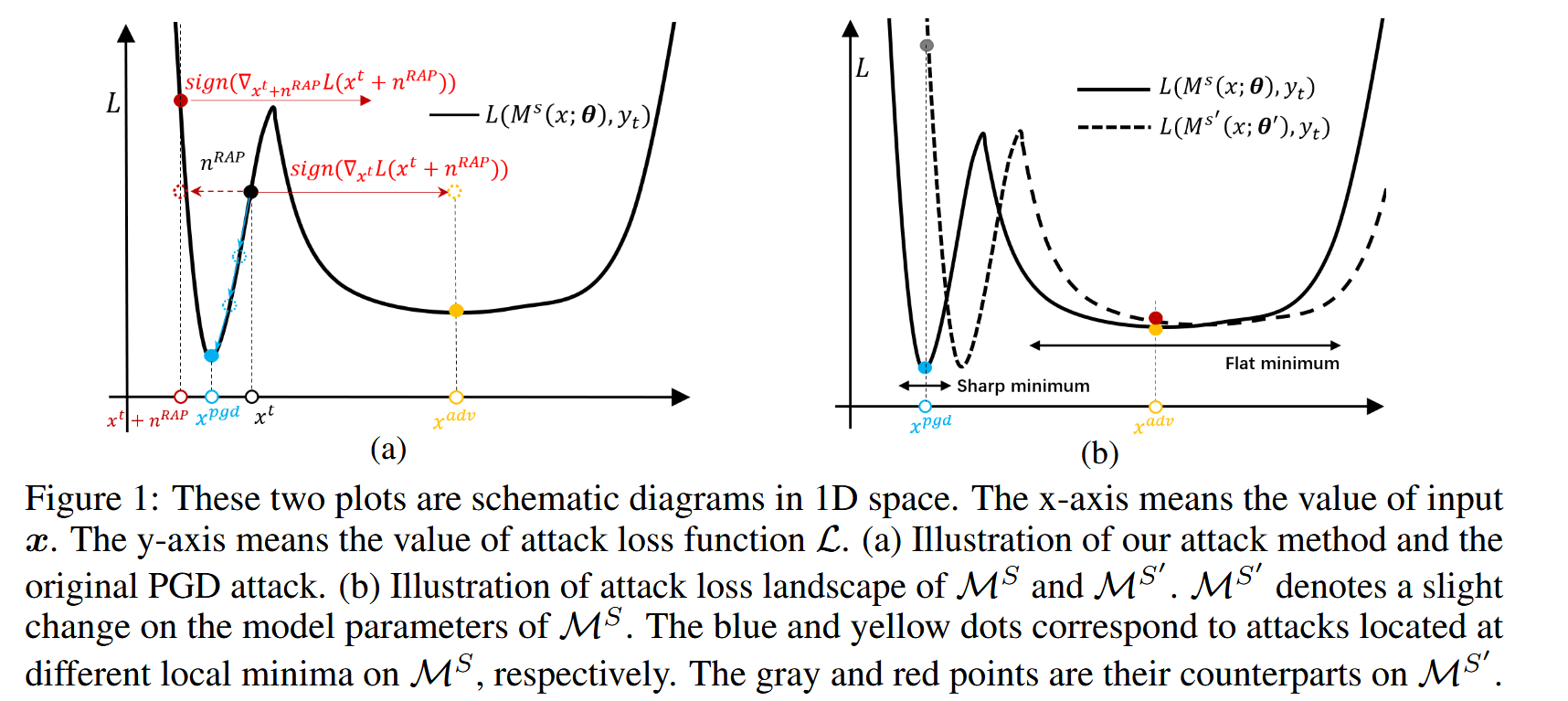
图1:这两幅图是一维空间的示意图。x 轴表示输入
x
x
x 的值。y 轴表示攻击损失函数
L
L
L 的值。
(a)我们的攻击方法和原始PGD攻击的图示。
(b)
M
S
M^S
MS 和
M
S
′
M^{S'}
MS′ 的攻击损失景观图示。
M
S
′
M^{S'}
MS′ 表示
M
S
M^{S}
MS 模型参数的微小变化。蓝色和黄色点分别对应于位于
M
S
M^{S}
MS 上不同局部最小值的攻击。灰色和红色点是它们在
M
S
′
M^{S'}
MS′ 上的对应点。
相关工作-Related Work
该部分主要回顾与黑盒攻击中对抗样本迁移性相关的研究,将黑盒攻击分为基于查询的攻击和基于迁移的攻击两类,重点聚焦于后者,并对提升对抗样本迁移性的方法进行了梳理。
- 黑盒攻击分类:黑盒攻击可分为基于查询的攻击和基于迁移的攻击。基于查询的攻击依靠对目标模型的迭代查询反馈来实施攻击;基于迁移的攻击则利用在代理模型上生成的对抗样本去攻击目标模型,本文主要关注基于迁移的攻击。
- 提升对抗样本迁移性的方法
- 输入变换:利用数据增强相关的手段来提升对抗样本迁移性,如随机调整大小和填充、随机缩放、对抗混合(adversarial mixup)等。此外,还有通过计算一组平移图像的梯度以及在选定变换分布上合成对抗样本的方法,都能在一定程度上增强迁移性。
- 梯度修改:部分研究通过改进梯度计算或更新策略来提升迁移性,像将动量融入更新策略、使用Nesterov加速梯度、调整梯度步长的方差等。也有针对特定模型架构(如跳跃连接)设计的方法,但这些方法在拓展到其他架构时存在一定难度。
- 中间特征攻击:一些研究提出利用特征空间约束来生成更具迁移性的攻击,但这类方法往往需要确定最佳的中间层或为所有被攻击类别训练一对一的二分类器。近期有研究发现,具有更多迭代次数和logit损失的迭代攻击能实现较高的目标迁移性,甚至超越基于特征的攻击。
- 生成模型:有方法利用生成模型来生成对抗扰动,如训练生成模型匹配源类和目标类的分布以增加目标迁移性,但在大规模数据集上学习扰动生成器并非易事。
- 研究现状总结:当前迁移攻击的性能,尤其是目标攻击的性能仍不尽人意。本文从对抗样本平坦性的角度研究对抗迁移性,提出新算法寻找位于平坦局部最小值的对抗样本。
方法-Methodology
该部分主要介绍了反向对抗扰动(RAP)的方法原理,具体包括迁移对抗攻击的基础、RAP的详细内容以及对RAP的深入分析,旨在解决对抗样本对代理模型过拟合导致迁移性差的问题。
迁移对抗攻击的预备知识-Preliminaries of Transfer Adversarial Attack
该部分主要介绍了迁移对抗攻击的基础概念,为后续理解研究内容做铺垫,具体如下:
- 迁移对抗攻击流程:给定一个良性样本 ( x , y ) ∈ ( X , Y ) (x, y) \in(X, Y) (x,y)∈(X,Y) ,迁移对抗攻击首先在邻域区域 B ϵ ( x ) = x ′ : ∥ x ′ − x ∥ p ≤ ϵ B_{\epsilon}(x)={x': \| x' - x \|_{p} ≤\epsilon} Bϵ(x)=x′:∥x′−x∥p≤ϵ 内,通过攻击白盒替代模型 M s ( x ; θ ) : X → Y M^{s}(x ; \theta): X \to Y Ms(x;θ):X→Y 构建对抗样本 x a d v x^{adv} xadv;然后将 x a d v x^{adv} xadv 用于直接攻击黑盒目标模型 M t ( x ; ϕ ) : X → Y M^{t}(x ; \phi): X \to Y Mt(x;ϕ):X→Y 。攻击目标分为非目标性攻击(误导目标模型,使其输出 M t ( x a d v ; ϕ ) ≠ y M^{t}(x^{adv} ; \phi) ≠y Mt(xadv;ϕ)=y )和目标性攻击(让目标模型输出特定标签 M t ( x a d v ; ϕ ) = y t M^{t}(x^{adv} ; \phi)=y_{t} Mt(xadv;ϕ)=yt, y t ∈ Y y_{t} \in Y yt∈Y 为目标标签)。
