






Introducing Competition to Boost the Transferability of Targeted Adversarial Examples through Clean Feature Mixup
本文 “Introducing Competition to Boost the Transferability of Targeted Adversarial Examples through Clean Feature Mixup” 提出通过引入竞争机制和干净特征混合(CFM)方法,提升目标对抗样本的可迁移性,在多个数据集和模型上进行实验,证明了该方法的有效性和高效性。
摘要-Abstract
Deep neural networks are widely known to be susceptible to adversarial examples, which can cause incorrect predictions through subtle input modifications. These adversarial examples tend to be transferable between models, but targeted attacks still have lower attack success rates due to significant variations in decision boundaries. To enhance the transferability of targeted adversarial examples, we propose introducing competition into the optimization process. Our idea is to craft adversarial perturbations in the presence of two new types of competitor noises: adversarial perturbations towards different target classes and friendly perturbations towards the correct class. With these competitors, even if an adversarial example deceives a network to extract specific features leading to the target class, this disturbance can be suppressed by other competitors. Therefore, within this competition, adversarial examples should take different attack strategies by leveraging more diverse features to overwhelm their interference, leading to improving their transferability to different models. Considering the computational complexity, we efficiently simulate various interference from these two types of competitors in feature space by randomly mixing up stored clean features in the model inference and named this method Clean Feature Mixup (CFM). Our extensive experimental results on the ImageNet-Compatible and CIFAR-10 datasets show that the proposed method outperforms the existing baselines with a clear margin.
众所周知,深度神经网络容易受到对抗样本的影响,这些对抗样本可以通过对输入进行细微修改来导致错误的预测。这些对抗样本往往在不同模型之间具有可迁移性,但由于决策边界存在显著差异,有针对性的攻击仍然具有较低的攻击成功率。为了提高有针对性的对抗样本的可迁移性,我们提出在优化过程中引入竞争机制。我们的思路是在存在两种新型竞争噪声的情况下生成对抗扰动:针对不同目标类别的对抗扰动和针对正确类别的友好扰动。有了这些竞争因素,即使一个对抗样本欺骗网络提取出导致目标类别的特定特征,这种干扰也可以被其他竞争因素抑制。因此,在这种竞争环境中,对抗样本应该采用不同的攻击策略,利用更多样化的特征来克服干扰,从而提高它们对不同模型的可迁移性。考虑到计算复杂度,我们通过在模型推理过程中随机混合存储的干净特征,在特征空间中有效地模拟这两种竞争因素带来的各种干扰,并将这种方法命名为干净特征混合(CFM)。我们在ImageNet-Compatible和CIFAR-10数据集上进行的大量实验结果表明,所提出的方法明显优于现有的基线方法。我们的代码可在https://github.com/dreamflake/CFM获取。
