







Enhancing the Self-Universality for Transferable Targeted Attacks
本文 “Enhancing the Self-Universality for Transferable Targeted Attacks” 提出了一种基于自通用性(Self-Universality,SU)的可迁移目标性攻击方法,旨在无需辅助网络额外训练的情况下提升对抗扰动的可迁移性,增强深度学习模型在现实应用中的安全性
摘要-Abstract
In this paper, we propose a novel transfer-based targeted attack method that optimizes the adversarial perturbations without any extra training efforts for auxiliary networks on training data. Our new attack method is proposed based on the observation that highly universal adversarial perturbations tend to be more transferable for targeted attacks. Therefore, we propose to make the perturbation to be agnostic to different local regions within one image, which we called as self-universality. Instead of optimizing the perturbations on different images, optimizing on different regions to achieve self-universality can get rid of using extra data. Specifically, we introduce a feature similarity loss that encourages the learned perturbations to be universal by maximizing the feature similarity between adversarial perturbed global images and randomly cropped local regions. With the feature similarity loss, our method makes the features from adversarial perturbations to be more dominant than that of benign images, hence improving targeted transferability. We name the proposed attack method as Self-Universality (SU) attack. Extensive experiments demonstrate that SU can achieve high success rates for transfer-based targeted attacks. On ImageNet-compatible dataset, SU yields an improvement of 12% compared with existing state-of-the-art methods.