- 现有迁移攻击方法的一般公式:以目标性攻击为例,许多现有迁移攻击方法的一般公式为 m i n x a d v ∈ B e ( x ) L ( M s ( G ( x a d v ) ; θ ) , y t ) min _{x^{adv} \in \mathcal{B}_{e}(x)} \mathcal{L}\left(\mathcal{M}^{s}\left(\mathcal{G}\left(x^{adv}\right) ; \theta\right), y_{t}\right) minxadv∈Be(x)L(Ms(G(xadv);θ),yt)。其中,损失函数 L \mathcal{L} L 常设置为交叉熵(CE)损失或logit损失; G ( ⋅ ) \mathcal G(\cdot) G(⋅) 是对对抗样本进行变换的函数,不同研究中它被设计为多种形式,如随机缩放填充(DI)、平移变换(TI)、尺度变换(SI)和对抗混合(Admix)等。若 G ( ⋅ ) \mathcal G(\cdot) G(⋅) 设为恒等函数,那么可以采用现成的白盒对抗攻击方法(如I-FSGM、MI-FGSM等)来求解该问题。
反向对抗扰动-Reverse Adversarial Perturbation
该部分主要提出反向对抗扰动(RAP)方法来缓解对抗样本对替代模型的过拟合问题,提升对抗样本的转移性,具体内容如下:
- 问题提出:从替代模型 M S M^{S} MS 生成的对抗样本在目标模型 M T M^{T} MT 上迁移性差,尤其是在目标性的攻击中。以往研究认为这是由于对抗攻击对 M S M^{S} MS 的过拟合。当对抗样本 x p g d x^{pgd} xpgd 处于尖锐局部最小值时,它不稳定且对 M S M^{S} MS 的变化敏感,模型参数的微小改变就可能导致攻击失败。
- 解决思路:为缓解对 M S M^{S} MS 的过拟合,倡导寻找位于平坦局部区域的对抗样本 x a d v x^{adv} xadv,即不仅 x a d v x^{adv} xadv 本身损失值低,其附近点的损失值也应较低。
- 具体方法:通过最小化对抗样本
x
a
d
v
x^{adv}
xadv 局部邻域内的最大损失值来实现上述目标。将
x
a
d
v
x^{adv}
xadv 扰动以最大化攻击损失,得到的扰动称为反向对抗扰动(RAP)。将RAP插入到现有迁移攻击方法的公式中,得到新的优化问题:
m i n x a d v ∈ B κ ( x ) L ( M s ( G ( x a d v + n r a p ) ; θ ) , y t ) min _{x^{adv} \in \mathcal{B}_{\kappa}(x)} \mathcal{L}\left(\mathcal{M}^{s}\left(\mathcal{G}\left(x^{adv}+n^{rap}\right) ; \theta\right), y_{t}\right) minxadv∈Bκ(x)L(Ms(G(xadv+nrap);θ),yt)
其中, n r a p = a r g m a x ∥ n r a p ∥ ∞ ≤ ϵ n L ( M s ( x a d v + n r a p ; θ ) , y t ) n^{rap}=\underset{\left\| n^{rap}\right\| _{\infty} \leq \epsilon_{n}}{arg max } \mathcal{L}\left(\mathcal{M}^{s}\left(x^{adv}+n^{rap} ; \theta\right), y_{t}\right) nrap=∥nrap∥∞≤ϵnargmaxL(Ms(xadv+nrap;θ),yt)。
这是一个极小极大双层优化问题,可通过迭代优化内层最大化和外层最小化问题来求解。- 内层最大化:对于给定的 x a d v x^{adv} xadv,使用投影梯度上升算法求解关于 n r a p n^{rap} nrap 的最大化问题,更新公式为 n r a p ← n r a p + α n ⋅ s i g n ( ∇ n r a p L ( M s ( x a d v + n r a p ; θ ) , y t ) ) n^{rap} \leftarrow n^{rap}+\alpha_{n} \cdot sign\left(\nabla_{n^{rap}} \mathcal{L}\left(\mathcal{M}^{s}\left(x^{adv}+n^{rap} ; \theta\right), y_{t}\right)\right) nrap←nrap+αn⋅sign(∇nrapL(Ms(xadv+nrap;θ),yt)) ,更新 T T T 步,步长 α n = ϵ n T \alpha_{n}=\frac{\epsilon_{n}}{T} αn=Tϵn.