引言-Introduction
这部分内容主要介绍了研究背景、目的和创新点,具体如下:
- 研究背景:深度神经网络在图像分类和目标检测等任务中表现出色,但容易受到对抗样本的攻击。对抗样本通过优化难以察觉的扰动,误导模型做出错误预测,且具有跨模型迁移性。不过,由于不同模型决策边界差异大,有特定目标类别的针对性对抗攻击成功率较低。但针对性攻击能诱导模型预测特定有害目标类别,潜在风险大。因此,研究新的基于迁移的攻击方法,对服务提供商评估模型鲁棒性、防范风险至关重要。
- 研究目的:文章旨在通过在目标对抗样本的优化过程中引入竞争机制,进一步提升其可迁移性。具体做法是在生成对抗扰动时,引入两种新噪声:针对不同目标类别的对抗扰动和针对正确类别的友好扰动。在这些竞争噪声影响下,为成功攻击,对抗扰动需要利用更多样化的特征,采用不同攻击策略,以此增强对不同模型的可迁移性。
- 创新点:提出Clean Feature Mixup(CFM)方法,在特征空间中通过随机混合存储的干净图像特征,高效模拟上述两种竞争噪声的干扰。该方法为卷积层和全连接层添加CFM模块,在推理时混合干净特征和输入特征,防止对抗样本在攻击源模型时过度聚焦特定特征,降低过拟合风险。而且,CFM计算成本低,仅增加一次前向传递用于存储干净特征,每次推理时特征混合的计算量也很小 。
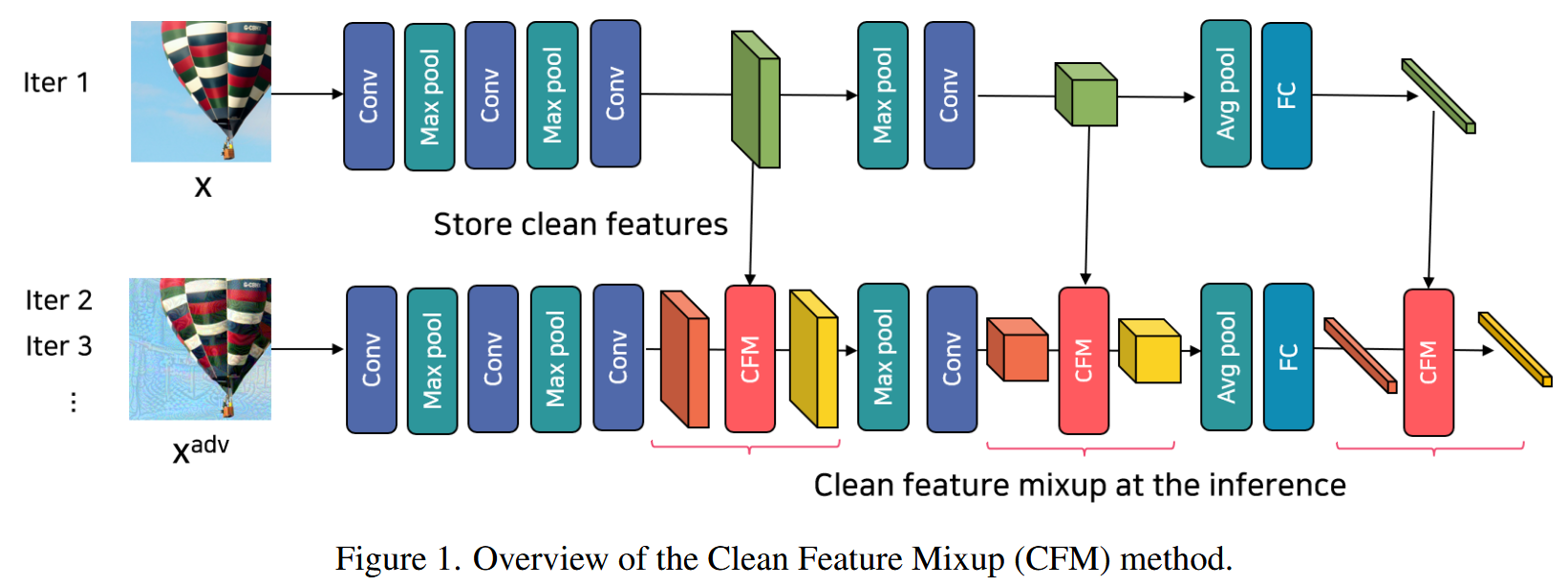
图1. 干净特征混合(CFM)方法概述。
背景-Background
这部分主要介绍了对抗攻击、基于迁移的黑盒攻击以及防御模型的相关背景知识,具体内容如下:
- 对抗攻击:给定干净图像 x x x、真实标签 y y y 和源模型 f f f,对抗攻击通过添加不可察觉的噪声 δ \delta δ 生成对抗样本 x a d v = x + δ x^{adv}=x+\delta xadv=x+δ,使模型预测错误。通常使用 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束对抗扰动,在白盒设置下,可利用损失函数(如交叉熵损失)关于输入图像的梯度来优化针对给定目标类 y t y_{t} yt 的 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束的目标对抗样本,基本攻击方法有FGSM,还可通过Iterative-FGSM以更小步长迭代更新图像进行优化。