在本文中,我们提出了一种全新的基于迁移的目标性攻击方法,该方法无需在训练数据上对辅助网络进行额外训练,就能优化对抗扰动。我们提出这种新攻击方法的依据是,具有高度通用性的对抗扰动在目标性攻击中往往更具迁移性。因此,我们提议让扰动对同一图像内的不同局部区域具有无关性,我们将其称为自通用性。与在不同图像上优化扰动不同,在不同区域上进行优化以实现自通用性,这样可以避免使用额外数据。具体而言,我们引入了一种特征相似性损失,通过最大化对抗扰动后的全局图像与随机裁剪的局部区域之间的特征相似性,促使学习到的扰动具有通用性。借助这种特征相似性损失,我们的方法使对抗扰动产生的特征比良性图像的特征更具主导性,从而提高了目标迁移性。我们将所提出的攻击方法命名为自通用性(SU)攻击。大量实验表明,SU攻击在基于迁移的目标性攻击中能够取得较高的成功率。在与ImageNet兼容的数据集上,与现有的最先进方法相比,SU攻击的性能提升了12%.
引言-Introduction
这部分内容主要介绍了研究背景、存在问题以及本文的研究内容和贡献,具体如下:
- 研究背景:对抗样本具有可迁移性,即一个白盒模型上生成的对抗样本可用于欺骗其他黑盒模型,这为黑盒攻击提供便利的同时,也给深度学习模型在现实应用中的安全性带来了隐患,因此提升对抗样本可迁移性的研究受到广泛关注。
- 存在问题:相比非目标性攻击,基于迁移的目标性攻击更具挑战性,因为不同深度神经网络(DNN)从源图像到目标类别的梯度方向通常不同,使得为非目标性攻击设计的迁移方法在目标性攻击中效果不佳。以往研究通过对齐生成的对抗样本特征与目标类的特征分布来提升可迁移性,但这些方法需要辅助网络学习目标类特征分布,依赖训练数据集且需额外训练,在实际场景中应用困难。
- 本文研究内容:提出一种更高效的提升对抗样本可迁移性的方法,即无需为辅助网络进行训练来学习目标类的特征分布。基于观察到更通用的扰动在目标性攻击中成功率更高,该方法旨在增强对抗扰动的通用性,通过使扰动对图像内不同局部区域具有无关性(即自通用性),并引入特征相似性损失,最大化对抗扰动后的全局图像与随机裁剪的局部区域之间的特征相似性,进而提高对抗扰动的目标性迁移能力。
- 本文贡献:发现高度通用的对抗扰动在目标性攻击中往往更具迁移性,为基于迁移的目标性攻击方法设计提供了新视角;提出自通用性(SU)攻击方法,在无需额外数据的情况下增强对抗扰动的通用性,提升目标性迁移能力;通过综合实验验证了SU攻击能显著提高对抗图像的跨模型目标性迁移能力,且该方法可轻松与其他现有方法结合。
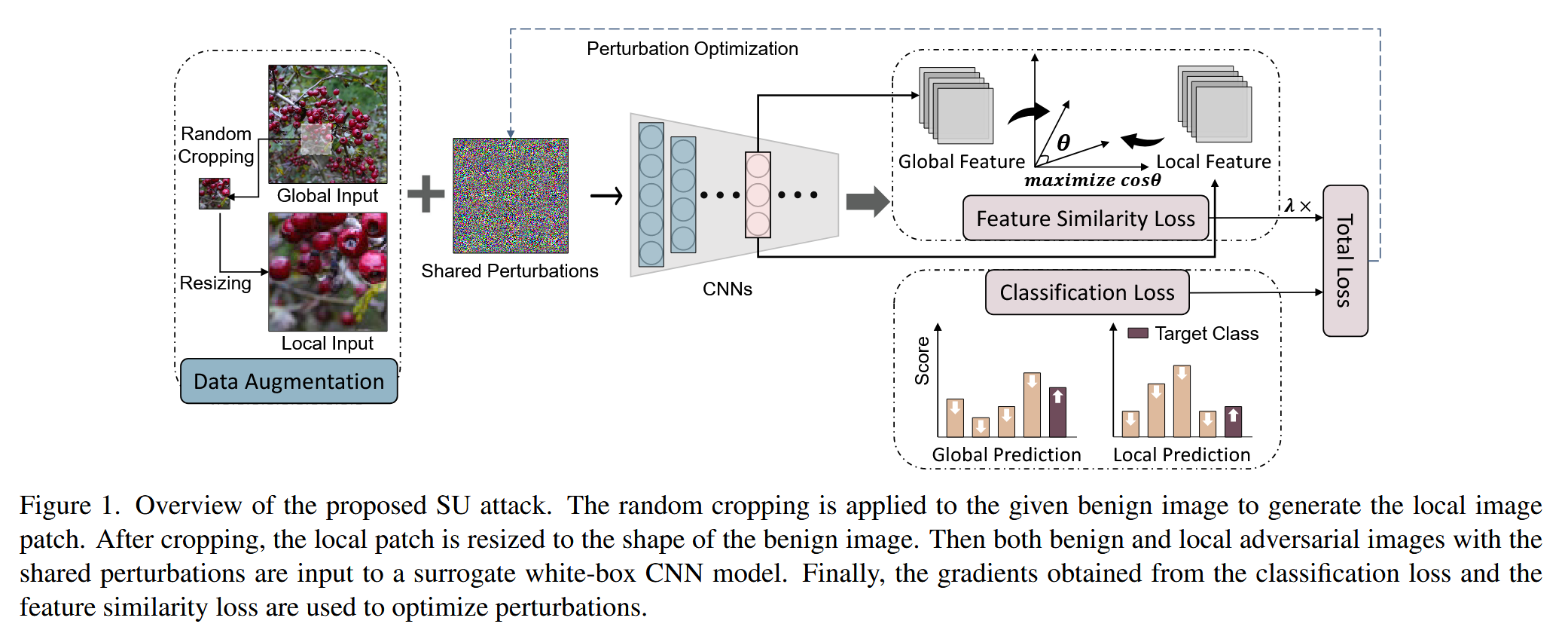
图1. 所提出的SU攻击概述。对给定的良性图像进行随机裁剪,生成局部图像块。裁剪后,将局部图像块调整为与良性图像相同的形状。然后,带有共享扰动的良性图像和局部对抗图像都被输入到一个代理白盒卷积神经网络(CNN)模型中。最后,利用从分类损失和特征相似性损失中获得的梯度来优化扰动。