- 外层最小化:给定 n r a p n^{rap} nrap 后,使用现成的求解原问题的算法(如一步投影梯度下降)来求解关于 x a d v x^{adv} xadv 的最小化问题,更新公式为 x a d v ← C l i p B ϵ ( x ) [ x a d v − α ⋅ s i g n ( ∇ x a d v L ( M s ( G ( x a d v + n r a p ) ; θ ) , y t ) ) ] x^{adv} \leftarrow Clip_{\mathcal{B}_{\epsilon}(x)}\left[x^{adv}-\alpha \cdot sign\left(\nabla_{x^{adv}} \mathcal{L}\left(\mathcal{M}^{s}\left(\mathcal{G}\left(x^{adv}+n^{rap}\right) ; \theta\right), y_{t}\right)\right)\right] xadv←ClipBϵ(x)[xadv−α⋅sign(∇xadvL(Ms(G(xadv+nrap);θ),yt))] ,其中 C l i p B ϵ ( x ) ( a ) Clip_{B_{\epsilon}(x)}(a) ClipBϵ(x)(a) 用于将 a a a 裁剪到邻域区域 B ϵ ( x ) B_{\epsilon}(x) Bϵ(x) 内。整体优化过程总结在算法1中。由于关于 x a d v x^{adv} xadv 的优化可由现有算法实现,RAP能自然地与多种方法结合,如输入变换方法。