- 基于迁移的黑盒攻击:在黑盒设置下,无法直接获取目标模型内部信息和计算图像梯度,攻击者需在白盒替代源模型上生成对抗样本,再对目标模型进行攻击。但源模型与目标模型的差异会影响对抗样本的迁移成功率,为提高迁移性,已提出多种技术 。包括输入多样化,如DI、RDI、TI、Admix、ODI方法;稳定图像梯度,如MI-FGSM、VT、SI攻击方法;使用不同损失函数,如用简单logit损失增加目标类的logit值。
- 防御模型:为抵御基于迁移的黑盒攻击,研究人员提出了多种方法。如对抗训练,直接利用对抗样本训练模型;构建集成模型,通过训练集成模型并添加正则化项考虑个体网络间的相互作用,提升模型鲁棒性,像ADP、GAL、DVERGE等正则化技术,分别从增强非最大预测多样性、使损失梯度不对齐、让子模型利用不同特征集合等方面,增加对抗样本在模型间迁移的难度。
干净特征混合-Clean Feature Mixup (CFM)
这部分主要介绍了Clean Feature Mixup(CFM)方法,该方法旨在通过在优化过程中模拟两种竞争噪声,增强目标对抗样本的可迁移性。具体内容如下:
- 方法概述:CFM通过变换特征图,防止对抗样本过度拟合源模型。在特征空间中,它随机混合干净特征和输入特征,而非直接对特征图应用传统图像变换,以避免因图像和特征域差异过大阻碍优化。在卷积层和全连接层,通过线性插值将层输出(即特征)与存储的干净特征进行混合。
- CFM模块的功能实现
- 存储干净特征:将预训练的源模型 f f f 转换为附加CFM模块的模型 f ′ f' f′,把干净图像 x x x 输入 f ′ f' f′,CFM模块在首次推理时存储干净特征。为避免干扰优化过程,CFM模块仅添加到输出尺寸远小于输入图像的深层(输出空间尺寸小于等于原始输入尺寸的 1 16 \frac{1}{16} 161,通常在经过两个池化层后),并且存储预激活特征用于特征混合。
- 混合存储的干净特征与输入特征:CFM模块在推理时,其内部过程包含随机激活、随机特征打乱和随机通道混合比三个操作。
随机激活指每个CFM模块以概率 p p p 随机应用干净特征混合,避免在所有层同时混合对推理过程造成过度干扰,且能在不同层数下保持稳定性能提升,减少超参数调整工作量。
随机特征打乱是在一个批次内按图像维度随机打乱存储的干净特征,这样可以选择将图像自身或其他图像的干净特征进行混合,实现不同类型竞争噪声的效果。
随机通道混合比是指每个CFM模块通过线性插值混合存储的干净特征和输入特征时,为每个通道随机采样混合比例,使竞争噪声的影响在不同通道间变化,增加干扰的多样性。
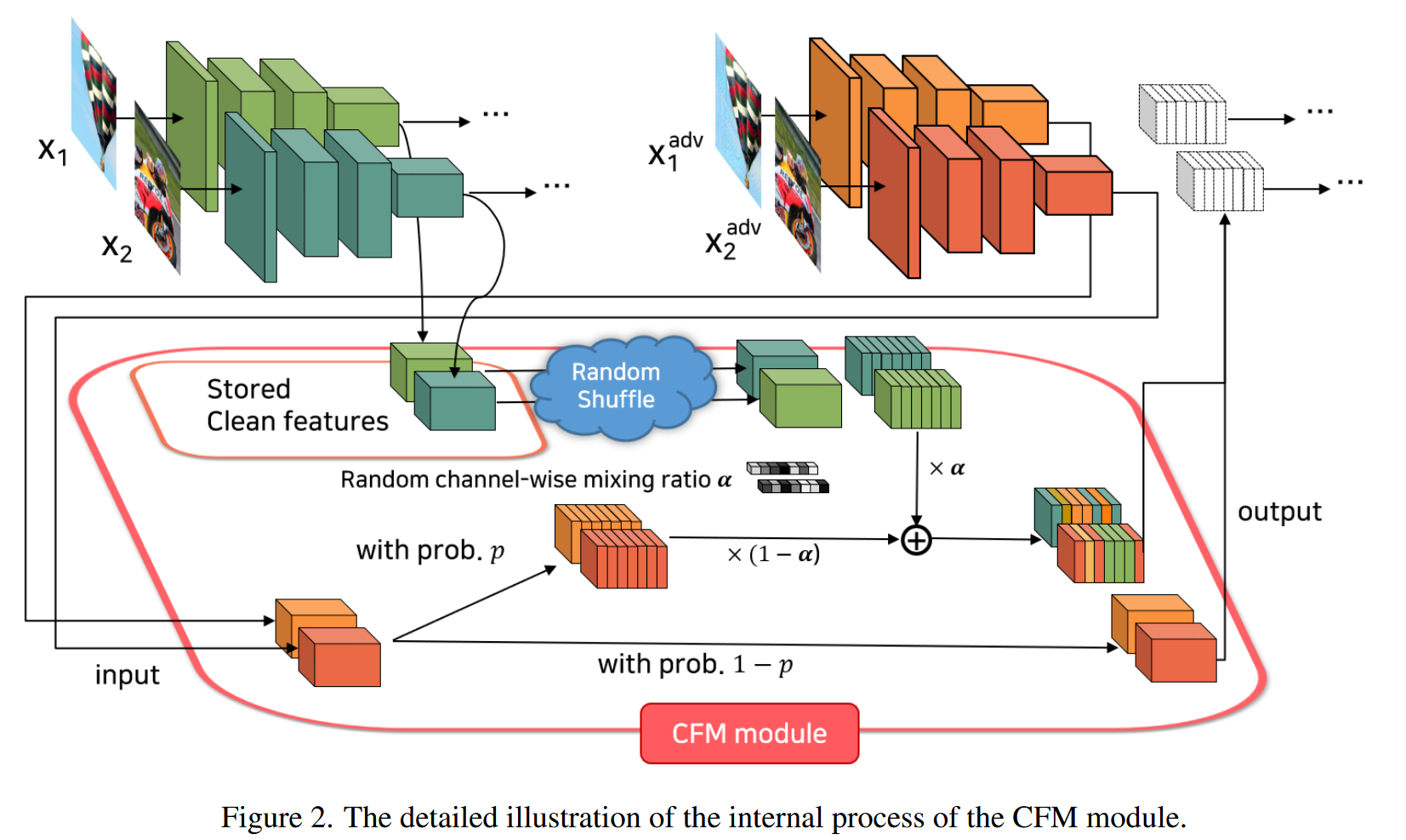
图2. CFM模块内部过程的详细示意图。
- CFM提升目标对抗样本可迁移性的原理:当混合图像自身的干净特征时,能抑制当前目标对抗扰动对特征的干扰,引导模型预测回到真实类别,促使对抗扰动探索其他特征干扰方式以成功攻击。