相关工作-Related Work
这部分主要回顾了非目标性可迁移攻击和目标性可迁移攻击的现有工作,具体如下:
- 非目标性可迁移攻击:此类攻击基于迭代快速梯度符号法(I-FGSM),但该方法生成的对抗样本容易过拟合白盒模型,难以攻击其他黑盒模型。后续研究主要从数据增强和高级梯度计算两方面改进:
- 数据增强:通过创建各种输入模式生成通用对抗扰动,如 DI 进行随机缩放和填充、SIM 应用尺度变换、Admix 整合其他标签图像扩展SIM。然而,这些方法未充分考虑更多样化的输入模式,且侧重于保持损失的变换。
- 高级梯度计算:通过改变梯度计算方法或设计新损失函数来改进。如在梯度计算中引入动量项和Nesterov加速梯度稳定梯度;TI 通过预定义卷积核对梯度进行平滑;SGM 修改梯度反向传播路径;Variance Tuning 利用周围数据点的梯度避免过拟合。在新损失函数设计方面,ATA 和 FIA 分别通过不同方式破坏黑盒模型可能利用的重要特征,但这些新损失函数局限于全局结构,而本文计算图像全局和局部结构之间的特征相似性损失。
- 目标性可迁移攻击:这类攻击比非目标性攻击更具挑战性,因为需要使模型预测指定的目标类别。以往方法主要通过训练特定类别的辅助网络或生成对抗网络(GANs)学习目标类的特征分布:
- 基于辅助网络的方法:FDA 利用白盒模型训练数据集的中间特征训练二元分类器,以生成目标性可迁移的对抗扰动;FDA N ^{N} N+xent 在此基础上结合CE损失和多层信息,提升了性能。
- 基于GANs的方法:TTP 训练生成器在预训练判别器的潜在空间中合成与目标样本特征相似的扰动。
- 基于I-FGSM的迭代攻击方法:AA 用欧氏距离损失替代分类损失,但依赖目标类的选定示例,在大分辨率图像数据集上性能较低;Po+Trip 利用Poincaré距离度量解决噪声固化问题,并设计三元组损失使对抗样本远离原始类,但仅在简单迁移场景评估,在Logit攻击的目标场景中性能不佳;Logit 增加迭代次数并利用目标logit输出的梯度更新扰动,但本文方法通过利用全局和局部结构生成具有自通用性的对抗样本,提升目标性迁移能力,且可与现有方法轻松结合。
方法-Methodology
预备知识-Preliminary
这部分内容主要介绍了一些基础概念和相关攻击方法的公式,为后续研究做铺垫,具体内容如下:
- 符号定义:明确了研究中使用的关键符号。 f f f 代表白盒代理模型, v v v 表示黑盒受害模型; x ∈ X ⊂ R H × W × C x \in X \subset R^{H×W×C} x∈X⊂RH×W×C 是带有真实标签 y ∈ Y = { 1 , 2 , . . . , K } y \in Y = \{1, 2, ..., K\} y∈Y={1,2,...,K} 的良性图像,其中 H H H、 W W W、 C C C 分别为图像的高度、宽度和通道数, K K K 为类别数; f ( x ) f(x) f(x) 和 v ( x ) v(x) v(x) 是模型对图像 x x x 在类别集合 y y y 上的预测。