- RAP的后期启动(LS)变体:初步实验发现,与基线攻击方法相比,RAP收敛所需迭代次数更多,初始迭代时性能略低。原因可能是早期攻击对替代模型的攻击性能较弱,此时求解极小极大问题可能是浪费。更好的策略是在早期只求解最小化问题,快速达到较高对抗攻击性能区域,之后启动RAP同时增强攻击性能和转移性,即RAP-LS。图2的实验结果初步支持了该策略的有效性,后续将进行更广泛评估。
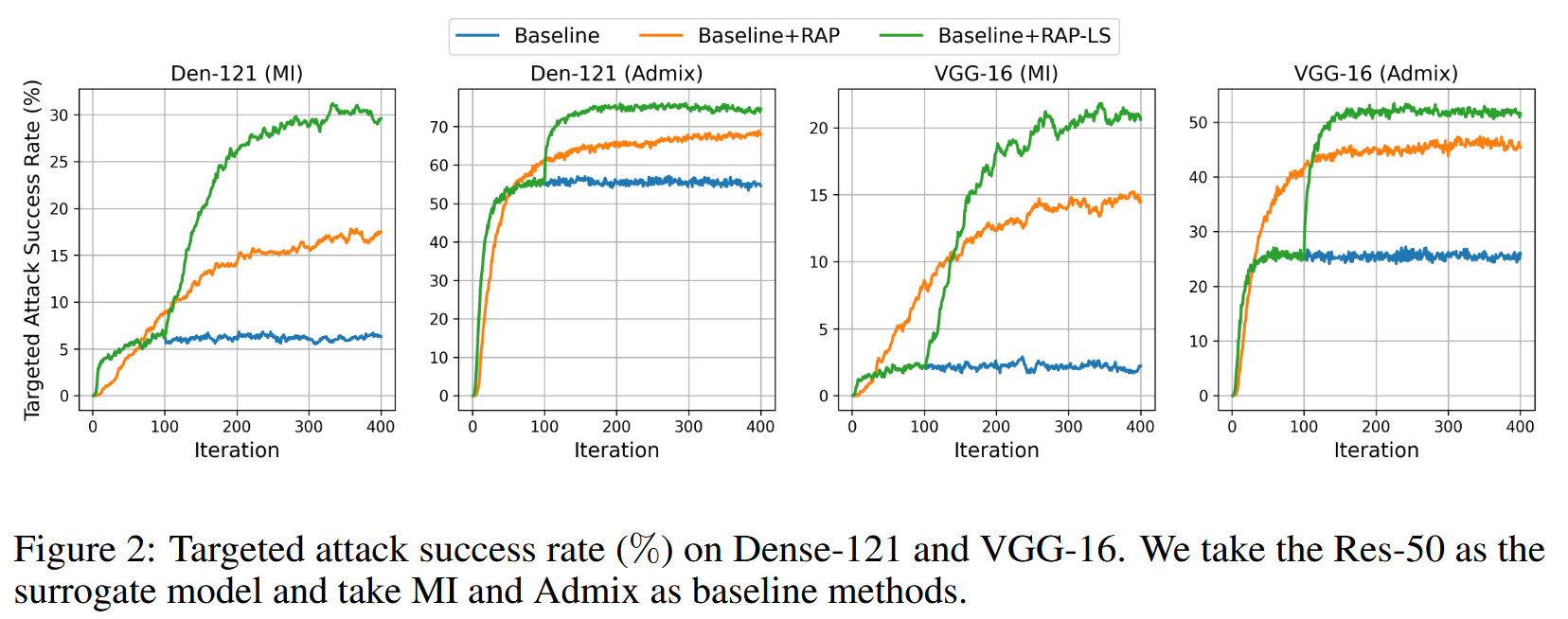
图2:在Dense-121和VGG-16上的目标攻击成功率(%)。我们以Res-50作为代理模型,并将MI和Admix作为基线方法。

- 对RAP的深入分析:为验证RAP能否找到位于局部平坦区域的
x
a
d
v
x^{adv}
xadv ,以ResNet50为代理模型进行非目标性攻击,可视化
x
a
d
v
x^{adv}
xadv 周围的损失景观。结果显示,与基线攻击方法相比,RAP能帮助找到位于平坦区域的
x
a
d
v
x^{adv}
xadv ,这意味着其对模型参数变化更不敏感,进一步证明了RAP在提升对抗样本迁移性方面的有效性。
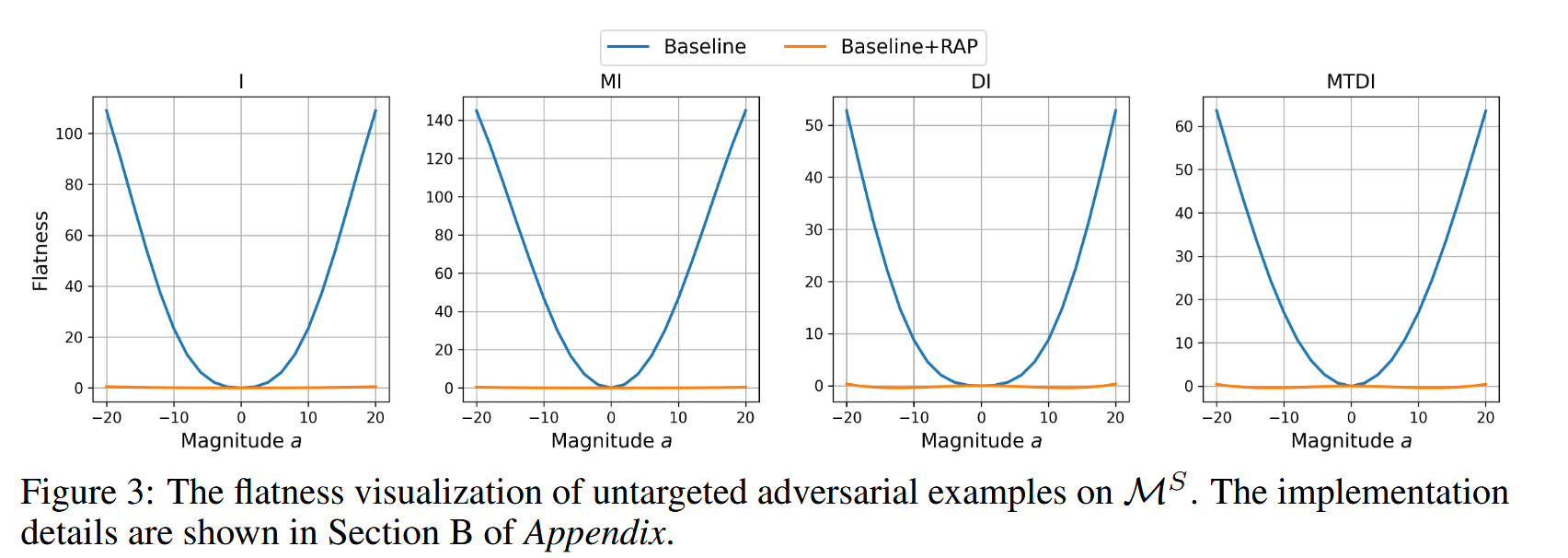
图3:在代理模型 M S M^{S} MS 上非目标性对抗样本的平坦度可视化。具体实现细节见附录B部分。
实验-Experiments
该部分通过多组实验,验证反向对抗扰动(RAP)方法在提升对抗样本迁移性方面的有效性,涵盖多种攻击场景、模型类型及超参数设置,为方法的实用性提供了充分依据。
-
实验设置