当混合其他图像的干净特征时,引入了对不同目标类别的攻击效果,使对抗样本在存在其他不同类别目标攻击的情况下,仍能优化诱导模型预测给定目标类别,从而探索更具鲁棒性的对抗特征干扰。总之,干净特征混合的干扰能有效减轻对抗样本优化过程中的过拟合问题,且CFM方法可与多种现有攻击方法兼容。
实验-Experiments
这部分主要介绍了实验设置、实验结果和消融研究,验证了CFM方法的有效性,具体内容如下:
- 实验设置
- 数据集:使用ImageNet-Compatible数据集(用于NIPS 2017对抗攻击挑战,含1000张299×299尺寸图像,有真实和目标类别)和CIFAR10数据集(从测试集中随机采样1000张图像,对随机选择的错误目标类别进行攻击)。
- 通用设置:多数设置参考已有研究,采用 ℓ ∞ \ell_{\infty} ℓ∞ 范数扰动约束( ϵ = 16 / 255 \epsilon = 16 / 255 ϵ=16/255 )和步长 η = 2 / 255 \eta = 2 / 255 η=2/255 进行迭代攻击,基于简单logit损失优化对抗样本,总迭代次数 T T T 设为300。
- 源模型和目标模型:选用10个预训练神经网络(如VGG-16、ResNet18等)、1个对抗训练的RN-50网络和5个Transformer - 基于的分类器作为目标网络;CIFAR10数据集实验中,使用由三个ResNet-20网络组成的不同集成模型,这些模型在四种防御设置下训练。
- 基线攻击:结合DI、RDI等8种现有技术构建基线攻击,多数情况选择RDI作为常见基线技术,并详细设置各技术参数。
- CFM方法设置:通道混合比 α \alpha α 从 U ( 0 , 0.75 ) U(0, 0.75) U(0,0.75) 随机采样,ImageNet和CIFAR10数据集的混合概率 p p p 分别设为0.1和0.25。考虑到CFM存储干净特征需一次推理,为公平比较,将可用剩余迭代次数减为299。
- 实验结果
- ImageNet-Compatible数据集实验:以预训练的RN-50和Inc-v3为源模型,对10个目标模型进行攻击,CFM在所有源模型下的攻击成功率均显著优于基线方法。在攻击对抗训练模型和5个Transformer - 基于的模型时,CFM同样表现出色,且其生成的对抗样本平均攻击成功率更高,达到饱和所需的迭代次数更多。
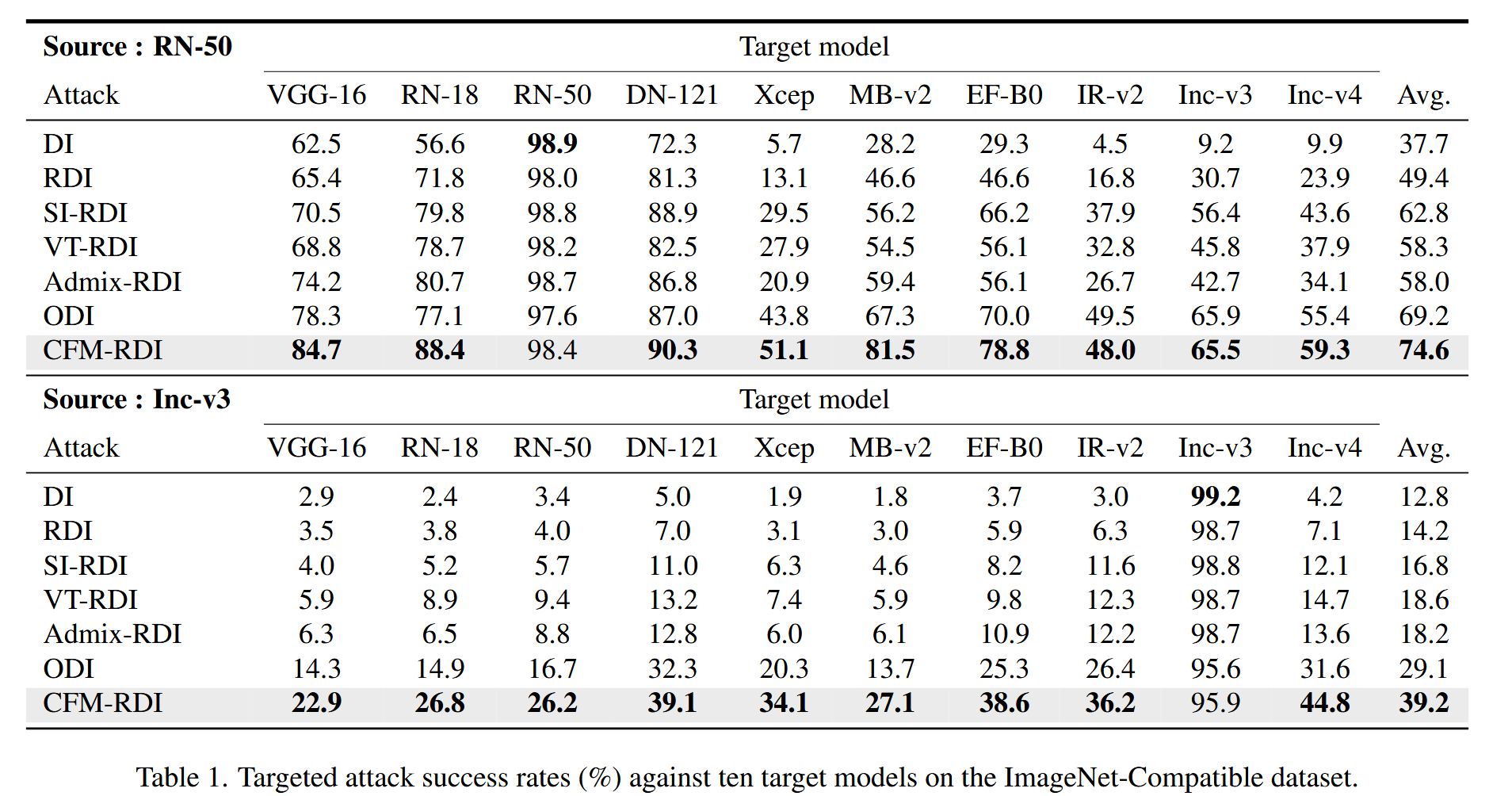
表1. 在ImageNet-Compatible数据集上针对十个目标模型的目标攻击成功率(%).