给定指定目标类别 y t y_{t} yt,基于迁移的目标攻击旨在从白盒模型 f f f 生成对抗样本 x a d v x_{adv} xadv,使黑盒模型 v ( x a d v ) = y t v(x_{adv}) = y_{t} v(xadv)=yt ,同时对扰动 δ \delta δ 施加 L ∞ L_{\infty} L∞ 范数约束,即 ∥ x a d v − x ∥ ∞ = ∥ δ ∥ ∞ ≤ ϵ \left\|x_{adv} - x\right\|_{\infty} = \|\delta\|_{\infty} \leq \epsilon ∥xadv−x∥∞=∥δ∥∞≤ϵ , ϵ \epsilon ϵ 为范数约束常数。
- I-FGSM攻击公式:迭代快速梯度符号法(I-FGSM)是目标攻击的一种常见方法,其迭代过程通过以下公式描述:首先初始化 δ 0 = 0 \delta_{0}=0 δ0=0, g 0 = 0 g_{0}=0 g0=0;接着计算损失函数关于扰动的梯度 g i + 1 = ∇ δ J ( f ( x + δ i ) , y t ) g_{i + 1}=\nabla_{\delta}J(f(x+\delta_{i}), y_{t}) gi+1=∇δJ(f(x+δi),yt);然后根据梯度更新扰动 δ i + 1 = δ i − α ∗ s i g n ( g i + 1 ) \delta_{i + 1}=\delta_{i}-\alpha * sign(g_{i + 1}) δi+1=δi−α∗sign(gi+1) ,其中 α \alpha α 是步长;最后通过 δ i + 1 = C l i p x , ϵ ( δ i + 1 ) \delta_{i + 1}=Clip_{x, \epsilon}(\delta_{i + 1}) δi+1=Clipx,ϵ(δi+1) 将扰动限制在满足 L ∞ L_{\infty} L∞ 范数约束的范围内 。但I-FGSM容易陷入局部最优并过拟合白盒模型 f f f,导致在目标攻击中表现不佳。
- DTMI攻击公式:为获得更稳定的性能,以往工作将DI、TI和MI结合作为基线,简称为DTMI。DTMI对I-FGSM的梯度计算进行了改进,用公式 g i + 1 = μ ⋅ g i + W ⋅ ∇ δ J ( f ( T ( x + δ i , p ) ) , y t ) ∥ W ⋅ ∇ δ J ( f ( T ( x + δ i , p ) ) , y t ) ∥ 1 g_{i + 1}=\mu \cdot g_{i}+\frac{W \cdot \nabla_{\delta}J(f(T(x+\delta_{i}, p)), y_{t})}{\left\| W \cdot \nabla_{\delta}J(f(T(x+\delta_{i}, p)), y_{t})\right\| _{1}} gi+1=μ⋅gi+∥W⋅∇δJ(f(T(x+δi,p)),yt)∥1W⋅∇δJ(f(T(x+δi,p)),yt) 替代I-FGSM中的梯度计算式,其中 T ( x + δ i , p ) T(x+\delta_{i}, p) T(x+δi,p) 在DI中以概率 P P P 执行随机缩放和填充操作, W W W 是TI中的预定义卷积核, μ \mu μ 是MI中的衰减因子。
目标性扰动的通用性-Universality of Targeted Perturbations