- 数据集和评估模型:使用包含1000张图像的ImageNet兼容数据集。代理模型选择Inception-v3、ResNet-50等四种常用网络架构;目标模型除代理模型外,还有Inception-ResNet-v2等更多不同架构;防御模型采用集成对抗训练模型等多种类型。
- 对比方法:选取I-FGSM、MI等多种攻击方法及组合方法,还将RAP与EOT等方法进行对比。
- 实现细节:非目标性攻击采用交叉熵(CE)损失,目标性攻击除CE损失外还实验了logit损失。设置对抗扰动 ϵ \epsilon ϵ 、步长 α \alpha α 、迭代次数 K K K 等参数,对RAP还设定了 K L S K_{LS} KLS 、 α n \alpha_{n} αn 、 ϵ n \epsilon_{n} ϵn等超参数,同时在附录中给出了计算成本等信息。
-
实验结果
-
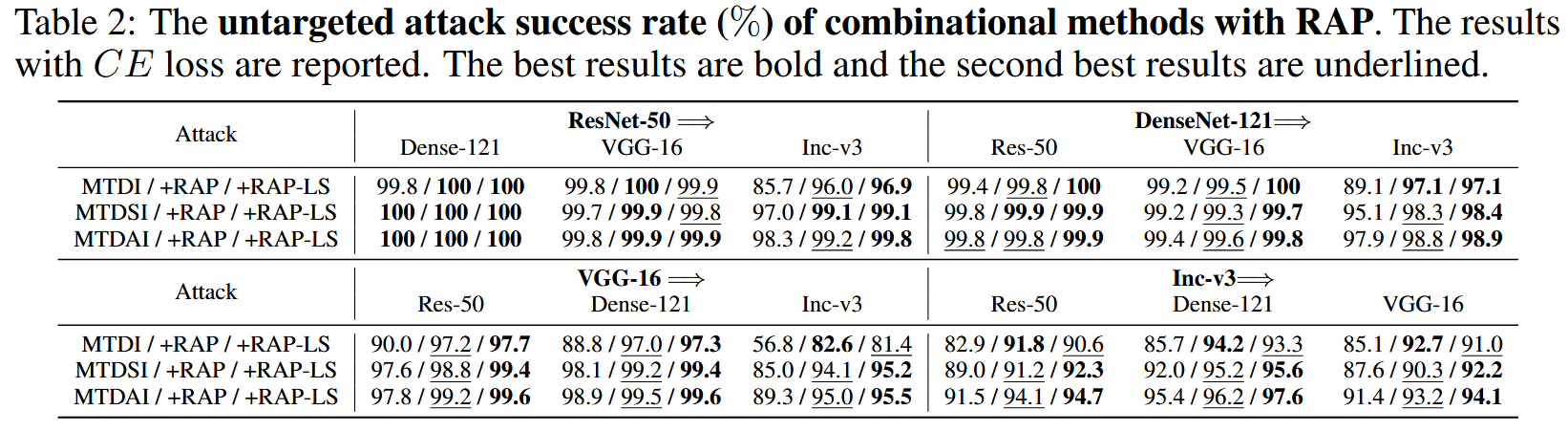
非目标性攻击评估:RAP与不同基线攻击方法结合,在各目标模型上均显著提升攻击成功率,对不同方法提升幅度在6.3%-16.3%之间,RAP-LS进一步增强了几乎所有方法的迁移攻击性能。组合攻击方法结合RAP-LS后,平均攻击成功率分别达到95.4%、97.6%和98.3% 。
表1:使用RAP的基线攻击的非目标性攻击成功率(%)。报告的是使用交叉熵(CE)损失的结果。最佳结果用粗体显示,第二好的结果用下划线标注。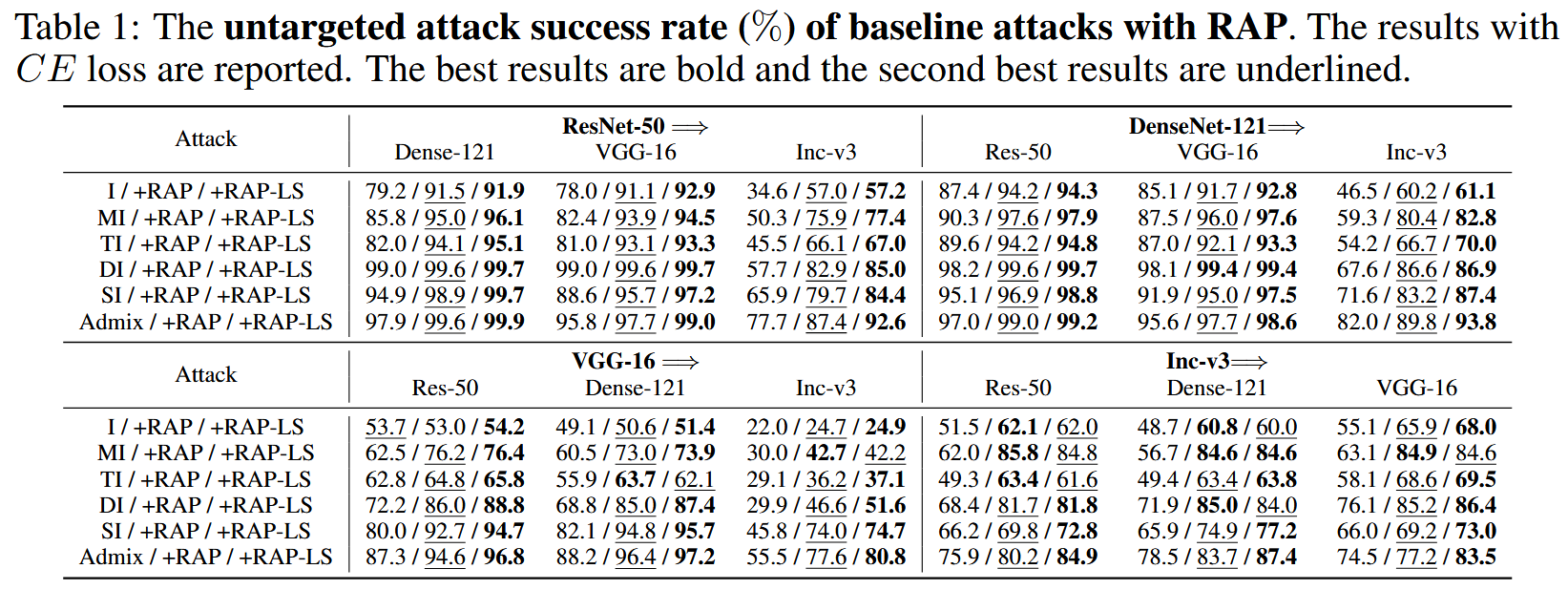
表2:结合RAP的组合攻击方法的非目标性攻击成功率(%)。报告的是采用交叉熵(CE)损失的结果。最优结果以粗体显示,次优结果以下划线标注。