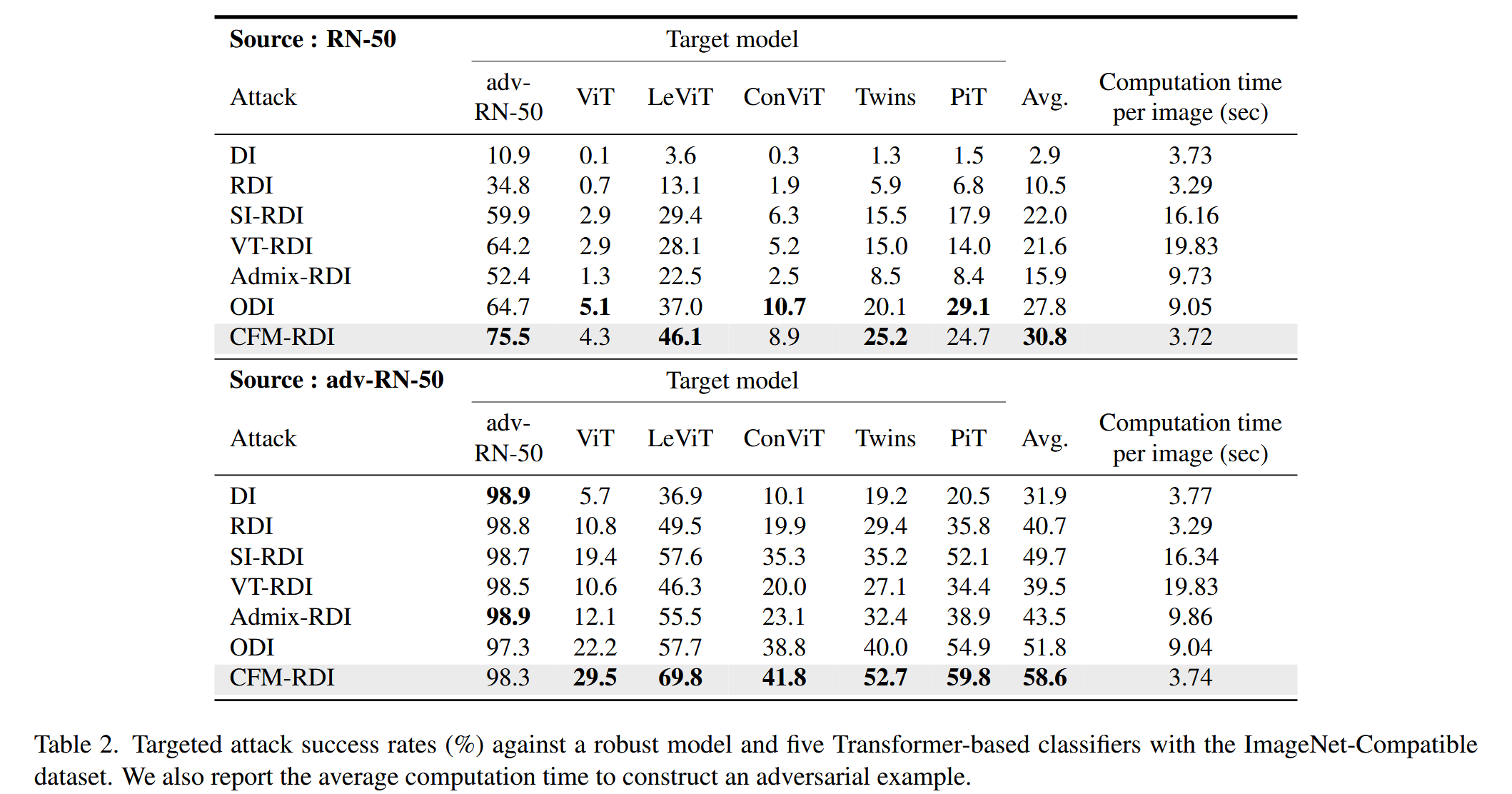
表2. 在ImageNet-Compatible数据集上,针对一个鲁棒模型和五个基于Transformer的分类器的目标攻击成功率(%)。我们还报告了构建一个对抗样本的平均计算时间.