这部分主要研究了目标扰动的通用性与目标可迁移性之间的关系,通过实验验证了二者存在正相关,具体内容如下:
- 通用性与可迁移性的关联分析:基于迁移的目标攻击需要生成能使不同模型都预测到指定目标类别的跨模型扰动,即扰动需具有模型无关性(通用性)。以往通过在大量模型上优化扰动来满足这一要求的方式在现实中不太可行。而有研究指出,目标通用对抗扰动(UAP)能使深度神经网络对几乎所有图像产生特定预测,原因是其产生的主导特征代表了目标类别的特征分布,可迁移攻击其他基于相同数据集训练的模型,这表明通用性与目标攻击中的可迁移性可能存在关联。
- 实验验证:为验证上述分析,作者以DenseNet121为白盒模型,在ImageNet兼容数据集上用I-FGSM和DTMI优化目标扰动,并以交叉熵(CE)损失作为分类损失。
- 通用性评估实验:给定一组良性图像,为其中每幅图像生成扰动。评估某一图像的扰动 δ m \delta^{m} δm 通用性时,将其添加到除该图像外的其他所有良性图像上,统计能成功使DenseNet121预测为目标类别的图像数量,数量越多表示 δ m \delta^{m} δm 的通用性越好。实验结果显示,DTMI生成的扰动比I-FGSM的通用性更高,且由于DTMI在目标可迁移性上表现更优,由此可初步推断通用性与目标可迁移性之间存在正相关。
- 特征相似性分析实验:对比添加特定目标扰动后,良性图像与对抗图像中间特征的平均余弦相似度。实验发现,添加扰动后图像特征变得更相似,说明目标扰动使不同良性图像的特征趋向于目标类别的特征分布,产生了更具主导性的特征。并且,DTMI生成的扰动使图像特征相似度更高,结合其更好的目标可迁移性,进一步表明具有高目标可迁移性的扰动会产生更主导的特征,具有更高的通用性。综上,实验表明在目标攻击中,具有高通用性的对抗样本往往更具可迁移性。
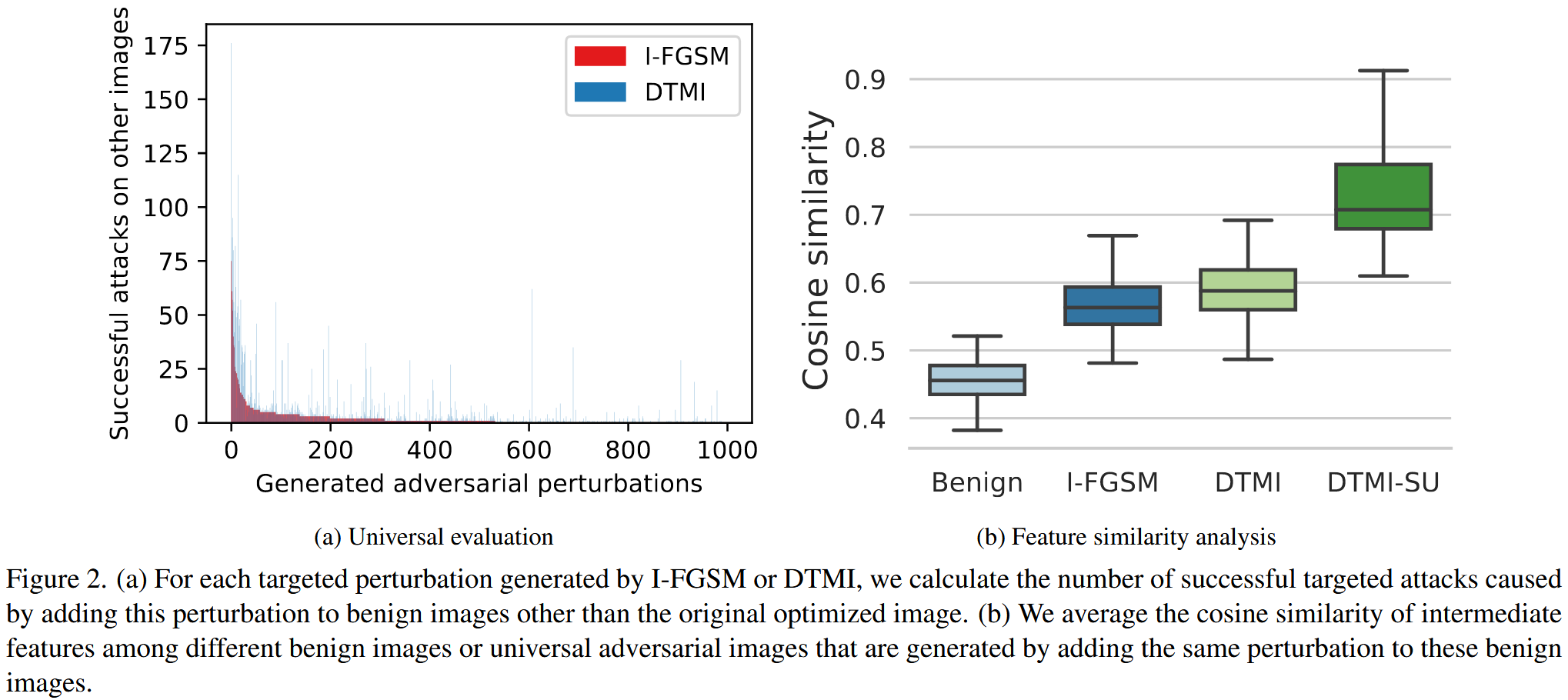
图2. (a) 对于由迭代快速梯度符号法(I-FGSM)或DTMI生成的每个目标扰动,我们计算将该扰动添加到除原始优化图像之外的良性图像上所引发的成功目标攻击的次数。(b) 我们对不同良性图像,或者是通过向这些良性图像添加相同扰动而生成的通用对抗图像之间的中间特征的余弦相似度求平均值。
自通用性攻击-Self-Universality (SU) Attack
这部分内容提出了自通用性(SU)攻击方法,旨在提升对抗扰动的通用性以增强可迁移目标攻击能力,具体如下:
- 方法核心思路:为增强对抗扰动的通用性,提出SU攻击方法。该方法不再通过在不同图像上优化扰动来实现通用性,而是优化扰动使其对同一图像内的不同局部区域无感知,即实现自通用性,进而在不使用额外数据的情况下生成通用扰动。
- 实现方式:通过将图像随机裁剪为局部图像块(裁剪操作由尺度参数 s = { s l , s i n t } s = \{s_{l}, s_{int }\} s={sl,sint} 控制, s l s_{l} sl 为随机裁剪图像面积下限, s i n t s_{int } sint 为上下限区间值 )并调整大小与原始良性图像一致,引入局部输入模式。同时,受前文实验中目标性扰动使图像特征更相似的启发,提出特征相似性损失,最大化对抗全局和局部输入之间中间特征的余弦相似度,以生成更具主导性特征的扰动。