-
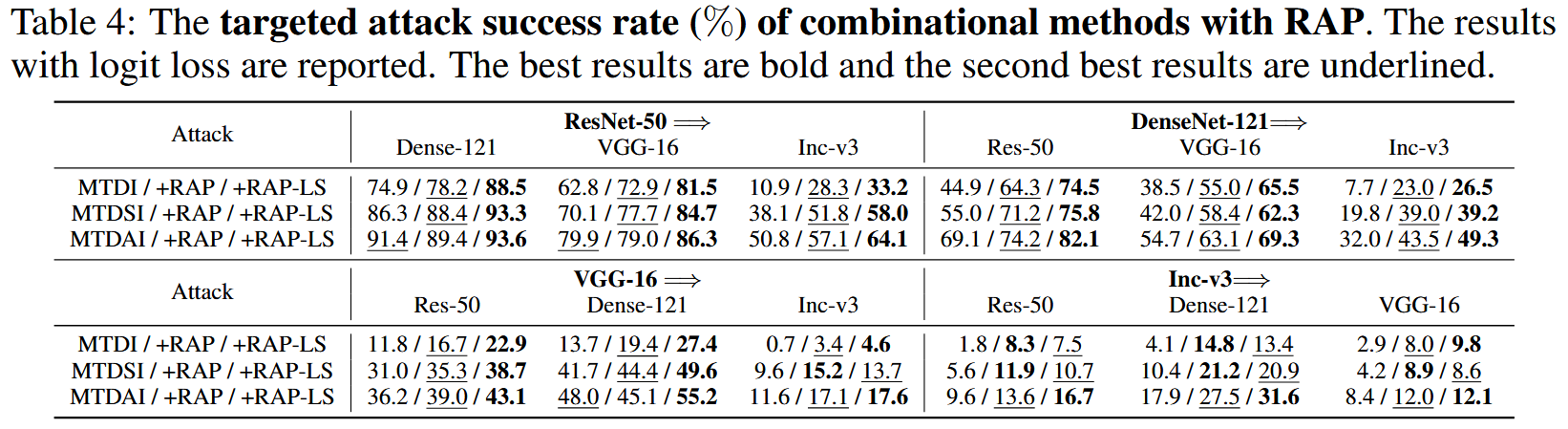
目标性攻击评估:RAP在目标性攻击中同样有效提升迁移性,对不同基线方法的平均性能提升在4.6%-18.5%之间,RAP-LS能进一步提高多数攻击的迁移性,其平均攻击成功率比RAP高2.6%。组合攻击方法中,RAP-LS表现最优,相比其他组合方法有显著提升。
表3:采用RAP的基线方法的目标性攻击成功率(%)。报告的是使用logit损失的结果。最佳结果用粗体显示,第二好的结果用下划线标注。
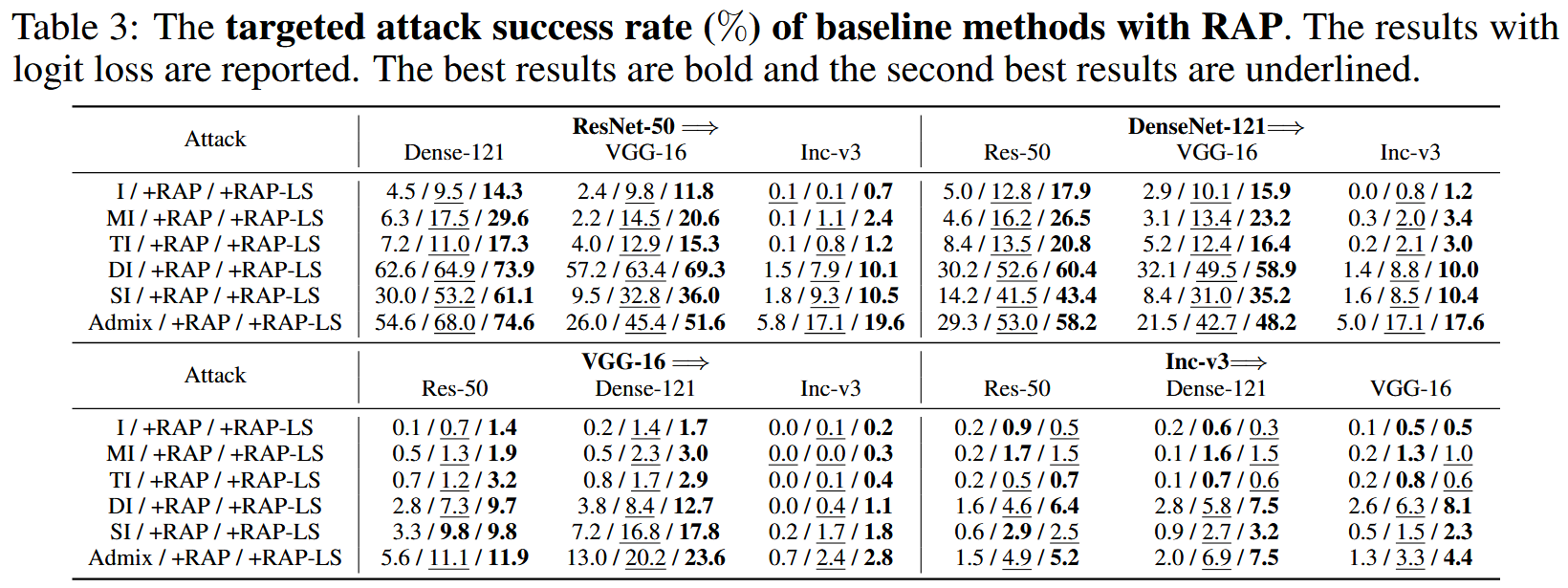
表4:结合RAP的组合攻击方法的目标性攻击成功率(%)。报告的是使用logit损失的结果。最佳结果用粗体显示,第二好的结果用下划线标注。
-
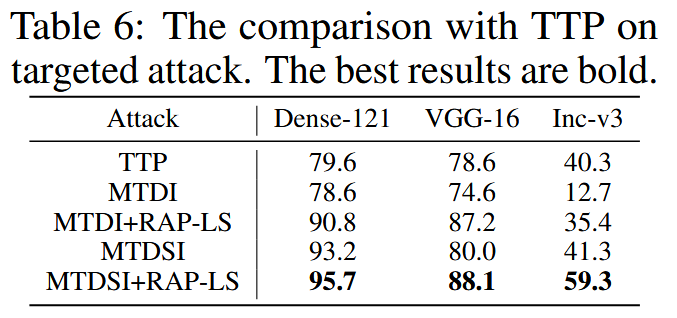
与其他类型攻击比较:与模型特定攻击LinBP、特征攻击ILA和生成目标攻击TTP相比,MI-DI+RAP在目标性攻击上表现更优,相比第二好的方法平均攻击成功率提升33.5%;MTDSI+RAP-LS在与TTP的对比中表现最佳,比TTP和MTDI分别高出14.9%和25.7% 。
表5:与ILA和LinBP的对比。我们使用ResNet-50作为代理模型( M S M^{S} MS )。最佳结果以粗体显示。
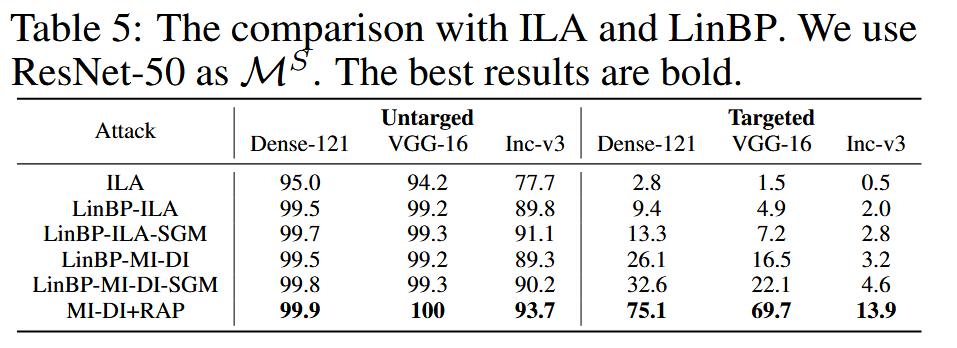
表6:与TTP在目标攻击上的对比。最佳结果用粗体显示。
-