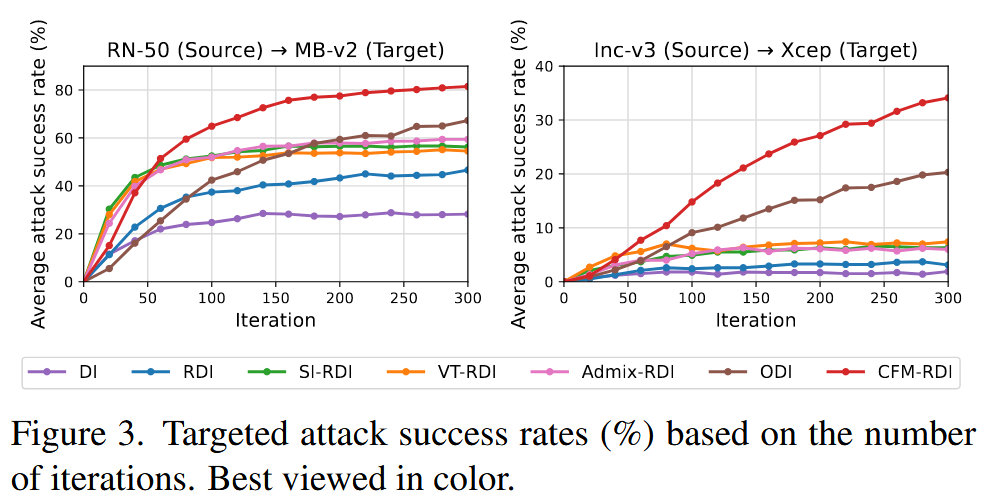
图3. 基于迭代次数的目标攻击成功率(%)。彩色查看效果更佳. - CIFAR10数据集实验:对CIFAR10数据集上的4种集成模型进行基于迁移的目标攻击,CFM显著提升了攻击成功率,例如将针对DVERGE模型的攻击成功率从14.9%提升到59.3%,平均攻击成功率达到89.3%。
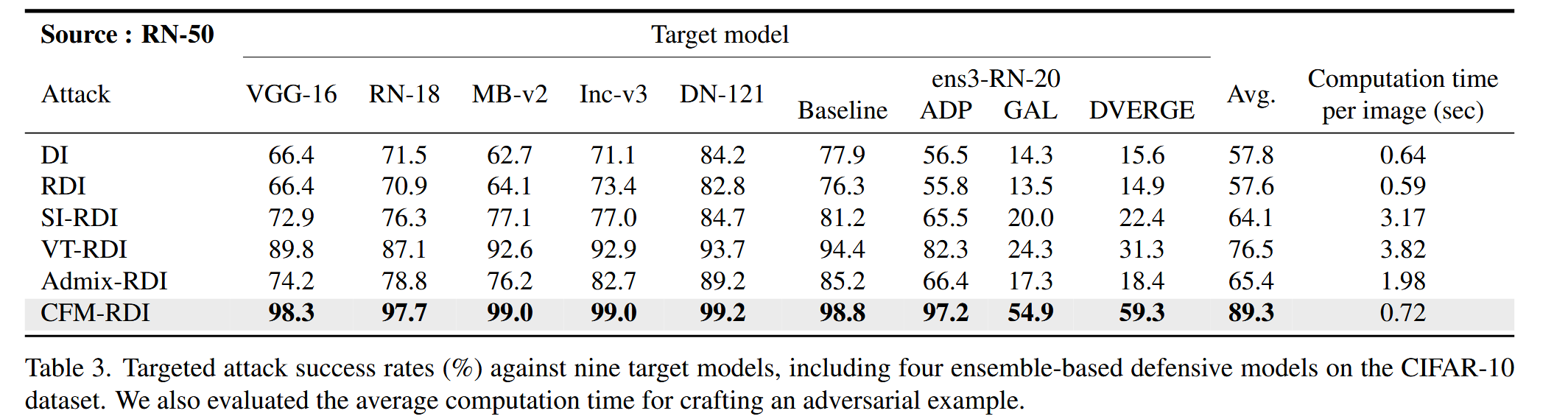
表3. 在CIFAR-10数据集上针对9个目标模型的目标攻击成功率(%),其中包括4个基于集成的防御模型。我们还评估了生成一个对抗样本的平均计算时间. - 计算成本:CFM模块增加的计算量较小,CFM-RDI相比其他基线方法,生成对抗样本的平均计算时间增加较少(见表2和3)。
- 与现有技术结合:CFM可与现有攻击技术兼容,如与Admix、SI和VT结合,能进一步提升攻击性能。
- ImageNet-Compatible数据集实验:以预训练的RN-50和Inc-v3为源模型,对10个目标模型进行攻击,CFM在所有源模型下的攻击成功率均显著优于基线方法。在攻击对抗训练模型和5个Transformer - 基于的模型时,CFM同样表现出色,且其生成的对抗样本平均攻击成功率更高,达到饱和所需的迭代次数更多。
- 消融研究
- 超参数影响:研究混合概率 p p p 和混合比上限 α m a x \alpha_{max} αmax 对迁移成功率的影响,发现CFM在 p = 0.1 p = 0.1 p=0.1 和 α m a x = 0.75 \alpha_{max} = 0.75 αmax=0.75 时成功率最高,但在其他值时也能取得较好效果,说明CFM对超参数变化不敏感。