该损失可表示为 C S ( f l ( x + δ i ) , f l ( L o c ( x , s ) + δ i ) ) CS(f_{l}(x+\delta_{i}), f_{l}(Loc(x, s)+\delta_{i})) CS(fl(x+δi),fl(Loc(x,s)+δi)) ,其中 f l ( ⋅ ) f_{l}(\cdot) fl(⋅) 表示从白盒模型 f f f 的第 l l l 层提取特征, C S ( ⋅ , ⋅ ) CS(\cdot, \cdot) CS(⋅,⋅) 计算特征间的余弦相似度得分。
- 优化公式:SU攻击方法在迭代攻击过程中,将原有的梯度计算式替换为 g i + 1 = ∇ δ ( J ( f ( x + δ i ) , y t ) + J ( f ( L o c ( x , s ) + δ i ) , y t ) − λ ⋅ C S ( f l ( x + δ i ) , f l ( L o c ( x , s ) + δ i ) ) ) g_{i + 1}= \nabla_{\delta}(J(f(x+\delta_{i}), y_{t}) + J(f(Loc(x, s)+\delta_{i}), y_{t})-\lambda \cdot CS(f_{l}(x+\delta_{i}), f_{l}(Loc(x, s)+\delta_{i}))) gi+1=∇δ(J(f(x+δi),yt)+J(f(Loc(x,s)+δi),yt)−λ⋅CS(fl(x+δi),fl(Loc(x,s)+δi))) ,其中 λ \lambda λ 用于权衡分类损失和特征相似性损失的贡献。
- 集成算法:将SU与基线方法DTMI集成,形成DTMI-SU攻击算法。通过这种方式,SU能够结合局部图像生成具有高主导性特征的对抗扰动,提升目标可迁移性。

实验-Experiment
这部分主要介绍了实验设置、性能对比和消融研究的相关内容,通过实验验证了SU攻击方法的有效性,具体如下:
- 实验设置
- 数据集和模型:使用ImageNet兼容数据集,对ResNet50、DenseNet121、VGGNet16和Inception-v3四种不同的分类器架构进行攻击实验,这些模型架构差异大,增加了实验的挑战性。
- 攻击设置:采用目标攻击成功率(TASR)评估对黑盒模型的攻击效果,TASR指被黑盒模型成功分类为目标类别的对抗样本比例,TASR越高,说明生成的对抗样本目标迁移性越强。实验设置最大扰动
ϵ
=
16
\epsilon = 16
ϵ=16,步长
α
=
2
\alpha = 2
α=2,最大迭代次数
I
=
300
I = 300
I=300,并从每个模型的浅到深选择1/2/3/4层提取特征。
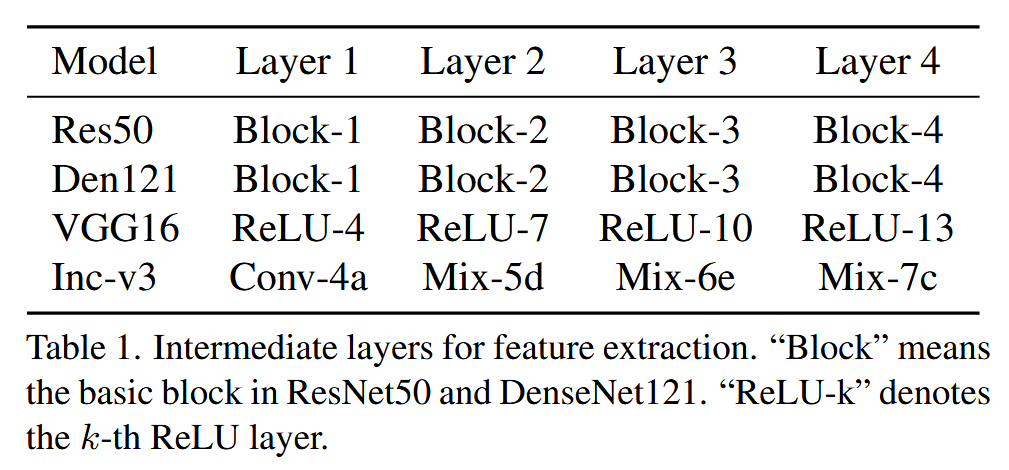
表1. 用于特征提取的中间层。“Block”指的是ResNet50和DenseNet121中的基本模块。“ReLU-k”表示第 k k k 个ReLU层。
- 性能对比
- 单模型迁移攻击:以DI、TI和MI的组合(DTMI)为基线,将SU方法与DTMI-CE和DTMI-Logit等基线方法结合进行对比。结果表明,SU方法在几乎所有情况下的TASR都显著高于基线方法,说明其适用于不同分类损失函数;使用ResNet50和DenseNet121作为白盒模型的攻击效果更好,这可能与它们的跳连接结构有关;SU在迭代次数较少时性能较差,但随着迭代次数增加,性能稳步提升,因为SU能解决CE损失导致的梯度消失问题。