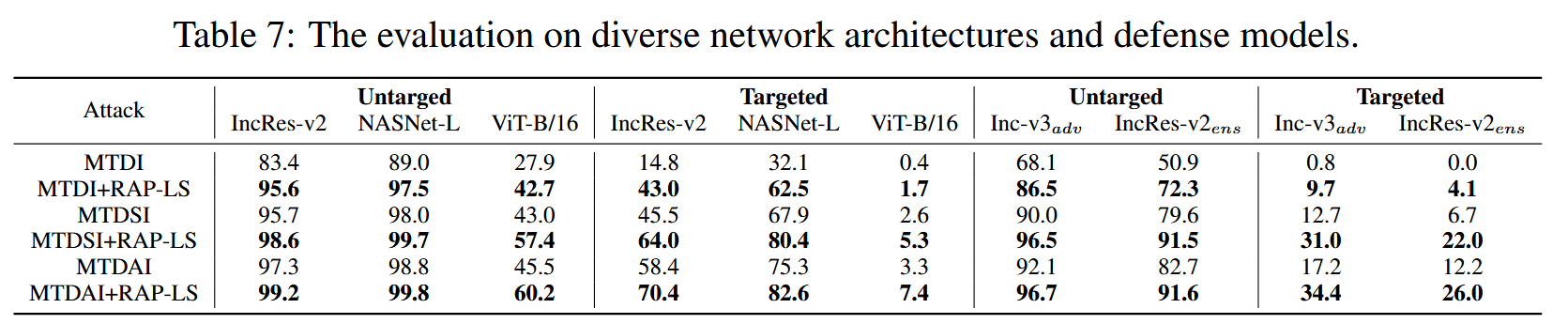
在不同网络架构和防御模型上的评估:在Inception-ResNet-v2等多种网络架构上,RAP-LS显著提升了组合攻击方法的性能,对不同攻击类型的平均性能提升在5.9%-7.8%之间,在基于Transformer架构的ViT-Base/16上也有一致的提升效果。在攻击防御模型时,RAP-LS进一步提升了基线方法在目标性和非目标性攻击上的迁移性,对不同防御模型的平均性能提升在9.8%-14.8%之间。
表7:在多种网络架构和防御模型上的评估。
-
-
消融研究:对RAP的超参数 ϵ n \epsilon_{n} ϵn 、 T T T 和 K L S K_{LS} KLS 进行消融研究。结果表明,对于固定的 ϵ n \epsilon_{n} ϵn ,更多的迭代次数 T T T攻击性能更好,较大的 ϵ n \epsilon_{n} ϵn 通常能提升攻击性能,在大多数情况下, ϵ n \epsilon_{n} ϵn 取12或16能得到满意结果;晚启动策略RAP-LS在大多数情况下能进一步提升RAP的攻击性能, K L S K_{LS} KLS 在100左右时性能提升效果较好。
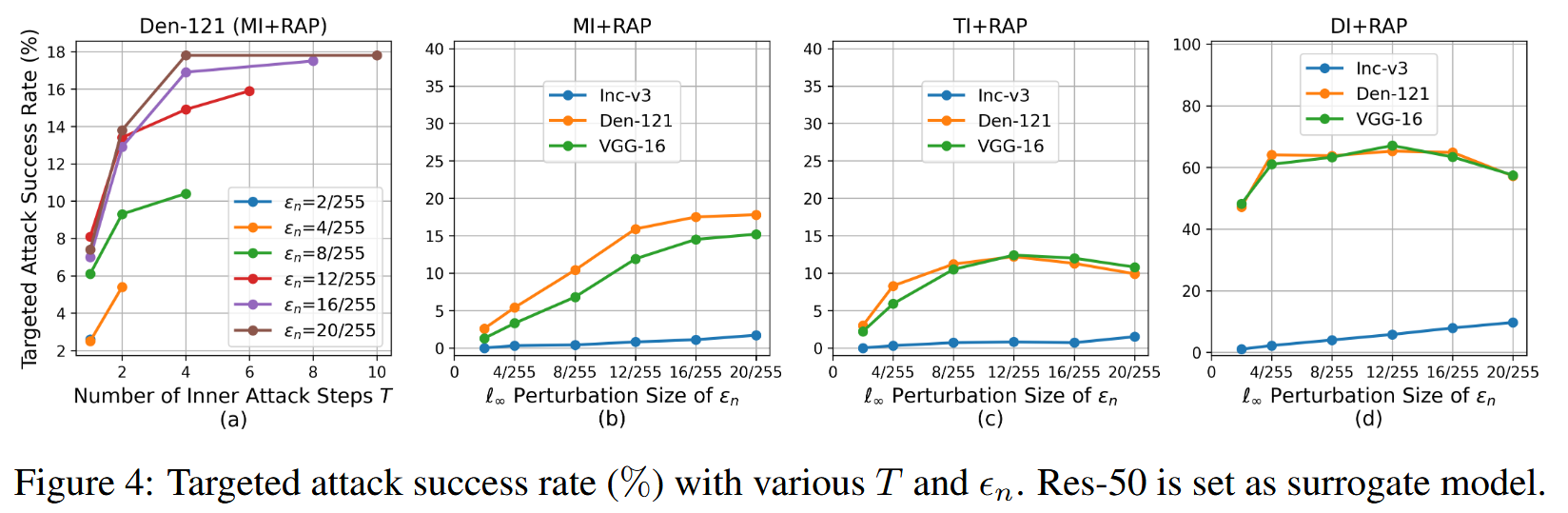
图4:以Res-50为代理模型,不同 T$ $ 和 ϵ n \epsilon_{n} ϵn 取值下的目标攻击成功率(%)。
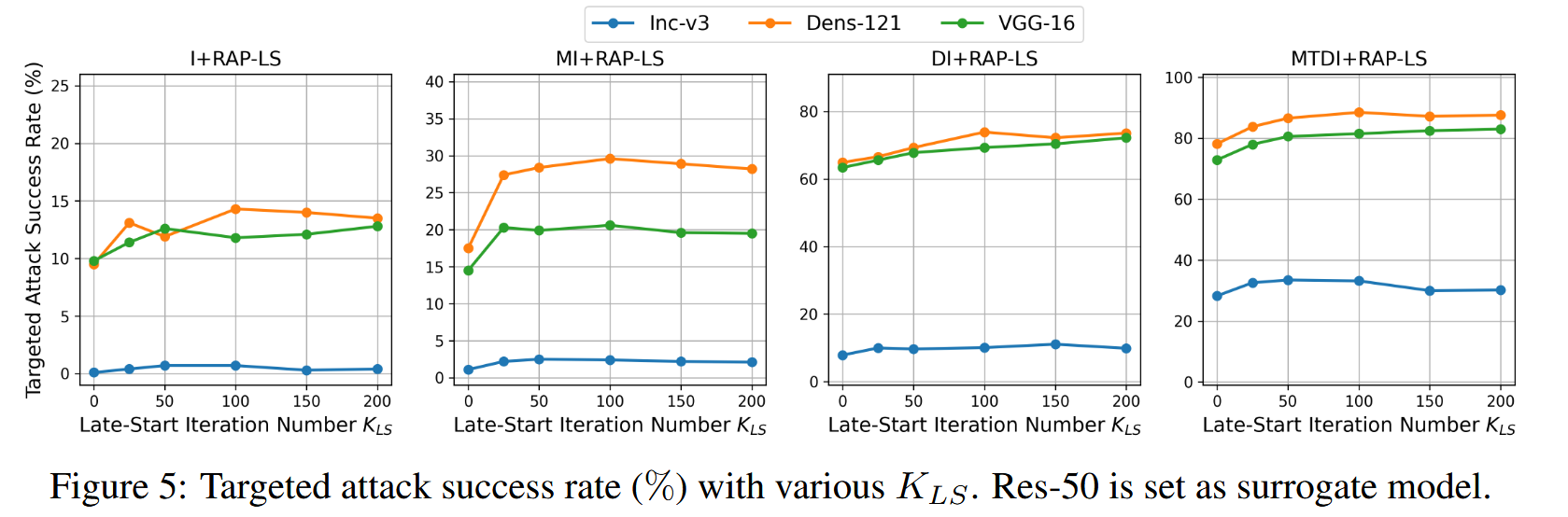
图5:以Res-50为代理模型,不同 K L S K_{LS} KLS 取值下的目标攻击成功率(%)。 -