- 模块内部函数影响:对CFM模块的三个内部函数进行消融实验,结果表明每个内部函数都有助于提高对抗样本的可迁移性。混合干净特征(即使不打乱)相比在图像域混合不同图像的Admix方法,平均攻击成功率提升超过10%;不使用通道混合比或不混合干净特征会降低性能提升效果。
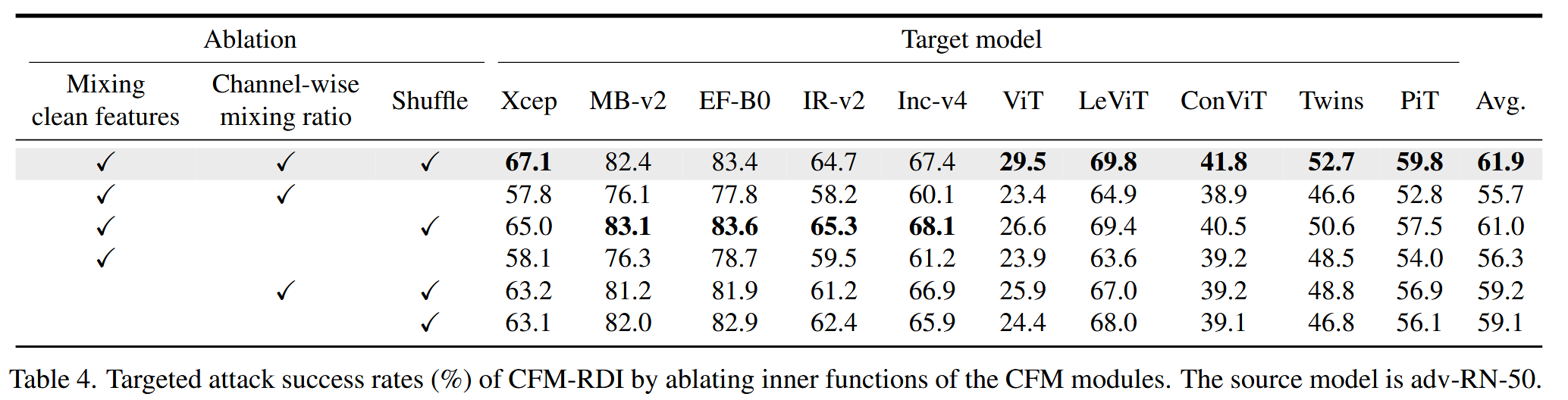
表4. 对CFM模块内部函数进行消融实验时,CFM-RDI的目标攻击成功率(%)。源模型为adv-RN-50. - 批量大小影响:评估不同批量大小对CFM-RDI的影响,发现批量大小为5、10、20和30时,平均成功率差异不显著。
结论-Conclusion
在这部分内容中,作者对研究工作进行全面总结,强调所提方法的核心要点、优势及实验验证成果,具体如下:
- 提出新方法及核心思想:文章提出一种提升目标对抗样本可迁移性的新方法,其核心是引入竞争机制。通过使用两种竞争噪声,鼓励在攻击过程中利用多样化特征,以此增强对抗样本在不同模型间的可迁移性。
- 开发CFM方法及优势:基于上述思想,开发了Clean Feature Mixup(CFM)方法。该方法在特征空间中通过随机混合批次图像的干净特征,高效模拟竞争噪声。CFM模块具有显著优势,无需额外反向传播,计算量极小,并且基于现成的模型转换,易于应用,还能与多种现有攻击方法兼容。
- 实验验证及结论:在ImageNet-Compatible和CIFAR-10数据集上开展大量实验,结果表明CFM在攻击成功率上远超现有基线方法。这充分证明了CFM方法的有效性和通用性,为对抗样本研究领域提供了更优的解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