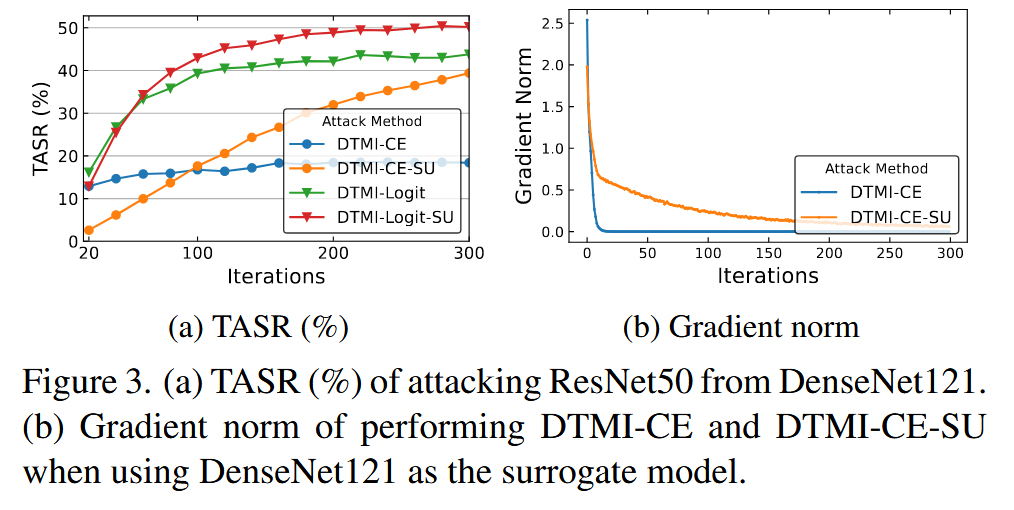
图3. (a) 以DenseNet121为白盒模型攻击ResNet50的目标攻击成功率(TASR,%)。(b) 以DenseNet121为代理模型时,执行DTMI-CE和DTMI-CE-SU攻击的梯度范数。
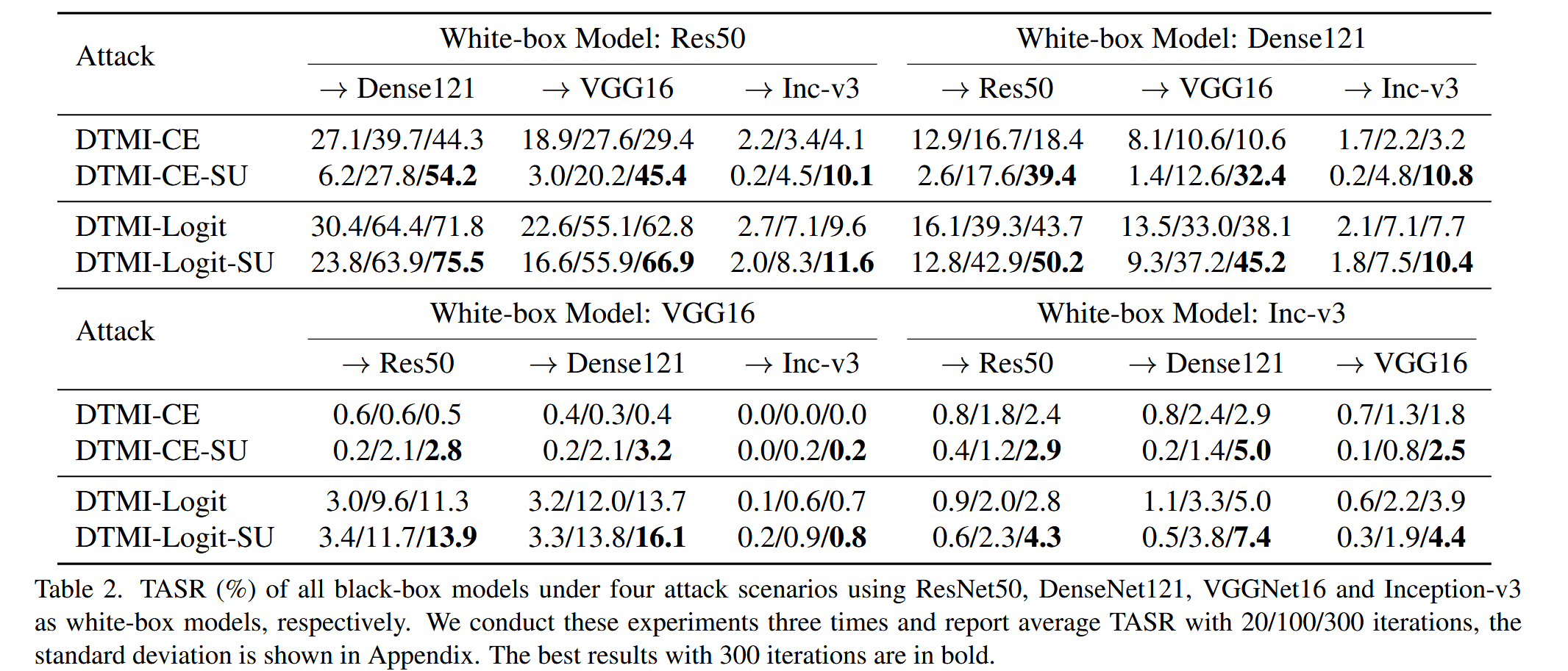
表2. 分别以ResNet50、DenseNet121、VGGNet16和Inception-v3作为白盒模型,在四种攻击场景下所有黑盒模型的目标攻击成功率(TASR,%)。我们进行了三次实验,并报告20次/100次/300次迭代的平均TASR,标准差见附录。300次迭代的最佳结果以粗体显示。 - 集成模型迁移攻击:选择一个黑盒模型作为攻击对象,用其他三个模型作为白盒模型进行集成攻击。结果显示,集成攻击比单模型迁移攻击性能更好,且SU进一步提升了跨模型目标迁移性。不过,DTMI-Logit-SU的TASR提升幅度相对较小,原因是Logit损失函数值可无限增大,而余弦相似度值有界,阻碍了特征相似性的最大化。但总体而言,与SU结合的方法在所有情况下都能促进目标迁移性。
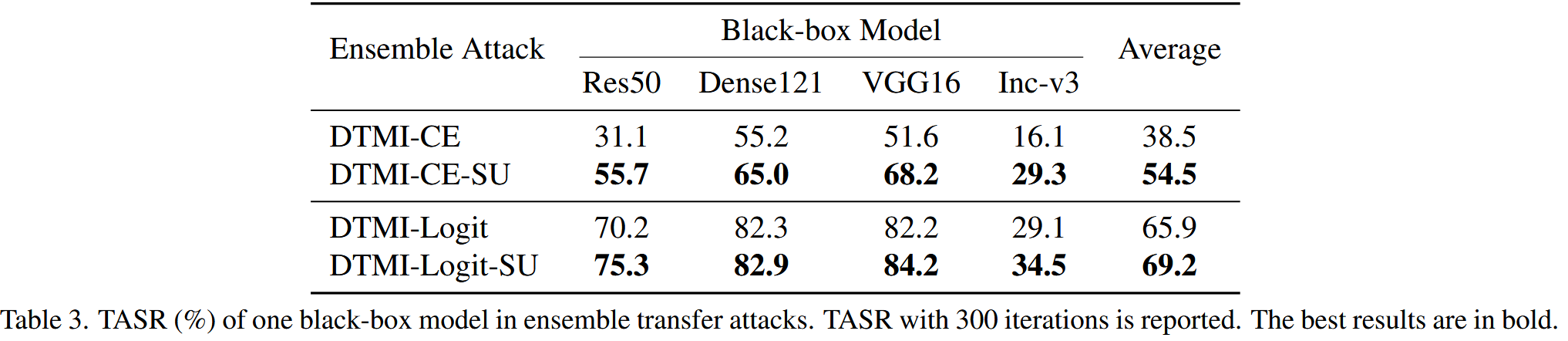
表3. 集成迁移攻击中一个黑盒模型的目标攻击成功率(TASR,%)。报告的是300次迭代的TASR。最佳结果以粗体显示。 - 与现有方法结合:将SU与SI、Admix、EMI和ODI等攻击方法结合,结果表明结合SU的攻击方法性能优于其他攻击方法,平均TASR增益可达6%。在计算效率方面,SU每次迭代仅需对全局和局部输入进行两次前向传播,低于SI、Admix和EMI(它们至少需要5次前向传播)。与ODI相比,DTMI-SU生成一个对抗样本所需的计算时间更短(DTMI-SU为2.3秒,DTMI-ODI为2.6秒)。
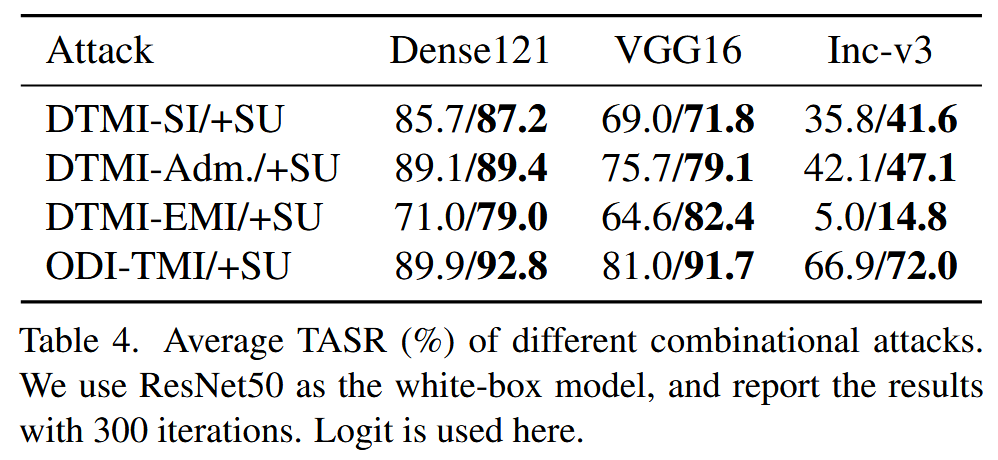
表4. 不同组合攻击的平均目标攻击成功率(TASR,%)。我们使用ResNet50作为白盒模型,并报告300次迭代的结果。此处使用的是Logit损失函数。
- 单模型迁移攻击:以DI、TI和MI的组合(DTMI)为基线,将SU方法与DTMI-CE和DTMI-Logit等基线方法结合进行对比。结果表明,SU方法在几乎所有情况下的TASR都显著高于基线方法,说明其适用于不同分类损失函数;使用ResNet50和DenseNet121作为白盒模型的攻击效果更好,这可能与它们的跳连接结构有关;SU在迭代次数较少时性能较差,但随着迭代次数增加,性能稳步提升,因为SU能解决CE损失导致的梯度消失问题。
- 消融研究
- 组件效果:以CE为分类损失,在四种攻击场景下评估SU中不同组件的作用。将SU拆分为局部输入和特征相似性损失两个部分,实验结果表明这两个组件都能提升目标迁移性,且特征相似性损失对TASR的提升更显著,验证了SU攻击中各组件的有效性。