针对Google Cloud Vision API的目标攻击:使用MTDAI-RAP-LS攻击Google Cloud Vision API,相比基线MTDAI,成功攻击的图像数量从232张提升到342张,性能提升22.0%,证明了该方法在实际系统中提升迁移性的高效性。
结论-Conclusion
本文围绕对抗样本迁移性展开研究,提出反向对抗扰动(RAP)方法,实验验证其有效性,同时指出迁移攻击的威胁及防御的必要性。具体内容如下:
- 研究问题聚焦:着重研究对抗样本的迁移性,该特性在黑盒攻击场景中意义重大,因为它直接影响攻击者能否利用在代理模型上生成的对抗样本成功攻击未知的目标模型。
- 方法提出及原理:针对对抗样本易过拟合代理模型进而降低迁移性的问题,提出RAP方法。该方法通过寻找位于更平坦局部区域的对抗样本,优化邻域区域的损失,将其构建为极小极大双层优化问题,在优化过程中注入最坏情况的扰动。
- 实验验证结果:经过大量严谨的实验,涵盖非目标性攻击和目标性攻击、标准模型和防御模型,以及对真实世界的Google Cloud Vision API的攻击测试。结果表明,RAP能够显著提升对抗样本的迁移性,有力地证明了该方法的有效性。
- 未来研究方向:RAP的有效性揭示了迁移攻击已成为严重威胁,这迫切需要研究人员思考并探索如何有效地防御此类攻击,为后续的研究工作指明了方向。


















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