表5. 我们提出的方法在不同组件组合下,黑盒模型的平均目标攻击成功率(TASR,%)。分类损失设置为交叉熵(CE)。“✓”表示使用了该组件,“-”表示未使用。TASR是在分别以ResNet50、DenseNet121、VGGNet16和Inception-v3作为白盒模型的四种攻击场景中取平均值得到的。 - 超参数影响:以DenseNet121为白盒模型,在黑盒模型上平均TASR进行评估。研究发现,随机裁剪图像的面积越小,SU性能越高,当
s
l
=
0.1
s_{l}=0.1
sl=0.1 且
s
i
n
t
=
0.1
s_{int}=0.1
sint=0.1 时达到最优结果,但为保持稳定性,后续实验采用
s
=
(
0.1
,
0.0
)
s = (0.1, 0.0)
s=(0.1,0.0);从第3层提取特征的效果优于其他层;加权参数
λ
=
1
0
−
3
\lambda = 10^{-3}
λ=10−3 时,SU性能最佳。
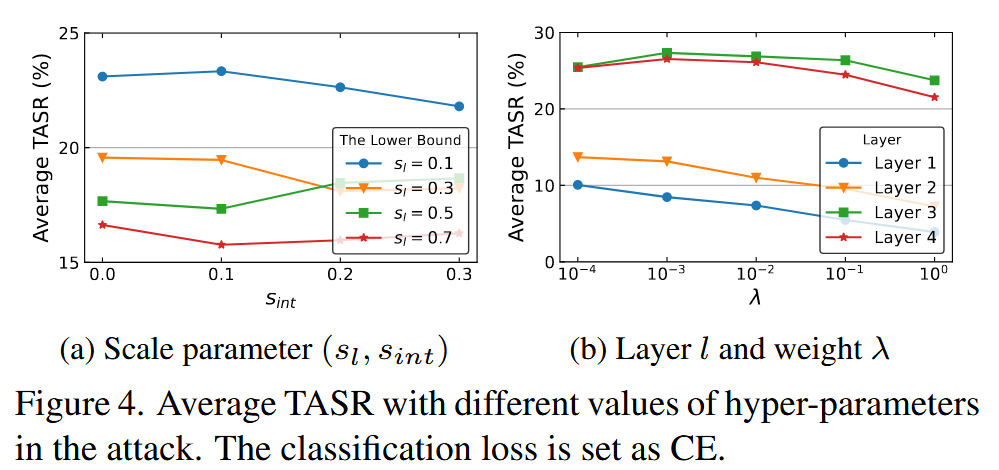
图4. 攻击中不同超参数取值下的平均目标攻击成功率(TASR)。分类损失设置为交叉熵(CE)。 - 不同裁剪区域影响:研究随机裁剪区域对攻击效果的影响,实验在图像的中心、角落、整个区域以及均匀分布区域进行。结果显示,中心和角落区域的性能差异不明显,因为SU关注目标类,不依赖于与原始类相关的对象;整个区域的攻击性能最佳;而均匀分布使得攻击难以收敛,性能最差。
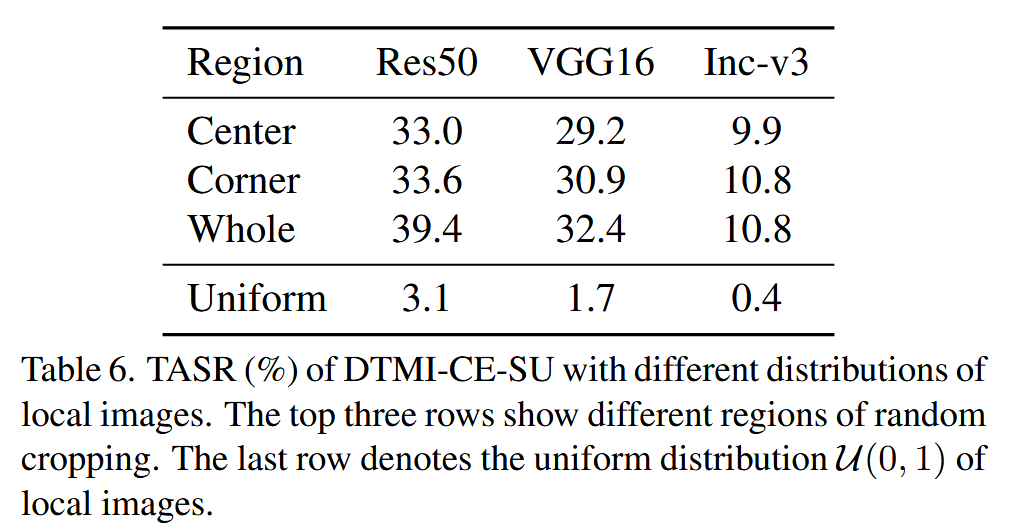
表6. DTMI-CE-SU在不同局部图像分布下的目标攻击成功率(TASR,%)。前三行展示了随机裁剪的不同区域。最后一行表示局部图像的均匀分布 u ( 0 , 1 ) u(0, 1) u(0,1).
- 组件效果:以CE为分类损失,在四种攻击场景下评估SU中不同组件的作用。将SU拆分为局部输入和特征相似性损失两个部分,实验结果表明这两个组件都能提升目标迁移性,且特征相似性损失对TASR的提升更显著,验证了SU攻击中各组件的有效性。
结论-Conclusion
本文聚焦于基于迁移的目标性攻击,通过研究提出自通用性(SU)攻击方法,在该领域取得了新进展,具体结论如下:
- 新见解:发现通用性与目标迁移性之间存在关联,即更具通用性的对抗扰动在目标性攻击中展现出更好的迁移性。这一发现为基于迁移的目标性攻击方法设计提供了新的思考方向。
- 方法优势:提出的SU攻击方法,优化了全局图像和多样局部图像上的扰动,并对齐它们之间的中间特征,使扰动对不同图像区域具有无关性,进而实现高自迁移性。该方法在不依赖额外数据的情况下,增强了对抗扰动的通用性,有效提升了目标迁移性。
- 实验验证:经过大量实验验证,无论是单模型攻击还是基于集成的攻击,SU攻击均能提高目标迁移性。在与现有最先进方法对比中,在ImageNet兼容数据集上,SU攻击的性能提升了12%。同时,消融实验表明,SU攻击中的组件及特定超参数设置对提升目标迁移性有效。
- 应用潜力:SU攻击方法可轻松与其他现有方法结合,进一步提升目标迁移性,且计算效率较高,在实际应用场景中具有一定的潜力,为后续研究和防御对抗攻击提供了参考。


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











